Amazon Redshift は、2025 年 11 月 1 日以降、新しい Python UDF の作成をサポートしなくなります。Python UDF を使用する場合は、その日付より前に UDF を作成してください。既存の Python UDF は引き続き通常どおり機能します。詳細については、ブログ記事
Amazon Redshift Serverless データウェアハウスの使用を開始
Amazon Redshift Serverless を初めて使用する場合、次のセクションをお読みになって Amazon Redshift Serverless の使用開始の参考にすることをお勧めします。Amazon Redshift Serverless の基本的な流れは、サーバーレスリソースの作成、Amazon Redshift Serverless への接続、サンプルデータのロード、データに対するクエリの実行です。このガイドでは、Amazon Redshift Serverless から、または Amazon S3 バケットからサンプルデータのロードを選択できます。サンプルデータは、Amazon Redshift ドキュメント全体で機能を実証するために使用されます。Amazon Redshift でプロビジョニングされたデータウェアハウスの使用を開始するには、「Amazon Redshift でプロビジョニングされたデータウェアハウスの使用を開始する」を参照してください。
AWS へのサインアップ
まだ AWS アカウントをお持ちでない場合は、サインアップを行います。すでにアカウントをお持ちの場合は、この前提条件をスキップして既存のアカウントを使用します。
オンラインの手順に従います。
AWS アカウントにサインアップすると、AWS アカウントのルートユーザーが作成されます。ルートユーザーは、アカウントのすべての AWS サービスとリソースにアクセスできます。セキュリティのベストプラクティスとして、管理ユーザーに管理アクセスを割り当て、ルートユーザーのみを使用してルートユーザーアクセスが必要なタスクを実行してください。
Amazon Redshift Serverless によるデータウェアハウスの作成
Amazon Redshift Serverless コンソールに初めてログインすると、サーバーレスリソースの作成と管理に使用できる、入門エクスペリエンスにアクセスするように求められます。このガイドでは、Amazon Redshift Serverless のデフォルト設定を使用してサーバーレスリソースを作成します。
設定をより細かく制御するには、[Customize settings] (設定をカスタマイズ) を選択します。
注記
