翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
ユースケース: 医療スタッフの管理とスキル向上
人材トランスフォーメーション戦略とスキル向上戦略を実装することで、ワークフォースは医療および医療サービスで新しいテクノロジーとプラクティスの使用に精通し続けることができます。プロアクティブなスキル向上イニシアチブにより、医療専門家は高品質の患者ケアを提供し、運用効率を最適化し、規制基準に準拠し続けることができます。さらに、人材トランスフォーメーションは継続的な学習の文化を育みます。これは、変化する医療状況に適応し、新たなパブリックヘルスの課題に対処するために不可欠です。クラスルームベースのトレーニングや静的学習モジュールなどの従来のトレーニングアプローチは、幅広い視聴者に統一されたコンテンツを提供します。多くの場合、個々の実務者の特定のニーズと習熟度に対処するために不可欠な、パーソナライズされた学習パスがありません。この one-size-fits-all戦略は、エンゲージメントを失い、知識保持が最適でなくなる可能性があります。
したがって、医療組織は、現在の状態と潜在的な将来の状態における各従業員のギャップを決定できる、画期的でスケーラブルなテクノロジー主導のソリューションを採用する必要があります。これらのソリューションは、ハイパーパーソナライズされた学習パスと適切な学習コンテンツのセットを推奨する必要があります。これにより、医療の未来に向けてワークフォースが効果的に準備されます。
ヘルスケア業界では、生成 AI を適用して、ワークフォースの理解とスキル向上に役立てることができます。大規模言語モデル (LLMs) と高度なリトリーバーを接続することで、組織は現在どのようなスキルを持っているかを理解し、将来必要になる可能性のある主要なスキルを特定できます。この情報は、新しいワーカーを雇用し、現在のワークフォースのスキルを向上させることで、ギャップを埋めるのに役立ちます。Amazon Bedrock とナレッジグラフを使用すると、医療組織は継続的な学習とスキル開発を容易にするドメイン固有のアプリケーションを開発できます。
このソリューションが提供する知識は、人材の効果的な管理、従業員のパフォーマンスの最適化、組織の成功の促進、既存のスキルの特定、人材戦略の策定に役立ちます。このソリューションは、数か月ではなく数週間でこれらのタスクを実行するのに役立ちます。
ソリューションの概要
このソリューションは、以下のコンポーネントで構成される医療人材変換フレームワークです。
-
インテリジェント再開パーサー – このコンポーネントは、候補の再開を読み取って、スキルを含む候補情報を正確に抽出できます。Amazon Bedrock で微調整された Llama 2 モデルを使用して構築されたインテリジェントな情報抽出ソリューションは、19 を超える業界の再開と人材プロファイルをカバーする独自のトレーニングデータセット上に構築されています。この LLM ベースのプロセスは、再開の手動レビュープロセスを自動化し、トップ候補をマッチングしてロールを開くことで、数百時間を節約します。
