翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
分析結果
SageMaker Clarify 処理ジョブが終了したら、出力ファイルをダウンロードして検査したり、SageMaker Studio で結果を可視化したりできます。次のトピックでは、バイアス分析、SHAP 分析、コンピュータビジョンの説明可能性分析、Partial Dependence Plot (PDP) 分析が生成するスキーマやレポートなど、SageMaker Clarify が生成する分析結果について説明します。設定分析に複数の分析を計算するパラメータが含まれている場合、その結果は 1 つの分析と 1 つのレポートファイルに集約されます。
SageMaker Clarify 処理ジョブの出力ディレクトリには次のファイルが含まれています。
-
analysis.json— JSON 形式のバイアスメトリクスと特徴量重要度を含むファイル。 -
report.ipynb— バイアスメトリクスと特徴量需要度を視覚化するのに役立つコードを含む静的ノートブック。 -
explanations_shap/out.csv— 作成され、特定の分析設定に基づいて自動的に生成されたファイルを格納するディレクトリ。例えば、save_local_shap_valuesパラメータを有効にすると、インスタンスごとのローカル SHAP 値がexplanations_shapディレクトリに保存されます。別の例として、analysis configurationに SHAP ベースラインパラメータの値が含まれていない場合、SageMaker Clarify の説明可能性ジョブは入力データセットをクラスタリングしてベースラインを計算します。次に、生成されたベースラインをディレクトリに保存します。
詳細については、以下のセクションを参照してください。
バイアス分析
Amazon SageMaker Clarify では、バイアスと公平性について説明するために、「バイアスと公平性に関する Amazon SageMaker Clarify の用語解説 」に記載されている用語を使用します。
分析ファイルのスキーマ
分析ファイルは JSON 形式で、トレーニング前のバイアスメトリクスとトレーニング後のバイアスメトリクスの 2 つのセクションに分かれています。トレーニング前とトレーニング後のバイアスメトリクスのパラメータは次のとおりです。
-
pre_training_bias_metrics — トレーニング前のバイアスメトリクスのパラメータ。詳細については、「トレーニング前のバイアスメトリクス」と「分析設定ファイル」を参照してください。
-
label — 分析設定の
labelパラメータによって定義されるグラウンドトゥルースラベル名。 -
label_value_or_threshold — 分析設定の
label_values_or_thresholdパラメータによって定義されるラベル値または間隔を含む文字列。例えば、二項分類問題に値1を指定した場合、文字列は1になります。多クラス問題で複数の値[1,2]を指定した場合、文字列は1,2になります。リグレッション問題にしきい値40を指定すると、文字列は(40, 68]のような内部文字列になります。ここで、68は入力データセット内のラベルの最大値です。 -
facets — このセクションには複数のキーと値のペアが含まれており、キーはファセット設定の
name_or_indexパラメータで定義されたファセット名に対応し、値はファセットオブジェクトの配列です。 オブジェクトには次のメンバーがあります。-
value_or_threshold — ファセット設定の
value_or_thresholdパラメータによって定義されるファセット値または間隔を含む文字列。 -
metrics — セクションにはバイアスメトリクス要素の配列が含まれ、各バイアスメトリクス要素には次の属性があります。
-
name — バイアスメトリクスのショートネーム。例えば、
CI。 -
description — バイアスメトリクスのフルネーム。例えば、
Class Imbalance (CI)。 -
value — バイアスメトリクス値。特定の理由でバイアスメトリクスが計算されなかった場合は JSON null 値。±∞ の値は、それぞれ文字列
∞と-∞として表されます。 -
error — バイアスメトリクスが計算されなかった理由を説明するオプションのエラーメッセージ。
-
-
-
-
post_training_bias_metrics — このセクションにはトレーニング後のバイアスメトリクスが含まれ、トレーニング前のセクションと同様のレイアウトと構造になっています。詳細については、「トレーニング済みデータのメトリクスとモデルのバイアスのメトリクス」を参照してください。
以下は、トレーニング前とトレーニング後のバイアスメトリクスの両方を計算する分析設定の例です。
