Aurora DB 클러스터에 대한 볼륨 복제
Aurora 복제를 사용하면 처음에는 원본과 동일한 데이터 페이지를 공유하지만 별도의 독립적인 볼륨인 새 클러스터를 생성할 수 있습니다. 이 프로세스는 빠르고 비용 효율적으로 진행되도록 설계되었습니다. 연결된 데이터 볼륨이 있는 새 클러스터를 복제본이라고 합니다. 복제본 생성은 스냅샷 복원과 같은 다른 기술을 사용하여 데이터를 물리적으로 복사하는 것보다 빠르고 공간 효율적입니다.
주제
Aurora 복제 개요
Aurora는 기록 중 복사(Copy-on-Write) 프로토콜을 사용하여 복제본을 생성합니다. 이 메커니즘은 최소한의 추가 공간을 사용하여 초기 복제를 만듭니다. 복제가 처음 생성되면 Aurora는 소스 Aurora DB 클러스터와 새로운(복제된) Aurora DB 클러스터에서 사용하는 데이터의 단일 복사본을 유지합니다. 소스 Aurora DB 클러스터 또는 Aurora DB 클러스터 복제가 Aurora 스토리지 볼륨의 데이터를 변경한 경우에만 추가 스토리지가 할당됩니다. 기록 중 복사(Copy-on-Write) 프로토콜에 대한 자세한 내용은 Aurora 복제 작동 방식 섹션을 참조하세요.
Aurora 복제 작업은 데이터 손상 위험 없이 프로덕션 데이터를 사용하여 테스트 환경을 신속하게 설정하는 데 특히 유용합니다. 다음과 같은 여러 유형의 애플리케이션에 복제본을 사용할 수 있습니다.
-
잠재적 변경 사항(예: 스키마 변경 및 파라미터 그룹 변경)을 실험하여 모든 영향을 평가합니다.
-
데이터 내보내기 또는 복제본에서 분석 쿼리 실행과 같은 워크로드 집약적인 작업을 수행하는 경우
-
개발, 테스트 또는 기타 용도로 프로덕션 DB 클러스터의 복사본을 생성합니다.
동일한 Aurora DB 클러스터에서 둘 이상의 복제본을 생성할 수 있습니다. 다른 복제본에서 여러 복제본을 생성할 수도 있습니다.
Aurora 복제본을 생성한 후 Aurora DB 인스턴스를 소스 Aurora DB 클러스터와 다르게 구성할 수 있습니다. 예를 들어 소스 프로덕션 Aurora DB 클러스터와 동일한 고가용성 요구 사항을 충족하기 위해 개발 목적으로 복제본이 필요하지 않을 수 있습니다. 이 경우 Aurora DB 클러스터에서 사용하는 여러 DB 인스턴스가 아닌 단일 Aurora DB 인스턴스로 복제본을 구성할 수 있습니다.
소스와 다른 배포 구성을 사용하여 복제를 생성하면 소스 Aurora DB 엔진의 최신 마이너 버전을 사용하여 복제본이 생성됩니다.
Aurora DB 클러스터에서 복제를 생성하면 소스 Aurora DB 클러스터를 소유하는 계정과 동일한 AWS 계정에서 복제본이 생성됩니다. 그러나 Aurora Serverless v2 및 프로비저닝된 Aurora DB 클러스터와 복제본을 다른 AWS 계정에 공유할 수도 있습니다. 자세한 내용은 AWS RAM과 Amazon Aurora에서 교차 계정 복제 단원을 참조하십시오.
복제본을 테스트, 개발 또는 다른 용도로 사용한 후 삭제할 수 있습니다.
Aurora 복제의 제한 사항
Aurora 복제는 다음과 같은 제한 사항이 있습니다.
-
AWS 리전에서 허용하는 최대 DB 클러스터 개수까지 원하는 만큼 복제본을 생성할 수 있습니다.
-
copy-on-write 프로토콜을 사용하여 최대 15개의 복제본을 만들 수 있습니다. 그러나 15개의 복제본을 생성한 후에는 다음에 생성하는 복제본이 전체 복제본이 됩니다. 전체 복사 프로토콜은 특정 시점 복구와 같은 역할을 합니다.
-
소스 Aurora DB 클러스터에서 다른 AWS 리전에 복제본을 생성할 수 없습니다.
