翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
オブジェクトおよび概念の検出
このセクションでは、Amazon Rekognition イメージおよび Amazon Rekognition Video を使用してイメージおよびビデオのラベルを検出する情報について説明します。
ラベルやタグは、イメージやビデオ内でそのコンテンツに基づいて発見されたオブジェクトや概念 (シーンやアクションを含む) です。例えば、南国のビーチでくつろぐ人々のイメージには、ヤシの木 (オブジェクト)、ビーチ (シーン)、ランニング (アクション)、アウトドア (概念) が含まれる場合があります。
Rekognition のラベル検出オペレーションでサポートされているラベル
注記
Amazon Rekognition は、特定のイメージ内の人物の物理的な外観に基づいて、性別バイナリ(男性、女性、女の子など)の予測を作成します。この種の予測は、人物の性自認を分類するためのものではないため、Amazon Rekognition を使用してこのような判断を下さないようにしましょう。たとえば、ある役のために長髪のかつらやイヤリングを身に着けている男性俳優は、女性として予測されるかもしれません。
Amazon Rekognition を使用してジェンダーバイナリー予測を作成することは、特定のユーザーを確認せずに性別分布の集計統計を分析する必要があるユースケースに最適です。たとえば、ソーシャルメディアプラットフォームで男性と比較した女性のユーザーの割合。
性別二者択一の予測を使用して、個人の権利、プライバシー、またはサービスへのアクセスに影響する決定を行うことはお勧めしません。
Amazon Rekognition は英語でラベルを返します。Amazon Translate
以下の図では、Amazon Rekognition Image または Amazon Rekognition Video オペレーションの使用目的に応じて、必要なオペレーションを呼び出す順序を示しています。

レスポンスオブジェクトのラベル付け
境界ボックス
Amazon Rekognition イメージおよび Amazon Rekognition Video は、車、家具、アパレル、またはペットなどの一般的なオブジェクトラベルの境界ボックスを返すことができます。境界ボックス情報は、それほど一般的ではないオブジェクトラベルを返しません。境界ボックスを使用して、画像内のオブジェクトの正確な位置を検出したり、検出された被写体のインスタンスを数えたり、境界ボックスのディメンションを使用して被写体のサイズを測定したりできます。
たとえば、次のイメージでは、Amazon Rekognition イメージは人物、スケートボード、駐車中の車、その他の情報の存在を検出することができます。Amazon Rekognition のイメージは、検出された人、および車や車輪などの他の検出されたオブジェクトの境界ボックスも返します。

信頼スコア
Amazon Rekognition Video および Amazon Rekognition Image は、Amazon Rekognition で検出された各ラベルの精度がどの程度信頼できるかを示す割合のスコアも表示します。
親
Amazon Rekognition イメージおよび Amazon Rekognition Video は、ラベルを分類するために祖先ラベルの階層分類を使用します。たとえば、道路を横切って歩いている人は Pedestrian として検出される可能性があります。Pedestrian の親ラベルは Person です。これらのラベルは両方とも応答で返されます。すべての先祖ラベルが返され、指定されたラベルにはその親および他の先祖ラベルのリストが含まれます。たとえば、祖父母ラベルと曽祖父母ラベル (存在する場合) です。親ラベルを使用して、関連するラベルのグループを作成したり、1 つ以上の画像内の類似ラベルを照会したりできます。たとえば、すべての Vehicles に対するクエリは、ある画像から自動車を、別の画像からバイクを返す可能性があります。
カテゴリ
Amazon Rekognition Image および Amazon Rekognition Video は、ラベルカテゴリに関する情報を返します。ラベルは、「車両と自動車」や「食品と飲料」のように、共通の機能やコンテキストに基づいて個々のラベルをグループ化するカテゴリの一部です。ラベルカテゴリは親カテゴリのサブカテゴリにすることができます。
エイリアス
Amazon Rekognition Image と Amazon Rekognition Video は、ラベルを返すだけでなく、ラベルに関連付けられているエイリアスをすべて返します。エイリアスとは、同じ意味を持つラベル、または返されるプライマリラベルと視覚的に置換可能なラベルです。例えば、「セルフォン」は「携帯電話」のエイリアスです。
以前のバージョンでは、Amazon Rekognition Image は「携帯電話」を含むプライマリラベル名と同じリストに「セルフォン」などのエイリアスを返していました。現在 Amazon Rekognition Image は、「エイリアス」というフィールドに「セルフォン」を返し、プライマリラベル名のリストに「携帯電話」を返すようになりました。アプリケーションが以前のバージョンの Rekognition によって返された構造に依存している場合、必要に応じて、イメージまたはビデオのラベル検出オペレーションによって返される現在のレスポンスを、すべてのラベルとエイリアスがプライマリラベルとして返される以前のレスポンス構造に変換します。
DetectLabels API (イメージ内のラベル検出用) からの現在のレスポンスを以前のレスポンス構造に変換する必要がある場合は、「DetectLabels レスポンスの変換」のコード例を参照してください。
GetLabelDetection API (保存されているビデオのラベル検出用) からの現在のレスポンスを以前のレスポンス構造に変換する必要がある場合は、「GetLabelDetection レスポンスの変換」のコード例を参照してください。
イメージプロパティ
Amazon Rekognition Image は、イメージ全体の画質 (鮮明度、明るさ、コントラスト) に関する情報を返します。イメージの前景と背景の鮮明度と明るさに関する情報も返されます。イメージプロパティを使用して、イメージ全体、前景、背景、および境界ボックスを持つオブジェクトのドミナントカラーを検出することもできます。