-
ナレッジグラフ – Amazon Neptune 上に構築されたナレッジグラフ。Amazon Neptune は、組織および業界の役割とスキルの分類を含む人材情報の統一されたリポジトリであり、スキル、役割とその特性、関係、論理的制約の定義を使用して医療人材のセマンティクスをキャプチャします。
-
スキルオントロジー – 候補スキルと理想的な現在の状態または将来の状態スキル (ナレッジグラフを使用して取得) の間のスキル近接性の発見は、候補スキルとターゲット状態スキルの間の意味論的類似性を測定するオントロジーアルゴリズムを通じて達成されます。
-
学習経路とコンテンツ – このコンポーネントは、特定されたスキルギャップに基づいて、任意のベンダーからの学習マテリアルのカタログから適切な学習コンテンツを推奨する学習レコメンデーションエンジンです。スキルギャップを分析し、優先順位付けされた学習コンテンツを推奨することで、各候補に最適なスキルアップパスを特定し、新しいロールへの移行中に各候補のシームレスで継続的な専門的な開発を可能にします。
このクラウドベースの自動化されたソリューションは、機械学習サービス、LLMs、ナレッジグラフ、検索拡張生成 (RAG) を利用しています。数十または数千の再開を最小限の時間で処理し、即時の候補プロファイルを作成し、現在または将来の状態のギャップを特定し、これらのギャップを埋めるために適切な学習コンテンツを効率的に推奨できます。
次の図は、フレームワークのend-to-endフローを示しています。このソリューションは、Amazon Bedrock の微調整された LLMs 上に構築されています。これらの LLMs、Amazon Neptune の医療人材ナレッジベースからデータを取得します。データ駆動型アルゴリズムは、候補ごとに最適な学習パスのレコメンデーションを行います。
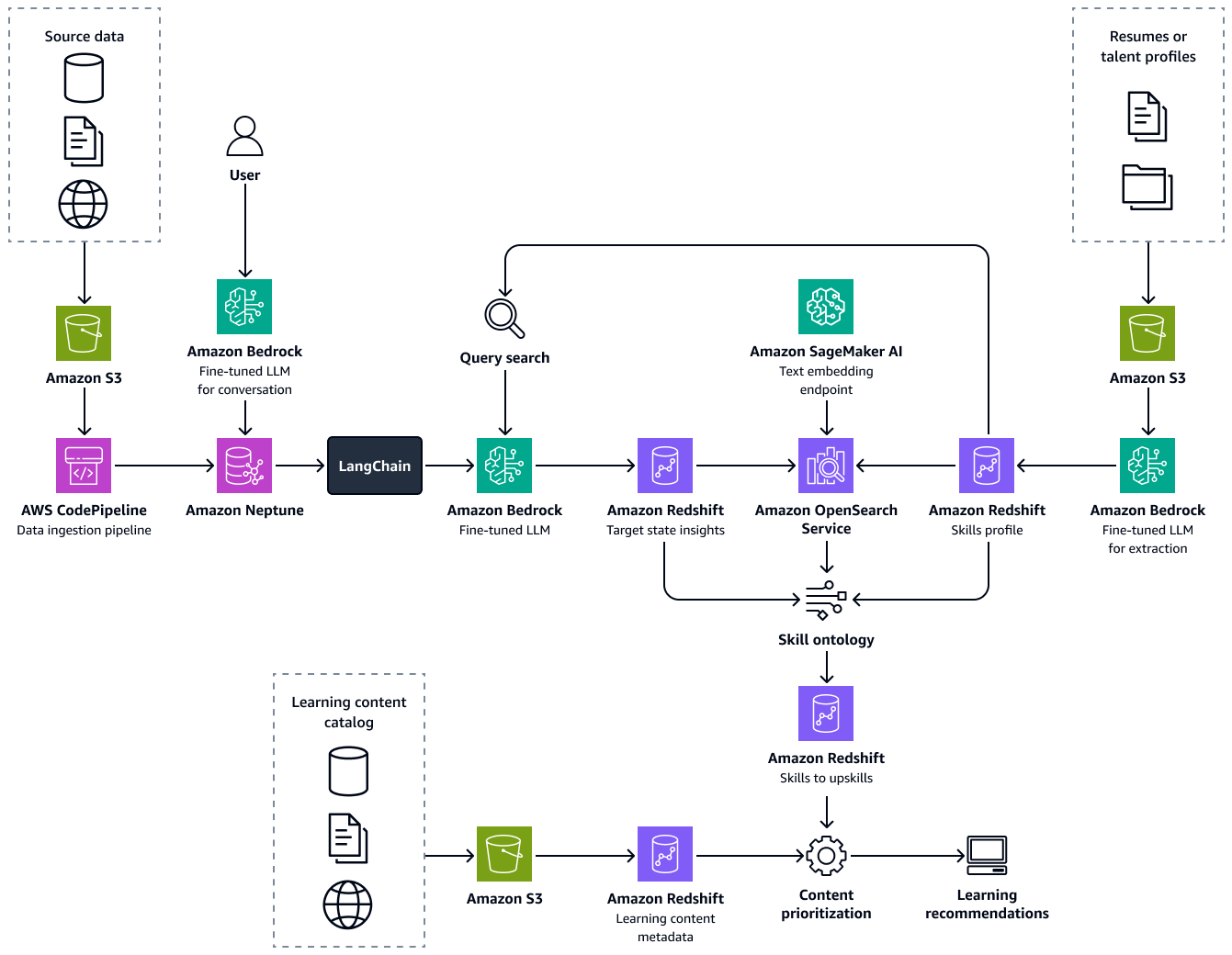
このソリューションの構築は、次のステップで構成されます。
ステップ 1: 人材情報を抽出し、スキルプロファイルを構築する
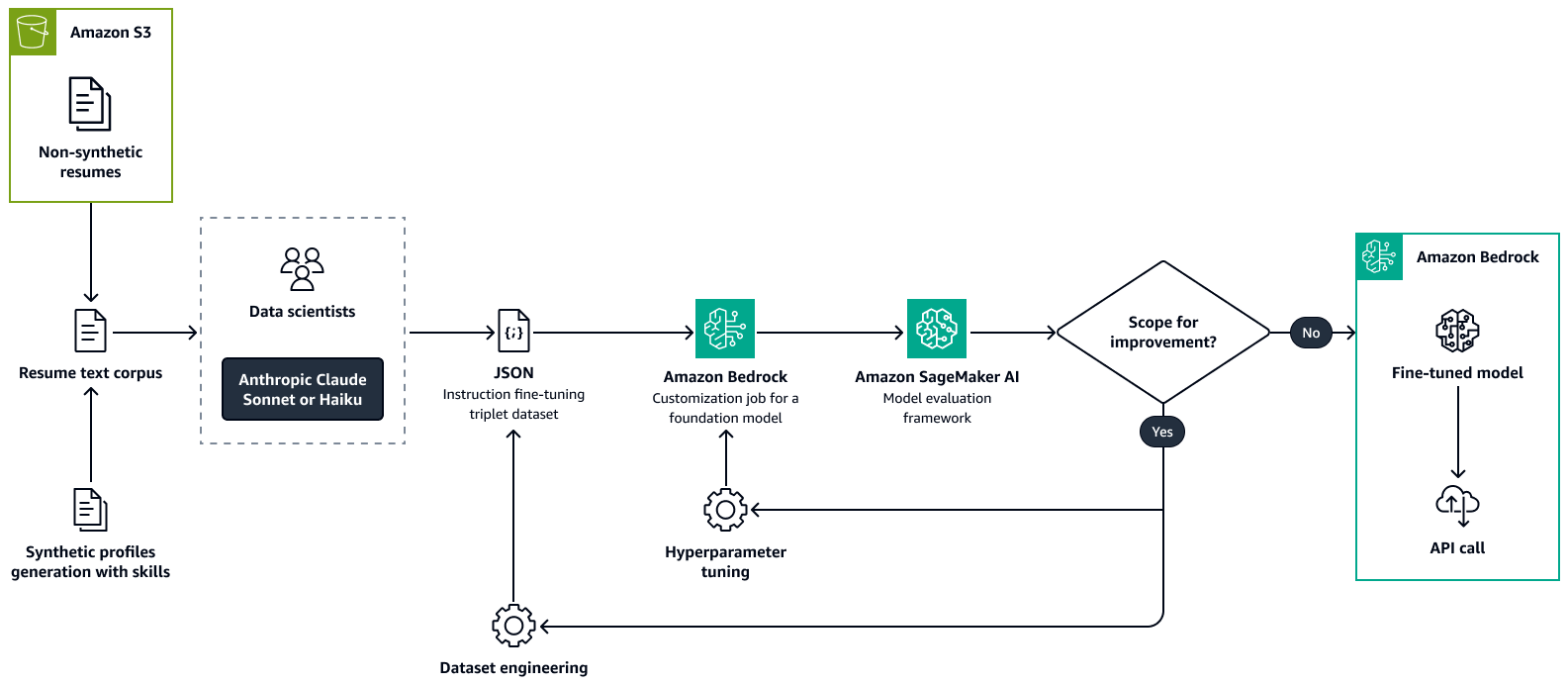
まず、カスタムデータセットを使用して Amazon Bedrock で Llama 2 などの大規模言語モデルを微調整します。これにより、LLM がユースケースに適応します。トレーニング中、候補者の職務再開や同様の人材プロファイルから主要な人材属性を正確かつ一貫して抽出します。これらの人材属性には、スキル、現在のロールタイトル、日付スパンを含む経験タイトル、教育、認定が含まれます。詳細については、Amazon Bedrock ドキュメントの「モデルをカスタマイズしてユースケースのパフォーマンスを向上させる」を参照してください。