-
병렬 쿼리 기능이 없는 Aurora DB 클러스터에서 병렬 쿼리를 사용하는 클러스터로의 복제본을 생성할 수 없습니다. 병렬 쿼리를 사용하는 클러스터에 데이터를 가져오려면 원본 클러스터의 스냅샷을 생성하여 병렬 쿼리 기능을 사용하는 클러스터에 복원합니다.
-
DB 인스턴스가 없는 Aurora DB 클러스터에서 복제본을 생성할 수 없습니다. 하나 이상의 DB 인스턴스가 있는 Aurora DB 클러스터만 복제할 수 있습니다.
-
복제본을 Aurora DB 클러스터의 Virtual Private Cloud(VPC)와 다른 Virtual Private Cloud(VPC)에 생성할 수 있습니다. 이렇게 하면 VPC의 서브넷을 동일한 가용 영역에 매핑해야 합니다.
-
프로비저닝된 Aurora DB 클러스터에서 Aurora 프로비저닝된 복제본을 생성할 수 있습니다.
-
Aurora Serverless v2 인스턴스가 있는 클러스터는 프로비저닝된 클러스터와 동일한 규칙을 따릅니다.
-
Aurora Serverless v1의 경우:
-
Aurora Serverless v1 DB 클러스터에서 프로비저닝된 복제본을 생성할 수 있습니다.
-
Aurora Serverless v1 또는 프로비저닝된 DB 클러스터에서 Aurora Serverless v1 복제본을 생성할 수 있습니다.
-
암호화되지 않은 프로비저닝된 Aurora DB 클러스터에서는 Aurora Serverless v1 복제본을 생성할 수 없습니다.
-
교차 계정 복제는 현재 Aurora Serverless v1 DB 클러스터 복제를 지원하지 않습니다. 자세한 내용은 계정 간 복제 제한 사항 단원을 참조하십시오.
-
복제된 Aurora Serverless v1 DB 클러스터는 Aurora Serverless v1 DB 클러스터와 동일한 동작과 제한 사항이 있습니다. 자세한 내용은 Amazon Aurora Serverless v1 사용 단원을 참조하십시오.
-
Aurora Serverless v1 DB 클러스터는 항상 암호화됩니다. Aurora Serverless v1 DB 클러스터를 프로비저닝된 Aurora DB 클러스터로 복제하는 경우 프로비저닝된 Aurora DB 클러스터가 암호화됩니다. 암호화 키를 선택할 수 있지만 암호화를 비활성화할 수는 없습니다. 프로비저닝된 Aurora DB 클러스터에서 Aurora Serverless v1로 복제하려면 암호화되고 프로비저닝된 Aurora DB 클러스터로 시작해야 합니다.
-
Aurora 복제 작동 방식
Aurora 복제는 Aurora DB 클러스터의 스토리지 계층에서 작동합니다. 이는 Aurora 스토리지 볼륨을 지원하는 기본 내구 미디어 측면에서 빠르고 공간 효율적인 기록 중 복사(copy-on-write) 프로토콜을 사용합니다. Amazon Aurora 스토리지 개요에서 Aurora 클러스터 볼륨에 대해 자세히 알아보세요.
기록 중 복사(copy-on-write) 이해
Aurora DB 클러스터는 기본 Aurora 스토리지 볼륨의 페이지에 데이터를 저장합니다.
예를 들어, 다음 다이어그램에서 데이터 페이지(1, 2, 3, 4)가 네 개인 Aurora DB 클러스터(A)를 찾을 수 있습니다. 복제본 B가 Aurora DB 클러스터에서 생성된다고 가정해 보겠습니다. 복제본이 생성되면 데이터가 복사되지 않습니다. 대신 복제본은 소스 Aurora DB 클러스터와 동일한 페이지 집합을 가리킵니다.
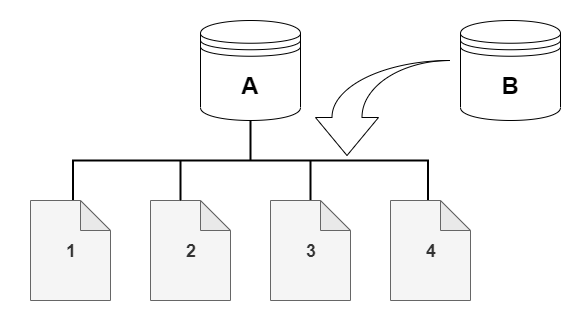
복제본이 생성되면 일반적으로 추가 스토리지가 필요하지 않습니다. 기록 중 복사(copy-on-write) 프로토콜은 물리적 스토리지 미디어에서 소스 세그먼트와 동일한 세그먼트를 사용합니다. 소스 세그먼트의 용량이 전체 복제본 세그먼트에 충분하지 않은 경우에만 추가 스토리지가 필요합니다. 이 경우 소스 세그먼트는 다른 물리적 디바이스로 복사됩니다.
