翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
SageMaker Training Compiler のトラブルシューティング
重要
Amazon Web Services (AWS) は、SageMaker Training Compiler の新しいリリースやバージョンがないことを発表しました。SageMaker Training では、既存の AWS Deep Learning Containers (DLC) を通じて SageMaker Training Compiler を引き続き使用できます。既存の DLCs は引き続きアクセス可能ですが、 AWS Deep Learning Containers Framework サポートポリシーに従って AWS、 からパッチや更新プログラムを受け取らなくなることに注意してください。
エラーが発生した場合は、次のリストを使用してトレーニングジョブのトラブルシュートを試みることができます。さらにサポートが必要な場合は、Amazon SageMaker AI AWS のサポート
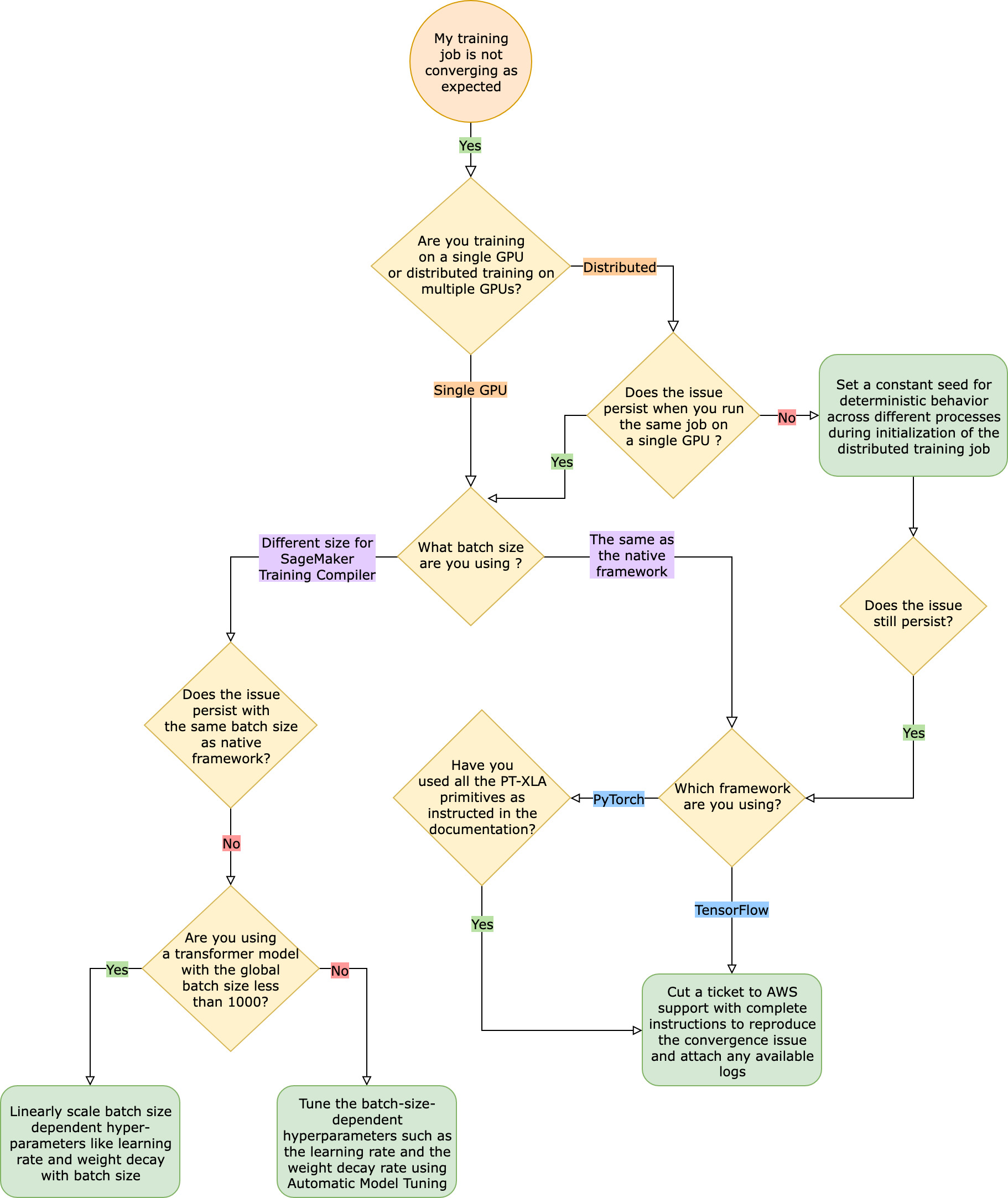
ネイティブフレームワークのトレーニングジョブと比較するとトレーニングジョブが期待どおりに収束しない
収束の問題は、「SageMaker Training Compiler がオンのときにモデルが学習しない」というものから「モデルは学習しているがネイティブフレームワークよりも遅い」というものまでさまざまです。このトラブルシューティングガイドでは、SageMaker Training Compiler を使用しない場合 (ネイティブフレームワークで) の収束は問題ないと仮定し、これをベースラインと考えます。
このような収束の問題に直面した場合、最初のステップは、問題が分散トレーニングに限定されているのか、単一 GPU トレーニングに起因するのかを特定することです。SageMaker Training Compiler による分散トレーニングは、単一 GPU トレーニングを拡張し、ステップを追加したものです。
-
複数のインスタンスまたは GPU でクラスタを設定します。
-
入力データをすべてのワーカーに分散します。
-
すべてのワーカーからのモデル更新を同期します。
したがって、単一 GPU トレーニングにおける収束の問題は、複数のワーカーによる分散トレーニングにも伝播されます。
単一 GPU トレーニングで発生する収束の問題
収束の問題が単一 GPU トレーニングに起因する場合は、ハイパーパラメータや torch_xla API の設定が不適切である可能性があります。
ハイパーパラメータのチェック
SageMaker Training Compiler でトレーニングすると、モデルのメモリフットプリントが変化します。コンパイラは再利用と再計算をインテリジェントに処理し、それに応じてメモリ消費量を増減させます。これを活用するには、トレーニングジョブを SageMaker Training Compiler に移行する際に、バッチサイズと関連するハイパーパラメータを再調整することが不可欠です。ただし、ハイパーパラメータの設定が正しくないと、トレーニング損失が振動し、結果として収束が遅くなることがよくあります。まれに、アグレッシブなハイパーパラメータの場合、モデルが学習しなくなる (トレーニング損失メトリクスが減少しない、または NaN を返さない) ことがあります。収束の問題がハイパーパラメータに起因するかどうかを特定するには、すべてのハイパーパラメータを同じに保ちながら、SageMaker Training Compiler を使用した場合と使用しない場合の 2 つのトレーニングジョブを並べてテストします。
torch_xla API が単一 GPU トレーニング用に適切に設定されているかどうかの確認
ベースラインのハイパーパラメータでも収束の問題が解決しない場合は、torch_xla API (特にモデルの更新用) が不適切に使用されていないかどうかを確認する必要があります。基本的に、torch_xla は、蓄積されたグラフを実行するように明示的に指示されるまで、命令をグラフ形式で蓄積し続けます (実行を延期)。torch_xla.core.xla_model.mark_step() 関数は蓄積されたグラフの実行を容易にします。モデルを更新するたびに、変数を印刷してログ記録する前に、この関数を使用してグラフの実行を同期する必要があります。同期ステップがないと、モデルは反復やモデル更新のたびに同期する必要のある最新の値を使用する代わりに、印刷、ログ、およびその後の前方パスの間、メモリ内の古い値を使用する可能性があります。
