Amazon CloudWatch 지표를 사용한 Aurora PostgreSQL의 리소스 사용량 분석
Aurora는 1분 단위로 CloudWatch에 지표 데이터를 자동 전송합니다. CloudWatch 지표를 사용하여 Aurora PostgreSQL의 리소스 사용량을 분석할 수 있습니다. 지표를 사용하여 네트워크 처리량(throughput)과 네트워크 사용량을 평가할 수 있습니다.
CloudWatch를 사용한 네트워크 처리량(throughput) 평가
시스템 사용량이 인스턴스 유형의 리소스 한도에 가까워지면 처리 속도가 느려질 수 있습니다. CloudWatch Logs Insights를 사용하여 스토리지 리소스 사용량을 모니터링하고 사용할 수 있는 리소스가 충분한지 확인할 수 있습니다. 필요한 경우 DB 인스턴스를 더 큰 인스턴스 클래스로 수정할 수 있습니다.
다음과 같은 이유로 Aurora 스토리지 처리 속도가 느릴 수 있습니다.
-
클라이언트와 DB 인스턴스 간의 네트워크 대역폭이 부족합니다.
-
스토리지 하위 시스템에 대한 네트워크 대역폭이 부족합니다.
-
인스턴스 유형에 비해 규모가 큰 워크로드입니다.
CloudWatch Logs Insights를 쿼리하여 Aurora 스토리지 리소스 사용량 그래프를 생성하여 리소스를 모니터링할 수 있습니다. 그래프는 더 큰 인스턴스 크기로 스케일 업할지를 결정하는 데 도움이 되는 CPU 사용률 및 지표를 보여줍니다. CloudWatch Logs Insights의 쿼리 구문에 대한 자세한 내용은 CloudWatch Logs Insights query syntax(CloudWatch Logs Insights 쿼리 구문)를 참조하세요.
CloudWatch를 사용하려면 Aurora PostgreSQL 로그 파일을 CloudWatch로 내보내야 합니다. CloudWatch로 로그를 내보내도록 기존 클러스터를 수정할 수도 있습니다. CloudWatch로 로그를 내보내는 방법에 대한 자세한 내용은 Amazon CloudWatch로 로그를 게시하는 옵션 설정을 참조하세요.
CloudWatch Logs Insights를 쿼리하려면 DB 인스턴스의 Resource ID(리소스 ID)가 필요합니다. Resource ID(리소스 ID)는 콘솔의 Configuration(구성) 탭에서 확인할 수 있습니다.

로그 파일에서 리소스 스토리지 지표를 쿼리하려면 다음을 수행하세요.
https://console.aws.amazon.com/cloudwatch/
에서 CloudWatch 콘솔을 엽니다. CloudWatch 개요 홈페이지가 표시됩니다.
-
필요한 경우 AWS 리전을 변경합니다. 탐색 모음에서 AWS가 있는 AWS 리전을 선택합니다. 자세한 내용은 리전 및 엔드포인트 섹션을 참조하세요.
-
탐색 창에서 Logs(로그)를 선택한 다음, Logs Insights를 선택합니다.
Logs Insights 페이지가 나타납니다.
-
드롭다운 목록에서 분석할 로그 파일을 선택합니다.
-
필드에 다음 쿼리를 입력하고
<resource ID>를 DB 클러스터의 리소스 ID로 바꿉니다.filter @logStream = <resource ID> | parse @message "\"Aurora Storage Daemon\"*memoryUsedPc\":*,\"cpuUsedPc\":*," as a,memoryUsedPc,cpuUsedPc | display memoryUsedPc,cpuUsedPc #| stats avg(xcpu) as avgCpu by bin(5m) | limit 10000 -
Run query(쿼리 실행)를 클릭합니다.
스토리지 사용률 그래프가 표시됩니다.
다음 이미지는 Logs Insights 페이지와 그래프를 나타냅니다.
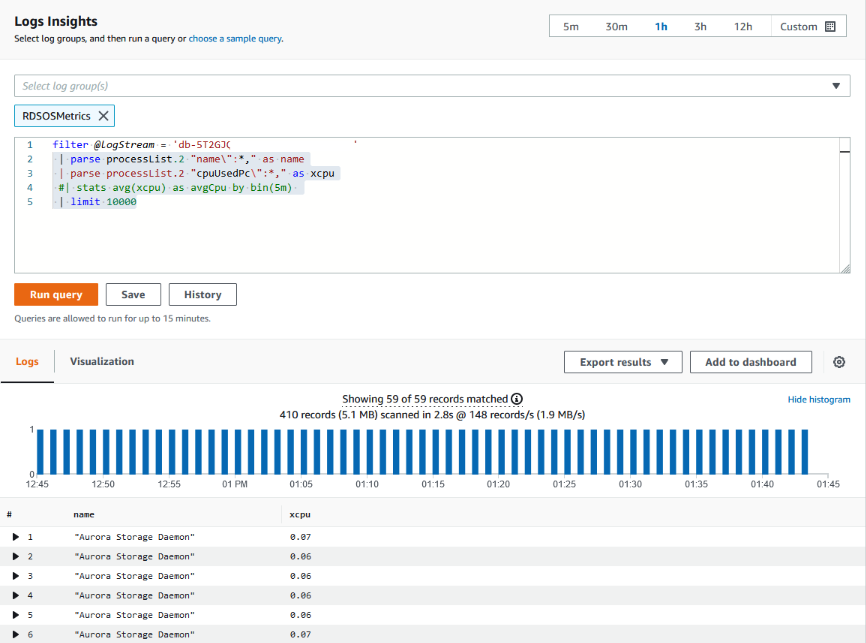
CloudWatch 지표를 사용한 Aurora PostgreSQL에 대한 DB 인스턴스 사용량 평가
CloudWatch 지표를 사용하여 인스턴스 처리량(throughput)을 관찰하고 인스턴스 클래스가 애플리케이션에 제공하는 리소스가 충분한지 확인할 수 있습니다. DB 인스턴스 클래스 한도에 대한 자세한 내용은 Aurora에 대한 DB 인스턴스 클래스의 하드웨어 사양에서 DB 인스턴스 클래스의 사양을 찾아 네트워크 성능을 확인하세요.