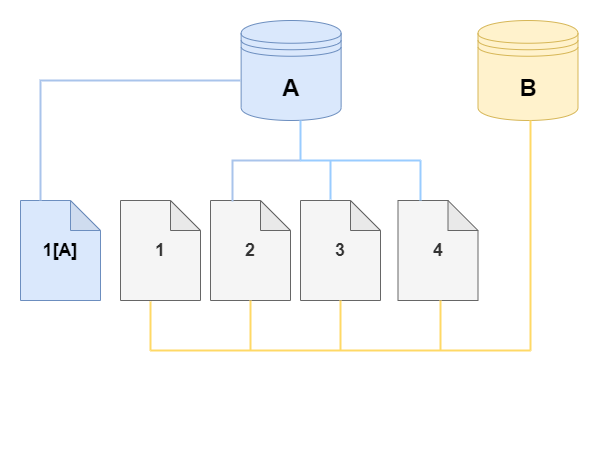
다음 다이어그램에서는 앞에서와 같이 동일한 클러스터 A와 해당 복제본 B를 사용하여 작동하는 기록 중 복사(copy-on-write) 프로토콜의 예를 찾을 수 있습니다. Aurora DB 클러스터(A)를 변경하여 페이지 1에 보관된 데이터가 변경된다고 가정해 보겠습니다. Aurora는 원본 페이지 1에 기록하는 대신 새 페이지 1[A]을 생성합니다. 클러스터(A)에 대한 Aurora DB 클러스터 볼륨은 이제 페이지 1[A], 2, 3, 4를 가리키고 복제본(B)은 여전히 원본 페이지를 참조합니다.
복제본에서 스토리지 볼륨의 페이지 4가 변경됩니다. 원본 페이지 4에 기록하는 대신 Aurora는 새 페이지 4[B]를 생성합니다. 이제 복제본은 페이지 1, 2, 3 및 페이지 4[B]를 가리키고 클러스터(A)는 계속해서 1[A], 2, 3 및 4를 가리킵니다.
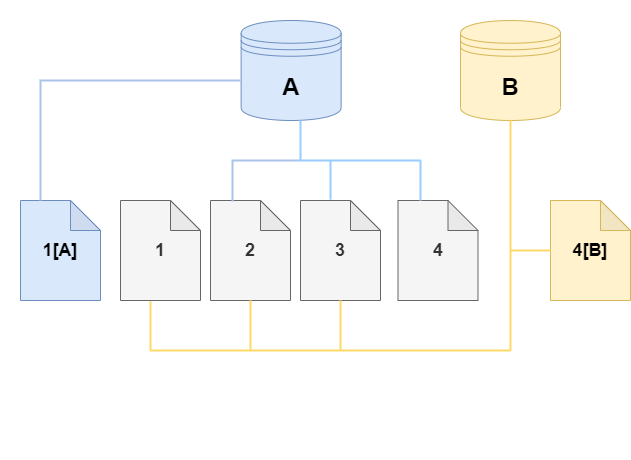
시간이 경과하여 소스 Aurora DB 클러스터 볼륨과 복제본 모두가 변경될 경우 변경 사항을 캡처하고 저장하기 위해 점점 더 많은 스토리지가 필요합니다.
원본 클러스터 볼륨 삭제
처음에 복제 볼륨은 복제가 생성된 원본 볼륨과 동일한 데이터 페이지를 공유합니다. 원본 볼륨이 존재하는 한 복제 볼륨은 복제본이 생성하거나 수정한 페이지의 소유자로만 간주됩니다. 따라서 복제 볼륨의 VolumeBytesUsed 지표는 작게 시작해서 데이터가 원본 클러스터와 복제본 간에 분산될 때만 커집니다. 소스 볼륨과 복제 간에 동일한 페이지가 있는 경우 스토리지 요금은 원본 클러스터에만 적용됩니다. VolumeBytesUsed 지표에 대한 자세한 내용은 Amazon Aurora에 대한 클러스터 수준 지표를 참고하세요.
