Amazon Aurora Global Database 모니터링
Aurora Global Database를 구성하는 Aurora DB 클러스터를 생성할 때 DB 클러스터의 성능을 모니터링할 수 있는 다양한 옵션을 선택할 수 있습니다. 옵션에는 다음이 포함됩니다.
Amazon RDS 성능 인사이트 – 기본 Aurora 데이터베이스 엔진에서 성능 스키마를 활성화합니다. 성능 인사이트 및 Aurora Global Database에 대한 자세한 내용은 Amazon RDS 성능 인사이트를 사용하여 Amazon Aurora Global Database 모니터링 단원을 참조하십시오.
향상된 모니터링 – CPU의 프로세스 또는 스레드 사용률에 대한 메트릭을 생성합니다. 향상된 모니터링에 대한 자세한 내용은 Enhanced Monitoring을 사용하여 OS 지표 모니터링 섹을 참조하세요.
Amazon CloudWatch Logs – 지정된 로그 유형을 CloudWatch Logs 에 게시합니다. 오류 로그는 기본적으로 게시되지만 Aurora 데이터베이스 엔진과 관련된 다른 로그를 선택할 수 있습니다.
Aurora MySQL–기반 Aurora DB 클러스터의 경우 감사 로그, 일반 로그 및 느린 쿼리 로그를 내보낼 수 있습니다.
Aurora PostgreSQL 기반 Aurora DB 클러스터의 경우 PostgreSQL 로그를 내보낼 수 있습니다.
Aurora MySQL 기반 글로벌 데이터베이스의 경우 특정
information_schema테이블을 쿼리하여 Aurora Global Database 및 해당 인스턴스의 상태를 확인할 수 있습니다. 자세한 방법은 Aurora MySQL 기반 글로벌 데이터베이스 모니터링을 참조하세요.Aurora PostgreSQL–기반 글로벌 데이터베이스의 경우 특정 함수를 사용하여 Aurora Global Database 및 해당 인스턴스의 상태를 확인할 수 있습니다. 자세한 방법은 Aurora PostgreSQL 기반 글로벌 데이터베이스 모니터링 단원을 참조하십시오.
다음 스크린샷은 Aurora Global Database에 있는 기본 Aurora DB 클러스터의 모니터링 탭에서 사용할 수 있는 몇 가지 옵션을 보여 줍니다.
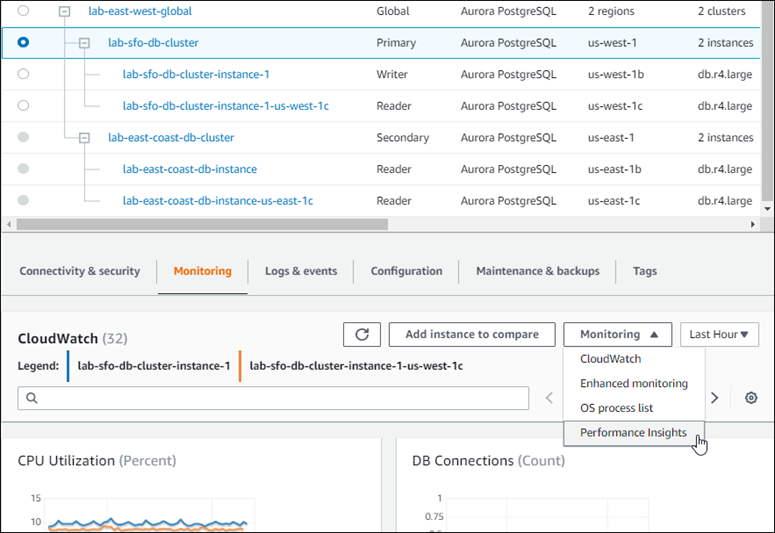
자세한 내용은 Amazon Aurora 클러스터에서 지표 모니터링 단원을 참조하십시오.
Amazon RDS 성능 인사이트를 사용하여 Amazon Aurora Global Database 모니터링
Amazon RDS 성능 개선 도우미와 Aurora Global Database를 함께 사용할 수 있습니다. Aurora Global Database의 각 Aurora DB 클러스터에 대해 이 기능을 개별적으로 활성화할 수 있습니다. 이렇게 하려면 데이터베이스 생성 페이지의 추가 구성 섹션에서 성능 인사이트 사용을 선택합니다. 또는 Aurora DB 클러스터를 실행하여 실행한 후 이 기능을 사용하도록 수정할 수 있습니다. Aurora Global Database의 일부인 각 클러스터에 대해 성능 개선 도우미를 활성화하거나 비활성화할 수 있습니다.
