翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
ユースケース: 患者の成果と再入院率の予測
AI を活用した予測分析は、患者の成果を予測し、パーソナライズされた治療計画を可能にすることで、さらにメリットをもたらします。これにより、患者の満足度と健康上の成果を向上させることができます。これらの AI 機能を Amazon Bedrock やその他のテクノロジーと統合することで、医療プロバイダーは大幅な生産性の向上、コストの削減、患者ケアの全体的な品質の向上を実現できます。
患者の履歴、臨床メモ、薬剤、治療などの医療データをナレッジグラフ
このソリューションは、再入院の可能性を予測するのに役立ちます。これらの予測により、患者の成果が向上し、医療コストを削減できます。このソリューションは、病院の臨床医や管理者が再入院のリスクが高い患者に注意を向けるのにも役立ちます。また、アラート、セルフサービス、データ駆動型のアクションを通じて、これらの患者との積極的な介入を開始するのにも役立ちます。
ソリューションの概要
このソリューションは、マルチリトリーバー取得拡張生成 (RAG) フレームワークを使用して、患者データを分析します。個々の患者の再入院の可能性を予測し、病院レベルの再入院傾向スコアを計算するのに役立ちます。このソリューションには、次の機能が統合されています。
-
ナレッジグラフ – 入院、以前の再入院、症状、検査結果、処方された治療、薬剤遵守履歴などの構造化された時系列患者データを保存します。
-
ベクトルデータベース – 退床サマリー、医師のメモ、予約ミスや報告された薬剤副作用の記録など、構造化されていない臨床データを保存します。
-
微調整された LLM – 患者の行動、治療の遵守状況、再入院の可能性に関する推論を生成するために、ナレッジグラフの構造化データとベクトルデータベースの非構造化データの両方を消費します。
リスクスコアモデルは、LLM からの推論を数値スコアに定量化します。スコアを病院レベルの再入院傾向スコアに集計できます。このスコアは、各患者のリスクエクスポージャーを定義し、定期的に、または必要に応じて計算できます。すべての推論とリスクスコアはインデックス化され、Amazon OpenSearch Service に保存されるため、ケアマネージャーと臨床医はそれを取得できます。会話型 AI エージェントをこのベクトルデータベースと統合することで、臨床医とケアマネージャーは個々の患者レベル、施設全体、または医療専門分野別にシームレスにインサイトを抽出できます。また、リスクスコアに基づいて自動アラートを設定して、プロアクティブな介入を促すこともできます。
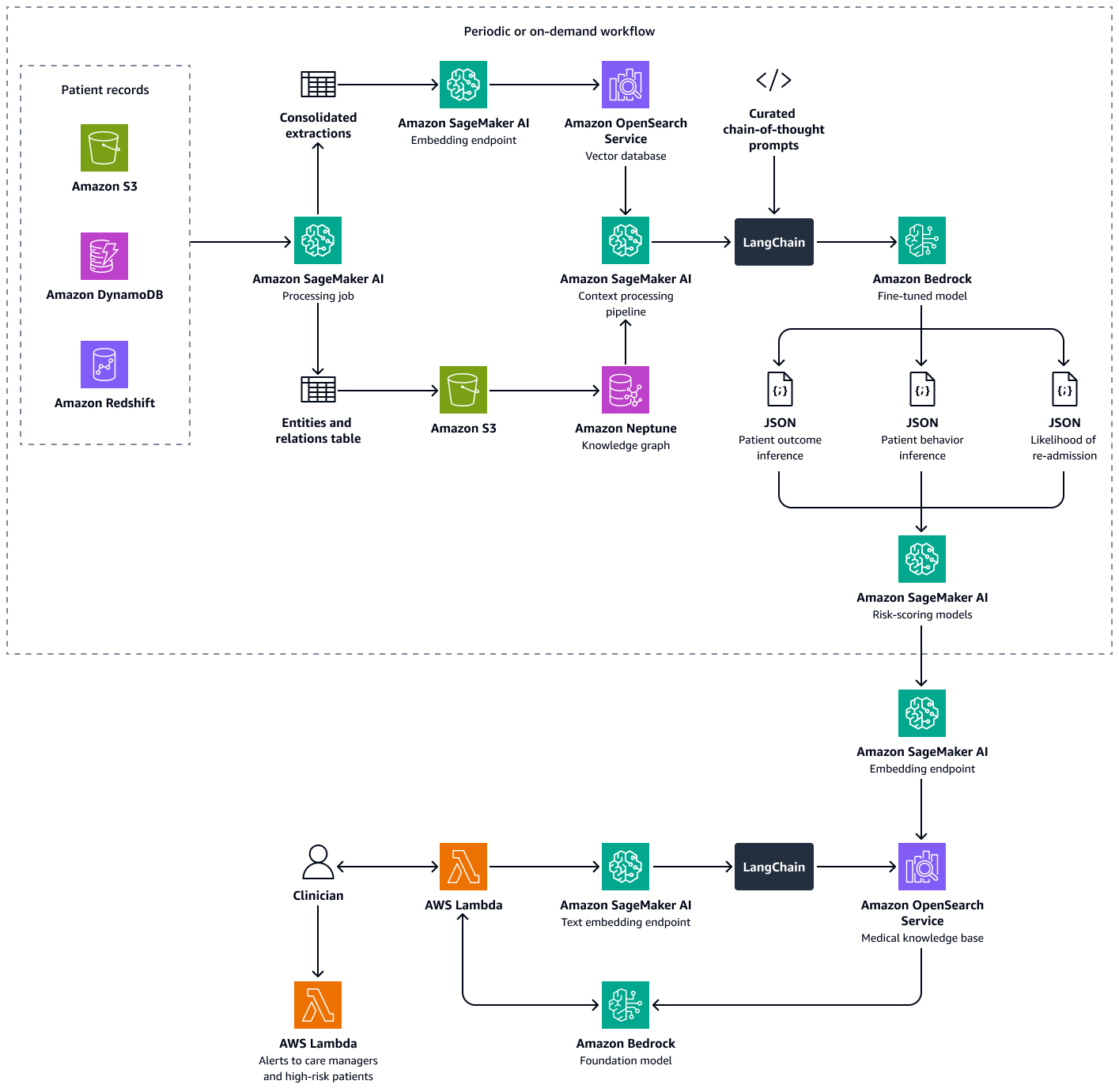
このソリューションの構築は、次のステップで構成されます。
ステップ 1: 医療知識グラフを使用して患者の成果を予測する
Amazon Neptune では、ナレッジグラフを使用して、患者の診察と結果に関する一時的な知識を経時的に保存できます。ナレッジグラフを構築して保存する最も効果的な方法は、グラフモデルとグラフデータベースを使用することです。グラフデータベースは、関係を保存およびナビゲートする目的で構築されています。グラフデータベースを使用すると、高度に接続されたデータのモデル化と管理が容易になり、柔軟なスキーマを持つことができます。
ナレッジグラフは、時系列分析の実行に役立ちます。以下は、患者の結果の一時的な予測に使用されるグラフデータベースの主要な要素です。
-
履歴データ - 患者の以前の診断、継続的な薬剤、以前に使用した薬剤、および検査結果
-
患者の訪問 (時系列) – 訪問日、症状、観察されたアレルギー、臨床記録、診断、処置、治療、処方された薬剤、および検査結果
-
症状と臨床パラメータ – 重大度、進行パターン、薬剤に対する患者の反応など、臨床および症状ベースの情報