SageMaker Training Compiler をグラデーションスケーリング (おそらく AMP の使用による) または勾配クリッピング技術とともに使用すると、さらに複雑になる可能性があります。AMP でのグラデーション計算の適切な順序は次のとおりです。
-
スケーリングによるグラデーション計算
-
グラデーションのスケーリング解除、勾配クリッピング、そしてスケーリング
-
モデルの更新
-
mark_step()によるグラフ実行の同期
リストに記載されているオペレーションに適した API を見つけるには、「トレーニングスクリプトを SageMaker Training Compiler に移行するためのガイド」を参照してください。
自動モデルチューニングの使用の検討
SageMaker Training Compiler の使用中にバッチサイズや関連するハイパーパラメータ (学習レートなど) を再調整する際に収束の問題が発生する場合は、自動モデル調整を使用してハイパーパラメータを調整することを検討してください。「SageMaker Training Compiler によるハイパーパラメータの調整についてのサンプルノートブック
分散トレーニングで発生する収束の問題
分散トレーニングでも収束の問題が解消されない場合は、ウェイトの初期化または torch_xla API の設定が不適切である可能性があります。
ワーカー全体のウェイトの初期化の確認
複数のワーカーで分散トレーニングジョブを実行しているときに収束の問題が発生する場合、該当する場合は定数のシードを設定して、すべてのワーカーで均一な確定的動作が行われるようにします。重みの初期化など、ランダム化を伴うテクニックには注意します。シードが定数でないと、各ワーカーは異なるモデルをトレーニングすることになる可能性があります。
torch_xla API が分散トレーニング用に適切に設定されているかどうかの確認
それでも問題が解決しない場合は、分散トレーニング用の torch_xla API の不適切な使用が原因と考えられます。SageMaker Training Compiler による分散トレーニング用のクラスタを設定するために、推定器に以下を追加していることを確認します。
distribution={'torchxla': {'enabled': True}}
この場合、トレーニングスクリプト内に 1 つのワーカーにつき 1 回呼び出される関数 _mp_fn(index) を追加する必要があります。mp_fn(index) 関数がないと、モデルの更新を共有することなく、各ワーカーに個別にモデルをトレーニングさせてしまうことになります。
次に、以下の例のように、トレーニングスクリプトの SageMaker Training Compiler への移行に関するドキュメントのガイドに従って、torch_xla.distributed.parallel_loader.MpDeviceLoader を分散データサンプラーと一緒に使用していることを確認します。
torch.utils.data.distributed.DistributedSampler()
これにより、入力データがすべてのワーカーに適切に分散されます。
最後に、すべてのワーカーからのモデル更新を同期するには、torch_xla.core.xla_model._fetch_gradients を使用してすべてのワーカーから勾配を収集し、torch_xla.core.xla_model.all_reduce を使用して収集したすべての勾配を 1 つの更新にまとめます。
SageMaker Training Compiler をグラデーションスケーリング (おそらく AMP の使用による) または勾配クリッピング技術とともに使用すると、さらに複雑になる可能性があります。AMP でのグラデーション計算の適切な順序は次のとおりです。
-
スケーリングによるグラデーション計算
-
すべてのワーカー間のグラデーション同期
-
グラデーションのスケーリング解除、勾配クリッピング、そしてグラデーションスケーリング
-
モデルの更新
-
mark_step()によるグラフ実行の同期
シングル GPU トレーニングのチェックリストと比較して、このチェックリストにはすべてのワーカーを同期するための追加項目があることに注意してください。
PyTorch/XLA 構成がないためにトレーニングジョブが失敗する
トレーニングジョブが失敗して Missing XLA configuration エラーメッセージが表示される場合、使用するインスタンスごとの GPU 数の設定ミスが原因である可能性があります。
