翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
SageMaker Processing を使用して、テラバイト規模の ML データセットの分散型特徴量エンジニアリングを実現
Chris Boomhower、Amazon Web Services
概要
テラバイト規模またはそれ以上のデータセットの多くは階層的なフォルダ構造で構成されており、データセット内のファイルは相互に依存している場合があります。このため、機械学習 (ML) エンジニアとデータサイエンティストは、モデルトレーニングや推論のためにデータを準備するために、慎重に設計上の決定を下さなければなりません。このパターンは、手動のマクロシャーディングとマイクロシャーディングの手法を Amazon SageMaker Processing と仮想 CPU (vCPU) 並列化と組み合わせて使用して、複雑なビッグデータ ML データセットの特徴量エンジニアリングプロセスを効率的にスケーリングする方法を示しています。
このパターンでは、データディレクトリを複数のマシンに分割して処理することを「マクロシャーディング」と定義し、「マイクロシャーディング」は各マシンのデータを複数の処理スレッドに分割することと定義されています。このパターンでは、Amazon SageMaker と「PhysioNet MIMIC-III
前提条件と制限
前提条件
独自のデータセットにこのパターンを実装する場合は、SageMaker ノートブックインスタンスまたは SageMaker Studio にアクセスできます。Amazon SageMaker を初めて使用する場合は、AWS ドキュメントの「Amazon SageMaker の入門」を参照してください。
SageMaker Studio、「PhysioNet MIMIC-III
」のサンプルデータを使用してこのパターンを実装したい場合。 このパターンは SageMaker 処理を使用しますが、SageMaker 処理ジョブを実行した経験は必要ありません。
制約事項
このパターンは、相互に依存するファイルを含む ML データセットに非常に適しています。このような相互依存関係は、手動によるマクロシャーディングと、複数の単一インスタンスの SageMaker Processing ジョブをparallel 実行することから最もメリットがあります。そのような相互依存関係が存在しないデータセットの場合、SageMaker Processing の
ShardedByS3Key機能は、同じ処理ジョブによって管理される複数のインスタンスにシャーディングされたデータを送信するため、マクロシャーディングのより良い代替となる可能性があります。ただし、このパターンのマイクロシャーディング戦略をどちらのシナリオでも実装して、インスタンス vCPUs を最大限に活用できます。
製品バージョン
Amazon SageMaker Python SDK バージョン 2
アーキテクチャ
ターゲットテクノロジースタック
Amazon Simple Storage Service (Amazon S3)
Amazon SageMaker
ターゲットアーキテクチャ
マクロシャーディングと分散型 EC2 インスタンス
このアーキテクチャで表される 10 個のparallel プロセスは、MIMIC-III データセットの構造を反映しています。(図を簡略化するため、プロセスは楕円で示されています)。手動マクロシャーディングを使用する場合も、同様のアーキテクチャがどのデータセットにも適用されます。MIMIC-III の場合、各患者グループフォルダーを最小の労力で個別に処理することで、データセットの未加工の構造を活用できます。以下の図では、レコードグループブロックが左側に表示されています (1)。データが分散されていることを考えると、患者グループごとにシャードするのは理にかなっています。
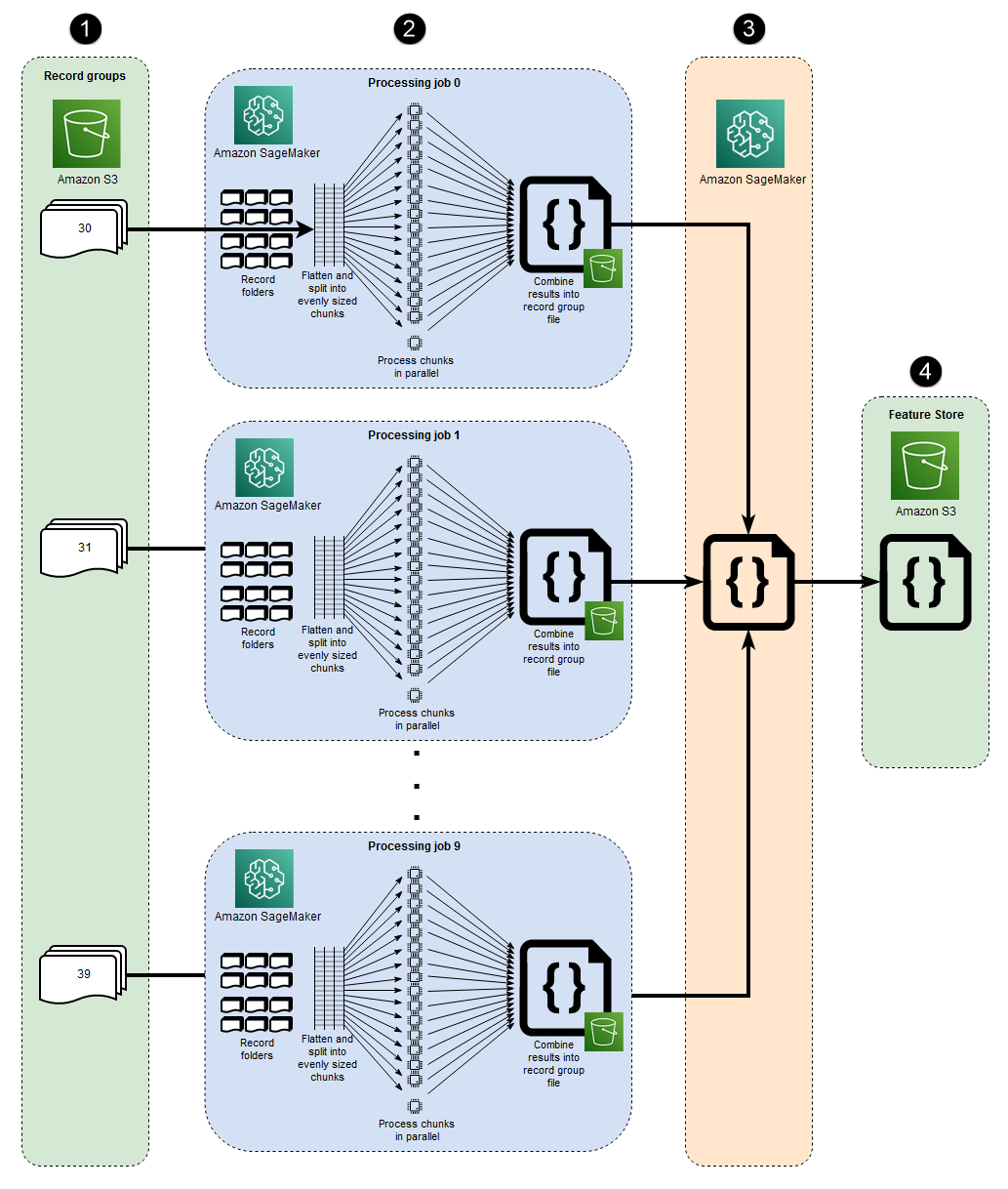