医療知識グラフからのインサイトを使用して、Llama 3 などの Amazon Bedrock の LLM を微調整できます。LLM は、一連の薬剤や治療に対する患者の反応に関するシーケンシャルな患者データで微調整します。の一連の薬剤または治療と患者と臨床の相互作用データを、患者の健康状態を示す事前定義されたカテゴリに分類するラベル付きデータセットを使用します。これらのカテゴリの例としては、健康状態の悪化、改善、または安定した進行などがあります。臨床医が患者とその症状に関する新しいコンテキストを入力すると、微調整された LLM はトレーニングデータセットのパターンを使用して、潜在的な患者の結果を予測できます。
次の図は、医療固有のトレーニングデータセットを使用して Amazon Bedrock で LLM をファインチューニングする手順を示しています。このデータには、患者の病状や時間の経過に伴う治療への反応が含まれる場合があります。このトレーニングデータセットは、モデルが患者の結果について一般化された予測を行うのに役立ちます。
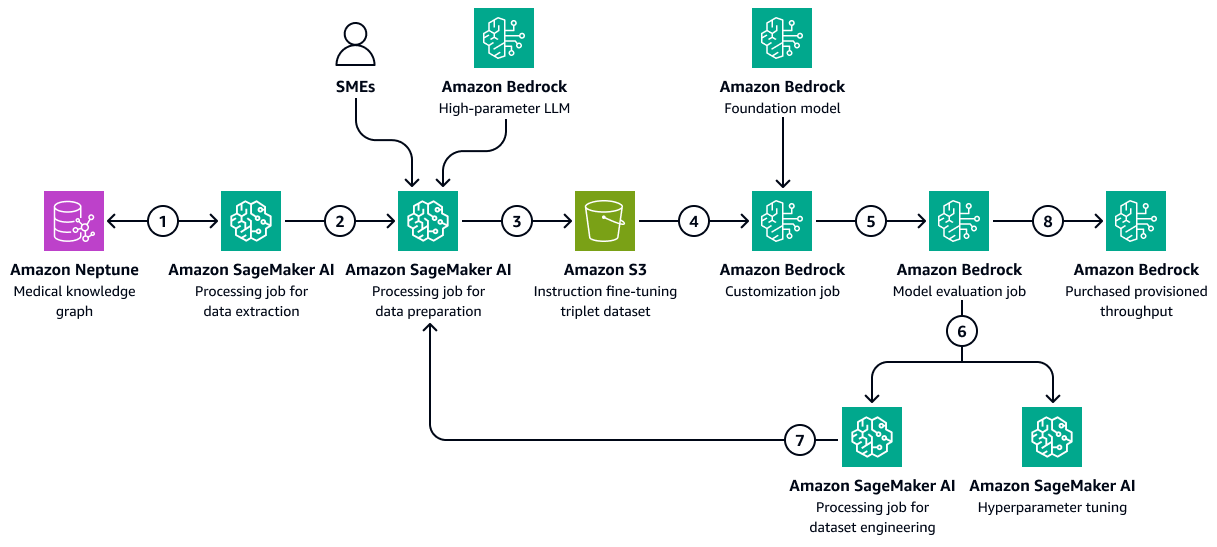
この図表は、次のワークフローを示しています:
-
Amazon SageMaker AI データ抽出ジョブは、ナレッジグラフをクエリして、一連の薬剤または治療に対するさまざまな患者の応答に関する時系列データを取得します。
-
SageMaker AI データ準備ジョブは、Amazon Bedrock LLM と対象分野のエキスパート (SMEs。ジョブは、ナレッジグラフから取得したデータを、各患者のヘルスステータスを示す事前定義されたカテゴリ (ヘルスの悪化、改善、安定した進行状況など) に分類します。
-
ジョブは、ナレッジグラフから抽出された情報、chain-of-thoughtプロンプト、および患者結果カテゴリを含むファインチューニングデータセットを作成します。トレーニングデータセットを Amazon S3 バケットにアップロードします。
-
Amazon Bedrock カスタマイズジョブは、このトレーニングデータセットを使用して LLM を微調整します。
-
Amazon Bedrock カスタマイズジョブは、選択した Amazon Bedrock 基盤モデルをトレーニング環境に統合します。微調整ジョブが開始され、設定したトレーニングデータセットとトレーニングハイパーパラメータが使用されます。
-
Amazon Bedrock 評価ジョブは、事前に設計されたモデル評価フレームワークを使用して、微調整されたモデルを評価します。
-
モデルを改善する必要がある場合、トレーニングデータセットを慎重に検討した後、トレーニングジョブはより多くのデータで再度実行されます。モデルが増分パフォーマンスの向上を示していない場合は、トレーニングハイパーパラメータの変更も検討してください。
-
モデル評価がビジネスステークホルダーによって定義された基準を満たしたら、微調整されたモデルを Amazon Bedrock のプロビジョニングされたスループットにホストします。
ステップ 2: 処方された薬剤または治療に対する患者の行動を予測する
微調整された LLMs は、一時的な医療知識グラフから臨床メモ、退床概要、およびその他の患者固有のドキュメントを処理できます。患者は、処方された薬剤や治療に従う可能性が高いかどうかを評価できます。
このステップでは、 で作成されたナレッジグラフを使用しますステップ 1: 医療知識グラフを使用して患者の成果を予測する。ナレッジグラフには、ノードとしての患者の過去の準拠状況など、患者のプロファイルからのデータが含まれます。また、医薬品や治療への非準拠、医薬品への副作用、医薬品へのアクセス不足やコスト障壁、このようなノードの属性としての複雑な治療計画も含まれます。