Redshift Serverless には、3 つの異なるアベイラビリティーゾーンに 3 つのサブネットを持つ Amazon VPC が必要です。Redshift Serverless には、少なくとも 3 個の使用可能な IP アドレスも必要です。Redshift Serverless で Amazon VPC を使用する前に、3 つの異なるアベイラビリティーゾーンに 3 つのサブネットがあり、少なくとも 3 個の使用可能な IP アドレスがあることを確認してください。Amazon VPC のサブネットを作成する方法の詳細については、「Amazon Virtual Private Cloud ユーザーガイド」の「サブネットの作成」を参照してください。Amazon VPC の IP アドレスの詳細については、「VPC とサブネットの IP アドレス指定」を参照してください。
デフォルト設定で設定するには:
AWS Management Console にサインインして、https://console.aws.amazon.com/redshiftv2/
で Amazon Redshift コンソールを開きます。 [Redshift Serverless の無料トライアルをお試しください] を選択します。
-
[Configuration] (設定) で、[Use default settings] (デフォルト設定を使用) を選択します。Amazon Redshift Serverless は、デフォルトの名前空間と、この名前空間に関連するデフォルトのワークグループを作成します。[設定の保存] を選択します。
注記
名前空間は、データベースオブジェクトとユーザーのコレクションです。名前空間は、スキーマ、テーブル、ユーザー、データ共有、スナップショットなど、Redshift Serverless で使用するすべてのリソースをグループ化します。
ワークグループは、コンピューティングリソースのコレクションです。ワークグループには、Redshift Serverless が計算タスクを実行するために使用するコンピューティングリソースが含まれます。
次のスクリーンショットは、Amazon Redshift Serverless のデフォルト設定を示しています。

-
セットアップが完了したら、[続行] を選択し、[サーバーレスダッシュボード] に移動します。サーバーレスワークグループと名前空間が使用可能であることがわかります。
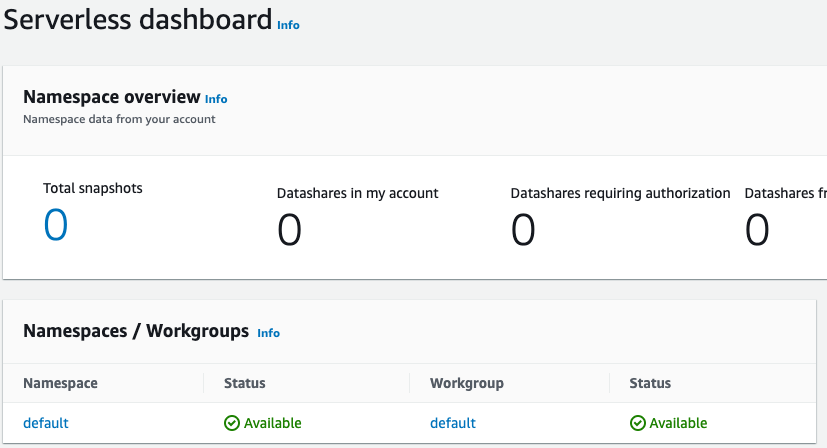
注記
Redshift Serverless がワークグループを正常に作成しない場合は、次の操作を実行できます。
Amazon VPC 内のサブネット数が少なすぎるなど、Redshift Serverless が報告するすべてのエラーに対処します。
Redshift Serverless ダッシュボードで [default-namespace]、[アクション]、[名前空間を削除] の順に選択して名前空間を削除します。名前空間の削除には数分かかります。
Redshift Serverless コンソールを再度開くと、ウェルカム画面が表示されます。
サンプルデータをロードする