{ "version": "1.0", "pre_training_bias_metrics": { "label": "Target", "label_value_or_threshold": "1", "facets": { "Gender": [{ "value_or_threshold": "0", "metrics": [ { "name": "CDDL", "description": "Conditional Demographic Disparity in Labels (CDDL)", "value": -0.06 }, { "name": "CI", "description": "Class Imbalance (CI)", "value": 0.6 }, ... ] }] } }, "post_training_bias_metrics": { "label": "Target", "label_value_or_threshold": "1", "facets": { "Gender": [{ "value_or_threshold": "0", "metrics": [ { "name": "AD", "description": "Accuracy Difference (AD)", "value": -0.13 }, { "name": "CDDPL", "description": "Conditional Demographic Disparity in Predicted Labels (CDDPL)", "value": 0.04 }, ... ] }] } } }
バイアス分析レポート
バイアス分析レポートには、詳細な説明と説明を含む複数の表と図が含まれています。これには、ラベル値の分布、ファセット値の分布、モデルのパフォーマンス概要図、バイアスメトリクスの表と、それらの説明などが含まれます。バイアスメトリクスとその解釈方法の詳細については、「Learn how Amazon SageMaker Clarify helps detect bias
SHAP 分析
SageMaker Clarify 処理ジョブは、カーネル SHAP アルゴリズムを使用して特徴量属性を計算します。SageMaker Clarify 処理ジョブは、ローカルとグローバルの両方の SHAP 値を生成します。これらは、モデル予測に対する各特徴量の寄与度を判断するのに役立ちます。ローカル SHAP 値は個々のインスタンスの特徴量重要度を表し、グローバル SHAP 値はデータセット内のすべてのインスタンスのローカル SHAP 値を集計します。SHAP 値とその解釈方法の詳細については、「Shapley 値を使用する特徴属性」を参照してください。
SHAP 分析ファイルのスキーマ
グローバル SHAP 分析の結果は、kernel_shap メソッドの下の分析ファイルの説明セクションに保存されます。SHAP 分析ファイルには次のようなさまざまなパラメータがあります。
-
explanations — 特徴量重要度の分析結果を含む分析ファイルのセクション。
-
kernal_shap — グローバル SHAP 分析結果を含む分析ファイルのセクション。
-
global_shap_values — 複数のキーと値のペアを含む分析ファイルのセクション。キーと値のペアの各キーは、入力データセットの特徴量名を表します。キーと値のペアの各値は、特徴量のグローバル SHAP 値に対応します。グローバル SHAP 値は、
agg_method設定を使用して特徴量のインスタンスごとの SHAP 値を集計することによって取得されます。use_logit設定がアクティブ化されている場合、値はロジスティック回帰係数を使用して計算され、対数オッズ比として解釈できます。 -
expected_value — ベースラインデータセットの平均予測値。
use_logit設定がアクティブ化されている場合、値はロジスティック回帰係数を使用して計算されます。 -
global_top_shap_text – NLP の説明可能性分析で使用します。キーと値のペアのセットが含まれている分析ファイルのセクション。SageMaker Clarify 処理ジョブは、各トークンの SHAP 値を集計し、グローバル SHAP 値に基づいて上位のトークンを選択します。
max_top_tokens設定では、選択するトークンの数を定義します。選択した上位トークンにはそれぞれキーと値のペアがあります。キーと値のペアのキーは、上位トークンのテキスト特徴量名に対応しています。キーと値のペアの各値は、上位トークンのグローバル SHAP 値です。
global_top_shap_textキー値のペアの例については、以下の出力を参照してください。
-
-
以下は、表形式データセットの SHAP 分析からの出力例です。
{ "version": "1.0", "explanations": { "kernel_shap": { "Target": { "global_shap_values": { "Age": 0.022486410860333206, "Gender": 0.007381025261958729, "Income": 0.006843906804137847, "Occupation": 0.006843906804137847, ... }, "expected_value": 0.508233428001 } } } }
