REL12-BP04 カオスエンジニアリングを使用して回復力をテストする
悪条件下でシステムがどのように反応するかを理解するために、本番環境またはできるだけそれに近い環境で定期的にカオス実験を行います。
期待される成果:
イベント発生時のワークロードの既知の期待動作を検証する回復力テストに加えて、フォールトインジェクション実験や想定外の負荷の注入という形でカオスエンジニアリングを適用し、ワークロードの回復力を定期的に検証します。カオスエンジニアリングと回復力テストの両方を組み合わせることで、ワークロードがコンポーネントの障害に耐え、想定外の中断から影響を最小限に抑えて回復できることを確信できます。
一般的なアンチパターン:
-
回復力を考慮した設計でありながら、障害発生時にワークロードが全体としてどのように機能するかを検証していない。
-
実際の条件および予期される負荷による実験を一切行わない。
-
実験をコードとして処理しないか、開発サイクルを通して維持しない。
-
CI/CD パイプラインの一部、またはデプロイの外部のどちらとしても、カオス実験を実行しない。
-
どの障害で実験するかを考慮する際に、過去のインシデント後の分析を無視する。
このベストプラクティスを活用するメリット: ワークロードの回復力を検証するために障害を発生させることで、回復力設計の復旧手順が実際の障害発生時にも機能するという確信を得られます。
このベストプラクティスを活用しない場合のリスクレベル: 中
実装のガイダンス
カオスエンジニアリングは、サービスプロバイダー、インフラストラクチャ、ワークロード、コンポーネントレベルにおいて、現実世界の障害 (シミュレーション) を継続的に発生させる機能を提供し、顧客には最小限の影響しか与えません。これにより、チームは障害から学び、ワークロードの回復力を観察、測定、改善することができます。また、イベント発生時にアラートが発せられ、チームに通知されることを確認することもできます。
カオスエンジニアリングを継続的に実施することで、放置しておくと可用性やオペレーションに悪影響を及ぼす可能性がある、ワークロードの欠陥が浮き彫りになります。
注記
カオスエンジニアリングとは、あるシステムで実験を行い、本稼働時の混乱状態に耐えることができるかどうかの確信を得るための手法です。– カオスエンジニアリングの原則
システムがこれらの混乱に耐えられる場合は、カオス実験を自動化されたリグレッションテストとして維持する必要があります。このように、カオス実験はシステム開発ライフサイクル (SDLC) の一部および CI/CD パイプラインの一部として実行される必要があります。
ワークロードがコンポーネントの障害に耐えられることを確認するために、実際のイベントを実験の一部として挿入します。例えば、Amazon EC2 インスタンスの喪失やプライマリ Amazon RDS データベースインスタンスのフェイルオーバーを実験し、ワークロードに影響がないこと (または最小限の影響にとどまること) を確認します。コンポーネントの障害の組み合わせを使用して、アベイラビリティーゾーンでの中断によって発生する可能性のあるイベントをシミュレートします。
アプリケーションレベルの障害 (クラッシュなど) では、メモリや CPU の枯渇などのストレス要因から始めます。
断続的なネットワーク中断による外部依存関係のフォールバックまたはフェイルオーバーメカニズム
その他の劣化状態では、機能の低下や応答の遅れが発生し、サービスの中断につながることがよくあります。このパフォーマンス低下の一般的な原因は、主要サービスのレイテンシー増加と、信頼性の低いネットワーク通信 (パケットのドロップ) です。レイテンシー、メッセージのドロップ、DNS 障害などのネットワークへの影響を含むこれらの障害実験には、名前の解決、DNS サービスへの到達、依存サービスへの接続ができないことなどが含まれる可能性があります。
カオスエンジニアリングのツール:
AWS Fault Injection Service (AWS FIS) は、フォールトインジェクション実験を実行するフルマネージドサービスであり、CD パイプラインの一部として、またはパイプラインの外で使用することができます。AWS FIS は、カオスエンジニアリングのゲームデー中に使用するのに適しています。Amazon EC2、Amazon Elastic Container Service (Amazon ECS)、Amazon Elastic Kubernetes Service (Amazon EKS)、Amazon RDS など、さまざまな種類のリソースに障害を同時発生させるのに役立ちます。これらの障害には、リソースの終了、強制フェイルオーバー、CPU またはメモリへのストレス、スロットリング、レイテンシー、パケット損失などが含まれます。Amazon CloudWatch アラームと連携しているため、ガードレールとして停止条件を設定し、想定外の影響を与えた場合に実験をロールバックすることができます。
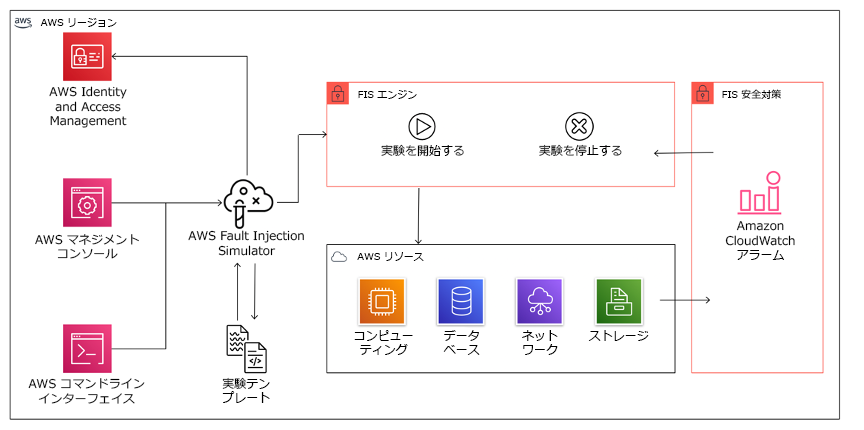
AWS Fault Injection Service を AWS リソースと統合することで、ワークロードのフォールトインジェクション実験を実行できるようになります。
フォールトインジェクション実験を実行するための、いくつかのサードパーティーオプションがあります。これには、Chaos Toolkit
実装手順
-
どの障害を実験に使用するかを決定します。
回復力に対するワークロードの設計を評価します。Well-Architected Framework のベストプラクティスを使用して作成するこのような設計では、重要な依存関係、過去のイベント、既知の問題、コンプライアンス要件に基づくリスクを考慮します。回復力を維持するために想定した設計の各要素と、それを低減するために設計する障害をリストアップします。このようなリストの作成の詳細については、「Operational Readiness Review」ホワイトペーパーを参照してください。このホワイトペーパーでは、過去のインシデントの再発を防ぐためのプロセスを作成する方法について説明します。障害モードと影響の分析 (FMEA) プロセスにより、障害とそれがワークロードに与える影響をコンポーネントレベルで分析するためのフレームワークが提供されます。FMEA については、Adrian Cockcroft の「障害モードと継続的回復力
」で詳しく説明しています。 -
各障害に優先度を割り当てます。
「高」「中」「低」などの大まかな分類から始めます。優先度を評価するには、障害の発生頻度と障害によるワークロード全体への影響を考慮します。
ある障害の発生頻度を考慮する場合、利用可能であれば、そのワークロードの過去のデータを分析します。利用できない場合は、類似の環境で実行されている他のワークロードのデータを使用します。
ある障害の影響を考慮する場合、一般的に、障害の範囲が大きければ大きいほど、影響も大きくなります。ワークロードの設計と目的も考慮します。例えば、ソースデータストアにアクセスする機能は、データ変換や分析を行うワークロードにとって重要です。この場合、アクセス障害、スロットルアクセス、レイテンシー挿入の実験を優先させることになります。
障害発生後の分析は、障害モードの頻度と影響の両方を理解するための良いデータソースとなります。
割り当てた優先度を使用して、どの障害を最初に実験するか、および新しいフォールトインジェクション実験を開発する順序を決定します。
-
実施するそれぞれの実験に関して、次の図のカオスエンジニアリングと継続的な回復力のフライホイールに従います。
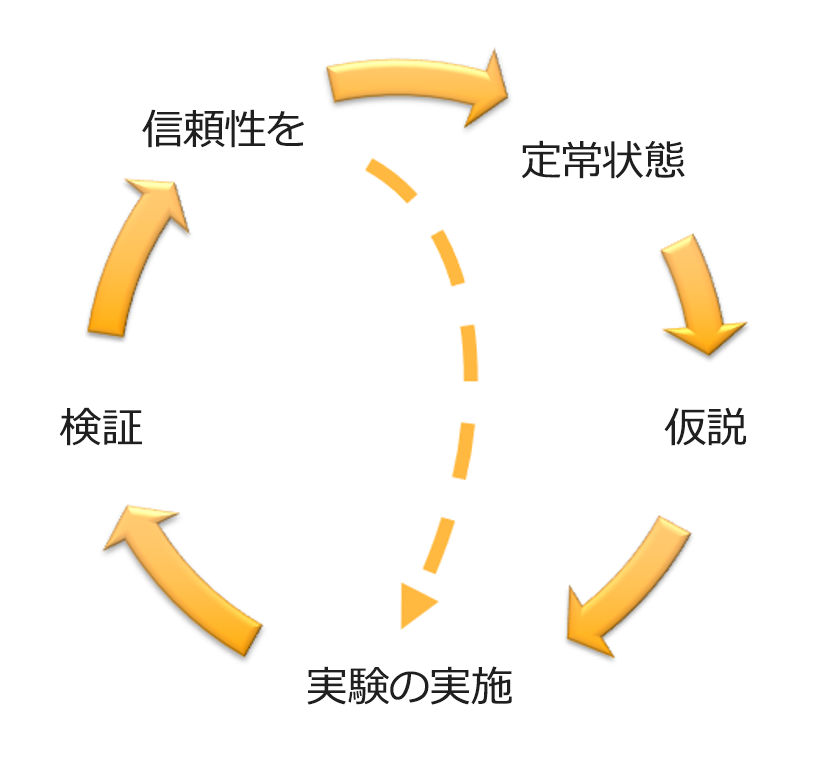
Adrian Hornsby による、科学的手法を用いたカオスエンジニアリングと継続的な回復力のフライホイール。
-
定常状態とは、正常な動作を示すワークロードの測定可能な出力であると定義します。