Amazon Redshift Serverless でデータウェアハウスをセットアップしたので、Amazon Redshift クエリエディタ v2 を使用してサンプルデータをロードできます。
-
Amazon Redshift Serverless コンソールからクエリエディタ v2 を起動するには、[データをクエリ] を選択します。Amazon Redshift Serverless コンソールで クエリエディタ v2 を呼び出すと、ブラウザ上に新しいタブが開きクエリーエディタが表示されます。クエリエディタ v2 により、クライアントマシンから Amazon Redshift Serverless 環境に接続されます。
![Amazon Redshift Serverless コンソールの [データをクエリ] ボタンにより、クエリエディタ v2 が起動します。](images/serverless-query-data-button.png)
-
このガイドでは、AWS 管理者アカウントとデフォルトの AWS KMS keyを使用します。Amazon Redshift クエリエディタ v2 の設定 (必要なアクセス許可など) については、「Amazon Redshift 管理ガイド」の「AWS アカウント の設定」を参照してください。カスタマーマネージドキーを使用するように Amazon Redshift を設定する方法、または Amazon Redshift で使用する KMS キーを変更する方法については、「名前空間の AWS KMS キーの変更」を参照してください。
-
ワークグループに接続するには、ツリービューパネルでワークグループ名を選択します。
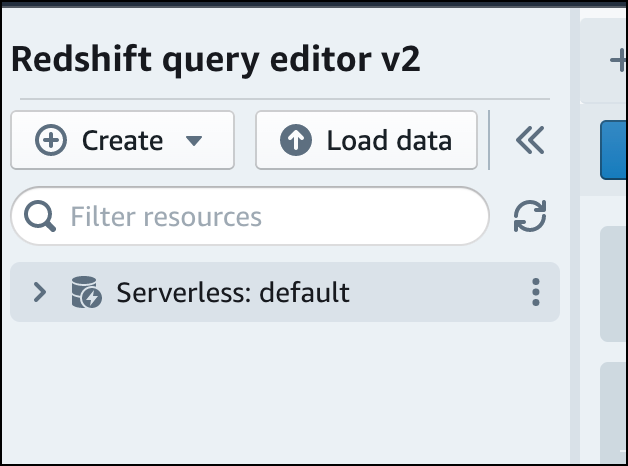
-
クエリエディタ v2 で初めて新しいワークグループに接続するときは、ワークグループへの接続に使用する認証タイプを選択する必要があります。このガイドでは、[フェデレーションユーザー] を選択したままにして、[接続の作成] を選択します。
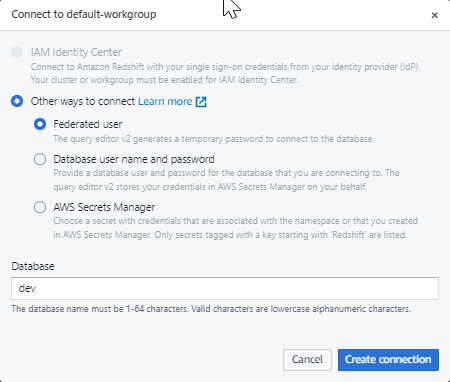
接続したら、Amazon Redshift Serverless から、または Amazon S3 バケットからサンプルデータのロードを選択できます。
-
Amazon Redshift サーバーレスのデフォルトワークグループで、sample_data_dev データベースを展開します。3 つのサンプルデータセットに対応する 3 つのサンプルスキーマがあり、これらを Amazon Redshift Serverless データベース内にロードできます。ロードするサンプルデータセットを選択して、[サンプルノートブックを開く] を選択します。
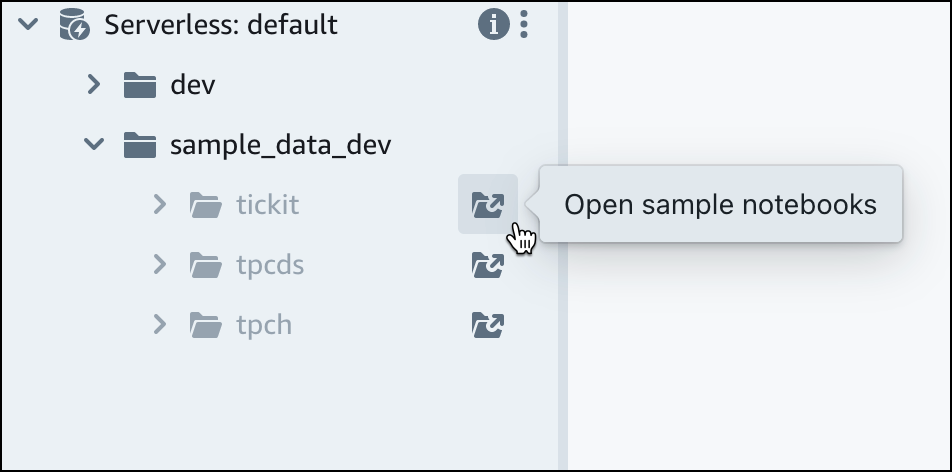
注記
