シナリオ 5: Apache Kafka を使用したリアルタイムのテレメトリデータのモニタリング
ABC1Cabs はオンラインタクシー予約サービス会社です。すべてのタクシーには、車両からテレメトリデータを収集する IoT デバイスがあります。現在、ABC1Cabs は、リアルタイムのイベント消費、システムヘルスメトリクスの収集、アクティビティの追跡、オンプレミスの Hadoop クラスター上に構築された Apache Spark ストリーミングプラットフォームへのデータのフィードを目的として設計された Apache Kafka クラスターを実行しています。
ABC1Cabs は、ビジネスメトリクス、デバッグ、アラート、その他のダッシュボードの作成に OpenSearch Dashboards を使用しています。同社は、Amazon MSK、Spark ストリーミングを使用した Amazon EMR、および OpenSearch Dashboards を備えた OpenSearch Service に関心を持っています。Apache Kafka および Hadoop クラスターを維持するための管理オーバーヘッドを削減すると同時に、使い慣れたオープンソースソフトウェアと API を使用してデータパイプラインをオーケストレートすることが要件です。次のアーキテクチャ図表は、同社の AWS でのソリューションを示しています。
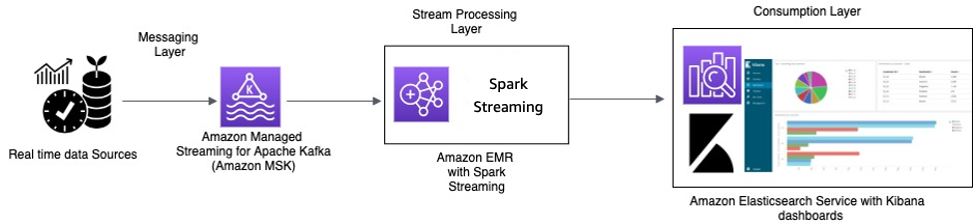
Amazon MSK によるリアルタイム処理、および Amazon EMR での Apache Spark ストリーミングおよび OpenSearch Dashboards を備えた Amazon OpenSearch Service を使用したストリーム処理
タクシーの IoT デバイスはテレメトリデータを収集し、ソースハブに送信します。ソースハブは Amazon MSK にリアルタイムでデータを送信するように設定されています。Amazon MSK は Apache Kafka プロデューサーライブラリ API を使用して、データを Amazon EMR クラスターにストリーミングするように設定されます。Amazon EMR クラスターには Kafka クライアントと Spark ストリーミングがインストールされており、データストリームを消費して処理できます。
Spark ストリーミングには、Elasticsearch の定義済みインデックスにデータを直接書き込むことができるシンクコネクタがあります。OpenSearch Dashboards を備えた Elasticsearch クラスターは、メトリクスとダッシュボードに使用できます。Amazon MSK、Spark ストリーミングを使用した Amazon EMR、OpenSearch Dashboards を備えた OpenSearch Service はすべてマネージドサービスであり、AWS がさまざまなクラスターのインフラストラクチャ管理という差別化されていない重労働を管理します。これにより、使い慣れたオープンソースソフトウェアを使用して、数回のクリックでアプリケーションを構築できます。次のセクションでは、これらのサービスについて詳しく説明します。
Amazon Managed Streaming for Apache Kafka (Amazon MSK)
Apache Kafka は、お客様がクリックストリームイベント、トランザクション、IoT イベント、アプリケーションログ、マシンログなどのストリーミングデータをキャプチャできるオープンソースプラットフォームです。この情報を使用して、リアルタイム分析を実行し、継続的な変換を実行し、このデータをデータレイクやデータベースにリアルタイムで配信するアプリケーションを開発できます。
Kafka をストリーミングデータストアとして使用して、アプリケーションをプロデューサーとコンシューマーから切り離し、2 つのコンポーネント間で信頼性の高いデータ転送を実現できます。Kafka は一般的なエンタープライズデータストリーミングおよびメッセージングプラットフォームですが、本番環境ではセットアップ、スケーリング、管理が難しい場合があります。
Amazon MSK はこれらの管理タスクを処理し、高可用性とセキュリティのためのベストプラクティスに従った環境で、Apache Zookeeper とともに Kafka を簡単にセットアップ、設定、実行します。お客様は引き続き Kafka のコントロールプレーンオペレーションとデータプレーンオペレーションを使用して、データの生成と消費を管理できます。
Amazon MSK はオープンソースの Apache Kafka を実行および管理しているため、お客様はアプリケーションコードを変更することなく、既存の Apache Kafka アプリケーションを AWS 上で簡単に移行して実行できます。
スケーリング
Amazon MSK では、ユーザーがクラスターの実行中にアクティブにスケールできるように、スケーリングオペレーションを提供しています。Amazon MSK クラスターを作成する際に、クラスターの起動時のブローカーのインスタンスタイプを指定できます。Amazon MSK クラスター内で少ないブローカーから始めて、その後、AWS Management Console または AWS CLI を使用して、クラスターあたり数百のブローカーまでスケールアップできます。