성능 통찰력에서 만든 보고서는 글로벌 데이터베이스의 각 클러스터에 적용됩니다. 이미 성능 개선 도우미를 사용하고 있는 Aurora Global Database에 새로운 보조 AWS 리전을 추가하려면 새로 추가된 클러스터에서 성능 개선 도우미를 활성화해야 합니다. 기존 글로벌 데이터베이스에서 성능 개선 도우미 설정을 상속하지는 않습니다.
글로벌 데이터베이스에 연결된 DB 인스턴스에 대한 성능 개선 도우미 페이지를 보면서 AWS 리전를 전환할 수 있습니다. 그러나 AWS 리전를 전환한 직후에는 성능 정보를 보지 못할 수 있습니다. DB 인스턴스는 각 AWS 리전에서 이름이 동일할 수 있지만 연결된 성능 개선 도우미 URL은 DB 인스턴스마다 다릅니다. AWS 리전를 전환한 후에 성능 개선 도우미 탐색 창에서 DB 인스턴스의 이름을 다시 선택하세요.
글로벌 데이터베이스와 연결된 DB 인스턴스의 경우, 성능에 영향을 미치는 요인은 AWS 리전에 따라 다를 수 있습니다. 예를 들어 각 AWS 리전의 DB 인스턴스는 용량이 서로 다를 수 있습니다.
성능 인사이트 사용에 대한 자세한 내용은 성능 개선 도우미를 통한 Amazon Aurora 모니터링 단원을 참조하십시오.
데이터베이스 활동 스트림을 사용하여 Aurora Global Database 모니터링
데이터베이스 활동 스트림을 사용하면 글로벌 데이터베이스의 DB 클러러스터에서 감사 활동에 대한 경보를 모니터링하고 설정할 수 있습니다. 데이터베이스 활동 스트림을 각 DB 클러스터에서 개별적으로 시작합니다. 각 클러스터는 자체 AWS 리전 내의 자체 Kinesis 스트림에 감사 데이터를 제공합니다. 자세한 내용은 데이터베이스 활동 스트림을 사용하여 Amazon Aurora 모니터링 단원을 참조하십시오.
Aurora MySQL 기반 글로벌 데이터베이스 모니터링
Aurora MySQL 기반 글로벌 데이터베이스의 상태를 보려면 information_schema.aurora_global_db_status 및 information_schema.aurora_global_db_instance_status 테이블을 쿼리합니다.
참고
information_schema.aurora_global_db_status 및 information_schema.aurora_global_db_instance_status 테이블은 Aurora MySQL 버전 3.04.0 이상의 글로벌 데이터베이스에서만 사용할 수 있습니다.
Aurora MySQL 기반 글로벌 데이터베이스를 모니터하는 방법
-
MySQL 클라이언트를 사용하여 글로벌 데이터베이스 기본 클러스터 엔드포인트에 연결합니다. 연결 방법에 대한 자세한 내용은 Amazon Aurora Global Database에 연결 단원을 참조하십시오.
-
mysql 명령의
information_schema.aurora_global_db_status테이블을 쿼리하여 기본 볼륨과 보조 볼륨을 나열합니다. 이 쿼리는 다음 예와 같이 글로벌 데이터베이스 보조 DB 클러스터의 지연 시간을 반환합니다.mysql> select * from information_schema.aurora_global_db_status;AWS_REGION | HIGHEST_LSN_WRITTEN | DURABILITY_LAG_IN_MILLISECONDS | RPO_LAG_IN_MILLISECONDS | LAST_LAG_CALCULATION_TIMESTAMP | OLDEST_READ_VIEW_TRX_ID -----------+---------------------+--------------------------------+------------------------+---------------------------------+------------------------ us-east-1 | 183537946 | 0 | 0 | 1970-01-01 00:00:00.000000 | 0 us-west-2 | 183537944 | 428 | 0 | 2023-02-18 01:26:41.925000 | 20806982 (2 rows)출력에는 다음 열이 포함된 글로벌 데이터베이스의 각 DB 클러스터에 대한 행이 포함됩니다.
-
AWS_REGION – 이 DB 클러스터가 속한 AWS 리전입니다. 엔진별 AWS 리전을 나열한 테이블은 리전 가용성 섹션을 참조하세요.
-
HIGHEST_LSN_WRITTEN – 이 DB 클러스터에 현재 작성된 가장 높은 로그 시퀀스 번호(LSN)입니다.