次の図は、Amazon Bedrock を使用して再開解析モデルを微調整するプロセスを示しています。キー情報を抽出するために、実際の再開と合成で作成された再開の両方が LLM に渡されます。データサイエンティストのグループは、抽出された情報を元の未加工テキストと照合します。次に、chain-of-thought
ステップ 2: ナレッジグラフからrole-to-skillの関連性を検出する
次に、組織およびヘルスケア業界の他の組織のスキルと役割の分類をカプセル化するナレッジグラフを作成します。この強化されたナレッジベースは、Amazon Redshift の集計された人材と組織データから取得されます。さまざまな労働市場データプロバイダーや、エンタープライズリソースプランニング (ERP) システム、人事情報システム (HRIS)、従業員の職務再開、職務記述書、人材アーキテクチャドキュメントなど、組織固有の構造化および非構造化データソースから人材データを収集できます。
Amazon Neptune でナレッジグラフを構築します。ノードはスキルとロールを表し、エッジはそれらの関係を表します。このグラフにメタデータを追加して、組織名、業界、ジョブファミリー、スキルタイプ、ロールタイプ、業界タグなどの詳細を含めます。
次に、Graph Retrieval Augmented Generation (Graph RAG) アプリケーションを開発します。Graph RAG は、グラフデータベースからデータを取得する RAG アプローチです。Graph RAG アプリケーションのコンポーネントは次のとおりです。
-
Amazon Bedrock での LLM との統合 – アプリケーションは、自然言語の理解とクエリ生成のために Amazon Bedrock の LLM を使用します。ユーザーは自然言語を使用してシステムとやり取りできます。これにより、技術系以外の利害関係者がアクセスできるようになります。
-
オーケストレーションと情報の取得 – LlamaIndex
またはLangChain オーケストレーターを使用して、LLM と Neptune ナレッジグラフの統合を容易にします。自然言語クエリを openCypher クエリに変換するプロセスを管理します。次に、ナレッジグラフでクエリを実行します。プロンプトエンジニアリングを使用して、openCypher クエリを構築するためのベストプラクティスについて LLM に指示します。これにより、クエリを最適化して関連するサブグラフを取得します。サブグラフには、クエリされたロールとスキルに関連するすべてのエンティティと関係が含まれます。 -
インサイトの生成 – Amazon Bedrock の LLM は、取得したグラフデータを処理します。現在の状態に関する詳細なインサイトを生成し、クエリされたロールと関連するスキルの将来の状態を予測します。
