翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
アーキテクチャ
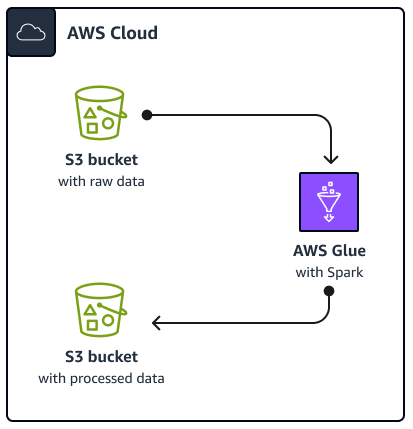
次の図は、このガイドで説明されているソリューションのアーキテクチャを示しています。 AWS Glue ジョブは、Amazon Simple Storage Service (Amazon S3) バケットからデータを読み取ります。バケットは、データの保存、保護、取得に役立つクラウドベースのオブジェクトストレージサービスです。ジョブは AWS Glue Spark SQL AWS Management Console、、 AWS Command Line Interface (AWS CLI)、または AWS Glue API を使用して開始できます。ジョブは、Amazon AWS Glue Spark SQLS3 バケット内の raw データを処理し、処理されたデータを別のバケットに保存します。 Amazon S3
例として、このガイドでは、 Pythonと Spark SQL () で記述された基本的なAWS GlueSpark SQLジョブについて説明しますPySpark。この AWS Glue ジョブは、Spark SQLチューニングのベストプラクティスを示すために使用されます。このガイドでは に焦点を当てていますが AWS Glue、このガイドのベストプラクティスは Amazon EMR Spark SQLジョブにも適用されます。
次の図は、Spark SQLクエリのライフサイクルを示しています。Spark SQL Catalyst Optimizer はクエリプランを生成します。クエリプランは、SQL リレーショナルデータベースシステムのデータにアクセスするために使用する手順などの一連のステップです。パフォーマンス最適化Spark SQLクエリプランを開発するには、まずEXPLAINプランを表示し、プランを解釈してから、プランを調整します。Spark SQL ユーザーインターフェイス (UI) またはSpark SQL履歴サーバーを使用して、プランを視覚化できます。
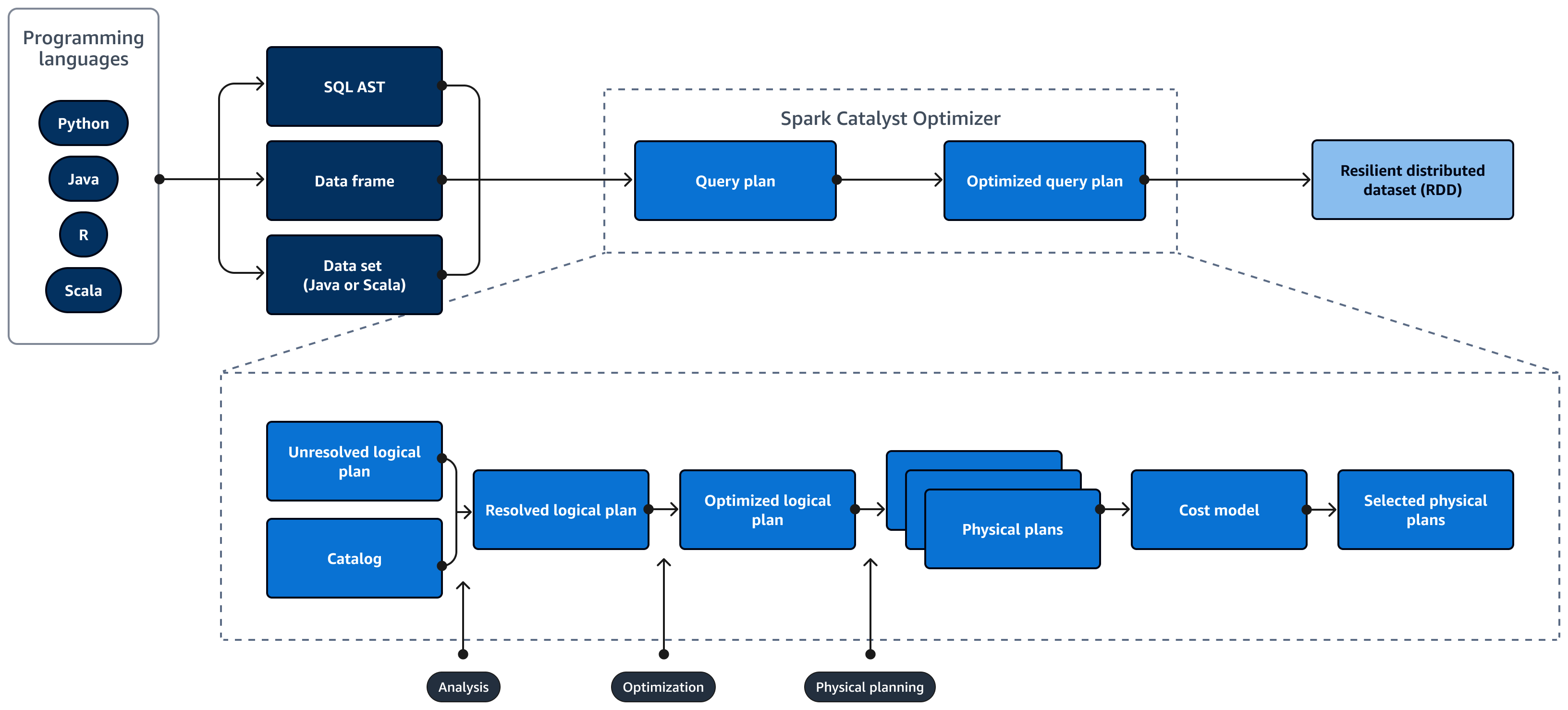
Spark Catalyst Optimizer は、次のように初期クエリプランを最適化されたクエリプランに変換します。
-
分析と宣言 APIs – 分析フェーズが最初のステップです。SQL クエリで参照されるオブジェクトが不明であるか、入力テーブルと一致していない未解決の論理プランは、バインドされていない属性とデータ型で生成されます。次に、Spark SQLCatalyst Optimizer は一連のルールを適用して論理プランを構築します。SQL パーサーは SQL Abstract Syntax Tree (AST) を生成し、これを論理プランの入力として提供できます。入力は、API を使用して構築されたデータフレームまたはデータセットオブジェクトである場合もあります。次の表は、SQL、データフレーム、またはデータセットを使用するタイミングを示しています。
