After careful consideration, we have decided to discontinue Amazon Kinesis Data Analytics for SQL applications:
1. From September 1, 2025, we won't provide any bug fixes for Amazon Kinesis Data Analytics for SQL applications because we will have limited support for it, given the upcoming discontinuation.
2. From October 15, 2025, you will not be able to create new Kinesis Data Analytics for SQL applications.
3. We will delete your applications starting January 27, 2026. You will not be able to start or operate your Amazon Kinesis Data Analytics for SQL applications. Support will no longer be available for Amazon Kinesis Data Analytics for SQL from that time. For more information, see Amazon Kinesis Data Analytics for SQL Applications discontinuation.
Migrating to Managed Service for Apache Flink Studio Examples
After careful consideration, we have made the decision to discontinue Amazon Kinesis Data Analytics for SQL applications. To help you plan and migrate away from Amazon Kinesis Data Analytics for SQL applications, we will discontinue the offering gradually over 15 months. These are important dates to note, September 1, 2025, October 15, 2025, and January 27, 2026.
-
From September 1, 2025, we won't provide any bug fixes for Amazon Kinesis Data Analytics for SQL applications because we will have limited support for it, given the upcoming discontinuation.
-
From October 15, 2025, you will not be able to create new Amazon Kinesis Data Analytics for SQL applications.
-
We will delete your applications starting January 27, 2026. You will not be able to start or operate your Amazon Kinesis Data Analytics for SQL applications. Support will no longer be available for Amazon Kinesis Data Analytics for SQL applications from that time. To learn more, see Amazon Kinesis Data Analytics for SQL Applications discontinuation.
We recommend that you use Amazon Managed Service for Apache Flink. It combines ease of use with advanced analytical capabilities, letting you build stream processing applications in minutes.
This section provides code and architecture examples to help you move your Amazon Kinesis Data Analytics for SQL applications workloads to Managed Service for Apache Flink.
For additional information, also see this AWS blog post: Migrate from Amazon Kinesis Data Analytics for SQL Applications to Managed Service for Apache Flink
Studio
To migrate your workloads to Managed Service for Apache Flink Studio or Managed Service for Apache Flink, this section provides query translations you can use for common use cases.
Before you explore these examples, we recommend you first review Using a Studio notebook with a Managed Service for Apache Flink.
Re-creating Kinesis Data Analytics for SQL queries in Managed Service for Apache Flink Studio
The following options provide translations of common SQL-based Kinesis Data Analytics application queries to Managed Service for Apache Flink Studio.
If you are looking to move workloads that use Random Cut Forest from Kinesis Analytics
for SQL to Managed Service for Apache Flink, this AWS blog post
See Converting-KDASQL-KDAStudio/
In the following exercise, you will change your data flow to use Amazon Managed Service for Apache Flink Studio. This will also mean switching from Amazon Kinesis Data Firehose to Amazon Kinesis Data Streams.
First we share a typical KDA-SQL architecture, before showing how you can replace this
using Amazon Managed Service for Apache Flink Studio and Amazon Kinesis Data Streams.
Alternatively you can launch the AWS CloudFormation template here
Amazon Kinesis Data Analytics-SQL and Amazon Kinesis Data Firehose
Here is the Amazon Kinesis Data Analytics SQL architectural flow:
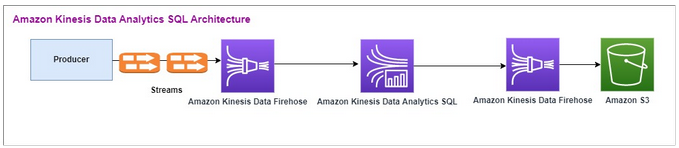
We first examine the setup of a legacy Amazon Kinesis Data Analytics-SQL and Amazon Kinesis Data
Firehose. The use case is a trading market where trading data, including stock ticker
and price, streams from external sources to Amazon Kinesis systems. Amazon Kinesis Data Analytics for
SQL uses the input stream to execute Windowed queries like Tumbling window to determine
the trade volume and the min, max, and average
trade price over a one-minute window for each stock ticker.
Amazon Kinesis Data Analytics-SQL is set up to ingest data from the Amazon Kinesis Data Firehose API. After processing, Amazon Kinesis Data Analytics-SQL sends the processed data to another Amazon Kinesis Data Firehose, which then saves the output in an Amazon S3 bucket.