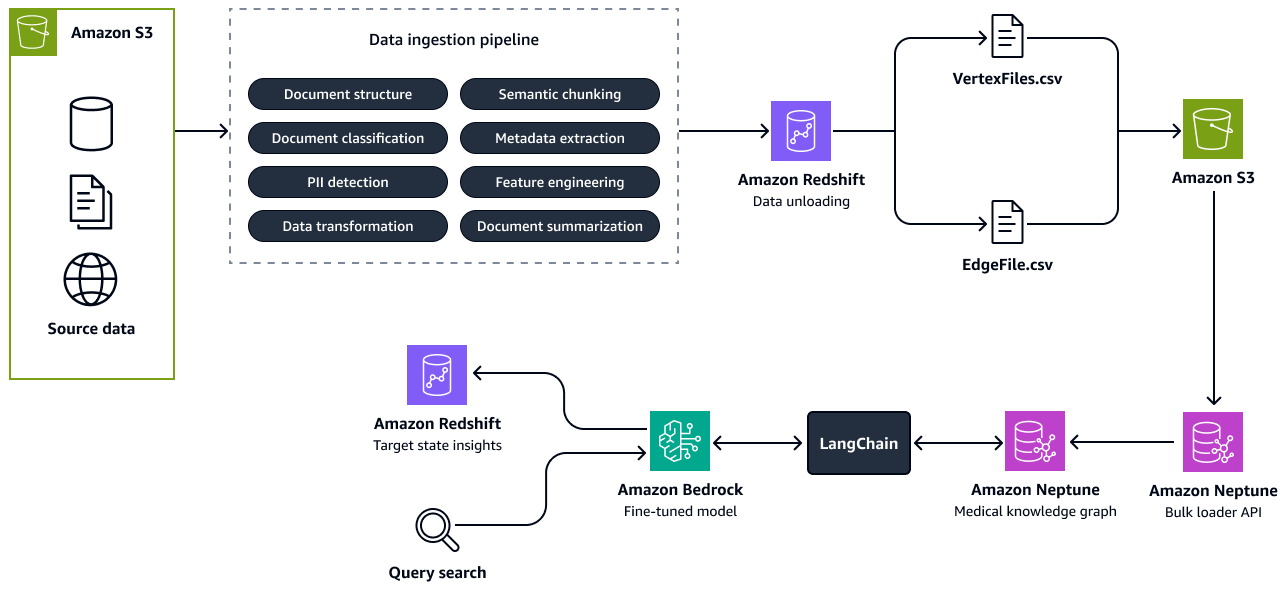
次の図は、ソースデータからナレッジグラフを構築するステップを示しています。構造化ソースデータと非構造化ソースデータをデータ取り込みパイプラインに渡します。パイプラインは、Amazon Neptune と互換性のある CSV 一括ロードフォーメーションに情報を抽出して変換します。バルクローダー API は、Amazon S3 バケットに保存されている CSV ファイルを Neptune ナレッジグラフにアップロードします。人材の将来の状態、関連するロール、スキルに関連するユーザークエリの場合、Amazon Bedrock の微調整された LLM はLangChainオーケストレーターを介してナレッジグラフとやり取りします。オーケストレーターは、ナレッジグラフから関連するコンテキストを取得し、Amazon Redshift のインサイトテーブルにレスポンスをプッシュします。LangChain オーケストレーターは、GraphQAChain
ステップ 3: スキルギャップの特定とトレーニングの推奨
このステップでは、医療専門家の現在の状態と将来の潜在的な状態の役割の間の近接性を正確に計算します。これを行うには、個人のスキルセットをジョブロールと比較することで、スキルアフィニティ分析を実行します。Amazon OpenSearch Service ベクトルデータベースには、スキルの説明、スキルタイプ、スキルクラスターなどのスキル分類情報とスキルメタデータを保存します。Amazon Titan Text Embeddings モデルなどの Amazon Bedrock 埋め込みモデルを使用して、識別されたキースキルをベクトルに埋め込みます。ベクトル検索を使用して、現在の状態スキルとターゲット状態スキルの説明を取得し、オントロジー分析を実行します。この分析は、現在の状態とターゲット状態のスキルペア間の近接スコアを提供します。ペアごとに、計算されたオントロジースコアを使用して、スキルアフィニティのギャップを特定します。次に、スキル向上に最適な方法をお勧めします。これは、ロールの移行中に候補が検討できます。
各ロールについて、スキルアップや再スキルのために正しい学習コンテンツを推奨するには、学習コンテンツの包括的なカタログの作成から始まる体系的なアプローチが必要です。このカタログは Amazon Redshift データベースに保存され、さまざまなプロバイダーのコンテンツを集約し、コンテンツ期間、難易度、学習モードなどのメタデータが含まれます。次のステップでは、各コンテンツが提供する主要なスキルを抽出し、ターゲットロールに必要な個々のスキルにマッピングします。このマッピングを実現するには、スキル近接性分析を通じてコンテンツによって提供されるカバレッジを分析します。この分析では、コンテンツによって教えられたスキルが、ロールに必要なスキルとどの程度一致しているかを評価します。