翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
R eady-to-use モデルで予測を行う
R eady-to-use モデルは、テキスト、イメージ、ドキュメントデータに使用できます。各データ型には、各ユースケースに最適な R eady-to-use モデルがあります。次のガイドを使用して、入力データで使用できる R eady-to-use モデルを決定します。
-
テキストデータ: センチメント分析、エンティティ抽出、言語検出、個人情報検出
-
画像データ: 画像内のオブジェクト検出、画像内のテキスト検出
-
ドキュメントデータ: 経費分析、身分証明書分析、ドキュメント分析、ドキュメントクエリ
次のスクリーンショットは、R eady-to-use モデルのランディングページを示しています。このページでは、さまざまなソリューションがすべて紹介されています。

各 R eady-to-use モデルは、データセットの単一予測とバッチ予測の両方をサポートします。単一予測では、単一の予測を行います。例えば、テキストを抽出する画像が 1 つだけの場合や、主要言語を検出するテキストの段落が 1 つだけの場合です。バッチ予測では、データセット全体の予測を行います。例えば、顧客感情を分析する顧客レビューのCSVファイルがある場合や、オブジェクトを検出する画像ファイルがある場合などです。
データを用意してユースケースを特定したら、次のワークフローのいずれかを選択してデータを予測します。
テキストデータの予測を行う
テキストデータセットの単一予測とバッチ予測の両方を行う方法を以下に示します。センチメント分析、エンティティ抽出、言語検出、個人情報検出の R eady-to-use モデルタイプには、 プロシージャを使用できます。
注記
現在、センチメント分析ができるのは英語のテキストだけです。
単一予測
テキストデータを受け入れる R eady-to-use モデルに対して単一の予測を行うには、次の手順を実行します。
-
Canvas アプリケーションの左側のナビゲーションペインで、Ready-to-use モデル を選択します。
-
R eady-to-use モデルページで、ユースケースの R eady-to-use モデルを選択します。テキストデータの場合、センチメント分析、エンティティ抽出、言語検出、または個人情報検出のいずれかである必要があります。
-
選択した R eady-to-use モデルの予測を実行するページで、単一予測 を選択します。
-
[テキストフィールド] に、予測を取得するテキストを入力します。
-
[予測結果を生成] を選択して予測を生成します。
右側のペインの [予測結果] には、各結果またはラベルの [信頼度] スコアに加えて、テキストの分析結果が表示されます。例えば、言語検出を選択して、フランス語のテキストの一部を入力した場合、信頼度スコアはフランス語が 95%、英語など他の言語が 5% になることがあります。
次のスクリーンショットは、その文章が英語であることのモデルの信頼度が 100% の場合の、言語検出を使用した単一予測の結果を示しています。