または、Apache Kafka ブローカーのサイズまたはファミリーを変更して、クラスターをスケールすることもできます。ブローカーのサイズまたはファミリーを変更すると、ワークロードの変化に伴って Amazon MSK クラスターのコンピューティング性能を柔軟に調整できます。Amazon MSK クラスターに適したブローカー数を決定するには、Amazon MSK Sizing and Pricing spreadsheet
Amazon MSK クラスターを作成したら、ブローカーごとの EBS ストレージ容量を増やすことができます。ただし、ストレージを減らすことはできません。ストレージボリュームは、このスケールアップオペレーション中も引き続き使用できます。オートスケーリングと手動スケーリングの 2 種類のスケーリングオペレーションが用意されています。
Amazon MSK では、アプリケーションのオートスケーリングポリシーを使用して、使用量の増加に応じてクラスターのストレージを自動的に拡張できます。オートスケーリングポリシーにより、ターゲットディスク使用率と最大スケーリング容量が設定されます。
ストレージ使用率のしきい値は、Amazon MSK がオートスケーリングオペレーションをトリガーするのに役立ちます。手動スケーリングを使用してストレージを増やすには、クラスターが ACTIVE 状態になるまで待ちます。ストレージのスケーリングでは、イベント間のクールダウン期間が最低 6 時間となります。このオペレーションによって追加のストレージがすぐに使用可能になりますが、クラスターを最適化するために最大 24 時間以上かかる場合があります。
最適化の所要時間は、ストレージサイズに比例します。さらに、AWS リージョン内でマルチアベイラビリティーゾーンのレプリケーションも提供され、高可用性を提供します。
設定
Amazon MSK は、ブローカー、トピック、および Apache Zookeeper ノードのデフォルト設定を提供します。また、カスタム設定を作成し、それらを使用して新しい Amazon MSK クラスターを作成したり、既存のクラスターを更新することもできます。カスタム Amazon MSK 設定を指定せずに MSK クラスターを作成すると、Amazon MSK はデフォルト設定を作成して使用します。これらのデフォルト値のリストについては、「Apache Kafka の設定」を参照してください。
Amazon MSK は、モニタリング目的で Apache Kafka メトリクスを収集し、Amazon CloudWatch に送信します。このメトリクスは Amazon CloudWatch で確認できます。MSK クラスター用に設定するメトリクスは、自動的に収集され、CloudWatch にプッシュされます。コンシューマーラグをモニタリングすると、トピックで利用可能な最新データに追いついていない、遅いコンシューマーやスタックしたコンシューマーを特定できます。必要に応じて、それらのコンシューマーのスケーリングや再起動などの是正措置を講じることができます。
Amazon MSK への移行
オンプレミスから Amazon MSK への移行は、次のいずれかの方法で実現できます。
-
MirrorMaker2.0 - MirrorMaker2.0 (MM2) MM2 は、Apache Kafka Connect フレームワークをベースにしたマルチクラスターのデータレプリケーションエンジンです。MM2 は Apache Kafka ソースコネクタとシンクコネクタの組み合わせです。1 つの MM2 クラスターを使用して、複数のクラスター間でデータを移行できます。MM2 は、新しいトピックとパーティションを自動的に検出すると同時に、トピックの設定がクラスター間で同期されるようにします。MM2 では、移行 ACL、トピック設定、オフセット変換がサポートされています。移行に関する詳細については、「Apache Kafka の MirrorMaker を使用したクラスターの移行」を参照してください。MM2 は、トピックの構成とオフセット変換の自動レプリケーションに関連するユースケースに使用されます。
-
Apache Flink - MM2 は少なくとも 1 回のセマンティクスをサポートしています。レコードは送信先に複製することができ、コンシューマーは重複レコードを処理するためにべき等であるべきです。exactly-once シナリオでは、コンシューマーが Apache Flink を使用できるセマンティクスが必要です。これは、厳密に 1 回のセマンティクスを実現するための代替手段を提供します。
Apache Flink は、データが送信先クラスターに送信される前にマッピングまたは変換アクションを必要とするシナリオにも使用できます。Apache Flink は、ある Apache Kafka クラスターからデータを読み取り、別の Apache Kafka クラスターに書き込むことができるソースとシンクを備えた Apache Kafka 用のコネクターを提供します。Amazon EMR クラスターを起動するか、Amazon Kinesis Data Analytics を使用してアプリケーションとして Apache Flink を実行することにより、Apache Flink を AWS 上で実行できます。