In this case, you use Amazon Kinesis Data Generator. Amazon Kinesis Data Generator
allows you to send test data to your Amazon Kinesis Data Streams or Amazon Kinesis Data
Firehose delivery streams. To get started, follow the instructions here
Once you run the AWS CloudFormation template, the output section will provide the Amazon Kinesis
Data Generator url. Log in to the portal using the Cognito user id and password you
set up here
Following is a sample payload using Amazon Kinesis Data Generator. The data generator targets the input Amazon Kinesis Firehose Streams to stream the data continuously. The Amazon Kinesis SDK client can send data from other producers as well.
2023-02-17 09:28:07.763,"AAPL",5032023-02-17 09:28:07.763, "AMZN",3352023-02-17 09:28:07.763, "GOOGL",1852023-02-17 09:28:07.763, "AAPL",11162023-02-17 09:28:07.763, "GOOGL",1582
The following JSON is used to generate a random series of trade time and date, stock ticker, and stock price:
date.now(YYYY-MM-DD HH:mm:ss.SSS), "random.arrayElement(["AAPL","AMZN","MSFT","META","GOOGL"])", random.number(2000)
Once you choose Send data, the generator will start sending mock data.
External systems stream the data to Amazon Kinesis Data Firehose. Using Amazon Kinesis Data Analytics for SQL Applications, you can analyze streaming data using standard SQL. The service enables you to author and run SQL code against streaming sources to perform time-series analytics, feed real-time dashboards, and create real-time metrics. Amazon Kinesis Data Analytics for SQL Applications could create a destination stream from SQL queries on the input stream and send the destination stream to another Amazon Kinesis Data Firehose. The destination Amazon Kinesis Data Firehose could send the analytical data to Amazon S3 as the final state.
Amazon Kinesis Data Analytics-SQL legacy code is based on an extension of SQL Standard.
You use the following query in Amazon Kinesis Data Analytics-SQL. You first create a destination
stream for the query output. Then, you would use PUMP, which is an Amazon
Kinesis Data Analytics Repository Object (an extension of the SQL Standard) that provides a
continuously running INSERT INTO stream SELECT ... FROM query
functionality, thereby enabling the results of a query to be continuously entered into a
named stream.
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (EVENT_TIME TIMESTAMP, INGEST_TIME TIMESTAMP, TICKER VARCHAR(16), VOLUME BIGINT, AVG_PRICE DOUBLE, MIN_PRICE DOUBLE, MAX_PRICE DOUBLE); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM STEP("SOURCE_SQL_STREAM_001"."tradeTimestamp" BY INTERVAL '60' SECOND) AS EVENT_TIME, STEP("SOURCE_SQL_STREAM_001".ROWTIME BY INTERVAL '60' SECOND) AS "STREAM_INGEST_TIME", "ticker", COUNT(*) AS VOLUME, AVG("tradePrice") AS AVG_PRICE, MIN("tradePrice") AS MIN_PRICE, MAX("tradePrice") AS MAX_PRICEFROM "SOURCE_SQL_STREAM_001" GROUP BY "ticker", STEP("SOURCE_SQL_STREAM_001".ROWTIME BY INTERVAL '60' SECOND), STEP("SOURCE_SQL_STREAM_001"."tradeTimestamp" BY INTERVAL '60' SECOND);
The preceding SQL uses two time windows – tradeTimestamp that
comes from the incoming stream payload and ROWTIME.tradeTimestamp is
also called Event Time or client-side time. It is often
desirable to use this time in analytics because it is the time when an event
occurred. However, many event sources, such as mobile phones and web clients, do not
have reliable clocks, which can lead to inaccurate times. In addition, connectivity
issues can lead to records appearing on a stream not in the same order the events
occurred.
In-application streams also include a special column called ROWTIME. It
stores a timestamp when Amazon Kinesis Data Analytics inserts a row in the first in-application
stream. ROWTIME reflects the timestamp at which Amazon Kinesis Data Analytics inserted a
record into the first in-application stream after reading from the streaming source.
This ROWTIME value is then maintained throughout your application.
The SQL determines the count of ticker as volume, min,
max, and average price over a 60-second
interval.
