翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Object2Vec の仕組み
Amazon SageMaker AI Object2Vec アルゴリズムを使用する場合は、データの処理、モデルのトレーニング、推論の生成という標準ワークフローに従います。
ステップ 1: データを処理する
前処理中に、データを「Object2Vec トレーニングのデータ形式」で指定した JSON Linesnp.random.shuffle、Unix の場合は shuf を使用します。
ステップ 2: モデルをトレーニングする
SageMaker AI Object2Vec アルゴリズムには、次の主要コンポーネントがあります。
-
2 つの入力チャネル - 入力チャネルは、同じタイプまたは異なるタイプのオブジェクトのペアを入力として受け取り、それらを独立したカスタマイズ可能なエンコーダーに渡します。
-
2 つのエンコーダー - enc0 および enc1 の 2 つのエンコーダーは、各オブジェクトを固定長の埋め込みベクトルに変換します。ペアになっているオブジェクトのエンコードされた埋め込みは、コンパレーターに渡されます。
-
コンパレーター - コンパレーターはさまざまな方法で埋め込みを比較し、ペアになったオブジェクト間の関係の強さを示すスコアを出力します。センテンスのペアに対する出力スコア。たとえば、1 はセンテンスのペア間の強い関係を示し、0 は弱い関係を表します。
トレーニング中、アルゴリズムはオブジェクトのペアとそれらの関係ラベルまたはスコアを入力として受け入れます。以前に示したように、各ペアではさまざまなタイプのオブジェクトを使用できます。両方のエンコーダへの入力が同じトークンレベルの単位で構成されている場合は、トレーニングジョブを作成するときに tied_token_embedding_weight ハイパーパラメータを True に設定することで、共有トークン埋め込みレイヤーを使用できます。たとえば、両方に単語トークンレベルの単位を含むセンテンスを比較する場合などです。指定した比率で負のサンプルを生成するには、負のサンプルの希望する比率のハイパーパラメータ negative_sampling_rate を正のサンプルの比率に設定します。このハイパーパラメータによって、観察された正のサンプルとそれ以外の負のサンプルを区別しやすくなります。
オブジェクトのペアは、対応するオブジェクトの入力タイプと互換性のある、カスタマイズ可能な独立したエンコーダーを経由して渡されます。エンコーダーは、ペアになっている各オブジェクトを同じ長さの固定長埋め込みベクトルに変換します。ベクトルのペアは比較演算子に渡され、比較演算子は comparator_list ハイパーパラメータで指定された値を使用してベクトルを単一のベクトルにアセンブルします。アセンブルされたベクトルは、多層パーセプトロン (MLP) レイヤーを通過します。これにより、損失関数によって、ユーザーが指定したラベルと比較する出力が生成されます。この比較では、モデルによって予測されるように、ペアのオブジェクト間の関係の強度を評価します。次の図はこのワークフローを示しています。
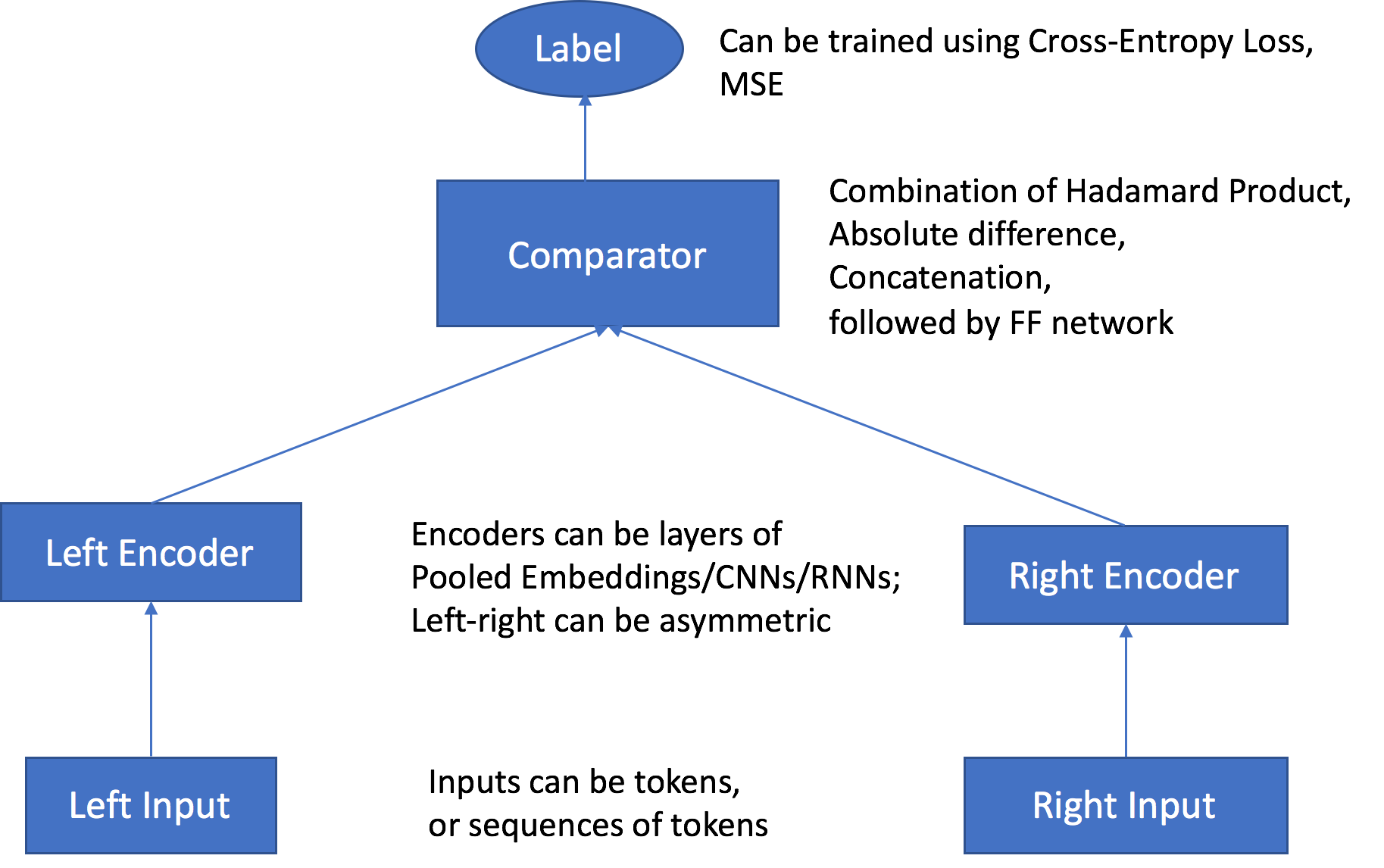
Object2Vec アルゴリズムのアーキテクチャ (データ入力からスコア)
ステップ 3: 推論を生成する
モデルがトレーニングされたら、トレーニングされたエンコーダーを使用して、入力オブジェクトの前処理を行ったり、次の 2 種類の推論を実行したりできます。
-
対応するエンコーダーを使用してシングルトン入力オブジェクトを固定長埋め込みに変換する
-
ペアになっている入力オブジェクト間の関係ラベルまたはスコアを予測する
推論サーバーは、入力データに基づいてどのタイプがリクエストされているかを自動的に判別します。埋め込みを出力として取得するには、1 つの入力のみを指定します。関係ラベルまたはスコアを予測するには、ペアに両方の入力を指定します。