ただし、患者グループごとに手動でシャーディングを行うと、図 (2) の中央のセクションでわかるように、複数の EC2 インスタンスによる単一の処理ジョブではなく、患者グループフォルダごとに個別の処理ジョブが必要になります。MIMIC-III のデータには、バイナリ波形ファイルと対応するテキストベースのヘッダーファイルの両方が含まれており、バイナリデータ抽出には「wfdb ライブラリs3_data_distribution_type='FullyReplicated'を指定することです。あるいは、すべてのデータが単一のディレクトリにあり、ファイル間に依存関係がない場合、より適切なオプションは、複数の EC2 インスタンスとs3_data_distribution_type='ShardedByS3Key'を指定して単一の処理ジョブを起動することかもしれません。Amazon S3 データ分散タイプとしてShardedByS3Key を指定すると、SageMaker はインスタンス間のデータシャーディングを自動的に管理するようになります。
複数のインスタンスを同時に実行すると時間を節約できるため、データを前処理するにはフォルダごとに処理ジョブを起動するのがコスト効率の高い方法です。コストと時間をさらに節約するために、各処理ジョブ内でマイクロシャーディングを使用することもできます。
マイクロシャーディングとparallel vCPUs
各処理ジョブ内で、グループ化されたデータはさらに分割され、SageMaker のフルマネージド EC2 インスタンスで使用可能なすべての vCPUs を最大限に活用します。図の中央のセクション (2) のブロックは、各主要処理ジョブ内で何が起こるかを表しています。患者記録フォルダーの内容は、インスタンスで使用可能なvCPUs の数に基づいてフラット化され、均等に分割されます。フォルダの内容が分割されると、同じサイズのファイルセットがすべての vCPUs に分散されて処理されます。処理が完了すると、各 vCPU の結果は、処理ジョブごとに 1 つのデータファイルにまとめられます。
添付のコードでは、これらの概念がsrc/feature-engineering-pass1/preprocessing.pyファイルの次のセクションに示されています。
def chunks(lst, n): """ Yield successive n-sized chunks from lst. :param lst: list of elements to be divided :param n: number of elements per chunk :type lst: list :type n: int :return: generator comprising evenly sized chunks :rtype: class 'generator' """ for i in range(0, len(lst), n): yield lst[i:i + n] # Generate list of data files on machine data_dir = input_dir d_subs = next(os.walk(os.path.join(data_dir, '.')))[1] file_list = [] for ds in d_subs: file_list.extend(os.listdir(os.path.join(data_dir, ds, '.'))) dat_list = [os.path.join(re.split('_|\.', f)[0].replace('n', ''), f[:-4]) for f in file_list if f[-4:] == '.dat'] # Split list of files into sub-lists cpu_count = multiprocessing.cpu_count() splits = int(len(dat_list) / cpu_count) if splits == 0: splits = 1 dat_chunks = list(chunks(dat_list, splits)) # Parallelize