Using each of these times in windowed queries that are time-based has advantages and disadvantages. Choose one or more of these times, and a strategy to deal with the relevant disadvantages based on your use case scenario.
A two-window strategy uses two time-based, both ROWTIME and one of the
other times like the event time.
-
Use
ROWTIMEas the first window, which controls how frequently the query emits the results, as shown in the following example. It is not used as a logical time. -
Use one of the other times that is the logical time that you want to associate with your analytics. This time represents when the event occurred. In the following example, the analytics goal is to group the records and return count by ticker.
Amazon Managed Service for Apache Flink Studio
In the updated architecture, you replace Amazon Kinesis Data Firehose with Amazon Kinesis Data Streams. Amazon Kinesis Data Analytics for SQL Applications are replaced by Amazon Managed Service for Apache Flink Studio. Apache Flink code is run interactively within an Apache Zeppelin Notebook. Amazon Managed Service for Apache Flink Studio sends the aggregated trade data to an Amazon S3 bucket for storage. The steps are shown following:
Here is the Amazon Managed Service for Apache Flink Studio architectural flow:

Create a Kinesis Data Stream
To create a data stream using the console
Sign in to the AWS Management Console and open the Kinesis console at https://console.aws.amazon.com/kinesis
. -
In the navigation bar, expand the Region selector and choose a Region.
-
Choose Create data stream.
-
On the Create Kinesis stream page, enter a name for your data stream and accept the default On-demand capacity mode.
With the On-demand mode, you can then choose Create Kinesis stream to create your data stream.
On the Kinesis streams page, your stream's Status is Creating while the stream is being created. When the stream is ready to use, the Status changes to Active.
-
Choose the name of your stream. The Stream Details page displays a summary of your stream configuration, along with monitoring information.
-
In the Amazon Kinesis Data Generator, change the Stream/delivery stream to the new Amazon Kinesis Data Streams: TRADE_SOURCE_STREAM.
JSON and Payload will be the same as you used for Amazon Kinesis Data Analytics-SQL. Use the Amazon Kinesis Data Generator to produce some sample trading payload data and target the TRADE_SOURCE_STREAM Data Stream for this exercise:
{{date.now(YYYY-MM-DD HH:mm:ss.SSS)}}, "{{random.arrayElement(["AAPL","AMZN","MSFT","META","GOOGL"])}}", {{random.number(2000)}} -
On the AWS Management Console go to Managed Service for Apache Flink and then choose Create application.
-
On the left navigation pane, choose Studio notebooks and then choose Create studio notebook.
-
Enter a name for the studio notebook.
-
Under AWS Glue database, provide an existing AWS Glue database that will define the metadata for your sources and destinations. If you don’t have an AWS Glue database, choose Create and do the following:
-
In the AWS Glue console, choose Databases under Data catalog from the left-hand menu.
-
Choose Create database
-
In the Create database page, enter a name for the database. In the Location - optional section, choose Browse Amazon S3 and select the Amazon S3 bucket. If you don't have an Amazon S3 bucket already set up, you can skip this step and come back to it later.
-
(Optional). Enter a description for the database.
-
Choose Create database.
-
-
Choose Create notebook
-
Once your notebook is created, choose Run.
-
Once the notebook has been successfully started, launch a Zeppelin notebook by choosing Open in Apache Zeppelin.
-
On the Zeppelin Notebook page, choose Create new note and name it MarketDataFeed.
The Flink SQL code is explained following, but first this is what a Zeppelin notebook screen looks like
Amazon Managed Service for Apache Flink Studio Code
Amazon Managed Service for Apache Flink Studio uses Zeppelin Notebooks to run the code. Mapping is done for this example to ssql code based on Apache Flink 1.13. The code in the Zeppelin Notebook is shown following, one block at a time.
Before running any code in your Zeppelin Notebook, Flink configuration commands must be run. If you need to change any configuration setting after running code (ssql, Python, or Scala), you must stop and restart your notebook. In this example, you must set checkpointing. Checkpointing is required so that you can stream data to a file in Amazon S3. This allows data streaming to Amazon S3 to be flushed to a file. The following statement sets the interval to 5000 milliseconds.
%flink.conf execution.checkpointing.interval 5000
%flink.conf indicates that this block is configuration statements.