ワークロードは、信頼性が高く、期待どおりに動作していれば、定常状態を示します。したがって、定常状態を定義する前に、ワークロードが正常であることを検証します。一定の割合の障害は許容範囲内である可能性があるため、定常状態は、必ずしも障害発生時にワークロードに影響が及ばないことを意味するものではありません。定常状態は実験中に観察される基準値であり、定義した仮説が次のステップで想定どおりにならない場合に、異常を強調します。
例えば、決済システムの定常状態は、成功率 99%、往復時間 500ms で 300TPS を処理することと定義できます。
-
ワークロードがどのように障害に対応するかについての仮説を立てます。
良い仮説は、定常状態を維持するために、ワークロードがどのように障害を軽減すると予想されるかに基づいています。仮説は、特定の種類の障害が発生した場合、システムまたはワークロードが定常状態を維持することを示します。なぜならば、ワークロードは特定の緩和策を講じて設計されているからです。特定の種類の障害および緩和策は、仮説の中で特定する必要があります。
次のテンプレートを仮説に使用できます (ただし、他の表現も許容されます)。
注記
特定の障害が発生した場合、ワークロード名のワークロードには、ビジネスまたは技術メトリクスの影響を維持するための緩和コントロールが記述されます。例:
-
Amazon EKS ノードグループの 20% のノードが停止しても、[Transaction Create API] は 100 ミリ秒未満で 99% のリクエストに対応し続けます (定常状態)。Amazon EKS ノードは 5 分以内に回復し、ポッドはスケジューリングされて、実験開始後 8 分以内にトラフィックを処理するようになります。3 分以内にアラートが発せられます。
-
Amazon EC2 インスタンスの単一障害が発生した場合、注文システムの Elastic Load Balancing ヘルスチェックにより、Amazon EC2 Auto Scaling が障害インスタンスを置き換える間、Elastic Load Balancing は残りの健全なインスタンスにのみリクエストを送信し、サーバーサイド (5xx) エラーの増加を 0.01% 未満に維持します (定常状態)。
-
プライマリ Amazon RDS データベースインスタンスに障害が発生した場合、サプライチェーンデータ収集ワークロードはフェイルオーバーし、スタンバイ Amazon RDS データベースインスタンスに接続して、データベースの読み取りまたは書き込みエラーを 1 分未満に維持します (定常状態)。
-
-
障害を挿入して実験を実行する。
実験はデフォルトでフェイルセーフであり、ワークロードが耐えることができる必要があります。ワークロードが失敗することがわかっている場合は、実験を実行しないでください。カオスエンジニアリングは、既知の未知、または未知なる未知を見つけるために使用される必要があります。既知の未知は、認識しているが完全には理解していないモノであり、未知なる未知は、認識も完全に理解もしていないモノです。壊れているとわかっているワークロードに対して実験を行っても、新しいインサイトを得ることはできません。実験は慎重に計画し、影響の範囲を明確にし、予期せぬ乱れが発生した場合に適用できるロールバックメカニズムを用意する必要があります。デューディリジェンスによりワークロードが実験に耐えられることがわかったら、実験を進めてください。障害を挿入するには、いくつかの方法があります。AWS のワークロードの場合、AWS FIS はアクションと呼ばれる多くの事前定義された障害シミュレーションを提供します。AWS Systems Manager ドキュメントを使用して、AWS FIS で実行するカスタムアクションを定義することもできます。
カオス実験にカスタムスクリプトを使用することは、スクリプトがワークロードの現在の状態を理解する機能を持ち、ログを出力でき、可能であればロールバックと停止条件のメカニズムを提供しない限り、お勧めできません。