SQL ノートブックは、SQL セルと Markdown セルのコンテナです。ノートブックを使用して、複数の SQL コマンドを 1 つのドキュメントにまとめて、注釈を付け、共有することができます。
-
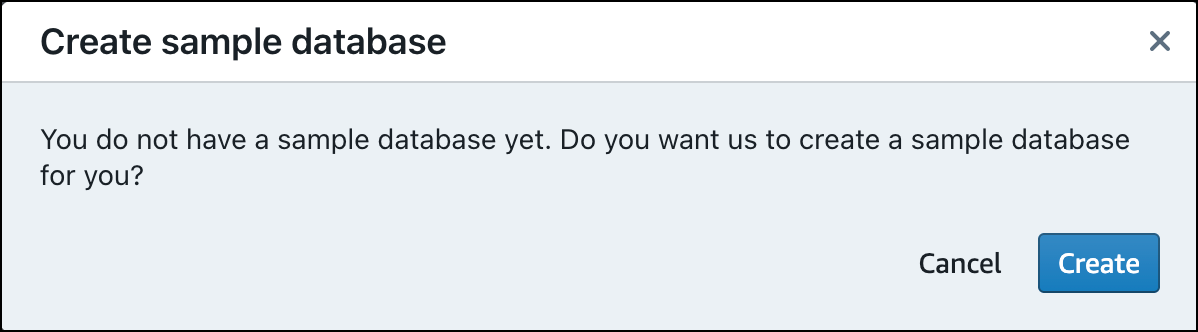
初めてデータをロードするとき、クエリエディタ v2 からサンプルデータベースを作成するように促しされます。[作成] を選択します。
サンプルクエリの実行
Amazon Redshift Serverless をセットアップすると、Amazon Redshift Serverless 内のサンプルデータセットの使用を開始できます。Amazon Redshift Serverless は tickit データセットなどのサンプルデータセットを自動的にロードし、直ちにデータをクエリすることができます。
-
Amazon Redshift Serverless がサンプルデータのロードを完了すると、すべてのサンプルクエリがエディタにロードされます。[すべて実行] を選択すると、サンプルノートブックのクエリをすべて実行できます。
![[すべて実行] ボタンを選択して、すべてのサンプルクエリを実行します。](images/serverless-running-sample-notebook.png)
結果を JSON または CSV ファイルとしてエクスポートしたり、結果をグラフで表示したりすることもできます。
![クエリエディタ v2 の [グラフビュー] ボタンの横にある [エクスポート] ボタン。](images/serverless-export-or-chart.png)
Amazon S3 バケットからデータをロードすることもできます。詳細については、「Amazon S3 からデータをロードする」を参照してください。
Amazon S3 からデータをロードする
データウェアハウスを作成すると、Amazon S3 からデータをロードできます。
この時点で、dev という名前のデータベースがあります。次に、このデータベースにいくつかのテーブルを作成し、テーブルにデータをアップロードして、クエリを実行してみます。すぐにロードして使えるサンプルデータを Amazon S3 バケットに用意しました。
-
Amazon S3 からデータをロードする前に、必要な権限を持つ IAM ロールを作成し、それをサーバーレス名前空間にアタッチする必要があります。これを行うには、Redshift Serverless コンソールに戻り、[名前空間設定] を選択します。ナビゲーションメニューから [名前空間] を選択して、[セキュリティと暗号化] を選択します。次に、[IAM ロールの管理] を選択します。
![名前空間の設定ページから、[セキュリティと暗号化] を選択してから、[IAM ロールを管理] を選択します。](images/serverless-namespace-configuration.png)
[IAM ロールを管理] メニューを展開して、[IAM ロールの作成] を選択します。