하나 이상의 복제본이 연결된 소스 클러스터 볼륨을 삭제해도 복제본의 클러스터 볼륨에 있는 데이터는 변경되지 않습니다. Aurora는 이전에 소스 클러스터 볼륨이 소유하던 페이지를 보존합니다. Aurora는 삭제된 클러스터가 소유한 페이지에 대한 스토리지 요금을 재분배합니다. 예를 들어 원본 클러스터에 두 개의 복제본이 있었는데 원본 클러스터가 삭제되었다고 가정해 보겠습니다. 이제 원본 클러스터가 소유한 데이터 페이지 중 절반을 하나의 복제본이 소유하게 됩니다. 페이지의 나머지 절반은 다른 복제본이 소유하게 됩니다.
원본 클러스터를 삭제한 다음 복제본을 더 생성하거나 삭제하면 Aurora는 동일한 페이지를 공유하는 모든 복제본에 데이터 페이지의 소유권을 계속 재분배합니다. 따라서 복제본의 클러스터 볼륨에 따라 VolumeBytesUsed 지표 값이 변경되는 것을 확인할 수 있습니다. 더 많은 복제본이 생성되고 페이지 소유권이 더 많은 클러스터에 분산됨에 따라 지표 값이 감소할 수 있습니다. 복제본이 삭제되고 페이지 소유권이 더 적은 수의 클러스터에 할당됨에 따라 지표 값이 증가할 수도 있습니다. 쓰기 작업이 복제 볼륨의 데이터 페이지에 미치는 영향에 대한 자세한 내용은 기록 중 복사(copy-on-write) 이해 섹션을 참조하세요.
원본 클러스터와 복제본을 동일한 AWS 계정에서 소유한 경우 해당 클러스터에 대한 모든 스토리지 요금이 동일한 AWS 계정에 적용됩니다. 클러스터 중 일부가 크로스 계정 복제본인 경우 원본 클러스터를 삭제하면 크로스 계정 복제본을 소유한 AWS 계정에 추가 스토리지 요금이 부과될 수 있습니다.
예를 들어 복제본을 생성하기 전에 먼저 클러스터 볼륨에 1,000개의 사용된 데이터 페이지가 있다고 가정해 보겠습니다. 해당 클러스터를 복제하면 처음에는 복제 볼륨의 사용된 페이지가 0으로 나타납니다. 복제본이 100개의 데이터 페이지를 수정하면 해당 100페이지만 복제본 볼륨에 저장되고 사용된 것으로 표시됩니다. 상위 볼륨의 변경되지 않은 나머지 900개 페이지는 두 클러스터에서 모두 공유됩니다. 이 경우 상위 클러스터의 스토리지 요금은 1,000페이지, 복제본 볼륨은 100페이지에 대한 스토리지 요금이 부과됩니다.
소스 볼륨을 삭제하는 경우 복제본에 대한 스토리지 요금에는 변경된 100페이지와 원본 볼륨의 공유 페이지 900개(총 1,000페이지)가 포함됩니다.
Amazon Aurora 복제 생성
소스 Aurora DB 클러스터와 같은 AWS 계정에서 복제본을 생성합니다. 이를 위해 AWS Management Console 또는 AWS CLI 및 다음 절차를 사용할 수 있습니다.
다른 AWS 계정에서 복제본을 생성하거나 다른 AWS 계정과 복제본을 공유하도록 허용하려면 AWS RAM과 Amazon Aurora에서 교차 계정 복제의 절차를 사용합니다.
다음 프로시저에서는 AWS Management Console을 사용하여 Aurora DB 클러스터를 복제하는 방법에 대해 설명합니다.
AWS Management Console을 사용하여 복제본을 생성하면 하나의 Aurora DB 인스턴스가 있는 하나의 Aurora DB 클러스터가 생성됩니다.
이번 지침은 복제본을 생성하는 것과 동일한 AWS 계정에서 소유하고 있는 DB 클러스터에 적용됩니다. DB 클러스터를 다른 AWS 계정에서 소유하고 있다면 AWS RAM과 Amazon Aurora에서 교차 계정 복제 섹션을 참조하세요.
AWS을 사용해 AWS Management Console 계정에서 소유하는 DB 클러스터 복제본을 생성하려면
AWS Management Console에 로그인한 후 https://console.aws.amazon.com/rds/
에서 Amazon RDS 콘솔을 엽니다. 탐색 창에서 데이터베이스를 선택합니다.