DB 인스턴스 사용량이 인스턴스 클래스 한도에 가까워지면 성능이 느려질 수 있습니다. CloudWatch 지표를 통해 이러한 상황을 확인할 수 있으므로 더 큰 인스턴스 클래스로 수동 스케일 업할 계획을 세울 수 있습니다.
다음 CloudWatch 지표 값을 조합하여 인스턴스 클래스 한도에 가까워졌는지 확인하세요.
-
NetworkThroughput – Aurora DB 클러스터의 각 인스턴스에 대해 클라이언트가 수신 및 전송한 네트워크 처리량(throughput)입니다. 이 처리량(throughput) 값에서 DB 클러스터의 인스턴스와 클러스터 볼륨 간 네트워크 트래픽은 제외됩니다.
-
StorageNetworkThroughput – Aurora DB 클러스터의 각 인스턴스에서 Aurora 스토리지 하위 시스템으로 수신 및 전송한 네트워크 처리량(throughput)입니다.
NetworkThroughput을 StorageNetworkThroughput에 추가하여 Aurora DB 클러스터의 각 인스턴스가 Aurora 스토리지 하위 시스템에서 수신 및 전송한 네트워크 처리량(throughput)을 확인하세요. 인스턴스에 대한 인스턴스 클래스 한도는 이 두 지표를 합한 값보다 커야 합니다.
다음 지표를 사용하여 전송 및 수신 시 클라이언트 애플리케이션의 네트워크 트래픽에 대한 추가 세부 정보를 검토할 수 있습니다.
-
NetworkReceiveThroughput – Aurora PostgreSQL DB 클러스터의 각 인스턴스가 클라이언트로부터 수신한 네트워크 처리량(throughput)입니다. 이 처리량에서 DB 클러스터의 인스턴스와 클러스터 볼륨 간 네트워크 트래픽은 제외됩니다.
-
NetworkTransmitThroughput – Aurora DB 클러스터의 각 인스턴스가 클라이언트로 전송한 네트워크 처리량(throughput)입니다. 이 처리량에서 DB 클러스터의 인스턴스와 클러스터 볼륨 간 네트워크 트래픽은 제외됩니다.
-
StorageNetworkReceiveThroughput – DB 클러스터의 각 인스턴스가 Aurora 스토리지 하위 시스템에서 수신한 네트워크 처리량(throughput)입니다.
-
StorageNetworkTransmitThroughput – DB 클러스터의 각 인스턴스가 Aurora 스토리지 하위 시스템으로 전송한 네트워크 처리량(throughput)입니다.
이러한 지표를 모두 더해 네트워크 사용량을 인스턴스 클래스 한도와 비교하는 방법을 평가합니다. 인스턴스 클래스 한도는 이러한 결합 지표를 합한 값보다 커야 합니다.
스토리지의 네트워크 한도와 CPU 사용률은 상호적인 관계가 있습니다. 네트워크 처리량(throughput)이 증가하면 CPU 사용률도 증가합니다. CPU 및 네트워크 사용량을 모니터링하면 리소스가 소진되는 방식 및 이유에 대한 정보를 얻을 수 있습니다.
네트워크 사용을 최소화하려면 다음을 고려하면 됩니다.
-
규모가 더 큰 인스턴스 클래스를 사용합니다.
-
pg_partman파티셔닝 전략을 사용합니다. -
쓰기 요청을 일괄적으로 나누어 전체 트랜잭션을 줄입니다.
-
읽기 전용 워크로드를 읽기 전용 인스턴스로 지정합니다.
-
사용하지 않는 인덱스를 삭제합니다.
-
부풀려진 객체 및 VACUUM이 있는지 확인합니다. 팽창이 심한 경우에는 PostgreSQL 확장
pg_repack을 사용합니다.pg_repack에 대한 자세한 내용은 Reorganize tables in PostgreSQL databases with minimal locks(최소 잠금으로 PostgreSQL 데이터베이스의 테이블 재구성)를 참조하세요.