![[IAM ロールを管理] メニューを展開して、[IAM ロールの作成] を選択します。](images/serverless-manage-iam-role.png)
このロールに付与する S3 バケットアクセスのレベルを選択して、[デフォルトとして IAM ロールを作成する] を選択します。
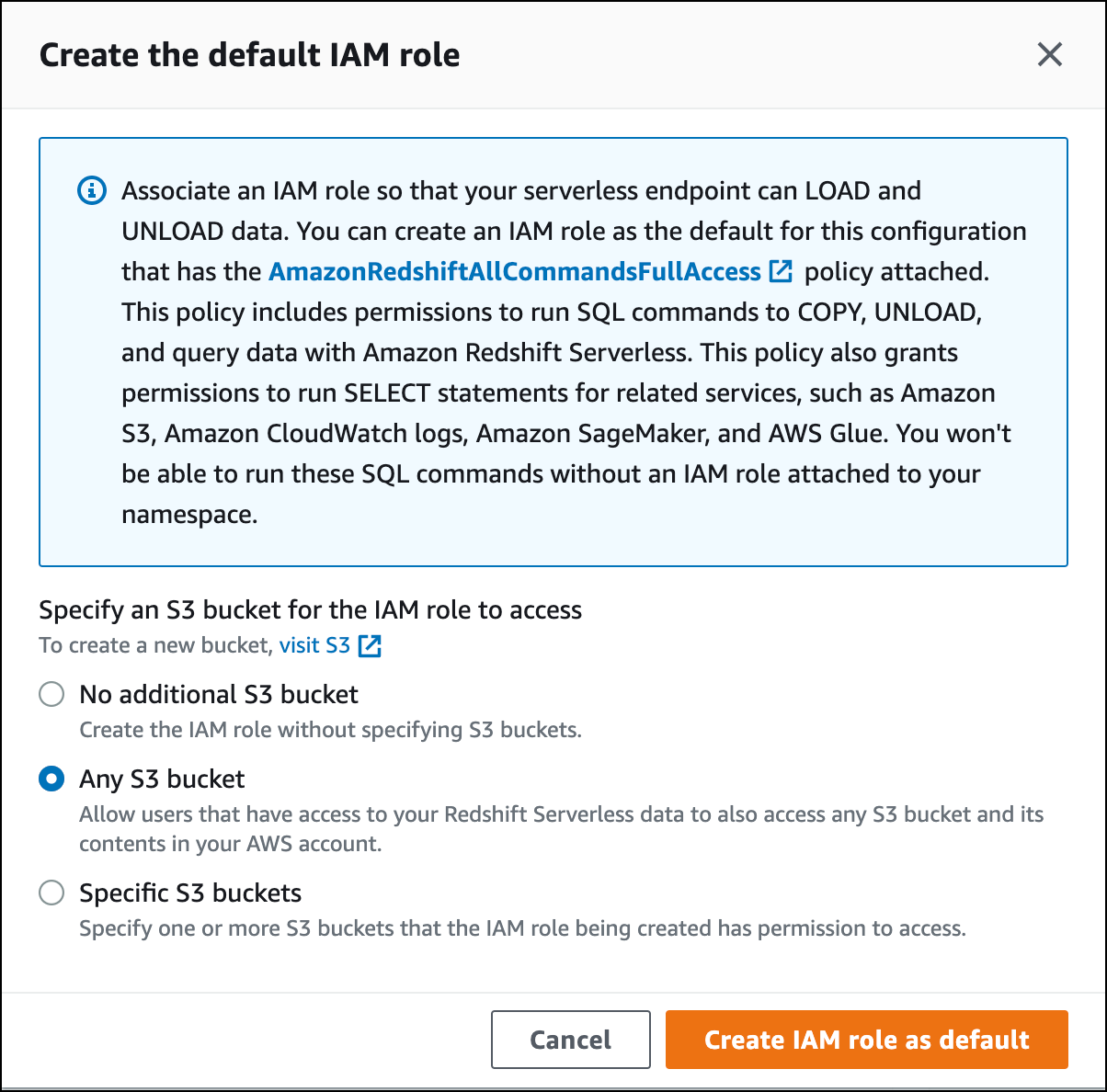
-
[変更を保存] をクリックします。これで Amazon S3 のサンプルデータをロードできるようになりました。
以下の手順ではパブリック Amazon Redshift S3 バケット内のデータを使用しますが、自分の S3 バケットと SQL コマンドを使用して同じ手順を再現することができます。
Amazon S3 からサンプルデータをロードする
-
クエリエディタ v2 で、[
 追加] を選択してから、[ノートブック] を選択して新しい SQL ノートブックを作成します。
追加] を選択してから、[ノートブック] を選択して新しい SQL ノートブックを作成します。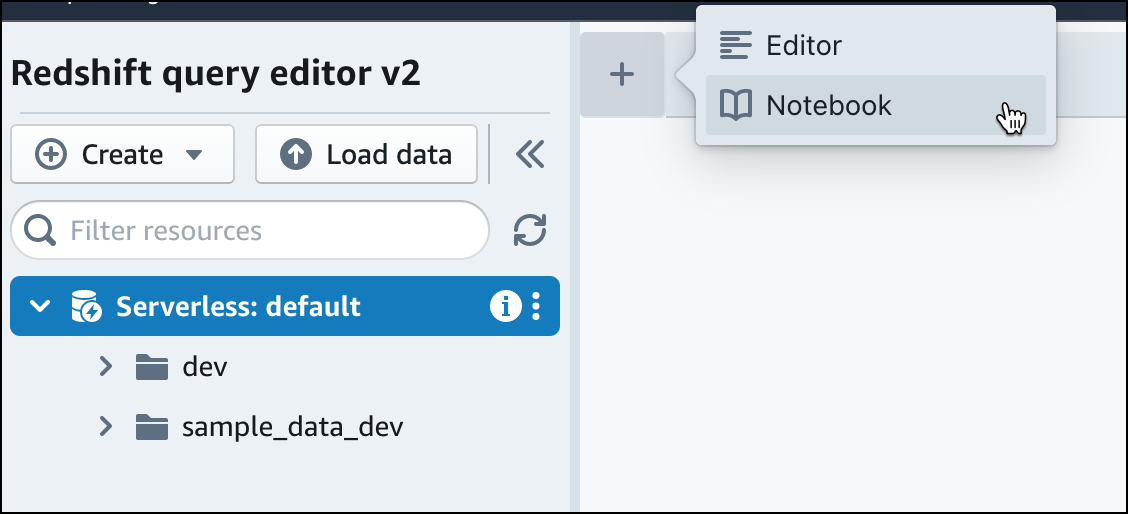
-
devデータベースに切り替えます。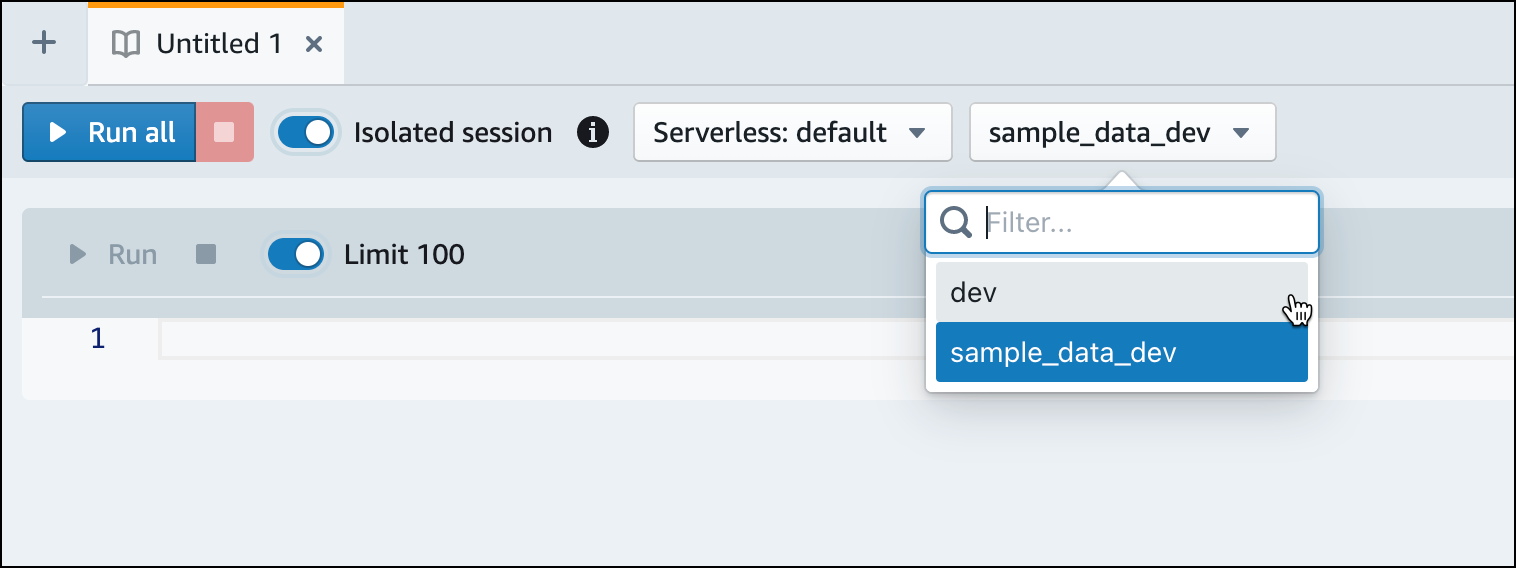
-
テーブルを作成します。
クエリエディタ v2 使用している場合は、次のテーブル作成ステートメントを個別にコピーして実行し、
devデータベースにテーブルを作成します。構文の詳細については、「Amazon Redshift データベースデベロッパーガイド」の「CREATE TABLE」を参照してください。create table users( userid integer not null distkey sortkey, username char(8), firstname varchar(30), lastname varchar(30), city varchar(30), state char(2), email varchar(100), phone char(14), likesports boolean, liketheatre boolean, likeconcerts boolean, likejazz boolean, likeclassical boolean, likeopera boolean, likerock boolean, likevegas boolean, likebroadway boolean, likemusicals boolean); create table event( eventid integer not null distkey, venueid smallint not null, catid smallint not null, dateid smallint not null sortkey, eventname