カオスエンジニアリングをサポートする効果的なフレームワークやツールセットは、実験の現在の状態を追跡し、ログを出力し、実験の制御された実行をサポートするためのロールバックメカニズムを提供します。AWS FIS のように、実験範囲を明確に定義し、実験によって予期せぬ乱れが生じた場合に実験をロールバックする安全なメカニズムを備えた実験を行うことができる、確立されたサービスから始めてみてください。AWS FIS を使用したさまざまな実験については、「Resilient and Well-Architected Apps with Chaos Engineering lab
」も参照してください。AWS Resilience Hub はワークロードを分析し、AWS FIS で実装および実行することを選択できる実験を作成します。 注記
すべての実験について、その範囲と影響を明確に理解します。本番環境で実行する前に、まず非本番環境で障害をシミュレートすることをお勧めします。
可能であれば、実験はコントロールと実験的なシステムデプロイの両方をスピンアップするカナリアデプロイ
を使用して、実際の負荷下の本番環境で実行する必要があります。オフピークの時間帯に実験を行うことは、本番で初めて実験を行う際に潜在的な影響を軽減するための良い方法です。また、実際の顧客トラフィックを使用するとリスクが高すぎる場合は、本稼働インフラストラクチャの制御環境と実験環境に対して合成トラフィックを使用し、実験を実行することができます。本番環境での実験が不可能な場合は、できるだけ本番環境に近い本番稼働前の環境で実験を行ってください。 実験が本稼働トラフィックや他のシステムに許容範囲を超えて影響を与えないように、ガードレールを確立してモニタリングする必要があります。停止条件を設定し、定義したガードレールのメトリクスでしきい値に達した場合は実験を停止するようにします。これには、ワークロードの定常状態のメトリクスと、障害を挿入するコンポーネントに対するメトリクスを含める必要があります。合成モニタ (ユーザー canary とも呼ばれます) は、通常、ユーザープロキシとして含める必要があるメトリクスの 1 つです。AWS FIS の停止条件は実験テンプレートの一部としてサポートされており、テンプレートごとに最大 5 つの停止条件を許可します。
カオスの原則の 1 つは、実験の範囲とその影響を最小化することです。
短期的な悪影響は許容する必要がありますが、実験の影響を最小化し、抑制することは、カオスエンジニアの責任であり義務です。
範囲や潜在的な影響を検証する方法として、本番環境で直接実験を行うのではなく、まず非本番環境で実験を行い、実験中に停止条件のしきい値が想定どおりに作動するか、例外をキャッチするためのオブザーバビリティがあるかどうかを確認することが挙げられます。
フォールトインジェクション実験を実行する場合は、すべての責任者に情報が十分に伝達されるようにします。オペレーションチーム、サービス信頼性チーム、カスタマーサポートなどの適切なチームとコミュニケーションをとり、実験がいつ実行され、何が期待されるかを伝えます。これらのチームには、何か悪影響が見られた場合に実験を行っているチームに知らせるための、コミュニケーションツールを提供します。
ワークロードとその基盤となるシステムを、元の既知の良好な状態に復元する必要があります。多くの場合、ワークロードの回復力のある設計が自己回復を行います。しかし、一部の障害設計や実験の失敗により、ワークロードが予期せぬ障害状態に陥ることがあります。実験が終了するまでにこのことを認識し、ワークロードとシステムを復旧させる必要があります。AWS FIS では、アクションのパラメータ内にロールバック設定 (ポストアクションとも呼ばれます) を設定することができます。ポストアクションは、ターゲットをアクションが実行される前の状態に戻します。自動化 (AWS FIS の使用など) であれ手動であれ、これらのポストアクションは、障害を検出して処理する方法を説明するプレイブックの一部である必要があります。
-
仮説を検証する。
カオスエンジニアリングの原則
は、ワークロードの定常状態を検証する方法について、以下のようなガイダンスを示しています。 システムの内部属性ではなく、測定可能な出力に焦点を当てます。その出力を短期間測定することによって、システムの定常状態のプロキシが構成されます。システム全体のスループット、エラーレート、レイテンシーのパーセンタイルはすべて、定常状態の動作を表す重要なメトリクスになり得ます。カオスエンジニアリングでは、実験中のシステムの動作パターンに焦点を当て、システムがどのように動作するかを検証するのではなく、システムが実際に動作することを検証します。
先の 2 つの例では、サーバーサイド (5xx) エラーの増加率が 0.01% 未満、データベースの読み取りと書き込みのエラーが 1 分未満という、定常状態のメトリクスが含まれています。
5xx エラーは、ワークロードのクライアントが直接経験する障害モードの結果であるため、良いメトリクスです。データベースエラーの測定は、障害の直接的な結果として適切ですが、顧客からのリクエストの失敗や、顧客に表面化したエラーなど、顧客への影響も測定して補足する必要があります。さらに、ワークロードのクライアントが直接アクセスする API や URI に、合成モニタリング (ユーザー canary とも呼ばれます) を含める必要があります。
-
回復力を高めるためのワークロード設計を改善する。
定常状態が維持されなかった場合は、AWS Well-Architected の信頼性の柱のベスト プラクティスを適用して、障害を軽減するためにワークロードの設計をどのように改善できるかを調査します。その他のガイダンスとリソースは、「AWS ビルダーライブラリ
」にあります。このライブラリには、ヘルスチェックの改善 方法や、アプリケーションコードでのバックオフによる再試行方法 などに関する記事がホストされています。 これらの変更を実施した後、再度実験を行い (カオスエンジニアリングフライホイールの点線で表示)、その効果を判断します。検証の結果、仮説が正しいことがわかれば、ワークロードは定常状態になり、このサイクルが続きます。
-
-
実験を定期的に実施する。
カオス実験はサイクルであり、実験はカオスエンジニアリングの一環として定期的に実施する必要があります。ワークロードが実験の仮説を満たしたら、CI/CD パイプラインのリグレッション部分として継続的に実行されるように、実験を自動化する必要があります。これを行う方法については、AWS CodePipeline を使用して AWS FIS 実験を実行する方法
に関するブログを参照してください。CI/CD パイプラインでの AWS FIS 反復実験 に関するこのラボでは、実践的に作業できます。 フォールトインジェクション実験は、ゲームデーの一部でもあります (REL12-BP05 定期的にゲームデーを実施する を参照)。ゲームデーでは、障害やイベントをシミュレートし、システム、プロセス、チームの対応を検証します。その目的は、例外的なイベントの発生時にチームが実行することになっているアクションを実際に実行することです。
-
実験結果をキャプチャし、保存する。
フォールトインジェクション実験の結果は、キャプチャおよび保持される必要があります。実験結果や傾向を後で分析できるように、必要なデータ (時間、ワークロード、条件など) をすべて含めておきましょう。結果の例として、ダッシュボードのスクリーンショット、メトリクスのデータベースからの CSV ダンプ、実験中のイベントや観察結果を手書きで記録したものなどがあります。AWS FIS を使用した実験ログ記録も、このデータキャプチャの一部です。
リソース
関連するベストプラクティス:
関連ドキュメント:
関連動画:
関連ツール:
