翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Debugger の高度なデモと視覚化
次のデモでは、デバッガーを使用した高度なユースケースと視覚化スクリプトを具体的に説明します。
トピック
Amazon SageMaker Experiments と Debugger を使用したモデルのトレーニングとプルーニング
Dr. Nathalie Rauschmayr、 AWS 応用科学者 | 長さ: 49 分 26 秒
Amazon SageMaker 実験とデバッガーがトレーニングジョブの管理を簡素化する方法を理解してください。Amazon SageMaker デバッガーは、トレーニングジョブを透過的に視覚化し、Amazon S3 バケットにトレーニングメトリクスを保存します。SageMaker 実験は、SageMaker Studio を通じてトレーニング情報をトライアルとして呼び出すことを可能にし、トレーニングジョブの視覚化をサポートします。これにより、重要度のランクに基づいて重要度の低いパラメータを減らしながら、モデルの品質を高く維持できます。
このビデオでは、高いモデル精度基準を維持しながら、事前トレーニング済みの RESNet50 および AlexNet モデルをより軽く手頃にするモデルプルーニング手法について紹介します。
SageMaker AI 推定器は、PyTorch フレームワークを使用した AWS Deep Learning Containers 内の PyTorch の model zoo から提供されたアルゴリズムをトレーニングし、デバッガーはトレーニングプロセスからトレーニングメトリクスを抽出します。
この動画では、プルーニングされたモデルの精度を監視し、精度がしきい値に達したときに Amazon CloudWatch イベントと AWS Lambda 関数をトリガーし、冗長な反復を避けるためにプルーニングプロセスを自動的に停止するようにデバッガーカスタムルールを設定する方法も示しています。
学習目標は次のとおりです。
-
SageMaker AI を使って ML モデルトレーニングを高速化しモデルの品質を改善する方法を学ぶ。
-
入力パラメータ、設定、結果を自動的にキャプチャして、 SageMaker 実験を使ってトレーニングの反復を管理する方法について理解する。
-
畳み込みニューラルネットワークの重み、勾配、アクティベーション出力などのメトリクスからリアルタイムテンソルデータを自動的にキャプチャすることで、デバッガーがトレーニングプロセスを透過的にする方法を発見する。
-
CloudWatch を使って、デバッガーが問題を検出したときに Lambda をトリガーする。
-
SageMaker 実験とデバッガーを使った SageMaker トレーニングプロセスをマスターする。