以下は、テキストデータセットの SHAP 分析からの出力例です。Comments 列に対応する出力は、テキスト特徴量の分析後に生成される出力の例です。
{ "version": "1.0", "explanations": { "kernel_shap": { "Target": { "global_shap_values": { "Rating": 0.022486410860333206, "Comments": 0.058612104851485144, ... }, "expected_value": 0.46700941970297033, "global_top_shap_text": { "charming": 0.04127962903247833, "brilliant": 0.02450240786522321, "enjoyable": 0.024093569652715457, ... } } } } }
生成されたベースラインファイルのスキーマ。
SHAP ベースライン設定が提供されていない場合、SageMaker Clarify 処理ジョブはベースラインデータセットを生成します。SageMaker Clarify は、距離ベースのクラスタリングアルゴリズムを使用して、入力データセットから作成されたクラスターからベースラインデータセットを生成します。結果のベースラインデータセットは、explanations_shap/baseline.csv にある CSV ファイルに保存されます。この出力ファイルには、ヘッダー行と、分析設定で指定された num_clusters パラメータに基づく複数のインスタンスが含まれます。ベースラインデータセットは特徴量列のみで構成されます。以下は、入力データセットをクラスタリングして作成されたベースラインの例です。
Age,Gender,Income,Occupation 35,0,2883,1 40,1,6178,2 42,0,4621,0
表形式データセットの説明可能性分析によるローカル SHAP 値のスキーマ
表形式のデータセットでは、単一のコンピューティングインスタンスが使用されている場合、SageMaker Clarify 処理ジョブはローカル SHAP 値を explanations_shap/out.csv という名前の CSV ファイルに保存します。複数のコンピューティングインスタンスを使用する場合、ローカル SHAP 値は explanations_shap ディレクトリ内の複数の CSV ファイルに保存されます。
ローカル SHAP 値を含む出力ファイルには、ヘッダーで定義されている各列のローカル SHAP 値を含む行があります。ヘッダーは、ヘッダーは、Feature_Label の命名規則に従って特徴量名にアンダースコアが追加され、その後にターゲット変数の名前が続きます。
多クラスの問題では、最初にヘッダーの特徴量名が変わり、次にラベルが変わります。例えば、ヘッダー内の 2 つの特徴量 F1, F2 と 2 つのクラス L1 と L2 は 、F1_L1、F2_L1、F1_L2、F2_L2 となります。分析設定に joinsource_name_or_index パラメータの値が含まれている場合、結合で使用されたキー列がヘッダー名の末尾に追加されます。これにより、ローカル SHAP 値を入力データセットのインスタンスにマッピングできるようになります。SHAP 値を含む出力ファイルの例を以下に示します。
Age_Target,Gender_Target,Income_Target,Occupation_Target 0.003937908,0.001388849,0.00242389,0.00274234 -0.0052784,0.017144491,0.004480645,-0.017144491 ...
NLP の説明可能性分析によるローカル SHAP 値のスキーマ
NLP の説明可能性分析では、単一のコンピューティングインスタンスが使用されている場合、SageMaker Clarify 処理ジョブはローカル SHAP 値を explanations_shap/out.jsonl という名前の JSON Lines ファイルに保存します。複数のコンピューティングインスタンスを使用する場合、ローカル SHAP 値は explanations_shap ディレクトリ内の複数の JSON Lines ファイルに保存されます。
ローカル SHAP 値を含む各ファイルには複数のデータ行があり、各行は有効な JSON オブジェクトです。JSON オブジェクトには以下の属性があります。
-
explanations — 1 つのインスタンスに関するカーネル SHAP の説明の配列を含む分析ファイルのセクション。配列の各要素には次のメンバーがあります。
-
feature_name — headers 設定によって提供される特徴量のヘッダー名。
