翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Redshift データウェアハウスのアーキテクチャコンポーネント
Amazon Redshift データウェアハウスのコアアーキテクチャコンポーネントについて基本的な知識を持つことをお勧めします。この知識は、最適なパフォーマンスを得るためにクエリとテーブルを設計する方法をよりよく理解するのに役立ちます。
Amazon Redshift のデータウェアハウスは、以下のコアアーキテクチャコンポーネントで構成されています。
-
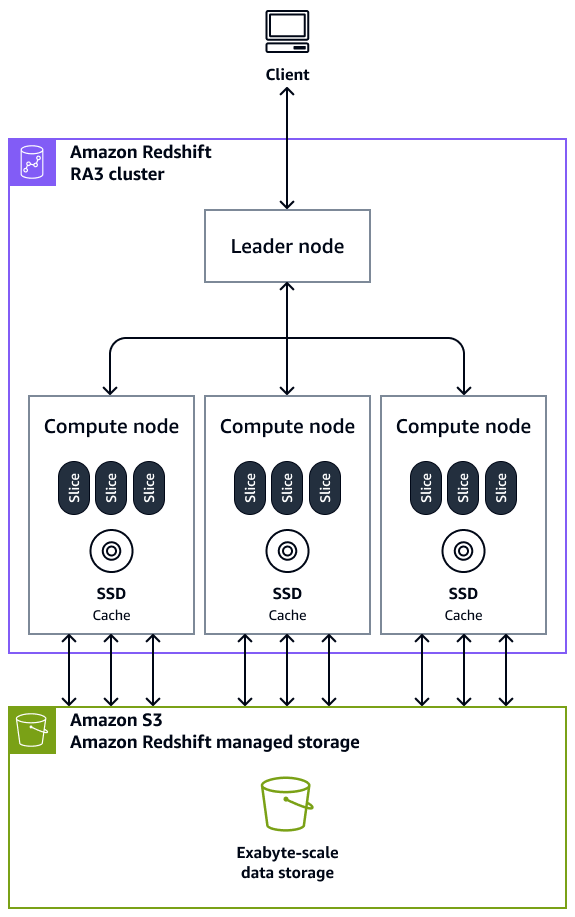
クラスター – 1 つ以上のコンピューティングノードで構成されるクラスターは、Amazon Redshift データウェアハウスのコアインフラストラクチャコンポーネントです。コンピューティングノードは外部アプリケーションに対して透過的ですが、クライアントアプリケーションはリーダーノードとのみ直接やり取りします。一般的なクラスターには、2 つ以上のコンピューティングノードがあります。コンピューティングノードはリーダーノードを介して調整されます。
-
リーダーノード – リーダーノードは、クライアントプログラムとすべてのコンピューティングノードの通信を管理します。リーダーノードは、クエリがクラスターに送信されるたびにクエリを実行するための計画も準備します。計画の準備ができたら、リーダーノードはコードをコンパイルし、コンパイルされたコードをコンピューティングノードに分散してから、データスライスを各コンピューティングノードに割り当ててクエリ結果を処理します。
-
コンピューティングノード – コンピューティングノードはクエリを実行します。リーダーノードは、クエリを実行するプランの個々の要素のコードをコンパイルし、コードを個々のコンピューティングノードに割り当てます。コンピューティングノードは、コンパイル済みのコードを実行し、最終的な集計のために中間結果をリーダーノードに返送します。各コンピューティングノードには、専用の CPU、メモリ、およびアタッチされたディスクストレージがあります。ワークロードが増えるに従って、ノードの数を増やすかノードの種類をアップグレードして、または両方を行って、クラスターのコンピューティング能力とストレージ容量を拡張できます。
-
ノードスライス – コンピューティングノードはスライスと呼ばれる単位に分割されます。コンピューティングノードのすべてのスライスには、ノードに割り当てられたワークロードの一部を処理するノードのメモリとディスク領域の一部が割り当てられます。スライスは、並列処理を行って操作を完了します。データは、特定のテーブルの分散スタイルと分散キーに基づいてスライス間で分散されます。データの均等な分散により、Amazon Redshift はワークロードをスライスに均等に割り当て、並列処理の利点を最大化できます。コンピューティングノードあたりのスライス数は、ノードのタイプに基づいて決定されます。詳細については、Amazon Redshift ドキュメントの「Amazon Redshift のクラスターとノード」を参照してください。
-
超並列処理 (MPP) – Amazon Redshift は MPP アーキテクチャを使用して、複雑なクエリや膨大な量のデータであっても、データを迅速に処理します。複数のコンピューティングノードがデータの一部に対して同じクエリコードを実行して、並列処理を最大化します。
-
クライアントアプリケーション – Amazon Redshift は、さまざまな抽出、変換、ロード (ETL)、ビジネスインテリジェンス (BI) レポート、データマイニング、分析ツールと統合されています。すべてのクライアントアプリケーションは、リーダーノードを介してのみクラスターと通信します。
次の図は、Amazon Redshift データウェアハウスのアーキテクチャコンポーネントがどのように連携してクエリを高速化するかを示しています。