バッチ予測
テキストデータを受け入れる R eady-to-use モデルのバッチ予測を行うには、次の手順を実行します。
-
Canvas アプリケーションの左側のナビゲーションペインで、Ready-to-use モデル を選択します。
-
R eady-to-use モデルページで、ユースケースの R eady-to-use モデルを選択します。テキストデータの場合、センチメント分析、エンティティ抽出、言語検出、または個人情報検出のいずれかである必要があります。
-
選択した R eady-to-use モデルの予測を実行するページで、バッチ予測 を選択します。
-
データセットを既にインポートしている場合は、[データセットを選択] を選択します。それ以外の場合は、[新しいデータセットをインポート] を選択すると、データのインポートワークフローが表示されます。
-
使用可能なデータセットのリストからデータセットを選択し、[予測を生成] を選択して予測を生成します。
予測ジョブの実行が完了すると、[予測を実行] ページの [予測] の下に出力データセットが表示されます。このデータセットには結果が格納されており、[その他のオプション] アイコン (
![]() ) を選択すると、出力データをプレビューできます。次に、[ダウンロード] を選択して結果をダウンロードします。
) を選択すると、出力データをプレビューできます。次に、[ダウンロード] を選択して結果をダウンロードします。
画像データの予測を行う
画像データセットの単一予測とバッチ予測の両方を行う方法を以下に示します。プロシージャは、オブジェクト検出イメージとイメージ内のテキスト検出の R eady-to-use モデルタイプに使用できます。
単一予測
画像データを受け入れる R eady-to-use モデルに対して単一の予測を行うには、次の手順を実行します。
-
Canvas アプリケーションの左側のナビゲーションペインで、Ready-to-use モデル を選択します。
-
R eady-to-use モデルページで、ユースケースの R eady-to-use モデルを選択します。画像データの場合は、[オブジェクト検出画像] または [画像内のテキスト検出] のいずれかである必要があります。
-
選択した R eady-to-use モデルの予測を実行するページで、単一予測 を選択します。
-
[画像をアップロード] を選択します。
-
ローカルコンピューターからアップロードする画像を選択するプロンプトが表示されます。ローカルファイルから画像を選択すると、予測結果が生成されます。
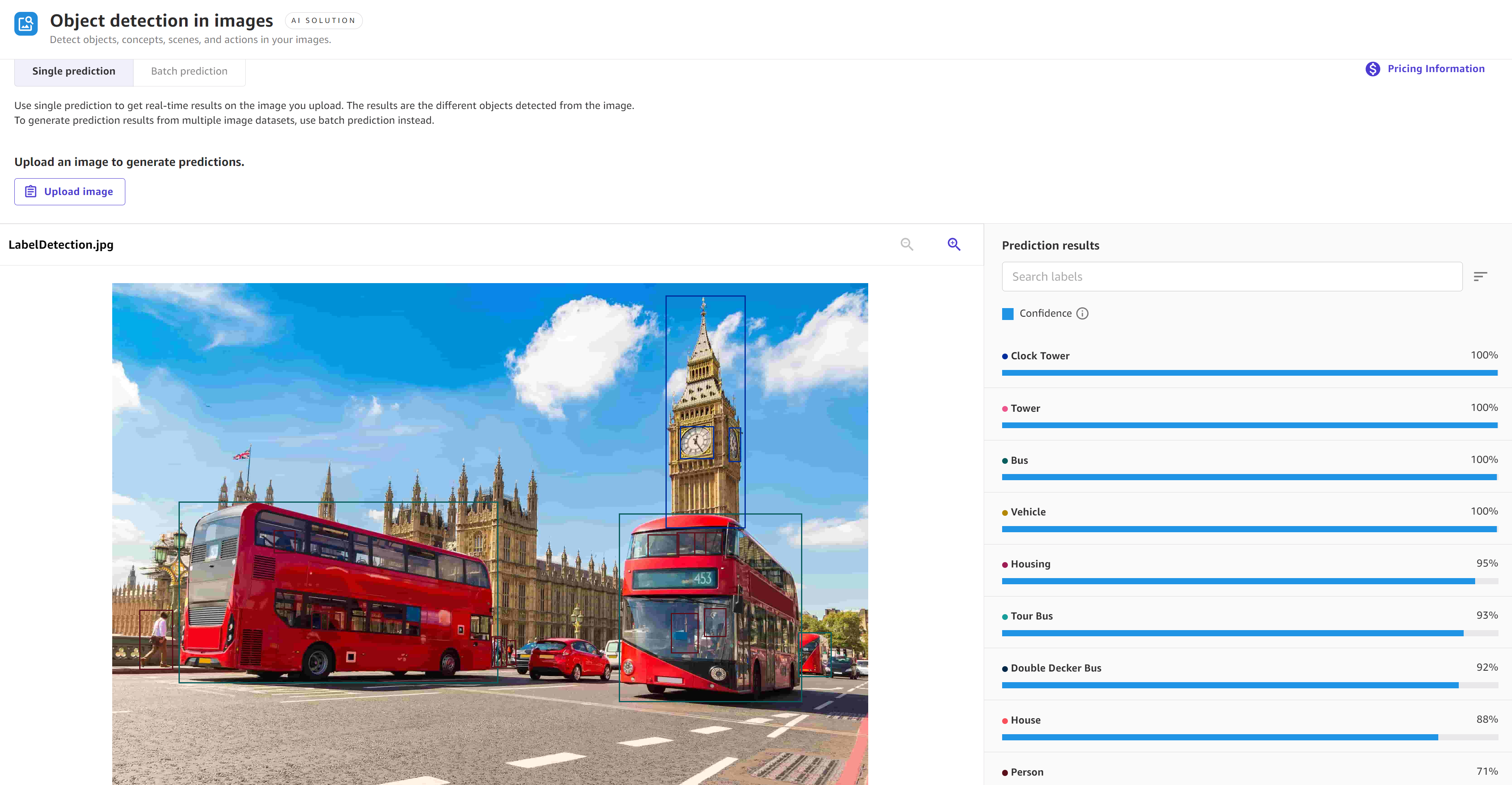
右側のペインの [予測結果] には、検知された各オブジェクトまたはテキストの [信頼度] スコアに加えて、画像の分析結果が表示されます。例えば、画像内のオブジェクト検出を選択した場合、画像内のオブジェクトのリストと、モデルでの各オブジェクトの検出精度の信頼性を示す信頼度スコア (93% など) が表示されます。