以下は、処理中のイメージの DetectLabels オペレーションのレスポンスに含まれる ImageProperties データの例です。
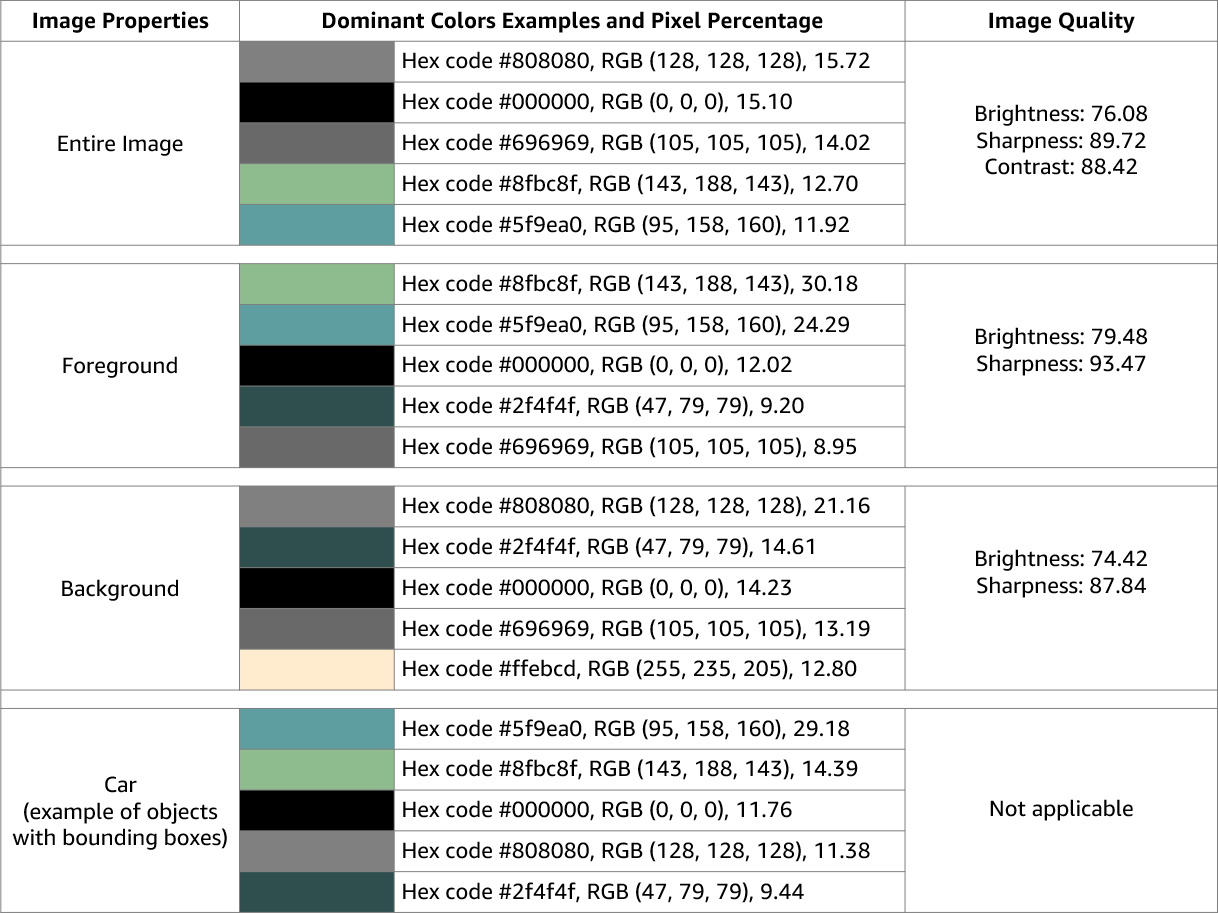
イメージプロパティは Amazon Rekognition Video では使用できません。
モデルのバージョン
Amazon Rekognition イメージおよび Amazon Rekognition Video は、いずれもイメージまたは保存されたビデオ内のラベルを検出するために使用されたラベル検出モデルのバージョンを返します。
包含フィルターと除外フィルター
Amazon Rekognition Image および Amazon Rekognition Video ラベル検出オペレーションによって返された結果をフィルタリングできます。ラベルとカテゴリのフィルタリング条件を指定して結果をフィルタリングします。ラベルフィルターには、包含フィルターと除外フィルターがあります。
DetectLabels を使用して得られた結果のフィルタリングの詳細については、「イメージ内のラベルの検出」を参照してください。
GetLabelDetection によって得られた結果のフィルタリングの詳細については、「ビデオ内のラベルの検出」を参照してください。
結果のソートと集計
特定の Amazon Rekognition Video オペレーションから得られた結果は、タイムスタンプとビデオセグメントに従ってソートおよび集計できます。ラベル検出ジョブまたはコンテンツモデレーションジョブの結果を、GetLabelDetection または GetContentModeration を使用して取得する場合、SortBy および AggregateBy 引数を使用して結果の返し方を指定できます。SortBy を TIMESTAMP または NAME (ラベル名) と一緒に使用したり、TIMESTAMPS または SEGMENTS を AggregateBy 引数と一緒に使用したりできます。