このビデオで使用されているノートブックとトレーニングスクリプトは、「SageMaker デバッガー PyTorch 反復モデルプルーニング
次の図は、反復モデルのプルーニングプロセスが、アクティベーション出力とグラデーションによって評価される重要度ランクに基づいて、下位 100 個のフィルターを切り取って AlexNet のサイズを縮小する方法を示しています。
プルーニングプロセスにより、最初は 5,000 万個のパラメータが 1,800 万個に削減されました。また、推定モデルサイズが 201MB から 73MB に縮小されました。

モデルの精度も追跡する必要があります。次の図では、モデルのプルーニングプロセスをプロットして、SageMaker Studio のパラメータ数に基づいてモデルの精度の変化を視覚化する方法を示しています。

SageMaker Studio で、[Experiments] (実験) タブを選択し、デバッガーがプルーニングプロセスから保存したテンソルのリストを選択してから、[Trial Component List] (トライアルコンポーネントリスト) パネルを作成します。10 個の反復をすべて選択し、[Add chart] (グラフを追加) を選択してトライアルコンポーネントグラフを作成します。デプロイするモデルを決定したら、トライアルコンポーネントを選択し、アクションを実行するメニューを選択するか、[Deploy model] (モデルをデプロイ) を選択します。
注記
次のノートブックの例を使って SageMaker Studio でモデルをデプロイするには、train.py スクリプトの train 関数の末尾に行を追加します。
# In the train.py script, look for the train function in line 58. def train(epochs, batch_size, learning_rate): ... print('acc:{:.4f}'.format(correct/total)) hook.save_scalar("accuracy", correct/total, sm_metric=True) # Add the following code to line 128 of the train.py script to save the pruned models # under the current SageMaker Studio model directorytorch.save(model.state_dict(), os.environ['SM_MODEL_DIR'] + '/model.pt')
SageMaker デバッガーを使用した畳み込み自動エンコーダーモデルのトレーニングのモニタリング
