翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
カスタム語彙の使用
カスタム語彙を作成したら、それを文字起こしのリクエストに含めることができます。例については、以下のセクションを参照してください。
リクエストに含めるカスタム語彙の言語は、メディアに指定した言語コードと一致する必要があります。言語が一致しない場合、カスタム語彙は文字起こしに適用されず、警告やエラーも発生しません。
バッチ文字起こしでカスタム語彙を使用する
バッチ文字起こしでカスタム語彙を使用するには、以下の例を参照してください。
-
AWS Management Console
にサインインします。 -
ナビゲーションペインで、[文字起こしジョブ] を選択後、[ジョブの作成] (右上) を選択します。これにより、「ジョブの詳細を指定」ページが開きます。
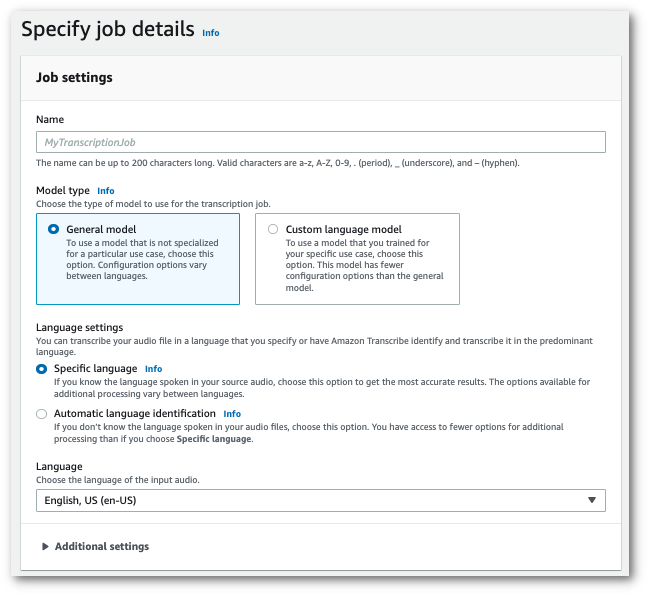
ジョブに名前を付け、入力メディアを指定します。オプションで、他のフィールドも追加し、[次へ] を選択します。
-
ジョブの設定ページの下部にあるカスタマイズパネルで、カスタム語彙をオンに切り替えます。
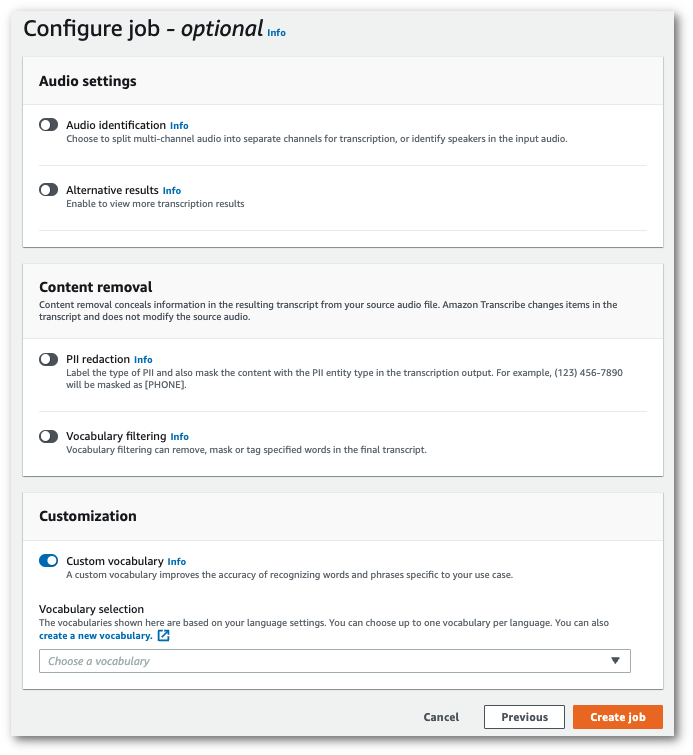
-
ドロップダウンメニューから [カスタム語彙] を選択します。
[ジョブの作成] を選択して、文字起こしジョブを実行します。
この例では、start-transcription-jobSettings パラメータ、VocabularyName サブパラメータを使用します。詳細については、StartTranscriptionJobおよびSettingsを参照してください。
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --settings VocabularyName=my-first-vocabulary
以下は、start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-vocabulary-job.json
ファイル my-first-vocabulary-job.json には、次のリクエストボディが含まれています。
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "Settings": { "VocabularyName": "my-first-vocabulary" } }
この例では AWS SDK for Python (Boto3) 、 を使用して、start_transcription_jobSettings引数を使用してカスタム語彙を含めます。詳細については、StartTranscriptionJobおよびSettingsを参照してください。
機能固有の例、シナリオ例、クロスサービス例など、 AWS SDKsSDK を使用した Amazon Transcribe のコード例 AWS SDKs「」章を参照してください。
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', Settings = { 'VocabularyName': 'my-first-vocabulary' } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
ストリーミング文字起こしでのカスタム語彙の使用
ストリーミング文字起こしでカスタム語彙を使用するには、以下の例を参照してください。
-
AWS Management Console
にサインインします。 -
ナビゲーションペインで、[リアルタイム文字起こし] を選択します。カスタマイズまでスクロールして、最小化されている場合はこのフィールドを展開します。
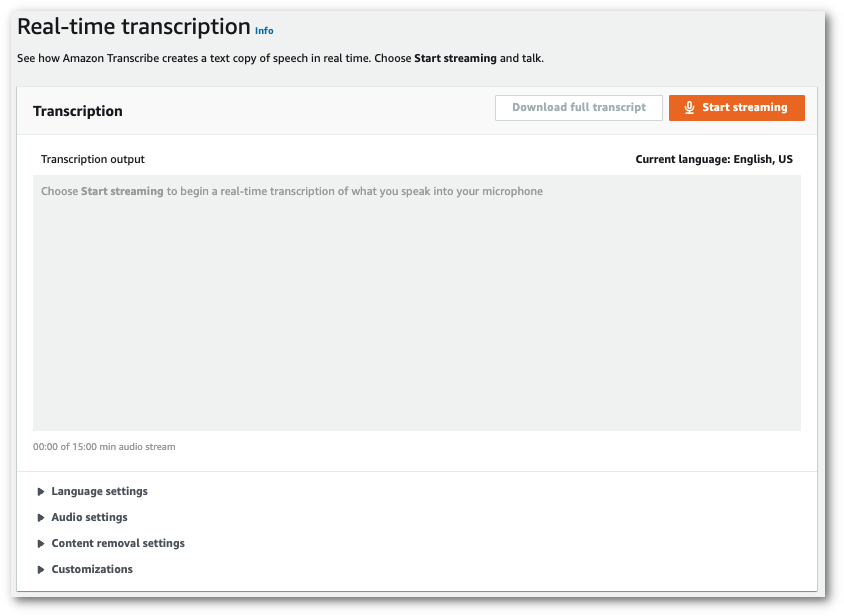
-
カスタム語彙をオンにして、ドロップダウンメニューから [カスタム語彙] を選択します。
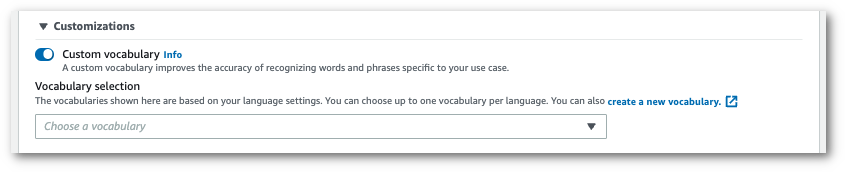