次のスクリーンショットは、画像内のオブジェクト検出ソリューションを使用した単一予測の結果を示しています。モデルでは、時計塔やバスなどの物体を 100% の信頼性で予測しています。
バッチ予測
画像データを受け入れる R eady-to-use モデルのバッチ予測を行うには、次の手順を実行します。
-
Canvas アプリケーションの左側のナビゲーションペインで、Ready-to-use モデル を選択します。
-
R eady-to-use モデルページで、ユースケースの R eady-to-use モデルを選択します。画像データの場合は、[オブジェクト検出画像] または [画像内のテキスト検出] のいずれかである必要があります。
-
選択した R eady-to-use モデルの予測を実行するページで、バッチ予測 を選択します。
-
データセットを既にインポートしている場合は、[データセットを選択] を選択します。それ以外の場合は、[新しいデータセットをインポート] を選択すると、データのインポートワークフローが表示されます。
-
使用可能なデータセットのリストからデータセットを選択し、[予測を生成] を選択して予測を生成します。
予測ジョブの実行が完了すると、[予測を実行] ページの [予測] の下に出力データセットが表示されます。このデータセットには結果が格納されており、[その他のオプション] アイコン (
![]() ) を選択すると、[予測結果を表示] を選択して出力データをプレビューできます。次に、予測のダウンロードを選択し、結果を CSVまたは ZIP ファイルとしてダウンロードできます。
) を選択すると、[予測結果を表示] を選択して出力データをプレビューできます。次に、予測のダウンロードを選択し、結果を CSVまたは ZIP ファイルとしてダウンロードできます。
ドキュメントデータの予測を行う
ドキュメントデータセットの単一予測とバッチ予測の両方を行う方法を以下に示します。プロシージャは、経費分析、ID ドキュメント分析、ドキュメント分析の R eady-to-use モデルタイプに使用できます。
注記
ドキュメントクエリでは、現在単一予測のみがサポートされています。
単一予測
ドキュメントデータを受け入れる R eady-to-use モデルに対して単一の予測を行うには、次の手順を実行します。
-
Canvas アプリケーションの左側のナビゲーションペインで、Ready-to-use モデル を選択します。
-
R eady-to-use モデルページで、ユースケースの R eady-to-use モデルを選択します。ドキュメントデータの場合は、[経費分析]、[身分証明書分析]、または[ドキュメント分析] のいずれかである必要があります。
-
選択した R eady-to-use モデルの予測を実行するページで、単一予測 を選択します。
-
R eady-to-use モデルがアイデンティティドキュメント分析またはドキュメント分析の場合は、次のアクションを実行します。経費分析または文書クエリを行う場合は、この手順をスキップして、手順 5 または手順 6 に進んでください。