processing of sub-lists across CPUs ws_df_list = Parallel(n_jobs=-1, verbose=0)(delayed(run_process)(dc) for dc in dat_chunks) # Compile and pickle patient group dataframe ws_df_group = pd.concat(ws_df_list) ws_df_group = ws_df_group.reset_index().rename(columns={'index': 'signal'}) ws_df_group.to_json(os.path.join(output_dir, group_data_out))
最初に関数chunksを定義し、与えられたリストをn の長さの均一な大きさのブロックに分割し、その結果をジェネレータとして返すことにより、与えられたリストを使用します。次に、存在するすべてのバイナリ波形ファイルのリストをコンパイルして、データを患者フォルダー全体でフラット化します。これが完了すると、EC2 インスタンスで使用可能な vCPUs の数が取得されます。バイナリ波形ファイルのリストは、chunksを呼び出すことによってこれらのvCPUに均等に分割され、その後、「joblibのParallelクラス
最初の処理ジョブがすべて完了すると、図 (3) の右側のブロックに示されているセカンダリ処理ジョブが、各プライマリ処理ジョブによって生成された出力ファイルを結合し、結合された出力を Amazon S3 (4) に書き込みます。
ツール
ツール
Python
— このパターンに使用されるサンプルコードは Python (バージョン 3) です。 SageMaker Studio – Amazon SageMaker Studio は、ウェブベースの機械学習用の統合開発環境 (IDE) です。この IDE を使うと、機械学習モデルを構築、トレーニング、デバッグ、デプロイ、モニタリングできます。SageMaker Processing ジョブは、SageMaker Studio 内の Jupyter Notebookを使用して実行します。
SageMaker Processing — Amazon SageMaker Processingを使用すると、データ処理ワークロードを簡単に実行できます。このパターンでは、特徴量エンジニアリングコードは SageMaker Processing ジョブを使用して大規模に実装されます。
Code
添付の.zip ファイルには、このパターンの完全なコードが記載されています。次のセクションでは、このパターンのアーキテクチャを構築する手順について説明します。各ステップは、添付ファイルのサンプルコードで説明されています。
エピック
| タスク | 説明 | 必要なスキル |
|---|---|---|
| Amazon SageMaker Studio へアクセスします。 | 「Amazon SageMaker ドキュメント」に記載されている指示に従って、AWS アカウントの SageMaker Studio にオンボーディングします。 | データサイエンティスト、ML エンジニア |
| wget ユーティリティをインストールします。 | 新しい SageMaker Studio 構成をオンボーディングした場合や、SageMaker Studio でこれらのユーティリティをこれまで使用したことがない場合は、「wget」をインストールしてください。 インストールするには、SageMaker Studio コンソールでターミナルウィンドウを開き、以下のコマンドを実行します。
| データサイエンティスト、ML エンジニア |
| サンプルコードをダウンロードして解凍します。 | 「添付ファイル」セクションから
| データサイエンティスト、ML エンジニア |
| physionet.org からサンプルデータセットをダウンロードし、Amazon S3 にアップロードします。 |
| データサイエンティスト、ML エンジニア |
