翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
ソリューションの概要
スケーラブルな ML フレームワーク
何百万人もの顧客が複数の事業部門に分散している企業でビジネス価値を引き出すためには、ML ワークフローで、サイロ化されたチームが所有および管理するデータを、さまざまなツールを使用して統合する必要があります。銀行は顧客データの保護に力を入れています。同様に、ML モデルの開発で使用するインフラストラクチャにも、高いセキュリティ基準が適用されます。このようなセキュリティ強化によってさらに複雑さが増し、新しい ML モデルのタイムトゥバリューに影響します。スケーラブルな ML フレームワークでは、最新の標準化されたツールセットを使用することで、さまざまなツールを組み合わせる手間が省け、新しい ML モデルの運用開始までのプロセスを簡素化できます。
従来、FS 業界におけるデータサイエンス活動の管理とサポートは、組織全体のデータチームの要件収集、リソースの提供、インフラストラクチャの維持を行う中央プラットフォームチームによって管理されています。組織全体の連合チームで ML の利用を迅速にスケールするために、スケーラブルな ML フレームワークを使用すれば、新しいモデルやパイプラインの開発者にセルフサービス機能を提供できます。これにより、開発者は事前に承認され、標準化された最新の安全なインフラストラクチャをデプロイできます。最終的には、このようなセルフサービス機能により、組織は一元化されたプラットフォームチームへの依存を減らし、ML モデル開発のタイムトゥバリューを短縮できます。
スケーラブルな ML フレームワークにより、データコンシューマー (データサイエンティストや ML エンジニアなど) が以下をできるようになることで、ビジネス価値を引き出すことができます。
モデルトレーニングに必要な、事前に承認されたデータを参照して見つける
事前に承認されたデータにすばやく簡単にアクセスできる
