翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
SageMaker AI 分散データ並列処理ライブラリの概要
SageMaker AI 分散データ並列処理 (SMDDP) ライブラリは、分散データ並列トレーニングのコンピューティングパフォーマンスを向上させる集合通信ライブラリです。SMDDP ライブラリは次の機能を提供し、主要な集合通信演算の通信オーバーヘッドに対処します。
-
このライブラリは、 向けに
AllReduce最適化されています AWS。AllReduceは、分散データトレーニング中の各トレーニング反復の終了時に GPUs 間で勾配を同期するために使用される主要なオペレーションです。 -
このライブラリは、 向けに
AllGather最適化されています AWS。AllGatherは、シャーディングデータ並列トレーニングで使用されるもう 1 つの主要なオペレーションです。これは、SageMaker AI モデル並列処理 (SMP) ライブラリ、DeepSpeed Zero Redundancy Optimizer (ZeRO)、PyTorch Fully Sharded Data Parallelism (FSDP) などの一般的なライブラリによって提供されるメモリ効率の高いデータ並列処理手法です。 -
このライブラリは、 AWS ネットワークインフラストラクチャと Amazon EC2 インスタンストポロジを最大限に活用することで、node-to-node通信を実行します。
SMDDP ライブラリは、トレーニングクラスターをスケールした際に、ほぼ線形のスケーリング効率でパフォーマンスを向上させることで、トレーニング速度を向上させることができます。
注記
SageMaker AI 分散トレーニングライブラリは、SageMaker トレーニングプラットフォーム内の PyTorch と Hugging Face 用の AWS 深層学習コンテナから入手できます。ライブラリを使うには、SageMaker Python SDK を使うか、SDK for Python (boto3) または AWS Command Line Interfaceから SageMaker API を使う必要があります。このドキュメントの説明と例では、SageMaker Python SDK を使った分散トレーニングライブラリの使用方法に焦点を当てています。
AWS コンピューティングリソースとネットワークインフラストラクチャ用に最適化された SMDDP 集合通信オペレーション
SMDDP ライブラリは、 AWS コンピューティングリソースAllReduceとネットワークインフラストラクチャに最適化された および AllGather集合演算の実装を提供します。
SMDDP AllReduce 集合演算
SMDDP ライブラリは、AllReduce 演算とバックワードパス (逆伝播) を最適にオーバーラップさせて、GPU の使用率を大幅に向上させます。CPU と GPU 間のカーネル操作を最適化することで、ほぼ線形のスケーリング効率とトレーニングの高速化を実現します。GPU が勾配を計算している間に AllReduce を並列で実行し、追加の GPU サイクルは不要なため、トレーニングをより迅速に行えるようになります。
-
CPU の活用: CPU を使って勾配の
AllReduceを実行し、このタスクを GPU からオフロードします。 -
GPU 使用率の向上: クラスターの GPU は、勾配の計算に集中し、トレーニング全体における GPUの使用率を向上させます。
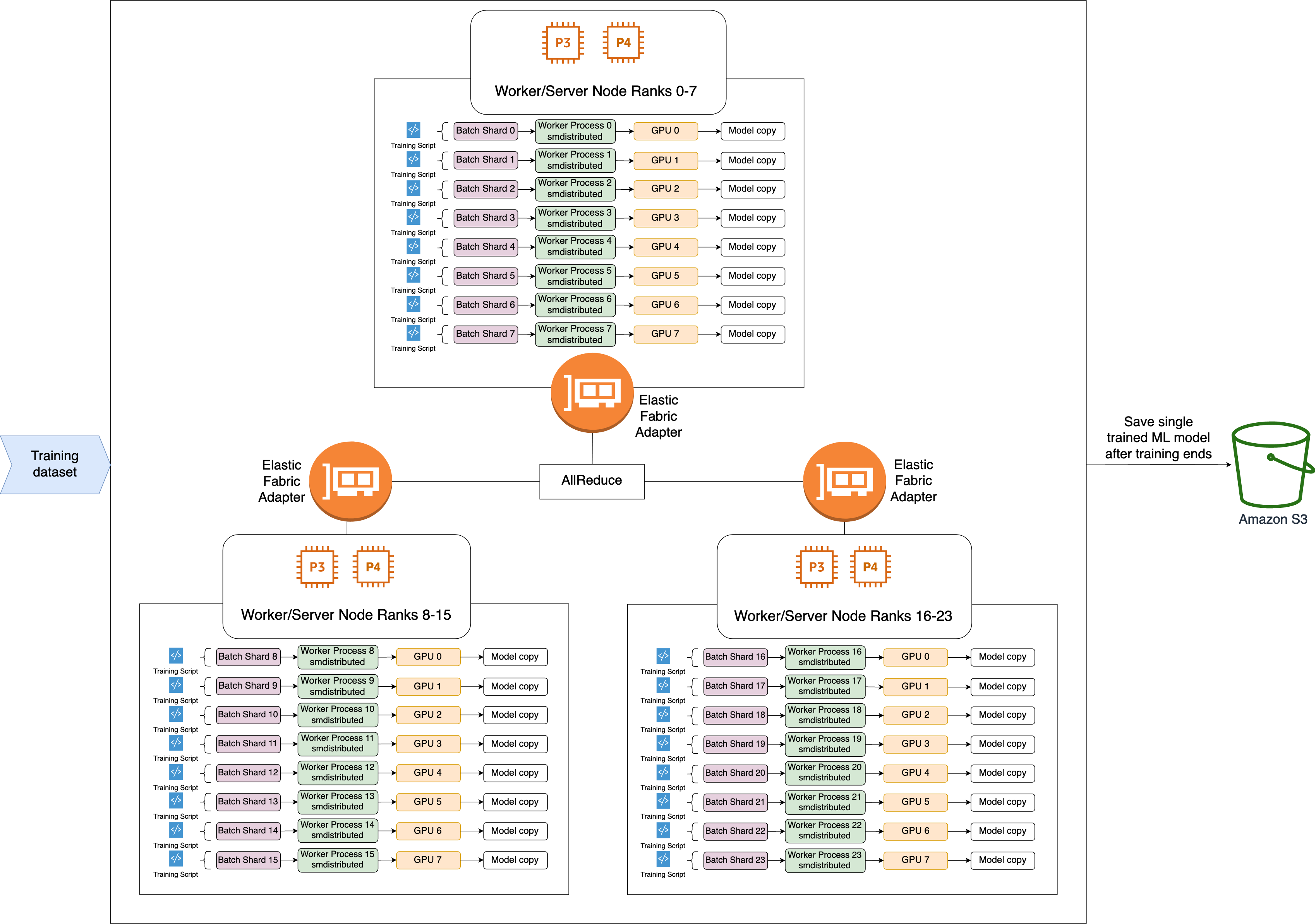
以下は、SMDDP AllReduce 演算のワークフローの概要図です。
-
ライブラリは GPU (ワーカー) にランクを与えます。
-
ライブラリは各反復で、各グローバルバッチをワーカーの総数 (ワールドサイズ) で割り、小さなバッチ (バッチシャード) をワーカーに割り当てます。
-
グローバルバッチのサイズは
(number of nodes in a cluster) * (number of GPUs per node) * (per batch shard)です。 -
バッチシャード (小さなバッチ) とは、反復ごとに各 GPU (ワーカー) に割り当てられるデータセットのサブセットです。
-
-