| タスク | 説明 | 必要なスキル |
|---|---|---|
| すべてのサブディレクトリにわたってファイル階層をフラット化する。 | MIMIC-III のような大規模なデータセットでは、論理的な親グループ内であってもファイルが複数のサブディレクトリに分散されることがよくあります。次のコードが示すように、スクリプトはすべてのサブディレクトリにあるすべてのグループファイルをフラット化するように設定する必要があります。
注記 このエピックのコードスニペットの例は、添付ファイルに記載されている | データサイエンティスト、ML エンジニア |
| vCPU 数に基づいてファイルをサブグループに分割します。 | ファイルは、スクリプトを実行するインスタンスに存在するvCPUs の数に応じて、同じサイズのサブグループまたはチャンクに分割する必要があります。このステップでは、次のようなコードを実装できます。
| データサイエンティスト、ML エンジニア |
| vCPUs 間のサブグループの処理を並列化します。 | スクリプトロジックは、すべてのサブグループを並行して処理するように設定する必要があります。そのためには、Joblib ライブラリの
| データサイエンティスト、ML エンジニア |
| Amazon S3 に単一ファイルグループの出力を保存します。 | 並列 vCPU 処理が完了したら、各 vCPU の結果を組み合わせて、ファイルグループの S3 バケットパスにアップロードする必要があります。このステップでは、次のようなコードを実行できます。
| データサイエンティスト、ML エンジニア |
| タスク | 説明 | 必要なスキル |
|---|---|---|
| 最初のスクリプトを実行したすべての処理ジョブで生成されたデータファイルを結合します。 | 前述のスクリプトは、データセットのファイルグループを処理する SageMaker Processing ジョブごとに 1 つのファイルを出力します。 次に、これらの出力ファイルを 1 つのオブジェクトに結合し、1 つの出力データセットを Amazon S3 に書き込む必要があります。これは、添付ファイルにある
| データサイエンティスト、ML エンジニア |
| タスク | 説明 | 必要なスキル |
|---|---|---|
| 最初の処理ジョブを実行します。 | マクロシャーディングを実行するには、ファイルグループごとに個別の処理ジョブを実行します。マイクロシャーディングは各処理ジョブ内で実行されます。これは、各ジョブで最初のスクリプトが実行されるためです。次のコードは、次のスニペット (
| データサイエンティスト、ML エンジニア |
| 2 つ目の処理ジョブを実行します。 | 最初の処理ジョブセットで生成された出力を結合し、前処理のために追加の計算を実行するには、1 つの SageMaker 処理ジョブを使用して 2 番目のスクリプトを実行します。次のコードはこれを示しています (
| データサイエンティスト、ML エンジニア |
関連リソース
クイックスタートを使用して Amazon SageMaker Studio にオンボーディングする (SageMaker ドキュメント)
プロセスデータ (SageMaker ドキュメンテーション)
scikit-learn を使ってデータを処理する (SageMaker ドキュメンテーション)
ムーディ、B.、ムーディ、G.、ビジャロエル、M.、クリフォード、G.D.、シルバ、I. (2020)。MIMIC-III
波形データベース (バージョン 1.0)。フィジオネット。 ジョンソン、A. E. W.、ポラード、T.J.、シェン、L.、リーマン、L.H.、フェン、M.、ガセミ、M.、ムーディ、B.、ゾロビッツ、P.、セリ、L.A.、マーク、R.G.(2016)。「MIMIC-III
」は、無料でアクセスできる救命救急データベースです。科学データ、3、160035。
添付ファイル
このドキュメントに関連する追加コンテンツにアクセスするには、次のファイルを解凍してください。「attachment.zip」