For more information about Flink configuration including checkpointing, see
Apache Flink Checkpointing
The input table for the source Amazon Kinesis Data Streams is created with the
following Flink ssql code. Note that the TRADE_TIME field stores
the date/time created by the data generator.
%flink.ssql DROP TABLE IF EXISTS TRADE_SOURCE_STREAM; CREATE TABLE TRADE_SOURCE_STREAM (--`arrival_time` TIMESTAMP(3) METADATA FROM 'timestamp' VIRTUAL, TRADE_TIME TIMESTAMP(3), WATERMARK FOR TRADE_TIME as TRADE_TIME - INTERVAL '5' SECOND,TICKER STRING,PRICE DOUBLE, STATUS STRING)WITH ('connector' = 'kinesis','stream' = 'TRADE_SOURCE_STREAM', 'aws.region' = 'us-east-1','scan.stream.initpos' = 'LATEST','format' = 'csv');
You can view the input stream with this statement:
%flink.ssql(type=update)-- testing the source stream select * from TRADE_SOURCE_STREAM;
Before sending the aggregate data to Amazon S3, you can view it directly in Amazon Managed Service for Apache Flink Studio with a tumbling window select query. This aggregates the trading data in a one-minute time window. Note that the %flink.ssql statement must have a (type=update) designation:
%flink.ssql(type=update) select TUMBLE_ROWTIME(TRADE_TIME, INTERVAL '1' MINUTE) as TRADE_WINDOW, TICKER, COUNT(*) as VOLUME, AVG(PRICE) as AVG_PRICE, MIN(PRICE) as MIN_PRICE, MAX(PRICE) as MAX_PRICE FROM TRADE_SOURCE_STREAMGROUP BY TUMBLE(TRADE_TIME, INTERVAL '1' MINUTE), TICKER;
You can then create a table for the destination in Amazon S3. You must use a
watermark. A watermark is a progress metric that indicates a point in time when
you are confident that no more delayed events will arrive. The reason for the
watermark is to account for late arrivals. The interval ‘5’ Second
allows trades to enter the Amazon Kinesis Data Stream 5 seconds late and still
be included if they have a timestamp within the window. For more information,
see Generating Watermarks
%flink.ssql(type=update) DROP TABLE IF EXISTS TRADE_DESTINATION_S3; CREATE TABLE TRADE_DESTINATION_S3 ( TRADE_WINDOW_START TIMESTAMP(3), WATERMARK FOR TRADE_WINDOW_START as TRADE_WINDOW_START - INTERVAL '5' SECOND, TICKER STRING, VOLUME BIGINT, AVG_PRICE DOUBLE, MIN_PRICE DOUBLE, MAX_PRICE DOUBLE) WITH ('connector' = 'filesystem','path' = 's3://trade-destination/','format' = 'csv');
This statement inserts the data into the TRADE_DESTINATION_S3.
TUMPLE_ROWTIME is the timestamp of the inclusive upper bound of
the tumbling window.
%flink.ssql(type=update) insert into TRADE_DESTINATION_S3 select TUMBLE_ROWTIME(TRADE_TIME, INTERVAL '1' MINUTE), TICKER, COUNT(*) as VOLUME, AVG(PRICE) as AVG_PRICE, MIN(PRICE) as MIN_PRICE, MAX(PRICE) as MAX_PRICE FROM TRADE_SOURCE_STREAM GROUP BY TUMBLE(TRADE_TIME, INTERVAL '1' MINUTE), TICKER;
Let your statement run for 10 to 20 minutes to accumulate some data in Amazon S3. Then abort your statement.
This closes the file in Amazon S3 so that it is viewable.
Here is what the contents looks like:

You can use the AWS CloudFormation template
AWS CloudFormation will create the following resources in your AWS account:
-
Amazon Kinesis Data Streams
-
Amazon Managed Service for Apache Flink Studio
-
AWS Glue database
-
Amazon S3 bucket
-
IAM roles and policies for Amazon Managed Service for Apache Flink Studio to access appropriate resources
Import the notebook and change the Amazon S3 bucket name with the new Amazon S3 bucket created by AWS CloudFormation.

