翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
AWS Lambda 関数の計測
注記
X-Ray SDK/デーモンメンテナンス通知 – 2026 年 2 月 25 日、 AWS X-Ray SDKsデーモンはメンテナンスモードに移行します。 AWS では、X-Ray SDK とデーモンのリリースがセキュリティの問題にのみ対処するように制限されます。サポートタイムラインの詳細については、「X-Ray SDK とデーモンのサポートタイムライン」を参照してください。OpenTelemetry に移行することをお勧めします。OpenTelemetry への移行の詳細については、「X-Ray による計装から OpenTelemetry による計装への移行」を参照してください。
Scorekeep は 2 つの AWS Lambda 関数を使用します。1 つ目は、新しいユーザー用にランダムな名前を生成する lambda ブランチからの Node.js 関数です。ユーザーが名前を入力せずにセッションを作成すると、アプリケーションは、 AWS SDK for Javaで random-name という名前の関数を呼び出します。X-Ray SDK for Java は、計測された AWS SDK クライアントで行われた他の呼び出しと同様に、サブセグメント内の Lambda への呼び出しに関する情報を記録します。
注記
random-name Lambda 関数を実装するには、Elastic Beanstalk 環境の外でその他のリソースを作成する必要があります。詳細については readme、手順については「AWS
Lambda との統合
2 つ目の関数 scorekeep-worker は、Scorekeep API と関係なく実行される Python 関数です。ゲームが終了すると、API はセッション ID とゲーム ID を SQS キューに書き込みます。ワーカー関数はキューから項目を読み取り、Scorekeep API を呼び出してAmazon S3 内のストレージのゲームセッションごとに完全なレコードを構築します。
Scorekeep には、両方の関数を作成するための CloudFormation テンプレートとスクリプトが含まれています。X-Ray SDK を関数コードとバンドルする必要があるため、テンプレートはコードなしで関数を作成します。Scorekeep をデプロイすると、.ebextensions フォルダに含まれている設定ファイルにより、SDK を含むソースバンドルが作成され、 AWS Command Line Interfaceによって関数コードと設定が更新されます。
ランダム名
Scorekeep は、ユーザーがサインインしたりユーザー名を指定したりせずにゲームセッションを開始するとランダム名関数を呼び出します。random-name の呼び出しが Lambda で処理されると、「トレースヘッダー」が読み出されます。これには、X-Ray SDK for Javaによって書き込まれるトレース ID とサンプリングデシジョンを含みます。
Lambda は、サンプリングされたリクエストごとに X-Ray デーモンを実行し、2 つのセグメントを書き込みます。最初のセグメントでは、関数を呼び出す Lambda の呼び出しに関する情報を記録します。このセグメントには、Scorekeep によって記録されるサブセグメントと同じ情報が含まれますが、Lambda の視点からという点で異なります。2 番目のセグメントは、関数の動作を表します。
Lambda は、関数コンテキストを通じて X-Ray SDK に関数セグメントを渡します。Lambda 関数を実装した場合、受信リクエストのセグメントを作成するために SDK は使用しません。 Lambdaにセグメントが提供され、SDK を使用することでクライアントを実装してサブセグメントを書き込みます。
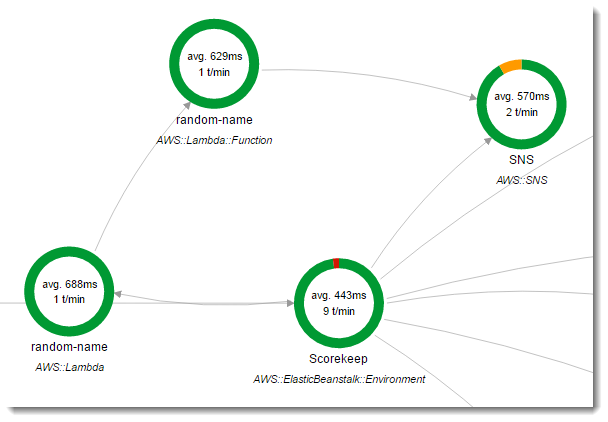
random-name 関数は、Node.js で実装されています。Node.js の SDK for JavaScript を使用して Amazon SNS で通知を送信し、X-Ray SDK for Node.js を使用して AWS SDK クライアントを計測します。注釈を書き込むため、関数は AWSXRay.captureFunc を使用してカスタムサブセグメントを作成し、実装された関数に注釈を書き込みます。 Lambdaでは、関数セグメントに直接注釈を書き込むことはできません。作成したサブセグメントにのみ書き込むことができます。
例 function/index.js
var AWSXRay = require('aws-xray-sdk-core');
var AWS = AWSXRay.captureAWS(require('aws-sdk'));
AWS.config.update({region: process.env.AWS_REGION});
var Chance = require('chance');
var myFunction = function(event, context, callback) {
var sns = new AWS.SNS();
var chance = new Chance();
var userid = event.userid;