목록에서 Aurora DB 클러스터를 선택하고 [작업(Actions)]에서 [복제본 생성(Create clone)]을 선택합니다.
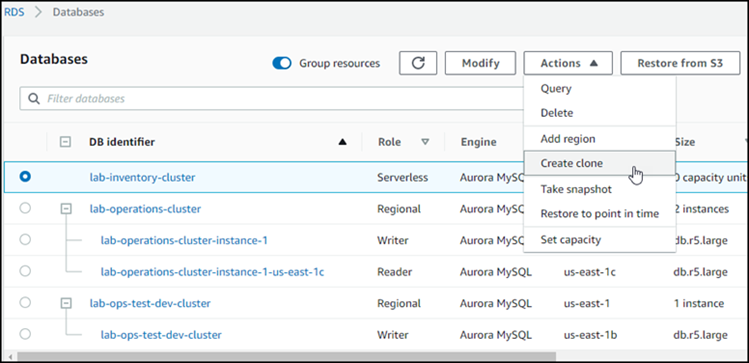
설정, 연결성 및 Aurora DB 클러스터 복제본에 대한 기타 옵션을 구성할 수 있는 복제본 생성 페이지가 열립니다.
-
DB 인스턴스 식별자에 복제된 Aurora DB 클러스터에 부여할 이름을 입력합니다.
Aurora Serverless v1 DB 클러스터의 경우 용량 유형에서 프로비저닝됨 또는 서버리스를 선택합니다.
소스 Aurora DB 클러스터가 Aurora Serverless v1 DB 클러스터이거나 암호화되고 프로비저닝된 Aurora DB 클러스터인 경우 [서버리스(Serverless)]를 선택합니다.
-
Aurora Serverless v2 또는 프로비저닝된 DB 클러스터의 경우 클러스터 스토리지 구성에서 Aurora I/O-Optimized 또는 Aurora Standard 중 하나를 선택합니다.
자세한 내용은 Amazon Aurora DB 클러스터의 스토리지 구성 단원을 참조하십시오.
-
DB 인스턴스 크기 또는 DB 클러스터 용량을 선택합니다.
-
프로비저닝된 복제본의 경우 DB 인스턴스 클래스를 선택합니다.
제공된 설정을 수락하거나 복제본에 다른 DB 인스턴스 클래스를 사용할 수 있습니다.
-
Aurora Serverless v1 또는 Aurora Serverless v2 복제본의 경우 용량 설정을 선택합니다.
제공된 설정을 수락하거나 복제본에 맞게 설정을 변경할 수 있습니다.
-
-
복제본에 필요에 따라 다른 설정을 선택하세요. Aurora DB 클러스터 및 인스턴스 설정에 대한 자세한 내용은 Amazon Aurora DB 클러스터 생성 섹션에서 참조하세요.
-
복제본 생성을 선택합니다.
복제본이 생성되면 복제본은 콘솔의 [데이터베이스(Databases)] 섹션에 다른 Aurora DB 클러스터와 함께 나열되고 현재 상태가 표시됩니다. 상태가 [사용 가능(Available)]이면 복제본을 사용할 준비가 된 것입니다.
AWS CLI를 사용하여 Aurora DB 클러스터를 복제하려면 클론 클러스터를 만들고 여기에 하나 이상의 DB 인스턴스를 추가하는 별도의 단계가 필요합니다.
restore-db-cluster-to-point-in-time AWS CLI 명령을 사용하면 원래 클러스터와 동일한 스토리지 데이터를 가진 Aurora DB 클러스터가 생성되지만 Aurora DB 인스턴스는 생성되지 않습니다. 클론이 사용 가능해지면 별도로 DB 인스턴스를 생성합니다. DB 인스턴스와 해당 인스턴스 클래스의 수를 선택하여 클론에 원래 클러스터보다 더 많거나 적은 컴퓨팅 파워를 제공할 수 있습니다. 프로세스의 단계는 다음과 같습니다.
-
restore-db-cluster-to-point-in-time CLI 명령을 사용하여 복제본을 생성합니다.
-
create-db-instance CLI 명령을 사용하여 클론에 대한 라이터 DB 인스턴스를 생성합니다.
-
(선택 사항) 추가 create-db-instance CLI 명령을 실행하여 하나 이상의 리더 인스턴스를 클론 클러스터에 추가합니다. 리더 인스턴스를 사용하면 클론의 고가용성 및 읽기 확장성 측면을 개선하는 데 도움이 됩니다. 개발 및 테스트용으로만 클론을 사용하려는 경우에는 이 단계를 건너뛰어도 됩니다.