メタデータは、各スキルに最適なコンテンツを選択する上で重要な役割を果たし、学習者が学習ニーズに合ったカスタマイズされたレコメンデーションを確実に受け取るようにします。Amazon Bedrock LLMs を使用して、コンテンツメタデータからスキルを抽出し、特徴量エンジニアリングを実行し、コンテンツのレコメンデーションを検証します。これにより、スキルアップまたは再スキルプロセスの精度と関連性が向上します。
AWS Well-Architected フレームワークへの調整
このソリューションは、AWS Well-Architected フレームワーク
-
運用上の優秀性 – モジュール式の自動化されたパイプラインにより、運用上の優秀性が向上します。パイプラインの主要なコンポーネントは分離および自動化されるため、モデルの更新が迅速になり、モニタリングが容易になります。さらに、自動トレーニングパイプラインは、微調整されたモデルのより迅速なリリースをサポートします。
-
セキュリティ – このソリューションは、再開時のデータや人材プロファイルなど、機密性の高い個人を特定できる情報 (PII) を処理します。AWS Identity and Access Management (IAM) で、きめ細かなアクセスコントロールポリシーを実装し、承認された担当者のみがこのデータにアクセスできることを確認します。
-
信頼性 – このソリューションは、Neptune AWS のサービス、Amazon Bedrock、OpenSearch Service などの を使用して、高需要時でも耐障害性、高可用性、インサイトへの中断のないアクセスを提供します。
-
パフォーマンス効率 – Amazon Bedrock および OpenSearch Service ベクトルデータベースの微調整された LLMs は、大規模データセットを迅速かつ正確に処理して、パーソナライズされた学習に関する推奨事項をタイムリーに提供できるように設計されています。
-
コスト最適化 – このソリューションは RAG アプローチを使用するため、モデルの継続的な事前トレーニングの必要性が軽減されます。モデル全体を繰り返しファインチューニングする代わりに、システムは再開からの情報の抽出や出力の構造化など、特定のプロセスのみをファインチューニングします。これにより、大幅なコスト削減につながります。リソースを大量に消費するモデルトレーニングの頻度と規模を最小限に抑え、pay-per-useクラウドサービスを使用することで、医療組織は高いパフォーマンスを維持しながら運用コストを最適化できます。
-
持続可能性 – このソリューションは、コンピューティングリソースを動的に割り当てるスケーラブルなクラウドネイティブサービスを使用します。これにより、大規模なデータ集約型の人材変革イニシアチブをサポートしながら、エネルギー消費と環境への影響を軽減できます。