LSN(로그 시퀀스 번호)은 데이터베이스 트랜잭션 로그의 레코드를 식별하는 고유한 순차적 번호입니다. LSN은 더 큰 LSN이 더 이후의 트랜잭션을 나타내도록 정렬됩니다.
-
DURABILITY_LAG_IN_MILLISECONDS - 보조 DB 클러스터의
HIGHEST_LSN_WRITTEN과 기본 DB 클러스터의HIGHEST_LSN_WRITTEN간 타임스탬프 값 차이입니다. 이 값은 Aurora Global Database의 기본 DB 클러스터에서 항상 0입니다. -
RPO_LAG_IN_MILLISECONDS – Recovery Point Objective(RPO) 지연 시간입니다. RPO 지연은 Aurora Global Databse의 기본 DB 클러스터에 저장된 후 가장 최근의 사용자 트랜잭션 COMMIT 보조 DB 클러스터에 저장하는 데 걸리는 시간입니다. 이 값은 Aurora Global Database의 기본 DB 클러스터에서 항상 0입니다.
간단히 말해서 이 지표는 Aurora Global Database의 각 Aurora MySQL DB 클러스터에 대한 복구 시점 목표, 즉 중단 시 손실될 수 있는 데이터의 양을 계산합니다. 지연과 마찬가지로 RPO는 시간 단위로 측정됩니다.
-
LAST_LAG_CALCULATION_TIMESTAMP –
DURABILITY_LAG_IN_MILLISECONDS및RPO_LAG_IN_MILLISECONDS에 대한 값이 마지막으로 계산된 시점을 나타내는 타임스탬프입니다. 시간 값(예:1970-01-01 00:00:00+00)은 이것이 기본 DB 클러스터임을 의미합니다. -
OLDEST_READ_VIEW_TRX_ID - 라이터 DB 인스턴스가 삭제할 수 있는 가장 오래된 트랜잭션의 ID입니다.
-
-
information_schema.aurora_global_db_instance_status테이블을 쿼리하여 기본 DB 클러스터와 보조 DB 클러스터 모두에 대한 모든 보조 DB 인스턴스를 나열합니다.mysql> select * from information_schema.aurora_global_db_instance_status;SERVER_ID | SESSION_ID | AWS_REGION | DURABLE_LSN | HIGHEST_LSN_RECEIVED | OLDEST_READ_VIEW_TRX_ID | OLDEST_READ_VIEW_LSN | VISIBILITY_LAG_IN_MSEC ---------------------+--------------------------------------+------------+-------------+----------------------+-------------------------+----------------------+------------------------ ams-gdb-primary-i2 | MASTER_SESSION_ID | us-east-1 | 183537698 | 0 | 0 | 0 | 0 ams-gdb-secondary-i1 | cc43165b-bdc6-4651-abbf-4f74f08bf931 | us-west-2 | 183537689 | 183537692 | 20806928 | 183537682 | 0 ams-gdb-secondary-i2 | 53303ff0-70b5-411f-bc86-28d7a53f8c19 | us-west-2 | 183537689 | 183537692 | 20806928 | 183537682 | 677 ams-gdb-primary-i1 | 5af1e20f-43db-421f-9f0d-2b92774c7d02 | us-east-1 | 183537697 | 183537698 | 20806930 | 183537691 | 21 (4 rows)출력에는 다음 열이 포함된 글로벌 데이터베이스의 각 DB 인스턴스에 대한 행이 포함됩니다.
-
SERVER_ID – DB 인스턴스의 서버 식별자입니다.
-
SESSION_ID – 현재 세션의 고유 식별자입니다.
MASTER_SESSION_ID의 값은 Writer(프라이머리) DB 인스턴스를 식별합니다. -
AWS_REGION - 이 DB 인스턴스가 속한 AWS 리전입니다. 엔진별 AWS 리전을 나열한 테이블은 리전 가용성 섹션을 참조하세요.
-
DURABLE_LSN – 스토리지에서 뛰어난 내구성을 갖게 된 LSN입니다.
-
HIGHEST_LSN_RECEIVED – 라이터 DB 인스턴스에서 DB 인스턴스가 수신한 가장 높은 LSN입니다.
-
OLDEST_READ_VIEW_TRX_ID - 라이터 DB 인스턴스가 삭제할 수 있는 가장 오래된 트랜잭션의 ID입니다.
-
OLDEST_READ_VIEW_LSN – DB 인스턴스가 스토리지에서 읽는 데 사용하는 가장 오래된 LSN입니다.