복제본 생성
restore-db-cluster-to-point-in-time CLI 명령을 사용하여 초기 클론 클러스터를 생성합니다.
소스 Aurora DB 클러스터로부터 클론을 생성하는 방법
-
restore-db-cluster-to-point-in-timeCLI 명령을 사용합니다. 다음 파라미터의 값을 지정합니다. 이 일반적인 경우에는 클론이 원래 클러스터와 동일한 엔진 모드(프로비저닝된 모드 또는 Aurora Serverless v1)를 사용합니다.-
--db-cluster-identifier- 복제본에 대해 의미 있는 이름을 선택합니다. 복제본의 이름을 지정할 때 restore-db-cluster-to-point-in-time CLI 명령을 사용합니다. 그런 다음 create-db-instance CLI 명령에 복제본 이름을 전달합니다. -
--restore-type–copy-on-write을 사용하여 소스 DB 클러스터의 복제본을 생성합니다. 이 파라미터가 없으면restore-db-cluster-to-point-in-time은 복제본을 생성하는 대신 Aurora DB 클러스터를 복원합니다. -
--source-db-cluster-identifier- 복제할 소스 Aurora DB 클러스터의 이름을 사용합니다. -
--use-latest-restorable-time- 이 값은 소스 DB 클러스터에 대해 복원 가능한 최신 볼륨 데이터를 가리킵니다. 이를 사용하여 클론을 생성할 수 있습니다.
-
다음 예제에서는 my-source-cluster라는 이름의 클러스터에서 my-clone라는 이름의 복제본을 생성합니다.
대상 LinuxmacOS, 또는Unix:
aws rds restore-db-cluster-to-point-in-time \ --source-db-cluster-identifiermy-source-cluster\ --db-cluster-identifiermy-clone\ --restore-type copy-on-write \ --use-latest-restorable-time
Windows의 경우:
aws rds restore-db-cluster-to-point-in-time ^ --source-db-cluster-identifiermy-source-cluster^ --db-cluster-identifiermy-clone^ --restore-type copy-on-write ^ --use-latest-restorable-time
이 명령은 복제본의 세부 사항을 포함하는 JSON 객체를 반환합니다. 클론에 대한 DB 인스턴스를 생성하기 전에 복제된 DB 클러스터를 사용할 수 있는지 확인합니다. 자세한 내용은 상태 확인 및 복제본 세부 정보 가져오기 단원을 참조하십시오.
예를 들어 복제하고자 하는 tpch100g라는 이름의 클러스터가 있다고 가정합니다. 다음 Linux 예제는 tpch100g-clone이라는 복제된 클러스터, tpch100g-clone-instance라는 Aurora Serverless v2 라이터 인스턴스 및 새 클러스터를 위한 tpch100g-clone-instance-2라는 프로비저닝된 리더 인스턴스를 만듭니다.
--master-username 및 --master-user-password와 같은 일부 파라미터를 제공할 필요가 없습니다. Aurora는 원본 클러스터에서 파라미터를 자동으로 결정합니다. 사용할 DB 엔진을 지정해야 합니다. 따라서 이 예제는 새 클러스터를 테스트하여 --engine 파라미터에 사용할 올바른 값을 결정합니다.
이 예에는 클론 클러스터를 생성할 때의 --serverless-v2-scaling-configuration 옵션도 포함되어 있습니다. 이렇게 하면 원래 클러스터에서 Aurora Serverless v2를 사용하지 않았더라도 클론에 Aurora Serverless v2 인스턴스를 추가할 수 있습니다.
$aws rds restore-db-cluster-to-point-in-time \ --source-db-cluster-identifier tpch100g \ --db-cluster-identifier tpch100g-clone \ --serverless-v2-scaling-configuration MinCapacity=0.5,MaxCapacity=16\ --restore-type copy-on-write \ --use-latest-restorable-time$aws rds describe-db-clusters \ --db-cluster-identifier tpch100g-clone \ --query '*[].[Engine]' \ --output textaurora-mysql$aws rds create-db-instance \ --db-instance-identifier tpch100g-clone-instance \ --db-cluster-identifier tpch100g-clone \ --db-instance-class db.serverless \ --engine aurora-mysql$aws rds create-db-instance \ --db-instance-identifier tpch100g-clone-instance-2 \ --db-cluster-identifier tpch100g-clone \ --db-instance-class db.r6g.2xlarge \ --engine aurora-mysql
소스 Aurora DB 클러스터와 다른 엔진 모드를 사용하여 복제본을 생성하는 방법
-
이 절차는 Aurora Serverless v1을 지원하는 이전 엔진 버전에만 적용됩니다. Aurora Serverless v1 클러스터가 있고 프로비저닝된 클러스터인 클론을 생성하려고 한다고 가정해 보겠습니다. 이 경우
restore-db-cluster-to-point-in-timeCLI 명령을 사용하여 이전 예제와 유사한 파라미터 값과 함께 다음 추가 파라미터를 지정합니다.-
--engine-mode- 소스 Aurora DB 클러스터와 다른 엔진 모드를 사용하는 클론을 생성하는 경우에만 이 파라미터를 사용합니다. 이 파라미터는 Aurora Serverless v1을 지원하는 이전 엔진 버전에만 적용됩니다. 다음과 같이--engine-mode를 사용하여 전달할 값을 선택합니다.-
--engine-mode provisioned을 사용하여 Aurora Serverless DB 클러스터에서 프로비저닝된 Aurora DB 클러스터 복제본을 생성합니다.참고
Aurora Serverless v1에서 복제된 클러스터와 함께 Aurora Serverless v2를 사용하려는 경우에도 클론의 엔진 모드를
provisioned로 지정해야 합니다. 그런 다음 이후에 추가 업그레이드 및 마이그레이션 단계를 수행합니다. -
--engine-mode serverless를 사용하여 프로비저닝된 Aurora DB 클러스터에서 Aurora Serverless v1 클론을 생성합니다.serverless엔진 모드를 지정할 때--scaling-configuration을 선택할 수도 있습니다.
-
-
--scaling-configuration- (선택 사항)--engine-mode serverless를 사용하여 Aurora Serverless v1 복제본의 최소 및 최대 용량을 구성합니다. 이 파라미터를 사용하지 않는 경우 Aurora가 DB 엔진의 기본 Aurora Serverless v1 용량 값을 사용하여 Aurora Serverless v1 클론을 생성합니다.
-
다음 예제에서는 my-source-cluster라는 이름의 Aurora Serverless v1 DB 클러스터에서 my-clone이라는 이름의 프로비저닝된 클론을 생성합니다.
대상 LinuxmacOS, 또는Unix:
aws rds restore-db-cluster-to-point-in-time \ --source-db-cluster-identifiermy-source-cluster\ --db-cluster-identifiermy-clone\ --engine-mode provisioned \ --restore-type copy-on-write \ --use-latest-restorable-time
Windows의 경우:
aws rds restore-db-cluster-to-point-in-time ^ --source-db-cluster-identifiermy-source-cluster^ --db-cluster-identifiermy-clone^ --engine-mode provisioned ^ --restore-type copy-on-write ^ --use-latest-restorable-time
이 명령은 DB 인스턴스를 생성하는 데 필요한 복제본의 세부 정보가 포함된 JSON 객체를 반환합니다. 복제본 상태(빈 Aurora DB 클러스터)가 사용 가능(Available) 상태가 될 때까지는 작업을 수행할 수 있습니다.
참고
restore-db-cluster-to-point-in-time AWS CLI 명령은 해당 DB 클러스터의 DB 인스턴스가 아닌 DB 클러스터만 복원합니다. 복원된 DB 클러스터에 대한 DB 인스턴스를 생성하려면 create-db-instance 명령을 실행합니다. 해당 명령으로 복원된 DB 클러스터의 식별자를 --db-cluster-identifier 파라미터로 지정합니다. restore-db-cluster-to-point-in-time 명령이 완료되고 DB 클러스터를 사용 가능할 때만 DB 인스턴스를 생성할 수 있습니다.
Aurora Serverless v1 클러스터로 시작해서 Aurora Serverless v2 클러스터로 마이그레이션하려고 한다고 가정해 보겠습니다. 마이그레이션의 초기 단계로 Aurora Serverless v1 클러스터의 프로비저닝된 클론을 생성합니다. 필요한 버전 업그레이드를 포함한 전체 절차는 Aurora Serverless v1 클러스터에서 Aurora Serverless v2로 업그레이드 단원을 참조하세요.
상태 확인 및 복제본 세부 정보 가져오기
다음 명령을 사용하여 새로 생성된 클론 클러스터의 상태를 확인할 수 있습니다.