See more
Here are some additional resources that you can use to learn more about using Managed Service for Apache Flink Studio:
The purpose of the pattern is to demonstrate how to leverage UDFs in Kinesis Data Analytics-Studio Zeppelin notebooks for processing data in the Kinesis stream. Managed Service for Apache Flink Studio uses Apache Flink to provide advanced analytical capabilities, including exactly once processing semantics, event-time windows, extensibility using user defined functions and customer integrations, imperative language support, durable application state, horizontal scaling, support for multiple data sources, extensible integrations, and more. These are critical for ensuring accuracy, completeness, consistency, and reliability of data streams processing and are not available with Amazon Kinesis Data Analytics for SQL.
In this sample application, we will demonstrate how to leverage UDFs in KDA-Studio Zeppelin notebook for processing data in the Kinesis stream. Studio notebooks for Kinesis Data Analytics allows you to interactively query data streams in real time, and easily build and run stream processing applications using standard SQL, Python, and Scala. With a few clicks in the AWS Management Console, you can launch a serverless notebook to query data streams and get results in seconds. For more information, see Using a Studio notebook with Kinesis Data Analytics for Apache Flink.
Lambda functions used for pre/post processing of data in KDA-SQL applications:

User-defined functions for pre/post processing of data using KDA-Studio Zeppelin notebooks

User-defined functions (UDFs)
To reuse common business logic into an operator, it can be useful to reference a user-defined function to transform your data stream. This can be done either within the Managed Service for Apache Flink Studio notebook, or as an externally referenced application jar file. Utilizing User-defined functions can simplify the transformations or data enrichments that you might perform over streaming data.
In your notebook, you will be referencing a simple Java application jar that has functionality to anonymize personal phone numbers. You can also write Python or Scala UDFs for use within the notebook. We chose a Java application jar to highlight the functionality of importing an application jar into a Pyflink notebook.
Environment setup
To follow this guide and interact with your streaming data, you will use an AWS CloudFormation script to launch the following resources:
-
Source and target Kinesis Data Streams
-
Glue Database
-
IAM role
-
Managed Service for Apache Flink Studio Application
-
Lambda Function to start Managed Service for Apache Flink Studio Application
-
Lambda Role to execute the preceding Lambda function
-
Custom resource to invoke the Lambda function
Download the AWS CloudFormation template here
Create the AWS CloudFormation stack
-
Go to the AWS Management Console and choose CloudFormation under the list of services.
-
On the CloudFormation page, choose Stacks and then choose Create Stack with new resources (standard).
-
On the Create stack page, choose Upload a Template File, and then choose the
kda-flink-udf.ymlthat you downloaded previously. Upload the file and then choose Next. -
Give the template a name, such as
kinesis-UDFso that it is easy to remember, and update input Parameters such as input-stream if you want a different name. Choose Next. -
On the Configure stack options page, add Tags if you want and then choose Next.
-
On the Review page, check the boxes allowing for the creation of IAM resources and then choose Submit.
The AWS CloudFormation stack may take 10 to 15 minutes to launch depending on the Region you are
launching in. Once you see CREATE_COMPLETE status for the entire stack, you
are ready to continue.
Working with Managed Service for Apache Flink Studio notebook
Studio notebooks for Kinesis Data Analytics allow you to interactively query data streams in real time, and easily build and run stream processing applications using standard SQL, Python, and Scala. With a few clicks in the AWS Management Console, you can launch a serverless notebook to query data streams and get results in seconds.
A notebook is a web-based development environment. With notebooks, you get a simple interactive development experience combined with the advanced data stream processing capabilities provided by Apache Flink. Studio notebooks use notebooks powered by Apache Zeppelin, and uses Apache Flink as the stream processing engine. Studio notebooks seamlessly combine these technologies to make advanced analytics on data streams accessible to developers of all skill sets.
Apache Zeppelin provides your Studio notebooks with a complete suite of analytics tools, including the following:
-
Data Visualization
-
Exporting data to files
-
Controlling the output format for easier analysis
Using the notebook
-
Go to the AWS Management Console and choose Amazon Kinesis under the list of services.
-
On the left-hand navigation page, choose Analytics applications and then choose Studio notebooks.
-
Verify that the KinesisDataAnalyticsStudio notebook is running.
-
Choose the notebook and then choose Open in Apache Zeppelin.
-
Download the Data Producer Zeppelin Notebook
file which you will use to read and load data into the Kinesis Stream. -
Import the
Data ProducerZeppelin Notebook. Make sure to modify inputSTREAM_NAMEandREGIONin the notebook code. The input stream name can be found in the AWS CloudFormation stack output. -
Execute Data Producer notebook by choosing the Run this paragraph button to insert sample data into the input Kinesis Data Stream.
-
While the sample data loads, download MaskPhoneNumber-Interactive notebook
, which will read input data, anonymize phone numbers from the input stream and store anonymized data into the output stream. -
Import the
MaskPhoneNumber-interactiveZeppelin notebook. -
Execute each paragraph in the notebook.
-
In paragraph 1, you import a User Defined Function to anonymize phone numbers.
%flink(parallelism=1) import com.mycompany.app.MaskPhoneNumber stenv.registerFunction("MaskPhoneNumber", new MaskPhoneNumber()) -
In the next paragraph, you create an in-memory table to read input stream data. Make sure the stream name and AWS Region are correct.
%flink.ssql(type=update) DROP TABLE IF EXISTS customer_reviews; CREATE TABLE customer_reviews ( customer_id VARCHAR, product VARCHAR, review VARCHAR, phone VARCHAR ) WITH ( 'connector' = 'kinesis', 'stream' = 'KinesisUDFSampleInputStream', 'aws.region' = 'us-east-1', 'scan.stream.initpos' = 'LATEST', 'format' = 'json'); -
Check if data is loaded into the in-memory table.
%flink.ssql(type=update) select * from customer_reviews -
Invoke the user defined function to anonymize the phone number.
%flink.ssql(type=update) select customer_id, product, review, MaskPhoneNumber('mask_phone', phone) as phoneNumber from customer_reviews -
Now that the phone numbers are masked, create a view with a masked number.
%flink.ssql(type=update) DROP VIEW IF EXISTS sentiments_view; CREATE VIEW sentiments_view AS select customer_id, product, review, MaskPhoneNumber('mask_phone', phone) as phoneNumber from customer_reviews -
Verify the data.
%flink.ssql(type=update) select * from sentiments_view -
Create in-memory table for the output Kinesis Stream. Make sure stream name and AWS Region are correct.
%flink.ssql(type=update) DROP TABLE IF EXISTS customer_reviews_stream_table; CREATE TABLE customer_reviews_stream_table ( customer_id VARCHAR, product VARCHAR, review VARCHAR, phoneNumber varchar ) WITH ( 'connector' = 'kinesis', 'stream' = 'KinesisUDFSampleOutputStream', 'aws.region' = 'us-east-1', 'scan.stream.initpos' = 'TRIM_HORIZON', 'format' = 'json'); -
Insert updated records in the target Kinesis Stream.
%flink.ssql(type=update) INSERT INTO customer_reviews_stream_table SELECT customer_id, product, review, phoneNumber FROM sentiments_view -
View and verify data from the target Kinesis Stream.
%flink.ssql(type=update) select * from customer_reviews_stream_table
-
Promoting a notebook as an application
Now that you have tested your notebook code interactively, you will deploy the code as a streaming application with durable state. You will need to first modify Application configuration to specify a location for your code in Amazon S3.
-
On the AWS Management Console, choose your notebook and in Deploy as application configuration - optional, choose Edit.
-
Under Destination for code in Amazon S3, choose the Amazon S3 bucket that was created by the AWS CloudFormation scripts
. The process may take a few minutes. -
You won't be able to promote the note as is. If you try, you will an error as
Selectstatements are not supported. To avert this issue, download the MaskPhoneNumber-Streaming Zeppelin Notebook. -
Import
MaskPhoneNumber-streamingZeppelin Notebook. -
Open the note and choose Actions for KinesisDataAnalyticsStudio.
-
Choose Build MaskPhoneNumber-Streaming and export to S3. Make sure to rename Application Name and include no special characters.
-
Choose Build and Export. This will take few minutes to setup Streaming Application.
-
Once the build is complete, choose Deploy using AWS console.
-
On the next page, review settings and make sure to choose the correct IAM role. Next, choose Create streaming application.
-
After few minutes, you would see message that the streaming application was created successfully.
For more information on deploying applications with durable state and limits, see Deploying as an application with durable state.
Cleanup
Optionally, you can now uninstall the AWS CloudFormation stack. This will remove all the services which you set up in previously.