-
data_type — SageMaker Clarify 処理ジョブによって推測される特徴量タイプ。テキスト特徴量の有効な値には
numerical、categorical、free_text(テキスト特徴量の場合) があります。 -
attributions — 特徴量固有の属性オブジェクトの配列。テキスト特徴量には、
granularity設定で定義された単位ごとに複数の属性オブジェクトを含めることができます。属性オブジェクトには以下のメンバーがあります。-
attribution — クラス固有の確率値の配列。
-
description — (テキスト特徴量の場合) テキスト単位の説明。
-
partial_text — SageMaker Clarify 処理ジョブによって説明されるテキストの部分。
-
start_idx — 部分テキストフラグメントの先頭を示す配列位置を識別する 0 から始まるインデックスです。
-
-
-
以下は、ローカル SHAP 値ファイルの 1 行の例で、読みやすくするために整理されています。
{ "explanations": [ { "feature_name": "Rating", "data_type": "categorical", "attributions": [ { "attribution": [0.00342270632248735] } ] }, { "feature_name": "Comments", "data_type": "free_text", "attributions": [ { "attribution": [0.005260534499999983], "description": { "partial_text": "It's", "start_idx": 0 } }, { "attribution": [0.00424190349999996], "description": { "partial_text": "a", "start_idx": 5 } }, { "attribution": [0.010247314500000014], "description": { "partial_text": "good", "start_idx": 6 } }, { "attribution": [0.006148907500000005], "description": { "partial_text": "product", "start_idx": 10 } } ] } ] }
SHAP 分析レポート
SHAP 分析レポートには、最大 10 個の上位グローバル SHAP 値の棒グラフが表示されます。次のグラフの例は、上位 4 つの特徴量の SHAP 値を示しています。
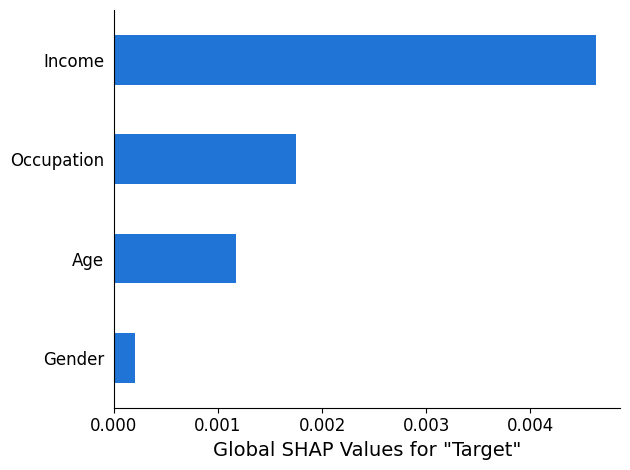
コンピュータービジョン (CV) の説明可能性分析
SageMaker Clarify コンピュータビジョンの説明可能性は、画像で構成されるデータセットを取得し、各画像をスーパーピクセルの集合として扱います。分析後、SageMaker Clarify 処理ジョブは画像のデータセットを出力します。各画像にはスーパーピクセルのヒートマップが表示されます。
次の例は、左側に入力された速度制限標識、右側に SHAP 値の大きさを示すヒートマップを示しています。これらの SHAP 値は、ドイツの交通標識

詳細については、サンプルノートブックの「Explaining Image Classification with SageMaker Clarify
部分依存プロット (PDP) 分析
部分依存プロットは、対象の一連の入力特徴量に対する予測ターゲットレスポンスの依存性を示します。これらは、他のすべての入力特徴量の値よりも周辺化され、補完特徴量と呼ばれます。直感的に、部分依存をターゲットレスポンスとして解釈できます。これは、対象の各入力特徴量の関数として期待されます。
分析ファイルのスキーマ
PDP 値は、pdp メソッドに基づいて分析ファイルの explanations セクションに保存されます。explanations 用のパラメータは次のとおりです。
-
explanations — 特徴量重要度の分析結果を含む分析ファイルのセクション。
-
pdp — 1 つのインスタンスに関する PDP の説明の配列を含む分析ファイルのセクション。配列の各要素には次のメンバーがあります。
-
feature_name —
headers設定によって提供される特徴量のヘッダー名。 -
data_type — SageMaker Clarify 処理ジョブによって推測される特徴量タイプ。
data_typeの有効な値には、数値とカテゴリが含まれます。 -
feature_values — 特徴量に存在する値が含まれます。SageMaker Clarify によって推論される