微調整された LLMs は、医療知識グラフの過去の処方フルフィルメントデータと、Amazon OpenSearch Service ベクトルデータベースの臨床メモの記述的な概要を消費できます。これらの臨床メモには、頻繁に予約を見逃したり、治療へのコンプライアンス違反があったりすることが記載されている場合があります。LLM は、これらのメモを使用して、将来の非準拠の可能性を予測できます。
-
次のように入力データを準備します。
-
構造化データ – 過去 3 回の訪問や検査結果などの最近の患者データを医療知識グラフから抽出します。
-
非構造化データ – Amazon OpenSearch Service ベクトルデータベースから最新の臨床メモを取得します。
-
-
患者の履歴と現在のコンテキストを含む入力プロンプトを作成します。プロンプトの例を次に示します。
You are a highly specialized AI model trained in healthcare predictive analytics. Your task is to analyze a patient's historical medical records, adherence patterns, and clinical context to predict the **likelihood of future non-adherence** to prescribed medications or treatments. ### **Patient Details** - **Patient ID:** {patient_id} - **Age:** {age} - **Gender:** {gender} - **Medical Conditions:** {medical_conditions} - **Current Medications:** {current_medications} - **Prescribed Treatments:** {prescribed_treatments} ### **Chronological Medical History** - **Visit Dates & Symptoms:** {visit_dates_symptoms} - **Diagnoses & Procedures:** {diagnoses_procedures} - **Prescribed Medications & Treatments:** {medications_treatments} - **Past Adherence Patterns:** {historical_adherence} - **Instances of Non-Adherence:** {past_non_adherence} - **Side Effects Experienced:** {side_effects} - **Barriers to Adherence (e.g., Cost, Access, Dosing Complexity):** {barriers} ### **Patient-Specific Insights** - **Clinical Notes & Discharge Summaries:** {clinical_notes} - **Missed Appointments & Non-Compliance Patterns:** {missed_appointments} ### **Let's think Step-by-Step to predict the patient behaviour** 1. You should first analyze past adherence trends and patterns of non-adherence. 2. Identify potential barriers, such as financial constraints, medication side effects, or complex dosing regimens. 