OPS10-BP01 イベント、インシデント、問題管理のプロセスを使用する
組織には、イベント、インシデント、問題を扱うためのプロセスがあります。イベント は、ワークロードで発生しますが、必ずしも介入を必要としない出来事です。インシデント は、介入を必要とするイベントです。 問題 は、介入しなければ解決できない、繰り返し発生するイベントです。これらのイベントがビジネスに与える影響を軽減し、適切に対応できるようにするためのプロセスが必要です。
ワークロードにインシデントや問題が発生したとき、それらを処理するためのプロセスが必要です。イベントの状況を関係者にどのように伝えますか。 対応をだれが監督しますか。 イベントの緩和に使用するツールは何ですか。 これらは、確実な対応策を講じるために必要な質問の一例です。
プロセスは一元的に文書化し、ワークロードに関わる誰もが利用できるようにする必要があります。もし、一元的な Wiki や ドキュメントの保管場所がない場合は、バージョン管理リポジトリを使用することができます。プロセスの進化につれて、これらのプランを最新に保ちます。
問題は、オートメーションの候補です。これらのイベントが発生すると、イノベーションにかける時間が奪われます。問題を軽減するための繰り返し可能なプロセスから始めましょう。時間をかけて、軽減策のオートメーション化または根本的な問題の解決に注力します。そうすることで、ワークロードの改善に充てる時間を確保することができます。
期待される成果: 組織には、イベント、インシデント、問題を扱うためのプロセスがあります。これらのプロセスは文書化され、一元的に保管されます。プロセスの変化につれて更新されます。
一般的なアンチパターン:
-
インシデントが週末に発生すると、オンコールエンジニアはどうしてよいかわかりません。
-
顧客からアプリケーションがダウンしたという E メールが送られてきます。修正するためにサーバーを再起動します。これが頻繁に起きます。
-
複数のチームが解決のために個別に取り組んでいるインシデントがあります。
-
ワークロードで、記録されることなくデプロイが行われます。
このベストプラクティスを活用するメリット:
-
ワークロードのイベントの監査証跡ができます。
-
インシデントからの復旧時間が短縮されます。
-
チームメンバーは一貫した方法でインシデントと問題を解決できます。
-
インシデントを調査するときに、より総合的に取り組むことができます。
このベストプラクティスを活用しない場合のリスクレベル: 高
実装のガイダンス
このベストプラクティスを実装すると、ワークロードイベントを追跡することになります。インシデントと問題を扱うためのプロセスができます。プロセスは文書化され、共有され、頻繁に更新されます。問題が特定され、優先順位が付けられ、修正されます。
顧客の事例
AnyCompany Retail では、社内 Wiki の一部がイベント、インシデント、問題管理のためのプロセス専用になっています。 すべてのイベントは以下に送信されます : Amazon EventBridge.問題は AWS Systems Manager OpsCenter で OpsItem として特定され、優先的に修正されるため、未分化な労力を削減することができます。プロセスが変化すると、社内 Wiki で更新されます。同社では、 AWS Systems Manager Incident Manager を使用してインシデントを管理し、緩和の取り組みを調整しています。
実装手順
-
イベント
-
人間の介入を必要としない場合でも、ワークロードで発生するイベントを追跡します。
-
ワークロードの関係者と協力して、追跡すべきイベントのリストを作成します。例えば、デプロイの完了やパッチ適用の成功などです。
-
また、 Amazon EventBridge または Amazon Simple Notification Service などのサービスを使用して、追跡するカスタムイベントを生成することができます。
-
-
インシデント
-
インシデント発生時の情報伝達プランを明確にすることから始めましょう。どのような関係者に通知する必要がありますか。 どのようにして情報を共有しますか。 誰が調整作業を監督しますか。 コミュニケーションと調整のために、社内チャットチャネルを立ち上げることをお勧めします。
-
特にオンコールのローテーションがないチームの場合は、ワークロードをサポートするチームのエスカレーションパスを定義しておきましょう。サポートレベルに基づいて、サポート に申請を行うことも可能です。
-
インシデントを調査するためのプレイブックを作成します。これには、情報伝達プランや詳細な調査手順が含まれている必要があります。調査には、 AWS Health Dashboard の確認を含めます。
-
インシデント対応計画を文書化します。インシデント管理計画を伝達し、社内外の顧客がエンゲージメントのルールと何を期待されているのかを理解できるようにします。使用方法について、チームメンバーをトレーニングします。
-
顧客は Incident Manager を使用してインシデント対応プランを設定し、管理できます。
-
エンタープライズサポートのお客様は インシデント管理ワークショップ
をテクニカルアカウントマネージャーからリクエストできます。このガイド付きワークショップでは、既存のインシデント対応計画をテストし、改善すべき点を明らかにすることができます。
-
-
問題
-
ITSM システムで問題を特定して、追跡する必要があります。
-
既知の問題をすべて特定し、修正作業とワークロードへの影響から優先順位を付けます。
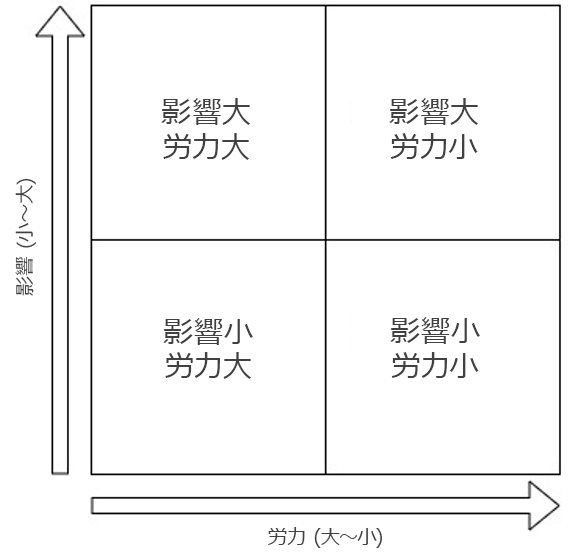
-
影響が大きく、労力が少なくて済む問題から解決します。そのような問題が解決したら、影響が少なく、労力が少なくて済む象限の問題に移ります。
-
専用のインフラストラクチャで Systems Manager OpsCenter を使用して、これらの問題を特定し、ランブックをアタッチして、追跡します。
-
実装計画に必要な工数レベル: 中程度。このベストプラクティスを実装するには、プロセスとツールの両方が必要です。プロセスを文書化し、ワークロードに関わる誰もが使用できるようにします。頻繁に更新します。問題を管理し、問題を緩和または修正するためのプロセスがあります。
リソース
関連するベストプラクティス:
-
OPS07-BP03 ランブックを使用して手順を実行する: 既知の問題には、緩和作業に一貫性を持たせるために、関連するランブックが必要です。
-
OPS07-BP04 プレイブックを使用して問題を調査する: インシデントはプレイブックを使用して調査する必要があります。
-
OPS11-BP02 インシデント後の分析を実行する: インシデントからの復旧後は、必ず事後分析を実施します。
関連するドキュメント:
関連動画:
関連する例:
関連サービス:
