ステップ 1: データを収集して集計する
次の図は、予測の問題に関するメンタルモデルを説明しています。可能な限り予測の精度を向上するために、できるだけ多くの関連情報を使用して、時系列 z_t を将来にわたり予測することが目標です。そのため、最初の最も重要なステップは、できるだけ多くの正確なデータを収集することです。
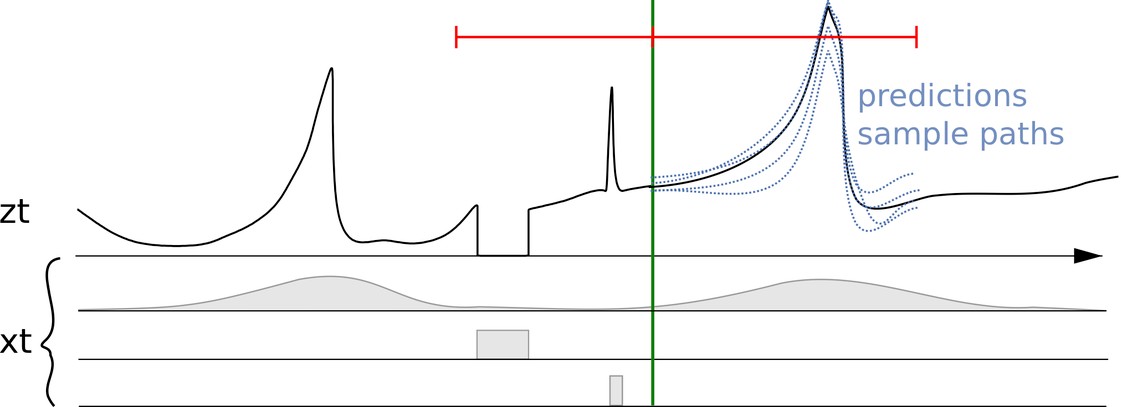
時系列 z_t と関連する特徴または共変量 (x_t)、および複数の予測
上の図では、縦線の右側に複数の予測が表示されています。これらの予測は、確率的予測分布の例です (逆の言い方をすれば、確率的予測を示すために使用できます)。
小売業が記録すべき重要な情報は次のとおりです。
-
取引売上データ — SKU (Stock Keeping Unit)、場所、タイムスタンプ、販売数など。
-
SKU 商品詳細データ — 商品のメタデータ。例としては、色、部門、サイズなどがあります。
-
価格データ — タイムスタンプが付随した各商品の時系列の価格。
-
プロモーション情報データ — 商品コレクション (カテゴリ) またはタイムスタンプが付随した個別の商品についてのさまざまなタイプのプロモーション。
-
在庫情報データ — SKU が在庫にあるか購入可能ある場合と SKU が在庫切れである場合を比較する情報が時間単位ごとに表示されます。
-
位置情報データ — 特定の時点での商品または販売の拠点は、
location_idstore_id文字列または実際の位置情報として表示できます。位置情報には、国コードと 5 桁の郵便番号、またはlatitude_longitudeを使用できます。拠点は、取引販売の「ディメンション」として扱われます。
Amazon Forecast
この問題では売上ではなく需要の予測に焦点をあてているにもかかわらず、この企業で記録されているのは売上のみであるため、在庫情報が重要であることに注意してください。SKU が在庫切れになると、販売数は潜在的な需要を下回るため、こののような在庫切れのイベントが発生した日時を把握して記録することが重要です。
考慮すべきその他のデータセットには、ウェブページ訪問数、検索用語の詳細、ソーシャルメディア、気象情報などがあります。多くの場合、このデータをモデルで使用するには、データ履歴と将来のデータがあることが重要です。これは、多くの予測モデルやバックテスト (ステップ 4: 予測を評価する セクションで説明) の要件となっています。
予測の問題によっては、未加工データの頻度が予測の問題の頻度と自然に一致することがあります。この例としては、分単位での予測の場合に、分単位でサンプリングされるサーバーボリュームのリクエストがあります。
多くの場合、データはより細かい頻度で記録されるか、時間範囲内の任意のタイムスタンプで記録されますが、予測の問題の場合の詳細度はより粗くなります。これは小売業のケーススタディでよく見られます。販売データは通常、取引データとして記録されます。取引データの形式は、例えば、販売が行われた日時をきめ細かく記録したタイムスタンプで構成されています。予測のユースケースでは、このような詳細度は必要ない場合があり、このデータを時間単位または日単位の売上に集計する方が適切な場合があります。このケースでは、集計のレベルは、例えば在庫管理やリソースプランニングなど、下流の問題に対応するものとします。
例
次の図の左のグラフは、カンマ区切り値 (CSV) ファイルとして Amazon Forecast に入力できる未加工の顧客売上データの例を示しています。この例では、売上データはより細かい日次時間のグリッドで定義されています。予測の問題の場合、より粗い時間グリッドでである週次需要を将来的に予測します。Amazon Forecast では、create_predictor API コールで特定の週の日次値を集計します。
集計された結果、未加工データは、週ごとに固定した頻度形式での時系列コレクションに変換されます。右のグラフはこの集計を、デフォルトの合計集計方法を使用したターゲット時系列で表示しています。その他の集計方法には、平均化、最大化、最小化、単一点 (最初の時点など) の選択などがあります。データが企業のユースケースに最も適したものとなるように、集計の詳細度と方法を選択する必要があります。この例では、集計値は週次集計に対応しています。その他の集計方法は、create_predictor API の FeaturizationConfig パラメータの FeaturizationMethodParameters キーを使用してユーザーが設定することができます。
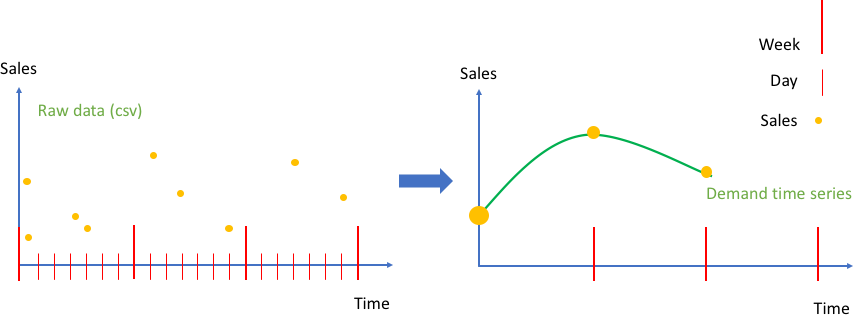
イベントである未加工の売上データ (左) を等間隔の時系列に集計した図 (右)