3. Thoroughly examine clinical notes and documented patient behaviors that may hint at non-adherence. 4. Correlate adherence history with prescribed treatments and patient conditions. 5. Finally predict the likelihood of non-adherence based on these contextual insights. ### **Output Format (JSON)** Return the prediction in the following structured format: ```json { "patient_id": "{patient_id}", "likelihood_of_non_adherence": "{low | moderate | high}", "reasoning": "{detailed_explanation_based_on_patient_history}" } -
プロンプトを微調整された LLM に渡します。LLM はプロンプトを処理し、結果を予測します。LLM からのレスポンスの例を次に示します。
{ "patient_id": "P12345", "likelihood_of_non_adherence": "high", "reasoning": "The patient has a history of missed appointments, has reported side effects to previous medications. Additionally, clinical notes indicate difficulty following complex dosing schedules." } -
モデルのレスポンスを解析して、予測された結果カテゴリを抽出します。たとえば、前のステップのレスポンス例のカテゴリは、非準拠である可能性が高い可能性があります。
-
(オプション) モデルログまたは追加の方法を使用して、信頼スコアを割り当てます。ログは、特定のクラスまたはカテゴリに属する項目の正規化されていない確率です。
ステップ 3: 患者の再入院の可能性を予測する
医療管理のコストが高く、患者の健康に影響するため、病院の再入室は大きな懸念事項です。再入院率の計算は、患者のケアの質と医療提供者のパフォーマンスを測定する方法の 1 つです。
再入院率を計算するために、7 日間の再入院率などのインジケータを定義しました。このインジケータは、入院した患者のうち、7 日以内に予定外の訪問のために再入院した患者の割合を示します。患者の再入院の可能性を予測するために、微調整された LLM は、 で作成した医療知識グラフの時間データを消費できますステップ 1: 医療知識グラフを使用して患者の成果を予測する。このナレッジグラフは、患者の診察、処置、薬剤、症状の時系列記録を維持します。これらのデータレコードには以下が含まれます。
-
患者の最後の退床からの期間
-
過去の治療や薬剤に対する患者の反応
-
時間の経過に伴う症状または状態の進行
これらの時系列イベントを処理して、キュレートされたシステムプロンプトを通じて患者の再入院の可能性を予測できます。プロンプトは、微調整された LLM に予測ロジックを付与します。
-
次のように入力データを準備します。
-
準拠履歴 – 医療知識グラフから、薬剤の集荷日、薬剤補充の頻度、診断と薬剤の詳細、時系列の医療履歴、その他の情報を抽出します。
-
行動指標 - 予約ミスや患者報告の副作用に関する臨床記録を取得して含めます。
-
-
準拠履歴と動作インジケータを含む入力プロンプトを作成します。プロンプトの例を次に示します。