-
[ドキュメントのアップロード] を選択します。
-
ローカルコンピュータから PDF、JPG、または PNG ファイルをアップロードするように求められます。ローカルファイルからドキュメントを選択すると、予測結果が生成されます。
-
-
R eady-to-use モデルが経費分析の場合は、次の操作を行います。
-
[請求書または領収書のアップロード] を選択します。
-
ローカルコンピュータから PDF、JPG、PNG、または TIFF ファイルをアップロードするように求められます。ローカルファイルからドキュメントを選択すると、予測結果が生成されます。
-
-
R eady-to-use モデルがドキュメントクエリの場合は、次の操作を行います。
-
[ドキュメントのアップロード] を選択します。
-
ローカルコンピュータからPDFファイルをアップロードするように求められます。ローカルファイルのドキュメントを選択します。の長さは 1~100 ページPDFである必要があります。
注記
アジアパシフィック (ソウル)、アジアパシフィック (シンガポール)、アジアパシフィック (シドニー)、または欧州 (フランクフルト) リージョンにいる場合、ドキュメントクエリの最大PDFサイズは 20 ページです。
-
右側のペインに、ドキュメント内の情報を検索するクエリを入力します。1 つのクエリに入力できる文字数は 1~200 文字です。クエリは一度に 15 個まで追加できます。
-
[クエリを送信] を選択すると、クエリに対する回答を含む結果が生成されます。クエリを送信するたびに 1 回請求されます。
-
右側のペインの [予測結果] には、文書の分析が表示されます。
以下の情報は、各タイプのソリューションの結果を示しています。
-
経費分析では、結果は領収書の合計などのフィールドを含む[概要フィールド] と、領収書の個々のアイテムなどのフィールドを含む[行アイテムフィールド] が表示されます。識別されたフィールドは、出力されたドキュメント画像上で強調表示されます。
-
ID ドキュメント分析の場合、出力には、姓名、住所、生年月日など、Ready-to-use モデルが識別したフィールドが表示されます。識別されたフィールドは、出力されたドキュメント画像上で強調表示されます。
-
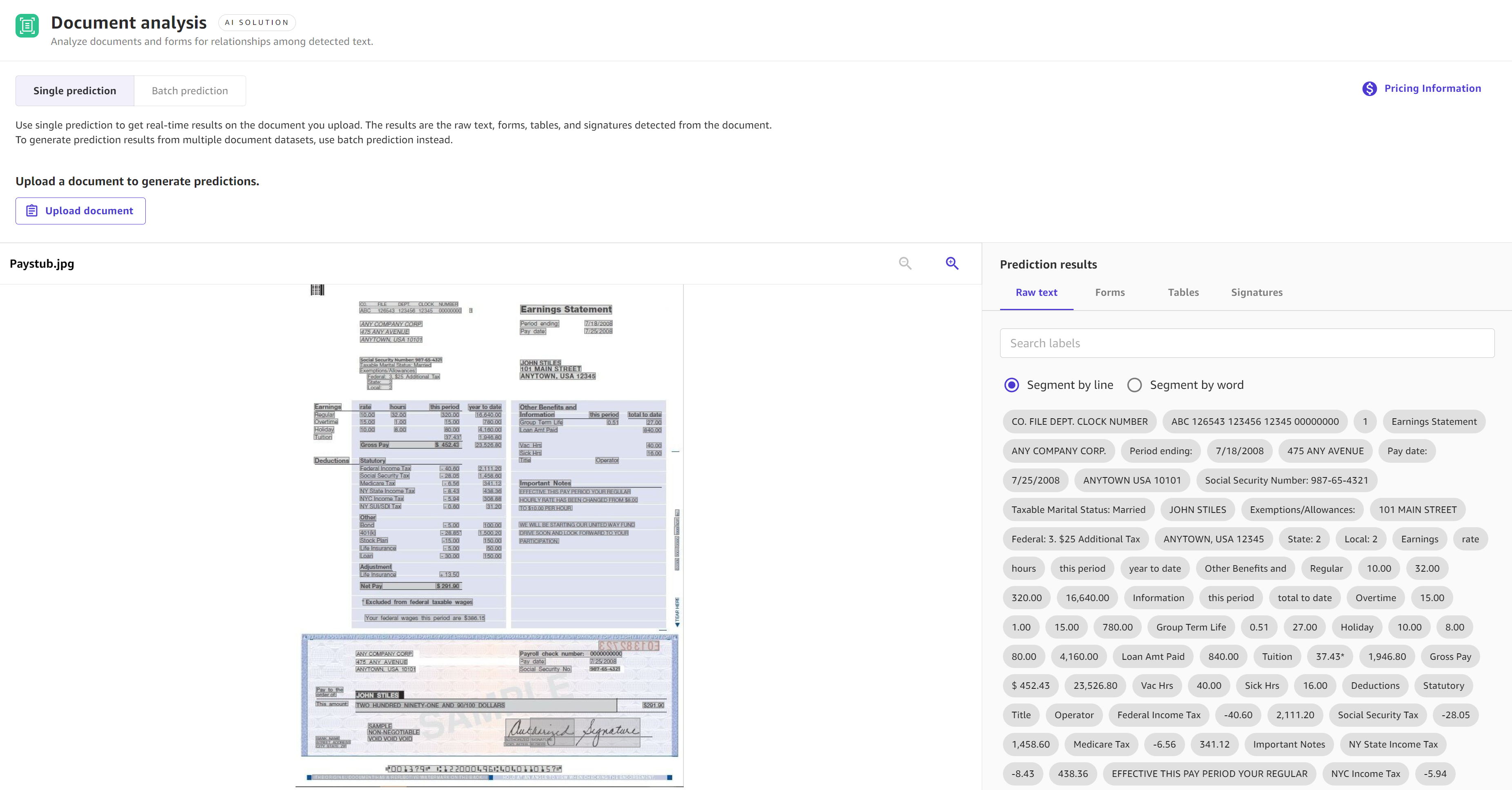
文書分析では、[未加工テキスト]、[フォーム]、[表]、[署名] が表示されます。[未加工テキスト] には抽出されたテキストがすべて含まれ、[フォーム]、[表]、[署名] にはこれらのカテゴリに該当するフォームに関する情報のみが含まれます。例えば、[表] にはドキュメント内の表から抽出された情報のみが含まれます。識別されたフィールドは、出力されたドキュメント画像上で強調表示されます。
-
ドキュメントクエリの場合、Canvas は各クエリに対する回答を返します。折りたたみ可能なクエリのドロップダウンを開くと、結果と予測の信頼度スコアが表示されます。Canvas がドキュメント内で複数の回答を検出した場合、クエリごとに複数の結果が表示される場合があります。