-
VISIBILITY_LAG_IN_MSEC - 기본 DB 클러스터의 리더의 경우 이 DB 인스턴스가 라이터 DB 인스턴스보다 얼마나 뒤처지는지 밀리초 단위로 나타낸 것입니다. 보조 DB 클러스터의 리더의 경우 이 DB 인스턴스가 보조 볼륨보다 얼마나 뒤처지는지 밀리초 단위로 나타낸 것입니다.
-
이러한 값이 시간에 따라 어떻게 바뀌는지 확인하려면 테이블 삽입에 한 시간이 걸리는 다음 트랜잭션 블록을 살펴보십시오.
mysql> BEGIN;
mysql> INSERT INTO table1 SELECT Large_Data_That_Takes_1_Hr_To_Insert;
mysql> COMMIT;
경우에 따라 BEGIN 문 이후 기본 DB 클러스터와 보조 DB 클러스터 사이에 네트워크 연결 끊김이 발생할 수 있습니다. 그렇다면 보조 DB 클러스터의 DURABILITY_LAG_IN_MILLISECONDS 값이 증가하기 시작합니다. INSERT 명령문 마지막에 DURABILITY_LAG_IN_MILLISECONDS의 값이 1시간입니다. 하지만 기본 DB 클러스터와 보조 DB 클러스터 간에 커밋된 모든 사용자 데이터가 여전히 동일하기 때문에 RPO_LAG_IN_MILLISECONDS 값은 0입니다. COMMIT 명령문이 완료되는 즉시 RPO_LAG_IN_MILLISECONDS 값이 증가합니다.
Aurora PostgreSQL 기반 글로벌 데이터베이스 모니터링
Aurora PostgreSQL 기반 글로벌 데이터베이스의 상태를 보려면 aurora_global_db_status 및 aurora_global_db_instance_status 함수를 사용합니다.
참고
Aurora PostgreSQL만 aurora_global_db_status 및 aurora_global_db_instance_status 함수를 지원합니다.
Aurora PostgreSQL기반 글로벌 데이터베이스를 모니터하는 방법
-
psql과 같은 PostgreSQL 유틸리티를 사용하여 글로벌 데이터베이스 기본 클러스터 엔드포인트에 연결합니다. 연결 방법에 대한 자세한 내용은 Amazon Aurora Global Database에 연결 단원을 참조하십시오.
-
psql 명령의
aurora_global_db_status함수를 사용하여 기본 볼륨과 보조 볼륨을 나열합니다. 이는 글로벌 데이터베이스 보조 DB 클러스터의 지연 시간을 보여 줍니다.postgres=> select * from aurora_global_db_status();aws_region | highest_lsn_written | durability_lag_in_msec | rpo_lag_in_msec | last_lag_calculation_time | feedback_epoch | feedback_xmin ------------+---------------------+------------------------+-----------------+----------------------------+----------------+--------------- us-east-1 | 93763984222 | -1 | -1 | 1970-01-01 00:00:00+00 | 0 | 0 us-west-2 | 93763984222 | 900 | 1090 | 2020-05-12 22:49:14.328+00 | 2 | 3315479243 (2 rows)출력에는 다음 열이 포함된 글로벌 데이터베이스의 각 DB 클러스터에 대한 행이 포함됩니다.
-
aws_region - 이 DB 클러스터가 있는 AWS 리전입니다. 엔진별 AWS 리전을 나열한 테이블은 리전 가용성 섹션을 참조하세요.
-
highest_lsn_written – 이 DB 클러스터에 현재 작성된 가장 높은 로그 시퀀스 번호(LSN)입니다.
LSN(로그 시퀀스 번호)은 데이터베이스 트랜잭션 로그의 레코드를 식별하는 고유한 순차적 번호입니다. LSN은 더 큰 LSN이 더 이후의 트랜잭션을 나타내도록 정렬됩니다.
-
durability_lag_in_msec – 보조 DB 클러스터에 작성된 가장 높은 로그 시퀀스 번호(
highest_lsn_written)와 기본 DB 클러스터의highest_lsn_written간의 타임스탬프 차이입니다. -
rpo_lag_in_msec – 복구 시점 목표(RPO) 지연 시간입니다. 이 지연 시간은 보조 DB 클러스터에 저장된 가장 최근의 사용자 트랜잭션 커밋과 기본 DB 클러스터에 저장된 가장 최근의 사용자 트랜잭션 커밋 간의 시간 차이입니다.
-
last_lag_calculation_time –
durability_lag_in_msec및rpo_lag_in_msec에 대한 값이 마지막으로 계산된 타임스탬프입니다. -
feedback_epoch – 보조 DB 클러스터가 상시 대기 방식 정보를 생성할 때 사용하는 epoch입니다.