varchar(200), starttime timestamp); create table sales( salesid integer not null, listid integer not null distkey, sellerid integer not null, buyerid integer not null, eventid integer not null, dateid smallint not null sortkey, qtysold smallint not null, pricepaid decimal(8,2), commission decimal(8,2), saletime timestamp); -
クエリエディタ v2 で、ノートブックに新しい SQL セルを作成します。
-
Amazon S3 または Amazon DynamoDB から大容量のデータセットを Amazon Redshift にロードする場合は、クエリエディタ v2 の COPY コマンドの使用をお勧めします。COPY 構文の詳細については、「Amazon Redshift データベースデベロッパーガイド」の「COPY」を参照してください。
COPY コマンドは、パブリック S3 バケットにあるサンプルデータを使用して実行できます。クエリエディタ v2 で次の SQL コマンドを実行します。
COPY users FROM 's3://redshift-downloads/tickit/allusers_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY event FROM 's3://redshift-downloads/tickit/allevents_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY sales FROM 's3://redshift-downloads/tickit/sales_tab.txt' DELIMITER '\t' TIMEFORMAT 'MM/DD/YYYY HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; -
データをロードしてから、ノートブックに別の SQL セルを作成して、いくつかのクエリ例を試します。SELECT コマンドの使用に関する詳細については、Amazon Redshift データベースデベロッパーガイドの SELECT を参照してください。サンプルデータの構造とスキーマを理解するため、クエリエディタ v2 を使用してみてください。