次のスクリーンショットは、ドキュメント分析ソリューションを使用した単一予測の結果を示しています。
バッチ予測
ドキュメントデータを受け入れる R eady-to-use モデルのバッチ予測を行うには、次の手順を実行します。
-
Canvas アプリケーションの左側のナビゲーションペインで、Ready-to-use モデル を選択します。
-
R eady-to-use モデルページで、ユースケースの R eady-to-use モデルを選択します。画像データの場合は、[経費分析]、[身分証明書分析]、または[ドキュメント分析] のいずれかである必要があります。
-
選択した R eady-to-use モデルの予測を実行するページで、バッチ予測 を選択します。
-
データセットを既にインポートしている場合は、[データセットを選択] を選択します。それ以外の場合は、[新しいデータセットをインポート] を選択すると、データのインポートワークフローが表示されます。
-
使用可能なデータセットのリストからデータセットを選択し、[予測を生成] を選択します。ユースケースがドキュメント分析の場合は、手順 6 に進んでください。
-
(オプション) ユースケースがドキュメント分析の場合は、[バッチ予測に含める機能の選択] という別のダイアログボックスが表示されます。[フォーム]、[表]、[署名] を選択して、結果をそれらの機能にグループ化できます。次に、[予測を生成] を選択します。
予測ジョブの実行が完了すると、[予測を実行] ページの [予測] の下に出力データセットが表示されます。このデータセットには結果が格納されており、[その他のオプション] アイコン (
![]() ) を選択すると、[予測結果を表示] を選択してドキュメントデータの分析結果をプレビューできます。
) を選択すると、[予測結果を表示] を選択してドキュメントデータの分析結果をプレビューできます。
以下の情報は、各タイプのソリューションの結果を示しています。
-
経費分析では、結果は領収書の合計などのフィールドを含む[概要フィールド] と、領収書の個々のアイテムなどのフィールドを含む[行アイテムフィールド] が表示されます。識別されたフィールドは、出力されたドキュメント画像上で強調表示されます。
-
ID ドキュメント分析の場合、出力には、姓名、住所、生年月日など、Ready-to-use モデルが識別したフィールドが表示されます。識別されたフィールドは、出力されたドキュメント画像上で強調表示されます。
-
文書分析では、[未加工テキスト]、[フォーム]、[表]、[署名] が表示されます。[未加工テキスト] には抽出されたテキストがすべて含まれ、[フォーム]、[表]、[署名] にはこれらのカテゴリに該当するフォームに関する情報のみが含まれます。例えば、[表] にはドキュメント内の表から抽出された情報のみが含まれます。識別されたフィールドは、出力されたドキュメント画像上で強調表示されます。
結果をプレビューしたら、予測のダウンロードを選択し、結果をZIPファイルとしてダウンロードできます。