data_typeがカテゴリの場合、feature_valuesには、その特徴量が取り得るすべての一意の値が含まれます。SageMaker Clarify によって推論されるdata_typeが数値の場合、feature_valuesには生成されたバケットの中心値のリストが含まれます。grid_resolutionパラメータは、特徴量列の値をグループ化するために使用されるバケットの数を決定します。 -
data_distribution — 割合の配列。各値はバケットに含まれるインスタンスの割合です。
grid_resolutionパラメータは、バケットの数を決定します。特徴量列の値はこれらのバケットにグループ化されます。 -
model_predictions — モデル予測の配列。配列の各要素は、モデルの出力内の 1 つのクラスに対応する予測の配列です。
label_headers —
label_headers設定によって提供されるラベルヘッダー。 -
error — 特定の理由で PDP 値が計算されなかった場合に生成されるエラーメッセージ。このエラー メッセージは
feature_values、data_distributions、model_predictionsフィールドに含まれるコンテンツを置き換えます。
-
-
以下は、PDP 分析結果を含む分析ファイルからの出力例です。
{ "version": "1.0", "explanations": { "pdp": [ { "feature_name": "Income", "data_type": "numerical", "feature_values": [1046.9, 2454.7, 3862.5, 5270.2, 6678.0, 8085.9, 9493.6, 10901.5, 12309.3, 13717.1], "data_distribution": [0.32, 0.27, 0.17, 0.1, 0.045, 0.05, 0.01, 0.015, 0.01, 0.01], "model_predictions": [[0.69, 0.82, 0.82, 0.77, 0.77, 0.46, 0.46, 0.45, 0.41, 0.41]], "label_headers": ["Target"] }, ... ] } }
PDP 分析レポート
各特徴量の PDP チャートを含む分析レポートを生成できます。PDP チャートは X 軸に沿って feature_values をプロットし、Y 軸に沿って model_predictions をプロットします。多クラスモデルの場合、model_predictions は配列であり、この配列の各要素はモデル予測クラスのいずれかに対応します。
以下は、特徴量 Age の PDP チャートの例です。出力例では、PDP はバケットにグループ化された特徴量値の数を示しています。バケット数は grid_resolution によって決まります。特徴量値のバケットはモデル予測と照合してプロットされます。この例では、特徴量値が高いほどモデル予測値は同じになります。
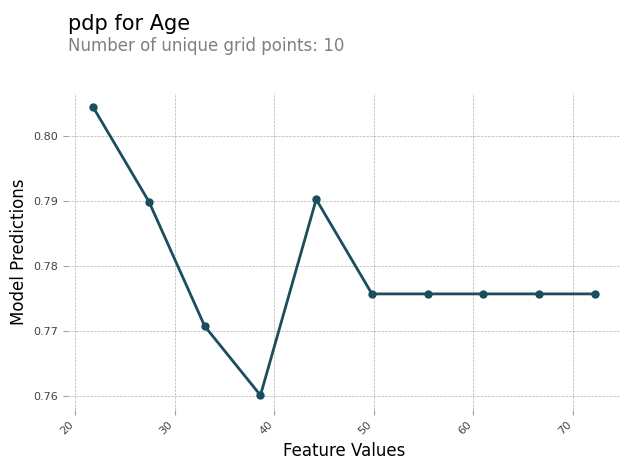
非対称 Shapley 値
SageMaker Clarify 処理ジョブは、非対称 Shapley 値アルゴリズムを使用して、時系列予測モデルの説明の貢献度を計算します。このアルゴリズムは、得られた予測に対する各時間ステップの入力特徴量の貢献度を決定します。
非対称 Shapley 値分析ファイルのスキーマ
非対称 Shapley 値の結果は Amazon S3 バケットに保存されます。このバケットの場所は、分析ファイルの説明セクションで指定されています。このセクションでは、特徴量の重要度分析結果について説明します。非対称 Shapley 値分析ファイルには、以下のパラメータが含まれています。
asymmetric_shapley_value — 説明ジョブの結果に関するメタデータを含む分析ファイルのセクション。コンテンツは以下のとおりです。
explanation_results_path — 説明結果を含む Amazon S3 の場所
direction —
directionの設定値に対するユーザー指定の設定granularity —
granularityの設定値に対するユーザー指定の設定
次のスニペットは、上記のパラメータをサンプル分析ファイルで使用しています。
{ "version": "1.0", "explanations": { "asymmetric_shapley_value": { "explanation_results_path": EXPLANATION_RESULTS_S3_URI, "direction": "chronological", "granularity": "timewise", } } }
以下のセクションでは、説明結果の構造が設定の granularity の値によってどのように影響されるかについて説明します。
時間単位の粒度
粒度が timewise の場合、出力は次の構造で表されます。scores 値は、各タイムスタンプの貢献度を表します。offset 値は、ベースラインデータ上のモデルの予測を表し、モデルがデータを受信していない場合のモデルの動作を記述します。