SQL データフレーム データセット 構文エラー ランタイム コンパイル時間 コンパイル時間 分析エラー ランタイム ランタイム コンパイル時間 入力のタイプの詳細については、以下を参照してください。
-
データセット API は型付きバージョンを提供します。これにより、ユーザー定義の Lambda 関数に大きく依存するため、パフォーマンスが低下します。RDD またはデータセットは静的に型付けされます。たとえば、RDD を定義する場合は、スキーマ定義を明示的に指定する必要があります。
-
データフレーム API は、型のないリレーショナルオペレーションを提供します。データフレームは動的に入力されます。RDD と同様に、データフレームを定義すると、スキーマは同じままになります。データは構造化されたままです。ただし、この情報は実行時にのみ使用できます。これにより、コンパイラは SQL のようなステートメントを記述し、新しい列をその場で定義できます。たとえば、オペレーションごとに新しいクラスを定義することなく、既存のデータフレームに列を追加できます。
-
Spark SQL クエリはランタイム中に構文エラーと分析エラーについて評価されるため、ランタイムが高速化されます。
-
-
カタログ – Spark SQL は、データベース、テーブル、列、パーティションなどの永続的なリレーショナルエンティティのメタデータを管理するApache Hive Metastore (HMS)ために を使用します。
-
最適化 — オプティマイザはヒューリスティックとコストを使用してクエリプランを書き換えます。最適化された論理プランを作成するには、以下を実行します。
-
列のプルーニング
-
述語をプッシュダウンする
-
結合の順序を変更する
-
-
物理プランとプランナー – Spark SQL Catalyst Optimizer は論理プランを一連の物理プランに変換します。つまり、 の内容を変換します。
-
選択した物理プラン – Spark SQL Catalyst Optimizer は、最も費用対効果の高い物理プランを選択します。
-
最適化クエリプラン – パフォーマンス最適化およびコスト最適化クエリプランSpark SQLを実行します。 Spark SQLMemory Management は、メモリ使用量を追跡し、タスクとオペレータ間でメモリを分散します。Spark SQL Tungsten エンジンは、Spark SQLアプリケーションのメモリと CPU 効率を大幅に向上させることができます。また、バイナリデータモデル処理を実装し、バイナリデータに対して直接動作します。これにより、逆シリアル化の必要性が回避され、データ変換と逆シリアル化に関連するオーバーヘッドが大幅に削減されます。