You are a highly specialized AI model trained in healthcare predictive analytics. Your task is to analyze a patient's historical medical records, clinical events, and adherence patterns to predict the **likelihood of hospital readmission** within the next few days. ### **Patient Details** - **Patient ID:** {patient_id} - **Age:** {age} - **Gender:** {gender} - **Primary Diagnoses:** {diagnoses} - **Current Medications:** {current_medications} - **Prescribed Treatments:** {prescribed_treatments} ### **Chronological Medical History** - **Recent Hospital Encounters:** {encounters} - **Time Since Last Discharge:** {time_since_last_discharge} - **Previous Readmissions:** {past_readmissions} - **Recent Lab Results & Vital Signs:** {recent_lab_results} - **Procedures Performed:** {procedures_performed} - **Prescribed Medications & Treatments:** {medications_treatments} - **Past Adherence Patterns:** {historical_adherence} - **Instances of Non-Adherence:** {past_non_adherence} ### **Patient-Specific Insights** - **Clinical Notes & Discharge Summaries:** {clinical_notes} - **Missed Appointments & Non-Compliance Patterns:** {missed_appointments} - **Patient-Reported Side Effects & Complications:** {side_effects} ### **Reasoning Process – You have to analyze this use case step-by-step.** 1. First assess **time since last discharge** and whether recent hospital encounters suggest a pattern of frequent readmissions. 2. Second examine **recent lab results, vital signs, and procedures performed** to identify clinical deterioration. 3. Third analyze **adherence history**, checking if past non-adherence to medications or treatments correlates with readmissions. 4. Then identify **missed appointments, self-reported side effects, or symptoms worsening** from clinical notes. 