ストリームに適用するその他の設定を含めます。
-
これで、ストリームを書き起こす準備ができました。[ストリーミングを開始する] を選択し、話し始めます。ディクテーションを終了するには、[ストリーミングを停止する] を選択します。
この例では、カスタム語彙を含む HTTP/2 リクエストを作成します。での HTTP/2 ストリーミングの使用の詳細については Amazon Transcribe、「」を参照してくださいHTTP/2 ストリームの設定。 Amazon Transcribeに固有のパラメータとヘッダーの詳細については、「StartStreamTranscription」を参照してください。
POST /stream-transcription HTTP/2 host: transcribestreaming.us-west-2.amazonaws.com X-Amz-Target: com.amazonaws.transcribe.Transcribe.StartStreamTranscriptionContent-Type: application/vnd.amazon.eventstream X-Amz-Content-Sha256:stringX-Amz-Date:20220208T235959Z Authorization: AWS4-HMAC-SHA256 Credential=access-key/20220208/us-west-2/transcribe/aws4_request, SignedHeaders=content-type;host;x-amz-content-sha256;x-amz-date;x-amz-target;x-amz-security-token, Signature=stringx-amzn-transcribe-language-code:en-USx-amzn-transcribe-media-encoding:flacx-amzn-transcribe-sample-rate:16000x-amzn-transcribe-vocabulary-name:my-first-vocabularytransfer-encoding: chunked
パラメータ定義は API リファレンスにあります。すべての AWS API オペレーションに共通のパラメータは、「共通パラメータ」セクションに記載されています。
この例では、カスタム語彙を WebSocket ストリームに適用する署名付き URL を作成します。読みやすくするために、改行が追加されています。で WebSocket ストリームを使用する方法の詳細については Amazon Transcribe、「」を参照してくださいWebSocket ストリームの設定。パラメータの詳細については、「StartStreamTranscription」を参照してください。
GET wss://transcribestreaming.us-west-2.amazonaws.com:8443/stream-transcription-websocket? &X-Amz-Algorithm=AWS4-HMAC-SHA256 &X-Amz-Credential=AKIAIOSFODNN7EXAMPLE%2F20220208%2Fus-west-2%2Ftranscribe%2Faws4_request &X-Amz-Date=20220208T235959Z &X-Amz-Expires=300&X-Amz-Security-Token=security-token&X-Amz-Signature=string&X-Amz-SignedHeaders=content-type%3Bhost%3Bx-amz-date &language-code=en-US&media-encoding=flac&sample-rate=16000&vocabulary-name=my-first-vocabulary
パラメータ定義は API リファレンスにあります。すべての AWS API オペレーションに共通のパラメータは、「共通パラメータ」セクションに記載されています。