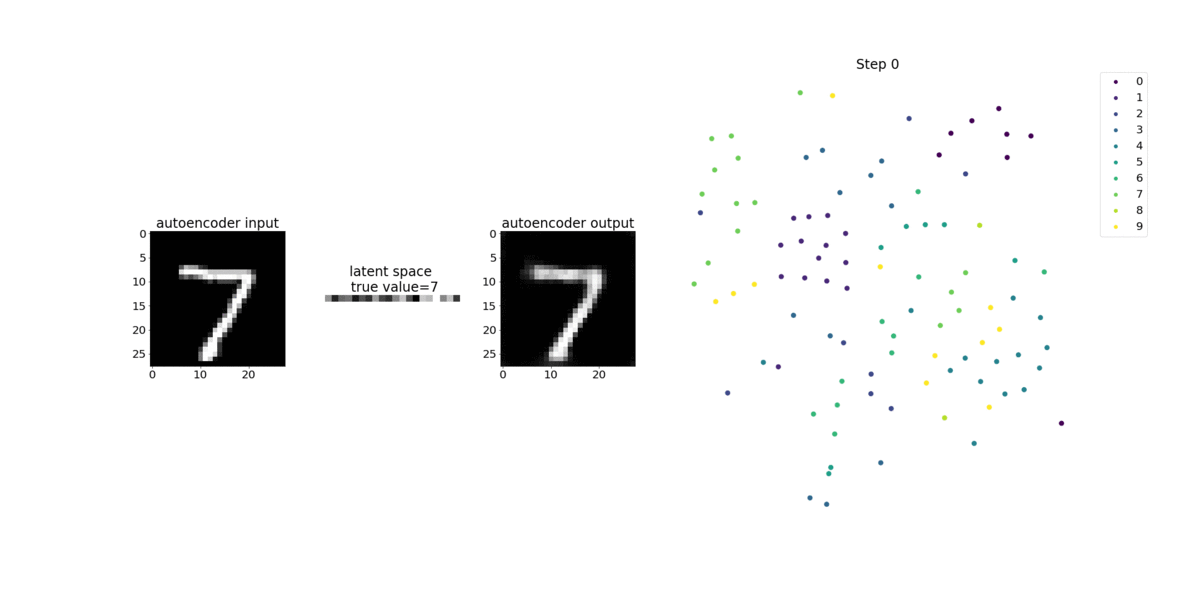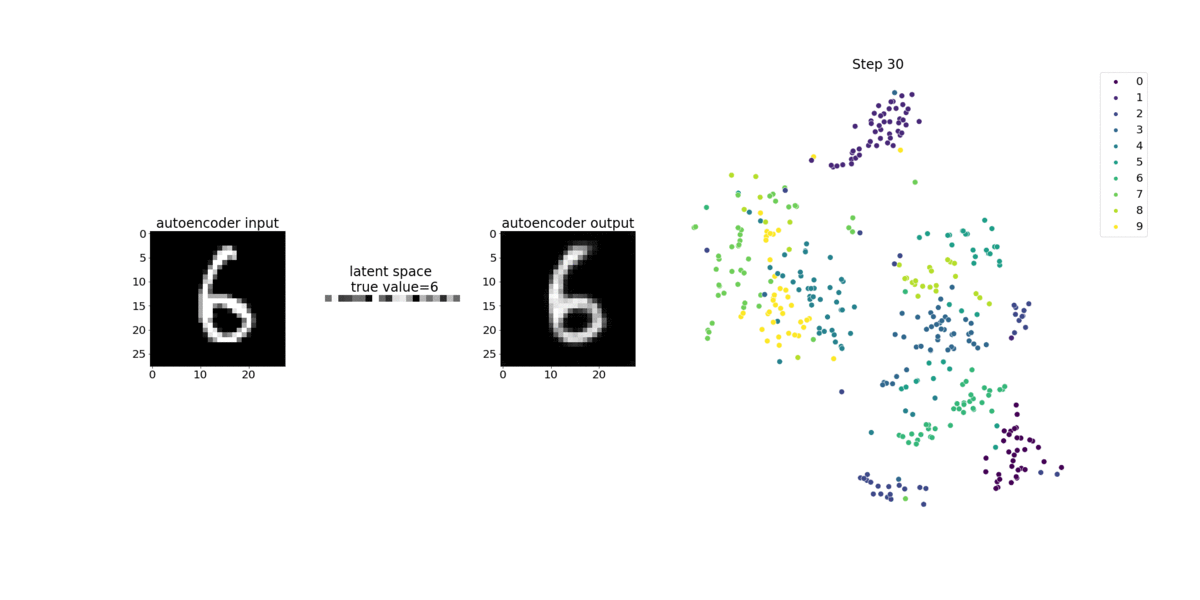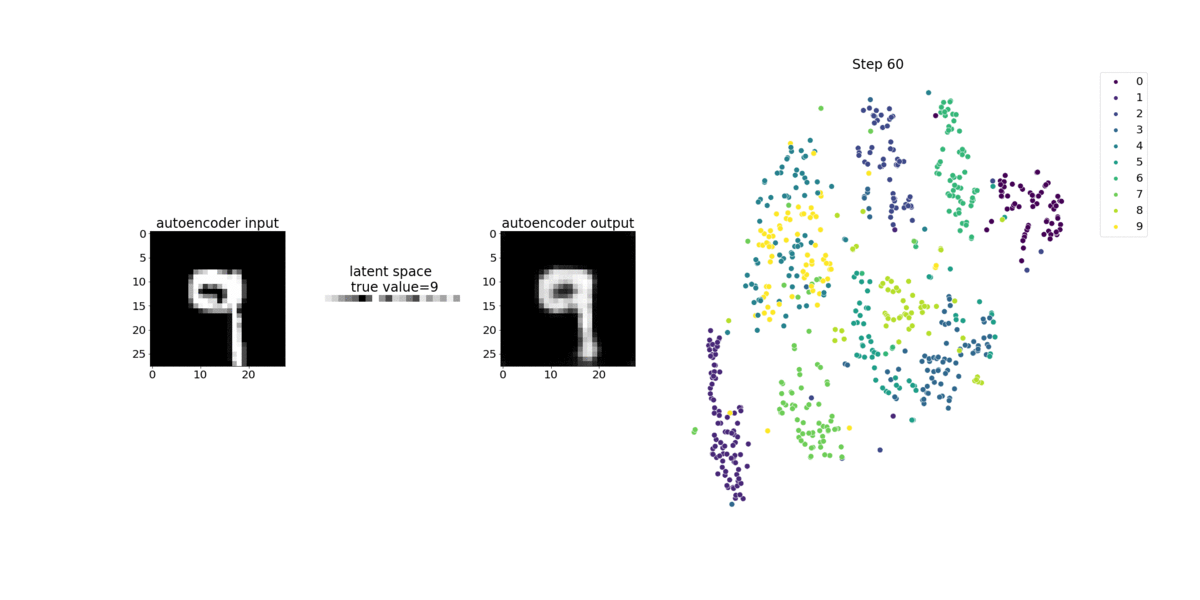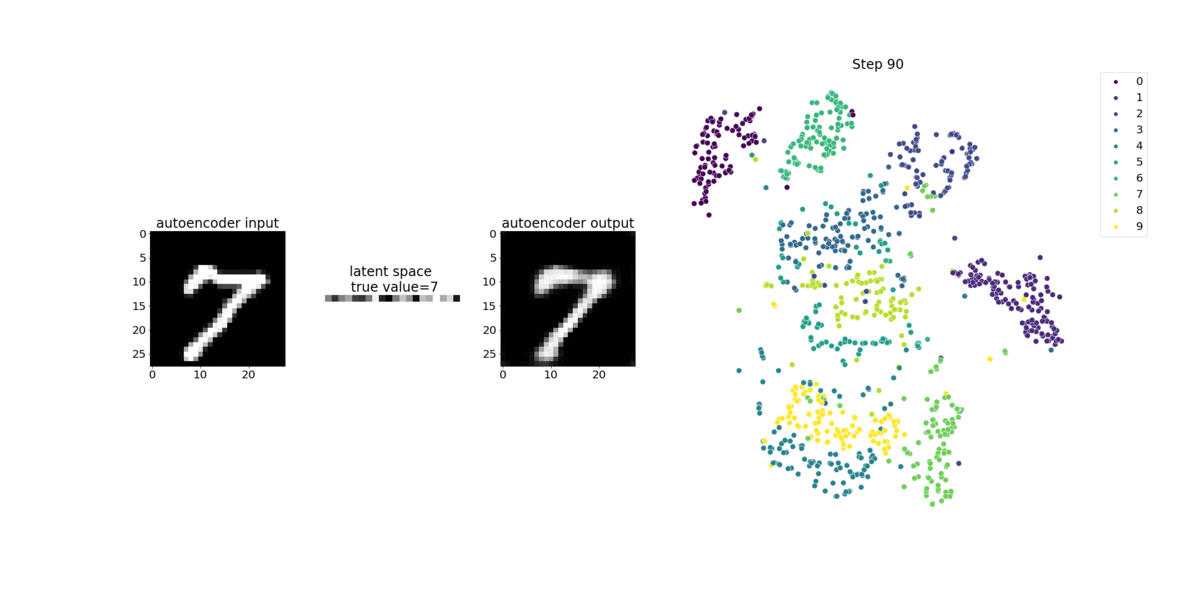
このノートブックでは、SageMaker デバッガーが手書き数字の MNIST イメージデータセット上で、教師なし (または自己教師あり) 学習プロセスからのテンソルを視覚化する方法を示しています。
このノートブックのトレーニングモデルは、MXNet フレームワークを使用した畳み込み式オートエンコーダです。畳み込みオートエンコーダは、エンコーダ部分とデコーダ部分からなるボトルネック型の畳み込みニューラルネットワークを持っています。
この例のエンコーダには、入力イメージの圧縮表現 (潜在変数) を生成するために、2 つの畳み込みレイヤーがあります。この場合、エンコーダは、サイズ (28、28) の元の入力イメージからサイズ (1、20) の潜在変数を生成し、トレーニングのデータサイズを 40 分の 1 まで大幅に縮小します。
デコーダは 2 つの畳み込み解除レイヤーを持ち、潜在変数が出力イメージを再構築することによって重要な情報を保持することを保証します。
畳み込みエンコーダは、より小さな入力データサイズでクラスタリングアルゴリズムを強化し、k-means、k-NN、t 分布型確率的近傍埋め込み法 (t-SNE) などのクラスタリングアルゴリズムのパフォーマンスを強化します。
このノートブックの例では、次のアニメーションに示すように、デバッガーを使って潜在変数を視覚化する方法を示しています。また、t-SNE アルゴリズムが潜在変数を 10 個のクラスターに分類し、それらを 2 次元空間に投影する方法も示しています。図の右側にある散布図の配色は、BERT モデルと t-SNE アルゴリズムが潜在変数をクラスターにどの程度適切に整理しているかを示す真の値を反映しています。
SageMaker デバッガーを使用して BERT モデルトレーニングの注意をモニタリングする
Transformer による双方向エンコード表現 (BERT) は、言語表現モデルです。モデルの名前が表すように、BERTモデルは、自然言語処理 (NLP) のための転送学習と Transformer モデルに基づいて構築されます。
BERT モデルは、文中の欠けている単語を予測したり、前の文に自然に続く次の文を予測するなどの教師なしタスクでに事前トレーニングされています。トレーニングデータには、Wikipedia や電子書籍などのソースから、33 億語 (トークン) の英文が含まれています。簡単な例として、BERT モデルは対象トークンから適切な動詞トークンまたは代名詞トークンに高いアテンションを付与することができます。