次のスニペットは、2 つの時間ステップの予測を行うモデルの出力例を説明しています。このため、すべての貢献度は、2 つの要素のリストであり、最初のエントリは最初の予測時間ステップを参照します。
{ "item_id": "item1", "offset": [1.0, 1.2], "explanations": [ {"timestamp": "2019-09-11 00:00:00", "scores": [0.11, 0.1]}, {"timestamp": "2019-09-12 00:00:00", "scores": [0.34, 0.2]}, {"timestamp": "2019-09-13 00:00:00", "scores": [0.45, 0.3]}, ] } { "item_id": "item2", "offset": [1.0, 1.2], "explanations": [ {"timestamp": "2019-09-11 00:00:00", "scores": [0.51, 0.35]}, {"timestamp": "2019-09-12 00:00:00", "scores": [0.14, 0.22]}, {"timestamp": "2019-09-13 00:00:00", "scores": [0.46, 0.31]}, ] }
きめ細かな粒度
次の例は、粒度が fine_grained の場合の貢献度の結果を説明しています。offset 値は、前のセクションでの説明と同じ意味を持ちます。貢献度は、ターゲット時系列と関連する時系列 (ある場合) のタイムスタンプごとに各入力特徴量について計算され、利用可能な場合は静的共変量ごとに計算されます。
{ "item_id": "item1", "offset": [1.0, 1.2], "explanations": [ {"feature_name": "tts_feature_name_1", "timestamp": "2019-09-11 00:00:00", "scores": [0.11, 0.11]}, {"feature_name": "tts_feature_name_1", "timestamp": "2019-09-12 00:00:00", "scores": [0.34, 0.43]}, {"feature_name": "tts_feature_name_2", "timestamp": "2019-09-11 00:00:00", "scores": [0.15, 0.51]}, {"feature_name": "tts_feature_name_2", "timestamp": "2019-09-12 00:00:00", "scores": [0.81, 0.18]}, {"feature_name": "rts_feature_name_1", "timestamp": "2019-09-11 00:00:00", "scores": [0.01, 0.10]}, {"feature_name": "rts_feature_name_1", "timestamp": "2019-09-12 00:00:00", "scores": [0.14, 0.41]}, {"feature_name": "rts_feature_name_1", "timestamp": "2019-09-13 00:00:00", "scores": [0.95, 0.59]}, {"feature_name": "rts_feature_name_1", "timestamp": "2019-09-14 00:00:00", "scores": [0.95, 0.59]}, {"feature_name": "rts_feature_name_2", "timestamp": "2019-09-11 00:00:00", "scores": [0.65, 0.56]}, {"feature_name": "rts_feature_name_2", "timestamp": "2019-09-12 00:00:00", "scores": [0.43, 0.34]}, {"feature_name": "rts_feature_name_2", "timestamp": "2019-09-13 00:00:00", "scores": [0.16, 0.61]}, {"feature_name": "rts_feature_name_2", "timestamp": "2019-09-14 00:00:00", "scores": [0.95, 0.59]}, {"feature_name": "static_covariate_1", "scores": [0.6, 0.1]}, {"feature_name": "static_covariate_2", "scores": [0.1, 0.3]}, ] }
timewise のユースケースと fine-grained のユースケースの両方で、結果は JSON 行 (.jsonl) 形式で保存されます。