-
AWS Lambda - AWS Lambda
のイベントソースとして Apache Kafka がサポートされ、お客様は Lambda 関数を介してトピックからのメッセージを使用できるようになりました。AWS Lambda サービスは、イベントソースからの新しいレコードまたはメッセージを内部でポーリングし、ターゲット Lambda 関数を同期的に呼び出してこれらのメッセージを消費します。Lambda はメッセージをバッチで読み取り、処理のためにイベントペイロード内の関数にメッセージバッチを提供します。消費されたメッセージは、変換または送信先の Amazon MSK クラスターに直接書き込みできます。
Spark ストリーミングを使用した Amazon EMR
Amazon EMR
Amazon EMR は Spark の機能を提供し、Spark ストリーミングを開始して Kafka からデータを消費するために使用できます。Spark ストリーミングは、スケーラブルで高スループット、耐障害性を備えたライブデータストリームのストリーミング処理を可能にするコア Spark API の拡張機能です。
Amazon EMR クラスターは、AWS Command Line Interface
処理されたデータは、ファイルシステム、データベース、ライブダッシュボードにプッシュできます。
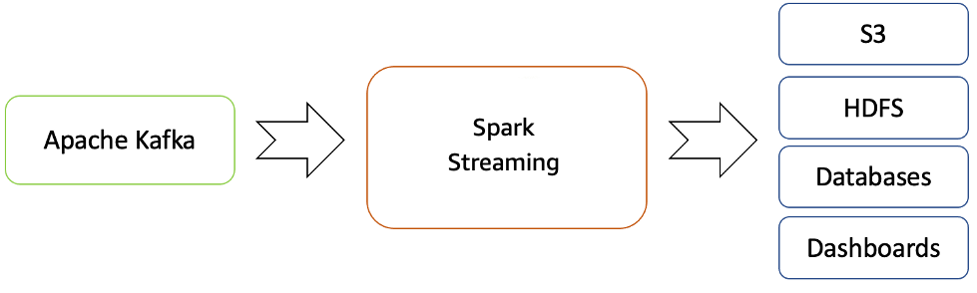
Apache Kafka から Hadoop エコシステムへのリアルタイムストリーミングフロー
デフォルトでは、Apache Spark ストリーミングにはマイクロバッチ実行モデルがあります。しかし、Spark 2.3 のリリースから、Apache は Continuous Processing と呼ばれる新しい低レイテンシー処理モードを導入しました。このモードでは、at-least-once 保証で 1 ミリ秒という低いエンドツーエンドのレイテンシーを実現できます。
クエリの Dataset/DataFrames オペレーションを変更しなくても、アプリケーションの要件に基づいてモードを選択できます。Spark ストリーミングの利点には、次のようなものがあります。
-
Apache Spark の言語統合 API
がストリーミング処理に導入され、バッチジョブを記述するのと同じ方法でストリーミングジョブを記述できます。 -
Java、Scala、Python をサポートしています。
-
余分なコードなしで、失われた作業とオペレーターの状態 (スライディングウィンドウなど) の両方を、すぐに回復できます。
-
Spark ストリーミングは、Spark 上で実行することで、バッチ処理に同じコードを再利用したり、履歴データに対してストリーミングを結合したり、ストリーミングの状態に対してアドホッククエリを実行したりして、分析だけでなく強力な対話型アプリケーションを構築できます。
-
Spark ストリーミングでデータストリームが処理された後、OpenSearch Sink Connector を使用して OpenSearch Service クラスターにデータを書き込むことができます。一方、OpenSearch Dashboards を使用する OpenSearch Service は、消費レイヤーとして使用できます。
OpenSearch Dashboards を備えた Amazon OpenSearch Service
OpenSearch Service は、AWS クラウドで OpenSearch クラスターを簡単にデプロイ、運用、スケールするマネージドサービスです。OpenSearch はログ分析、リアルタイムのアプリケーションモニタリング、クリックストリーム分析などのユースケース向けの、人気の高いオープンソースの検索および分析エンジンです。
OpenSearch Dashboards
OpenSearch Dashboards は、人気のある分析および検索エンジンである OpenSearch
概要
Apache Kafka は AWS でマネージドサービスとして提供されているため、通常は Apache Kafka を詳細に理解する必要があるブローカー間の調整の管理ではなく、消費に集中できます。高可用性、ブローカーのスケーラビリティ、きめ細かいアクセスコントロールなどの機能は Amazon MSK プラットフォームによって管理されます。
ABC1Cabs はこれらのサービスを利用して、インフラストラクチャ管理の専門知識を必要とせずに本番アプリケーションを構築しました。Amazon MSK からデータを消費し、さらに可視化レイヤーに伝播する、処理レイヤーに集中できます。
Amazon EMR の Spark ストリーミングは、ストリーミングデータのリアルタイム分析や、可視化レイヤーでの Amazon OpenSearch Service の OpenSearch Dashboards