5. Finally predict the **likelihood of readmission** based on these contextual insights. ### **Output Format (JSON)** Return the prediction in the following structured format: ```json { "patient_id": "{patient_id}", "likelihood_of_readmission": "{low | moderate | high}", "reasoning": "{detailed_explanation_based_on_patient_history}" } -
ファインチューニングされた LLM にプロンプトを渡します。LLM はプロンプトを処理し、再入院の可能性と理由を予測します。LLM からのレスポンスの例を次に示します。
{ "patient_id": "P67890", "likelihood_of_readmission": "high", "reasoning": "The patient was discharged only 5 days ago, has a history of more than two readmissions to hospitals where the patient received treatment. Recent lab results indicate abnormal kidney function and high liver enzymes. These factors suggest a medium risk of readmission." } -
予測を低、中、高などの標準化されたスケールに分類します。
-
LLM が提供する推論を確認し、予測に寄与する主要な要因を特定します。
-
定性的出力を量的スコアにマッピングします。例えば、非常に高い場合、確率は 0.9 になります。
-
検証データセットを使用して、実際の再アドミッション率に対してモデル出力をキャリブレーションします。
ステップ 4: 再入院傾向スコアを計算する
次に、患者ごとに再入院傾向スコアを計算します。このスコアは、前のステップで実行された 3 つの分析の正味の影響を反映しています。考えられる患者の成果、薬剤や治療に対する患者の行動、患者の再入院の可能性です。患者レベルの再入院傾向スコアを専門分野レベルに集約し、次に病院レベルで集計することで、臨床医、ケアマネージャー、管理者に関するインサイトを得ることができます。再入院傾向スコアは、施設、専門分野、または状態別に全体的なパフォーマンスを評価するのに役立ちます。次に、このスコアを使用してプロアクティブな介入を実装できます。
-
さまざまな要因 (結果予測、準拠可能性、再入院) に重みを割り当てます。重みの例を次に示します。
-
結果予測の重み: 0.4
-
準拠予測の重み: 0.3
-
再入院の可能性の重み: 0.3
-
-
複合スコアを計算するには、次の計算を使用します。
ReadadmissionPropensityScore= (OutcomeScore×OutcomeWeight) + (AdherenceScore×AdherenceWeight) + (ReadmissionLikelihoodScore×ReadmissionLikelihoodWeight) -
0~1 など、すべての個々のスコアが同じスケールであることを確認します。
-
アクションのしきい値を定義します。たとえば、0.7 を超えるスコアはアラートを開始します。
上記の分析と患者の再入院傾向スコアに基づいて、臨床医またはケアマネージャーは、計算されたスコアに基づいて個々の患者を監視するアラートを設定できます。事前定義されたしきい値を超えると、そのしきい値に達したときに通知されます。これにより、ケアマネージャーは患者の退床ケアプランを作成する際に、事後対応的ではなく事前対応的になることができます。患者の結果、動作、再入院傾向スコアをインデックス付き形式で Amazon OpenSearch Service ベクトルデータベースに保存して、ケアマネージャーが会話 AI エージェントを使用してシームレスに取得できるようにします。