$aws rds describe-db-clusters --db-cluster-identifiermy-clone--query '*[].[Status]' --output text
또는 다음 AWS CLI 쿼리를 사용하여 복제본에 대한 DB 인스턴스를 생성하는 데 필요한 다른 값 및 상태를 가져올 수 있습니다.
대상 LinuxmacOS, 또는Unix:
aws rds describe-db-clusters --db-cluster-identifiermy-clone\ --query '*[].{Status:Status,Engine:Engine,EngineVersion:EngineVersion,EngineMode:EngineMode}'
Windows의 경우:
aws rds describe-db-clusters --db-cluster-identifiermy-clone^ --query "*[].{Status:Status,Engine:Engine,EngineVersion:EngineVersion,EngineMode:EngineMode}"
이 쿼리는 다음과 비슷한 출력을 반환합니다.
[ { "Status": "available", "Engine": "aurora-mysql", "EngineVersion": "8.0.mysql_aurora.3.04.1", "EngineMode": "provisioned" } ]
복제본에 대한 Aurora DB 인스턴스 생성
create-db-instance CLI 명령을 사용하여 Aurora Serverless v2 또는 프로비저닝된 복제본에 대한 DB 인스턴스를 생성합니다. Aurora Serverless v1 클론을 위한 DB 인스턴스는 만들지 않습니다.
DB 인스턴스는 소스 DB 클러스터에서 --master-username 및 --master-user-password 속성을 상속합니다.
다음은 프로비저닝된 복제본에 대한 DB 인스턴스를 생성하는 예제입니다.
대상 LinuxmacOS, 또는Unix:
aws rds create-db-instance \ --db-instance-identifiermy-new-db\ --db-cluster-identifiermy-clone\ --db-instance-classdb.r6g.2xlarge\ --engine aurora-mysql
Windows의 경우:
aws rds create-db-instance ^ --db-instance-identifiermy-new-db^ --db-cluster-identifiermy-clone^ --db-instance-classdb.r6g.2xlarge^ --engine aurora-mysql
다음 예제에서는 Aurora Serverless v2를 지원하는 엔진 버전을 사용하는 클론을 위해 Aurora Serverless v2 DB 인스턴스를 만듭니다.
대상 LinuxmacOS, 또는Unix:
aws rds create-db-instance \ --db-instance-identifiermy-new-db\ --db-cluster-identifiermy-clone\ --db-instance-class db.serverless \ --engine aurora-postgresql
Windows의 경우:
aws rds create-db-instance ^ --db-instance-identifiermy-new-db^ --db-cluster-identifiermy-clone^ --db-instance-class db.serverless ^ --engine aurora-mysql
복제본에 사용할 파라미터
다음 표에는 restore-db-cluster-to-point-in-time에서 Aurora DB 클러스터를 복제하는 데 사용되는 다양한 파라미터가 요약되어 있습니다.
| 파라미터 | 설명 |
|---|---|
|
|
복제할 소스 Aurora DB 클러스터의 이름을 사용합니다. |
|
|
|
|
|
|
|
|
이 값은 소스 DB 클러스터에 대해 복원 가능한 최신 볼륨 데이터를 가리킵니다. 이를 사용하여 클론을 생성할 수 있습니다. |
|
|
(Aurora Serverless v2를 지원하는 최신 버전) 이 파라미터를 사용하여 Aurora Serverless v2 클론의 최소 및 최대 용량을 구성합니다. 이 파라미터를 지정하지 않으면 클러스터를 수정하여 이 속성을 추가하기 전까지는 클론 클러스터에 Aurora Serverless v2 인스턴스를 만들 수 없습니다. |
|
|
(Aurora Serverless v1만 지원하는 이전 버전) 이 파라미터를 사용하여 소스 Aurora DB 클러스터와 다른 유형의 클론을 생성합니다. 클론에는 다음 값 중 하나가 포함되어야 합니다.
|
|
|
(Aurora Serverless v1만 지원하는 이전 버전) 이 파라미터를 사용하여 Aurora Serverless v1 클론의 최소 및 최대 용량을 구성합니다. 이 파라미터를 지정하지 않는 경우 Aurora가 DB 엔진의 기본 용량 값을 사용하여 복제본을 생성합니다. |
VPC 간 및 계정 간 복제에 대한 자세한 내용은 다음 섹션을 참조하세요.