事前に承認されたデータを使用してモデルの実行可能性を証明する
実証済みのモデルを本番稼働環境にリリースし、他のユーザーが使用できるようにする
次の図は、フレームワークのエンドツーエンドのフローと、ML ユースケースの運用開始までの簡略化されたルートを示しています。
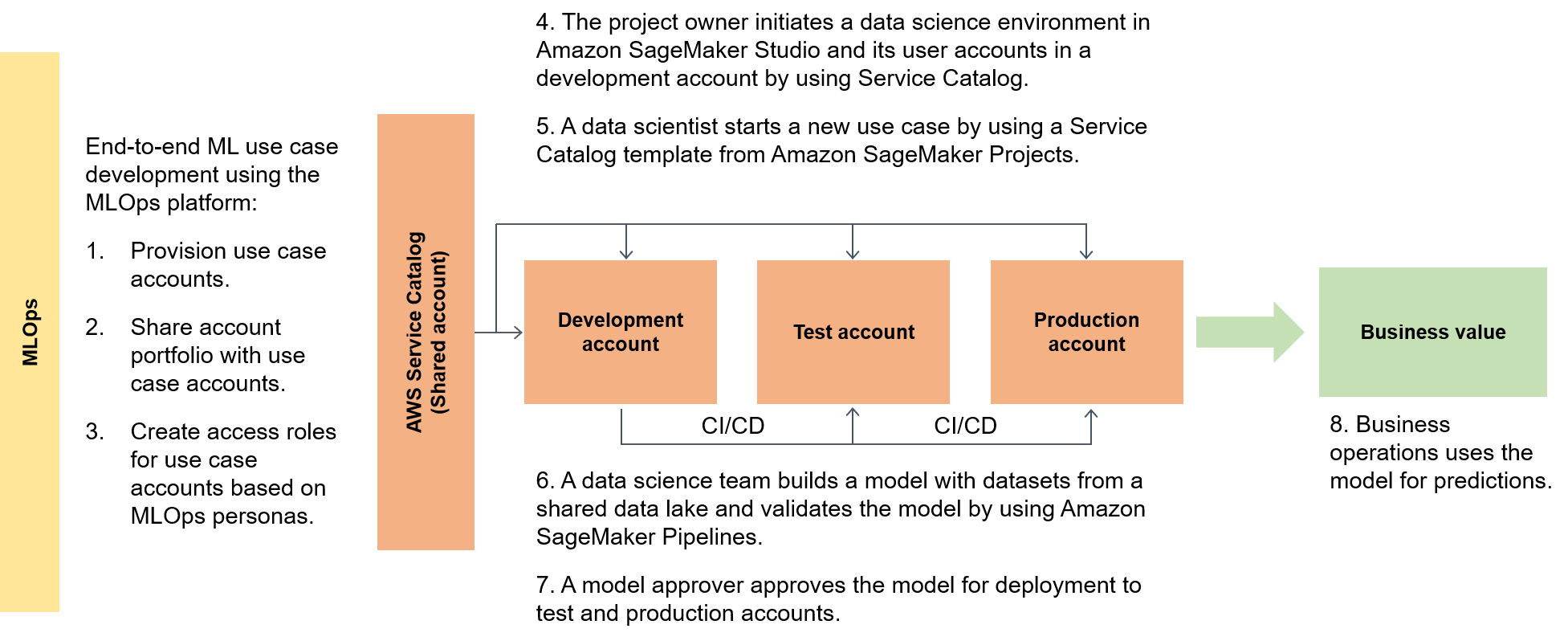
広い意味では、データコンシューマーは data.all と呼ばれるサーバーレスアクセラレーターを使用して複数のデータレイクにまたがるデータを調達し、そのデータを使用してモデルをトレーニングします。これを次の図に示します。
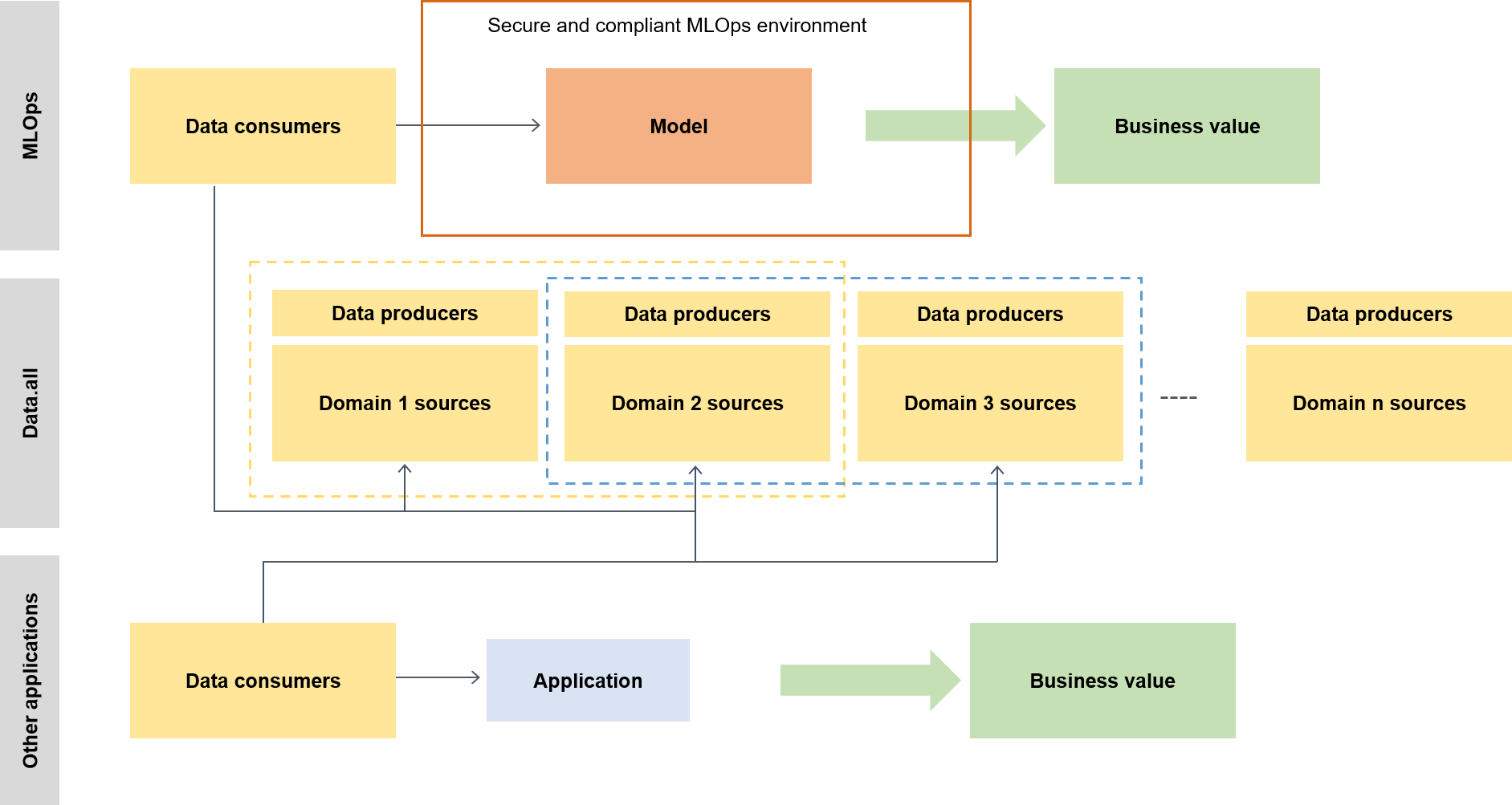
下位レベルでは、スケーラブルな ML フレームワークには次のものが含まれます。
セルフサービスインフラストラクチャのデプロイ — 一元化されたチームへの依存を軽減します。
中央の Python パッケージ管理システム — 事前に承認された Python パッケージをモデル開発に使用できるようにします。
モデル開発とプロモーションのための CI/CD パイプライン — 継続的インテグレーションと継続的 (CI/CD) パイプラインをInfrastructure as Code (IaC) テンプレートの一部として組み込むことで、稼働までの時間を短縮します。
モデルテスト機能 — 新しいモデルで自動的に利用できるユニットテスト、モデルテスト、インテグレーションテスト、エンドツーエンドテストの機能を活用できます。
モデルのデカップリングとオーケストレーション – Amazon Amazon SageMaker AI Pipelines
を使用して、計算リソースの要件とさまざまなステップのオーケストレーションに従ってモデルステップをデカップリングすることで、不要なコンピューティングを回避し、デプロイをより堅牢にします。 コード標準化 — Python Enhancement Proposal (PEP 8)
