翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
モデルのコンパイル (Amazon SageMaker AI コンソール)
Amazon SageMaker Neo コンパイルジョブはAmazon SageMakerコンソールで作成できます。
Amazon SageMaker AI コンソールで、コンパイルジョブを選択し、コンパイルジョブの作成を選択します。
[Create compilation job] (コンパイルジョブの作成) ページで、[Job name] (ジョブ名) に名前を入力します。次に、[IAM ロール] を選択します。
![[コンパイルジョブの作成] ページ。](images/neo/9-create-compilation-job-config.png)
IAM ロールがない場合は、[新しいロールを作成] を選択してください。
[IAM ロールを作成] ページで、[任意の S3 バケット] を選択し、[ロールを作成] を選択します。
![[IAM ロールを作成] ページ。](images/neo/10-create-iam-role.png)
-
-
[Output configuration] (出力設定) セクションに移動します。モデルをデプロイする場所を選択します。[Target device] (ターゲットデバイス) または [Target platform] (ターゲットプラットフォーム) にモデルをデプロイできます。ターゲットデバイスには、クラウドやエッジデバイスがあります。ターゲットプラットフォームは、モデルを実行する特定の OS、アーキテクチャ、アクセラレーターを参照します。
[S3 Output location] (S3 出力場所) には、モデルを保存する S3 バケットへのパスを入力します。必要に応じて、JSON 形式のコンパイラオプションを[Compiler options] (コンパイラオプション) セクションに追加できます。
![[出力設定] ページ。](images/neo/neo-console-output-config.png)
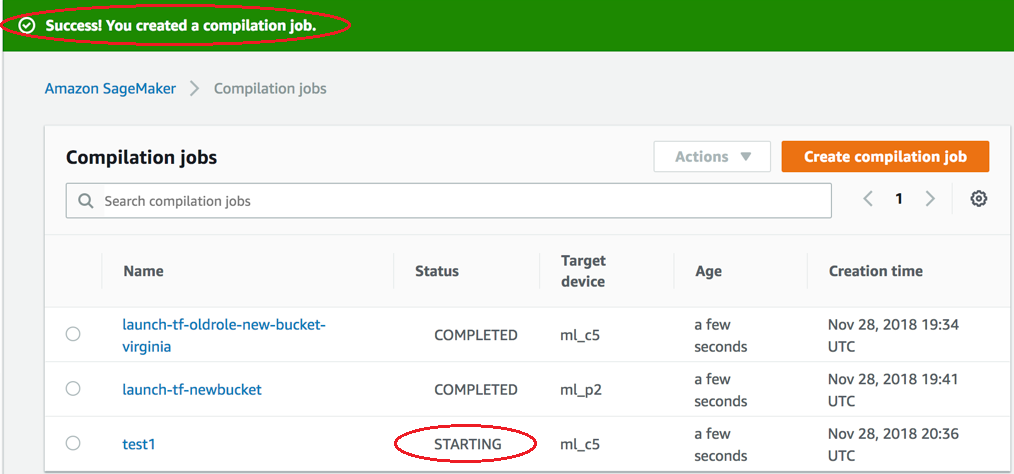
開始時にコンパイルジョブのステータスを確認してください。次のスクリーンショットに示すとおり、このジョブステータスは、[Compilation jobs] (コンパイルジョブ) ページの上部にあります。[Status] (状態) 列でもジョブのステータスを確認できます。
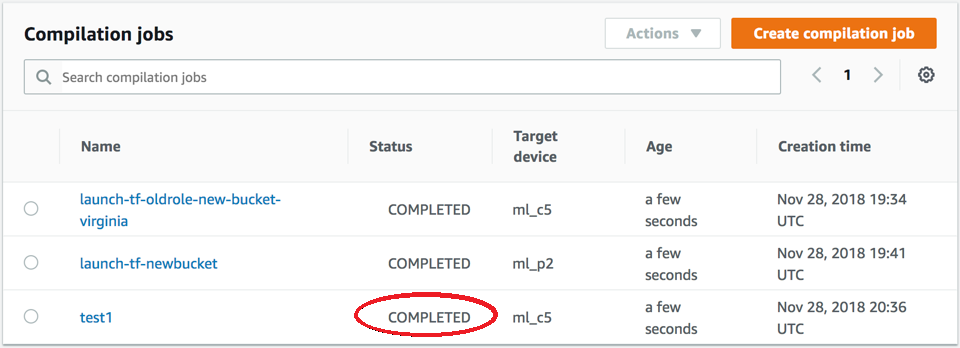
完了時にコンパイルジョブのステータスを確認してください。次のスクリーンショットに示すように、[Status] (状態) 列でステータスを確認できます。
![[入力設定] ページ。](images/neo/neo-create-compilation-job-input-config.png)
![[Framework バージョン] を選択する場所を示す [入力設定] セクションの例。](images/neo/compile_console_pytorch.png)
![[出力設定] セクションの例。](images/neo/neo_compilation_console_pytorch_compiler_options.png)