핫 스탠바이는 서버가 복구 또는 대기 모드에 있는 동안 DB 클러스터가 연결하고 쿼리할 수 있는 때입니다. 핫 스탠바이 피드백은 핫 스탠바이 상태일 때 DB 클러스터에 대한 정보입니다. 자세한 내용은 PostgreSQL 설명서의 핫 스탠바이
를 참조하십시오. -
feedback_xmin – 보조 DB 클러스터가 사용하는 최소(가장 오래된) 활성 트랜잭션 ID입니다.
-
-
aurora_global_db_instance_status함수를 사용하여 기본 DB 클러스터와 보조 DB 클러스터 모두에 대한 모든 보조 DB 인스턴스를 나열합니다.postgres=> select * from aurora_global_db_instance_status();server_id | session_id | aws_region | durable_lsn | highest_lsn_rcvd | feedback_epoch | feedback_xmin | oldest_read_view_lsn | visibility_lag_in_msec --------------------------------------------+--------------------------------------+------------+-------------+------------------+----------------+---------------+----------------------+------------------------ apg-global-db-rpo-mammothrw-elephantro-1-n1 | MASTER_SESSION_ID | us-east-1 | 93763985102 | | | | | apg-global-db-rpo-mammothrw-elephantro-1-n2 | f38430cf-6576-479a-b296-dc06b1b1964a | us-east-1 | 93763985099 | 93763985102 | 2 | 3315479243 | 93763985095 | 10 apg-global-db-rpo-elephantro-mammothrw-n1 | 0d9f1d98-04ad-4aa4-8fdd-e08674cbbbfe | us-west-2 | 93763985095 | 93763985099 | 2 | 3315479243 | 93763985089 | 1017 (3 rows)출력에는 다음 열이 포함된 글로벌 데이터베이스의 각 DB 인스턴스에 대한 행이 포함됩니다.
-
server_id – DB 인스턴스의 서버 식별자입니다.
-
session_id – 현재 세션의 고유 식별자입니다.
-
aws_region - 이 DB 인스턴스가 있는 AWS 리전입니다. 엔진별 AWS 리전을 나열한 테이블은 리전 가용성 섹션을 참조하세요.
-
durable_lsn – 스토리지에서 뛰어난 내구성을 갖도록 만든 LSN입니다.
-
highest_lsn_rcvd – 라이터 DB 인스턴스에서 DB 인스턴스가 수신한 가장 높은 LSN입니다.
-
feedback_epoch – DB 인스턴스가 핫 스탠바이 정보를 생성할 때 사용하는 epoch입니다.
상시 대기 상황은 서버가 복구 또는 대기 모드에 있는 동안 DB 인스턴스가 연결하고 쿼리할 수 있는 기간입니다. 핫 스탠바이 피드백은 핫 스탠바이 상태일 때 DB 인스턴스에 대한 정보입니다. 자세한 내용은 핫 스탠바이
에 관한 PostgreSQL 설명서를 참조하십시오. -
feedback_xmin – DB 인스턴스가 사용하는 최소(가장 오래된) 활성 트랜잭션 ID입니다.
-
oldest_read_view_lsn – DB 인스턴스가 스토리지에서 읽는 데 사용하는 가장 오래된 LSN입니다.
-
visibility_lag_in_msec – 이 DB 인스턴스가 라이터 DB 인스턴스보다 지연된 시간입니다.
-
이러한 값이 시간에 따라 어떻게 바뀌는지 확인하려면 테이블 삽입에 한 시간이 걸리는 다음 트랜잭션 블록을 살펴보십시오.
psql> BEGIN;
psql> INSERT INTO table1 SELECT Large_Data_That_Takes_1_Hr_To_Insert;
psql> COMMIT;경우에 따라 BEGIN 문 이후 기본 DB 클러스터와 보조 DB 클러스터 사이에 네트워크 연결 끊김이 발생할 수 있습니다. 이러한 경우 보조 DB 클러스터의 durability_lag_in_msec 값이 증가하기 시작합니다. INSERT 문의 끝에서 durability_lag_in_msec 값은 1시간입니다. 하지만 기본 DB 클러스터와 보조 DB 클러스터 간에 커밋된 모든 사용자 데이터가 여전히 동일하기 때문에 이 rpo_lag_in_msec 값은 0입니다. COMMIT 문이 완료되는 즉시 rpo_lag_in_msec 값이 증가합니다.