ライブラリは、各ワーカーでトレーニングスクリプトを起動します。
-
ライブラリは、ワーカーからのモデルの重みと勾配のコピーを、各反復の終了時に管理します。
-
ライブラリは、ワーカー間でモデルの重みと勾配を同期させて、1 つのトレーニング済みモデルに集約します。
次のアーキテクチャ図は、ライブラリが 3 ノードからなるクラスターに対してどのようにデータ並列処理を設定するかの例を示しています。
SMDDP AllGather 集合演算
AllGather は、各ワーカーがまず入力バッファを処理した後、他のすべてのワーカーからの入力バッファを連結 (gather) して 1 つの出力バッファにまとめる集合演算です。
注記
SMDDP AllGather集合演算は、PyTorch v2.0.1 以降の smdistributed-dataparallel>=2.0.1および AWS Deep Learning Containers (DLC) で使用できます。
AllGather は、個々のワーカーがモデルの一部 (シャーディングされた層) を保持するシャーディングデータ並列処理など、分散トレーニング手法で多用されます。ワーカーは、フォワードパス (順伝播) とバックワードパス (逆伝播) の前に AllGather を呼び出して、シャーディング (分割) された層を再構築します。パラメータがすべて収集 (all gather) された後、フォワードパスとバックワードパスが続行されます。バックワードパス中、各ワーカーは ReduceScatter を呼び出して勾配を集約 (reduce) し、勾配シャードに分割 (scatter) して、対応するシャーディングされた層を更新します。シャーディングデータ並列処理におけるこれらの集合演算の役割の詳細については、SMP ライブラリのシャーディングデータ並列処理の実装、DeepSpeed ドキュメントの「ZeRO
AllGather のような集合演算はすべてのイテレーションで呼び出されるため、GPU 通信オーバーヘッドの主な要因となります。これらの集合演算の計算速度が上がれば、収束に支障をきたすことなく、トレーニング時間の短縮に直結します。これを実現するために、SMDDP ライブラリは P4d インスタンスAllGather を提供しています。
SMDDP AllGather は、次の手法を使用して P4d インスタンス上で計算性能を向上させます。
-
インスタンス間 (ノード間) のデータ転送は、メッシュトポロジーを用いた Elastic Fabric Adapter (EFA) ネットワーク
を介して行われます。EFA は AWS 、低レイテンシーで高スループットのネットワークソリューションです。ノード間ネットワーク通信のメッシュトポロジは、EFA と AWS ネットワークインフラストラクチャの特性により適しています。NCCL のリングトポロジーやツリートポロジーは複数のパケットホップを伴いますが、それと比較して SMDDP は 1 回のホップで済むため、複数のホップによるレイテンシーの蓄積を回避します。SMDDP は、メッシュトポロジー内の各通信ピアに負荷を分散させるネットワーク速度制御アルゴリズムを実装し、全体的なネットワークスループットを向上させます。 -
NVIDIA GPUDirect RDMA テクノロジー (GDRCopy) に基づく低レイテンシーの GPU メモリコピーライブラリ
を採用して、ローカル NVLink と EFA ネットワークトラフィックを調整します。GDRCopy は、NVIDIA が提供する低レイテンシーの GPU メモリコピーライブラリです。CPU プロセスと GPU CUDA カーネル間の低レイテンシー通信を実現します。このテクノロジーを利用することで、SMDDP ライブラリはノード内およびノード間のデータ移動をパイプライン化できます。 -
GPU ストリーミングマルチプロセッサの使用を減らし、モデルカーネルを実行するための計算能力を増強します。P4d インスタンスと P4de インスタンスは NVIDIA A100 GPU を搭載し、それぞれに 108 のストリーミングマルチプロセッサがあります。NCCL は、集合演算を実行するために最大 24 のストリーミングマルチプロセッサを使用しますが、SMDDP が使用するストリーミングマルチプロセッサ数は 9 未満です。モデルの計算カーネルは、空いた分のストリーミングマルチプロセッサを使用して、より迅速に計算を処理します。