var name = chance.first();
AWSXRay.captureFunc('annotations', function(subsegment){
subsegment.addAnnotation('Name', name);
subsegment.addAnnotation('UserID', event.userid);
});
// Notify
var params = {
Message: 'Created randon name "' + name + '"" for user "' + userid + '".',
Subject: 'New user: ' + name,
TopicArn: process.env.TOPIC_ARN
};
sns.publish(params, function(err, data) {
if (err) {
console.log(err, err.stack);
callback(err);
}
else {
console.log(data);
callback(null, {"name": name});
}
});
};
exports.handler = myFunction;この関数は、サンプルアプリケーションを Elastic Beanstalk にデプロイするときに自動的に作成されます。xray ブランチには、空白のLambda 関数を作成するスクリプトが含まれています。.ebextensions フォルダの設定ファイルは、デプロイnpm install中に で関数パッケージを構築し、 CLI で Lambda AWS 関数を更新します。
ワーカー
実装されたワーカー関数は、ワーカー関数と関連リソースを作成してからでないと実行できないため、自身のブランチ xray-worker で提供されます。手順については、ブランチの readme
この関数は、5 分ごとにバンドルされているAmazon CloudWatch Events イベントによってトリガーされます。実行されると、この関数は Scorekeep によって管理されるAmazon SQS キューから項目を取得します。各メッセージには、完了したゲームに関する情報が含まれています。
ワーカーは、ゲームレコードが参照する他のテーブルからゲームレコードとドキュメントを取得します。たとえば、 DynamoDBのゲームレコードには、ゲーム中に実行されたムービーのリストが含まれています。リストには、ムービー自体は含まれておらず、別個のテーブルに格納されたムービーの ID が含まれています。
セッションと状態は、参照としても保存されます。これにより、ゲームテーブル内のエントリが大きくなりすぎることはありませんが、ゲームに関するすべての情報を取得するには追加の呼び出しが必要です。このワーカーは、これらのすべてのエントリを間接参照し、ゲームの完全なレコードをAmazon S3 に単一のドキュメントとして構築します。データで分析を行う場合、読み取り量の多いデータ移行を実行してデータを DynamoDBから取得しなくても、Amazon Athena を使用して Amazon S3 で直接クエリを実行できます。
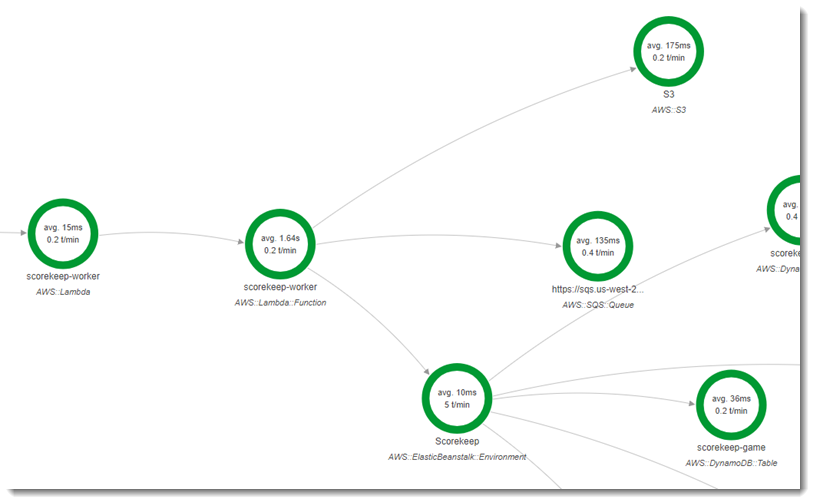
ワーカー関数では、 AWS Lambdaのその設定においてアクティブトレースが有効になっています。ランダム名関数とは異なり、ワーカーは計測されたアプリケーションからリクエストを受信しないため、 AWS Lambda はトレースヘッダーを受信しません。アクティブトレースを使用すると、 Lambdaはトレース ID を作成してサンプリングの決定を行います。
X-Ray SDK for Python は、SDK をインポートし、そのpatch_all関数を実行して、Amazon SQS と Amazon S3 の呼び出しに使用する AWS SDK for Python (Boto) と HTTclientsにパッチを適用する関数の上部にある数行です。ワーカーが API を呼び出すと、SDK はトレースヘッダーをリクエストに追加し、API を通じて呼び出しをトレースします。
例_lambda/scorekeep-worker/scorekeep-worker.py
import os
import boto3
import json
import requests
import time
from aws_xray_sdk.core import xray_recorder
from aws_xray_sdk.core import patch_all
patch_all()
queue_url = os.environ['WORKER_QUEUE']
def lambda_handler(event, context):
# Create SQS client
sqs = boto3.client('sqs')
s3client = boto3.client('s3')
# Receive message from SQS queue
response = sqs.receive_message(
QueueUrl=queue_url,
AttributeNames=[
'SentTimestamp'
],
MaxNumberOfMessages=1,
MessageAttributeNames=[
'All'
],
VisibilityTimeout=0,
WaitTimeSeconds=0
)
...