事前トレーニングされた BERT モデルは、追加の出力レイヤーを使って微調整することができ、質問への自動応答、テキスト分類など、NLP タスクにおける最先端のモデルトレーニングを達成します。
デバッガーは、微調整プロセスからテンソルを収集します。NLP のコンテキストでは、ニューロンの重みはアテンションと呼ばれます。
このノートブックでは、Stanford Question and Answering データセットで GluonNLP の model zoo から事前トレーニングされた BERT モデル
クエリとキーベクトルにアテンションスコアと個々のニューロンをプロットすると、誤ったモデル予測の原因を特定するのに役立ちます。SageMaker AI デバッガーを使うと、テンソルを取得し、トレーニングの進行に応じてリアルタイムでアテンションヘッドビューをプロットし、モデルが学習している内容を理解できます。
次のアニメーションは、ノートブックの例で提供されているトレーニングジョブにおける 10 個の反復に対する最初の 20 個の入力トークンのアテンションスコアを示しています。

SageMaker デバッガーを使用して畳み込みニューラルネットワーク (CNNs) のクラスアクティベーションマップを視覚化する
このノートブックでは、SageMaker デバッガーを使って、畳み込みニューラルネットワーク (CNN) でのイメージの検出と分類のためのクラスアクティベーションマップをプロットする方法について説明します。深層学習では、畳み込みニューラルネットワーク (CNN または ConvNet)は、視覚的イメージの分析に最も一般的に適用される深層ニューラルネットワークのクラスです。クラスアクティベーションマップを採用した用途の 1 つに自動運転車があり、交通標識、道路、障害物などのイメージの瞬時の検出と分類が必須とされます。
このノートブックでは、PyTorch RESnet モデルを German Traffic Sign Dataset データセット

トレーニングプロセス中、SageMaker デバッガーはテンソルを収集し、クラスアクティベーションマップをリアルタイムでプロットします。アニメーションイメージに示すように、クラスアクティベーションマップ (顕著性マップとも呼ばれます) は、アクティベーションの高い領域を赤色で強調表示します。
デバッガーによってキャプチャされたテンソルを使うと、モデルトレーニング中にアクティベーションマップがどのように進化するかを視覚化できます。モデルは、トレーニングジョブの開始時に左下隅のエッジを検出することから始まります。トレーニングが進むにつれ、焦点が中央にシフトして制限速度標識を検出し、97% の信頼度でクラス 3 (制限速度 60km/h 標識のクラス) として入力イメージを予測することに成功します。
