クラスターワークロードの内訳表の表示
コンソールのワークロードの実行内訳表を確認して、ワークロードのパフォーマンスの詳細を表示できます。この表は、QueryRuntimeBreakdown メトリクスで提供されるデータを使用して構成されています。この表では、待機や計画などのさまざまな処理ステージで、クエリにどれだけの時間がかかっているかを見ることができます。
注記
ワークロードの実行内訳表は、単一ノードのクラスターには表示されません。
次のメトリクスのリストでは、さまざまな処理ステージを説明しています。
-
QueryPlanning: SQL ステートメントの解析と最適化にかかった時間。 -
QueryWaiting: ワークロード管理 (WLM) キューでの待機にかかった時間。 -
QueryExecutingRead: 読み取りクエリの実行にかかった時間。 -
QueryExecutingInsert: 挿入クエリの実行にかかった時間。 -
QueryExecutingDelete: 削除クエリの実行にかかった時間。 -
QueryExecutingUpdate: 更新クエリの実行にかかった時間。 -
QueryExecutingCtas: CREATE TABLE AS クエリの実行にかかった時間。 -
QueryExecutingUnload: アップロードクエリの実行にかかった時間。 -
QueryExecutingCopy: コピークエリの実行にかかった時間。
たとえば、Amazon Redshift コンソールの次のグラフには、計画、待機、読み取り、および書き込みの各段階でクエリにかかった時間が示されます。このグラフの結果を、この先の分析のために他のメトリクスと組み合わせることができます。一部のケースでは、短い期間のクエリ (QueryDuration メトリクスによって測定) が待機時間に多くの時間をかけていると表示されることがあります。このような場合には、特定のキューの WLM 同時実行率を上げることで、スループットを増大させることができます。
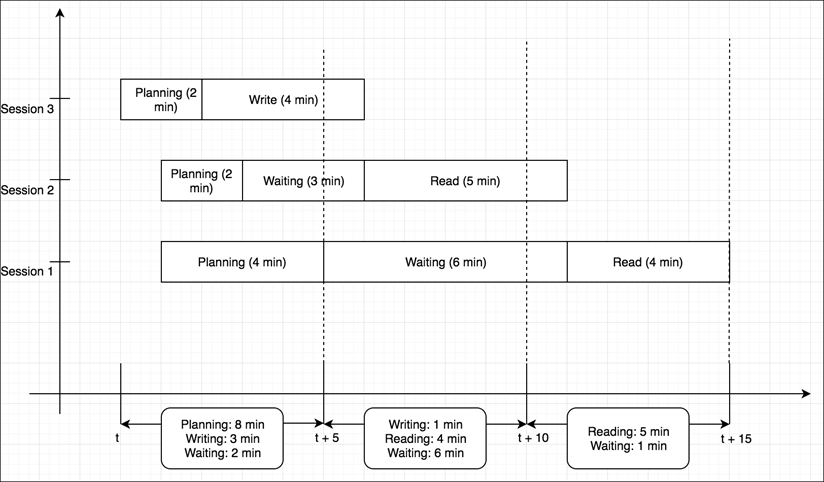
次に、ワークロードの実行内訳表の例を示します。チャートの y 軸の値は、積み上げ棒グラフとして示された、指定時刻における各ステージの平均期間です。

次の図は、Amazon Redshift がどのように同時セッションの集計クエリ処理を行うかを示しています。
クラスターワークロードの内訳表を表示するには
-
AWS Management Console にサインインして、https://console.aws.amazon.com/redshiftv2/
で Amazon Redshift コンソールを開きます。 -
ナビゲーションメニューで [クラスター] を選択し、リストからクラスター名を選択してその詳細を開きます。クラスターの詳細が表示されます。これには、[クラスターのパフォーマンス]、[クエリのモニタリング]、[データベース]、[データ共有]、[スケジュール]、[メンテナンス]、および [プロパティ] タブなどがあります。
-
クエリに関するメトリクスの [クエリのモニタリング] タブを選択します。
-
[Query monitoring (クエリのモニタリング)] セクションで、[Database performance (データベースのパフォーマンス)] を選択し、[Cluster metrics (クラスターのメトリクス)] を選択します。
次のメトリクスは、選択した時間範囲について積み上げ棒グラフで表示されています。
-
プラン時間
-
待機時間
-
コミット時間
-
実行時間
-