の標準を検証するために、CI/CD パイプライン統合を使用してコードの品質向上を図ります。 汎用 ML テンプレートのクイックスタート – デプロイに SageMaker AI プロジェクトを使用して、ボタンをクリックするだけで ML モデリング環境 (開発、本番前、本番稼働) と関連するパイプラインをインスタンス化する Service Catalog テンプレートを取得します。
データ品質とモデル品質のモニタリング – Amazon SageMaker AI Model Monitor を使用してデータとモデル品質のドリフトを自動的にモニタリングすることで、モデルが運用要件を満たし、リスク許容レベル内で動作することを確認します。
バイアスモニタリング — データの不均衡や、世界の変化によってモデルにバイアスが生じていないかを自動的にチェックすることで、モデル所有者が公正かつ公平な意思決定を行えるようにします。
メタデータの中央ハブ
data.all
SageMaker 検証
さまざまなデータ処理と ML アーキテクチャにわたって SageMaker AI の機能を証明するために、機能を実装するチームは、銀行リーダーシップチームとともに、銀行の顧客のさまざまな部門からさまざまな複雑さのユースケースを選択します。ユースケースデータは難読化され、機能検証フェーズのユースケース開発アカウントのローカル Amazon Simple Storage Service (Amazon S3)
元のトレーニング環境から SageMaker AI アーキテクチャへのモデル移行が完了すると、クラウドホストデータレイクは、本番モデルによるデータの読み取りを可能にします。本番モデルによって生成された予測は、データレイクに書き戻されます。
候補となるユースケースが移行されると、スケーラブルな ML フレームワークがターゲットメトリクスの初期ベースラインを作成します。スケーラブルな ML フレームワークによって時間短縮が可能になったことの証拠として、ベースラインを過去のオンプレミスや他のクラウドプロバイダーのタイミングと比較できます。