次の図は、臨床医またはケアマネージャーが患者の成果、予想される動作、再入院傾向に関するインサイトを取得するために使用できる会話型 AI エージェントのワークフローを示しています。ユーザーは、患者レベル、部門レベル、または病院レベルでインサイトを取得できます。AI エージェントはこれらのインサイトを取得し、Amazon OpenSearch Service ベクトルデータベースのインデックス付き形式で保存されます。エージェントはクエリを使用して関連データを取得し、再入院のリスクが高い患者に対して推奨されるアクションなど、カスタマイズされたレスポンスを提供します。リスクのレベルに基づいて、エージェントは患者とケア提供者のリマインダーを設定することもできます。
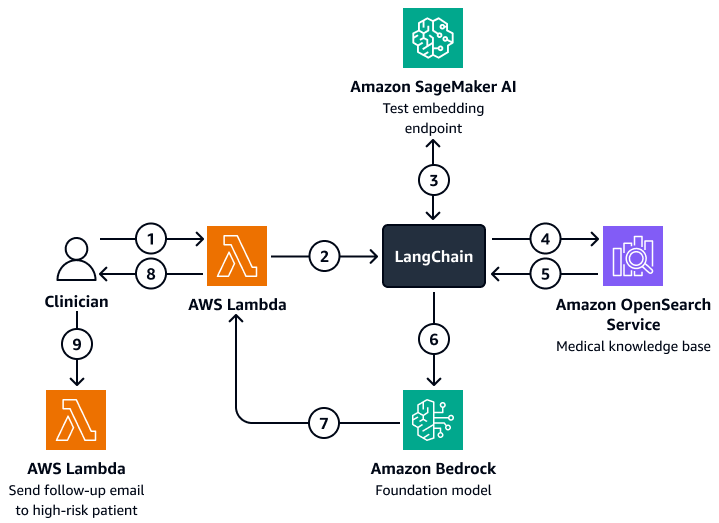
この図表は、次のワークフローを示しています:
-
臨床医は、 関数を格納する会話型 AI エージェントに質問をします AWS Lambda 。
-
Lambda 関数はLangChainエージェントを開始します。
-
LangChain エージェントは、ユーザーの質問を Amazon SageMaker AI テキスト埋め込みエンドポイントに送信します。エンドポイントは質問を埋め込みます。
-
LangChain エージェントは埋め込み質問を Amazon OpenSearch Service の医療ナレッジベースに渡します。
-
Amazon OpenSearch Service は、ユーザークエリに最も関連性の高い特定のインサイトをLangChainエージェントに返します。
-
LangChain エージェントは、ナレッジベースから取得したクエリとコンテキストを Amazon Bedrock 基盤モデルに送信します。
-
Amazon Bedrock 基盤モデルはレスポンスを生成し、Lambda 関数に送信します。
-
Lambda 関数は、臨床医にレスポンスを返します。
-
臨床医は、再入院のリスクが高い患者にフォローメールを送信する Lambda 関数を開始します。
AWS Well-Architected フレームワークへの調整
患者の行動を追跡し、再入院率を予測するアーキテクチャは AWS のサービス、AWS Well-Architected フレームワーク
-
運用上の優秀性 – このソリューションは、Amazon Bedrock と を使用してリアルタイムのアラート AWS Lambda を行う、分離された自動化されたシステムです。
-
セキュリティ – このソリューションは、HIPAA などの医療規制に準拠するように設計されています。暗号化、きめ細かなアクセスコントロール、Amazon Bedrock ガードレールを実装して、患者データを保護することもできます。
-
信頼性 – このアーキテクチャでは、耐障害性のあるサーバーレスを使用します AWS のサービス。
-
パフォーマンス効率 – Amazon OpenSearch Service と微調整された LLMs は、迅速かつ正確な予測を提供できます。
-
コストの最適化 – サーバーレステクノロジーとpay-per-inferenceモデルは、コストを最小限に抑えるのに役立ちます。微調整された LLM を使用すると追加料金が発生する可能性がありますが、モデルは微調整プロセスに必要なデータと計算時間を短縮する RAG アプローチを使用します。
-
持続可能性 – このアーキテクチャは、サーバーレスインフラストラクチャを使用してリソースの消費を最小限に抑えます。また、効率的でスケーラブルな医療オペレーションもサポートしています。