XLA では、トレーニングジョブをコンパイルするために追加の環境変数が必要です。最も一般的な欠落している環境変数は GPU_NUM_DEVICES です。コンパイラが正しく動作するためには、この環境変数をインスタンスごとの GPU の数と等しく設定する必要があります。
GPU_NUM_DEVICES 環境変数を設定するには 3 つの方法があります。
-
アプローチ 1 – SageMaker AI 推定器クラスの
environment引数を使用します。例えば、4 つの GPU を持つml.p3.8xlargeインスタンスを使用する場合は、次の操作を行います。# Using the SageMaker Python SDK's HuggingFace estimator hf_estimator=HuggingFace( ... instance_type="ml.p3.8xlarge", hyperparameters={...}, environment={ ... "GPU_NUM_DEVICES": "4" # corresponds to number of GPUs on the specified instance }, ) -
アプローチ 2 – SageMaker AI 推定器クラスの
hyperparameters引数を使用して、トレーニングスクリプトで解析します。-
GPU の数を指定するには、
hyperparameters引数にキーと値のペアを追加します。例えば、4 つの GPU を持つ
ml.p3.8xlargeインスタンスを使用する場合は、次の操作を行います。# Using the SageMaker Python SDK's HuggingFace estimator hf_estimator=HuggingFace( ... entry_point = "train.py" instance_type= "ml.p3.8xlarge", hyperparameters = { ... "n_gpus":4# corresponds to number of GPUs on specified instance } ) hf_estimator.fit() -
トレーニングスクリプトで、
n_gpusハイパーパラメータを解析し、GPU_NUM_DEVICES環境変数の入力として指定します。# train.py import os, argparse if __name__ == "__main__": parser = argparse.ArgumentParser() ... # Data, model, and output directories parser.add_argument("--output_data_dir", type=str, default=os.environ["SM_OUTPUT_DATA_DIR"]) parser.add_argument("--model_dir", type=str, default=os.environ["SM_MODEL_DIR"]) parser.add_argument("--training_dir", type=str, default=os.environ["SM_CHANNEL_TRAIN"]) parser.add_argument("--test_dir", type=str, default=os.environ["SM_CHANNEL_TEST"]) parser.add_argument("--n_gpus", type=str, default=os.environ["SM_NUM_GPUS"]) args, _ = parser.parse_known_args() os.environ["GPU_NUM_DEVICES"] = args.n_gpus
-
-
アプローチ 3 — トレーニングスクリプトに
GPU_NUM_DEVICES環境変数をハードコードします。例えば、4 つの GPU をもつインスタンスを使用する場合は、スクリプトに以下を追加します。# train.py import os os.environ["GPU_NUM_DEVICES"] =4
ヒント
使用する機械学習インスタンス上の GPU デバイスの数を調べるには、「Amazon EC2 インスタンスタイプページ」の「高速コンピューティング
SageMaker Training Compiler では合計トレーニング時間が短縮されない
SageMaker Training Compiler を使用しても合計トレーニング時間が短縮されない場合は、SageMaker Training Compiler のベストプラクティスと考慮事項 ページを参照して、トレーニング設定、入力テンソル形状のパディング戦略、ハイパーパラメータを確認することを強くお勧めします。