-- Find top 10 buyers by quantity. SELECT firstname, lastname, total_quantity FROM (SELECT buyerid, sum(qtysold) total_quantity FROM sales GROUP BY buyerid ORDER BY total_quantity desc limit 10) Q, users WHERE Q.buyerid = userid ORDER BY Q.total_quantity desc; -- Find events in the 99.9 percentile in terms of all time gross sales. SELECT eventname, total_price FROM (SELECT eventid, total_price, ntile(1000) over(order by total_price desc) as percentile FROM (SELECT eventid, sum(pricepaid) total_price FROM sales GROUP BY eventid)) Q, event E WHERE Q.eventid = E.eventid AND percentile = 1 ORDER BY total_price desc;
データをロードし、いくつかのサンプルクエリを実行したので、Amazon Redshift Serverless の他の領域を調べることができます。Amazon Redshift Serverless の使用方法の詳細については、次のリストを参照してください。
-
Amazon S3 バケットからデータをロードできます。詳細については、「Amazon S3 からデータをロードする」を参照してください。
-
クエリエディタ v2 を使用すると、5 MB 未満のローカルの文字区切りされたファイルからデータをロードできます。詳細については、「ローカルファイルからのデータのロード」を参照してください。
-
Amazon Redshift Serverless には、JDBC ドライバーと ODBC ドライバーを備えたサードパーティー製 SQL ツールで接続できます。詳細については、「Amazon Redshift Serverless への接続」を参照してください。
-
Amazon Redshift Data API を使用して、Amazon Redshift Serverless に接続することもできます。詳細については、「Amazon Redshift Data API の使用
」を参照してください。 -
Amazon Redshift Serverless 内のデータと Redshift ML を使用して、CREATE MODEL コマンドで機械学習モデルを作成できます。Redshift ML モデルの構築方法については、「チュートリアル: カスタマーチャーンモデルの構築」を参照してください。
-
Amazon Redshift Serverless にデータをロードせずに Amazon S3 データレイクからデータをクエリすることができます。詳細については、「データレイクのクエリ」を参照してください。
