Amazon Aurora Global Database 사용
Amazon Aurora Global Database 기능을 사용하면 여러 AWS 리전에 걸쳐 있는 여러 Aurora DB 클러스터를 설정합니다. Aurora는 기본 DB 클러스터의 모든 변경 사항을 하나 이상의 보조 클러스터와 자동으로 동기화합니다. Aurora 글로벌 데이터베이스는 하나의 리전에 프라이머리 DB 클러스터를 그리고 서로 다른 리전에 최대 10개의 보조 DB 클러스터를 포함합니다. 이 다중 리전 구성은 전체 AWS 리전에 영향을 미칠 수 있는 드물게 발생하는 중단으로부터 빠르게 복구합니다. 여러 지리적 위치에 모든 데이터의 전체 복사본을 보유하면 전 세계에 널리 분산된 위치에서 연결되는 애플리케이션의 읽기 작업도 지연 시간이 짧게 처리할 수 있습니다.
주제
Amazon Aurora Global Database 개요
Amazon Aurora Global Database 기능을 사용하면 여러 AWS 리전에 걸쳐 있는 단일 Aurora 데이터베이스를 사용하여 전역으로 분산된 애플리케이션을 실행할 수 있습니다.
Aurora 글로벌 데이터베이스는 데이터가 써지는 하나의 프라이머리 AWS 리전 및 최대 10개의 읽기 전용 보조 AWS 리전으로 구성됩니다. 쓰기 연산을 기본 AWS 리전의 기본 DB 클러스터에서 시작합니다. 이렇게 하는 가장 편리한 방법은 Aurora Global Database 라이터 엔드포인트에 연결하는 것입니다. 이 엔드포인트는 다른 AWS 리전으로 전환 또는 장애 조치 후에도 항상 기본 DB 클러스터를 가리킵니다. 쓰기 작업 후 Aurora는 일반적으로 1초 미만의 대기 시간으로 전용 인프라를 사용하여 보조 AWS 리전에 데이터를 복제합니다.
다음 다이어그램에서 두개의 AWS 리전에 걸쳐 있는 Aurora Global Database의 예를 볼 수 있습니다.
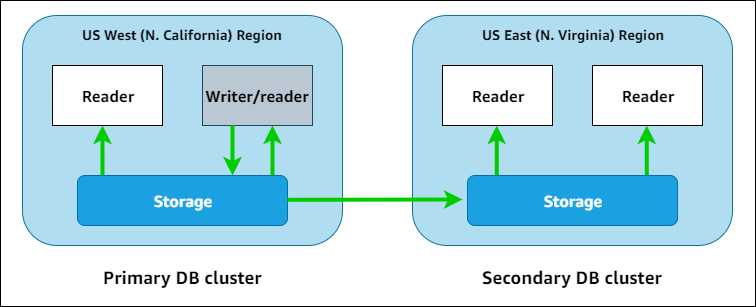
하나 이상의 Aurora 리더 인스턴스를 추가하여 읽기 전용 워크로드를 처리함으로써 보조 클러스터를 독립적으로 확장할 수도 있습니다. Aurora Serverless v2를 리더 인스턴스에 사용하여 더 세분화되고 유연한 조정을 수행할 수 있습니다.
기본 클러스터만 쓰기 작업을 수행합니다. 쓰기 작업을 수행하는 클라이언트는 항상 기본 클러스터의 라이터 DB 인스턴스를 가리키는 Aurora Global Database 라이터 엔드포인트에 연결됩니다. 다이어그램에 표시된 대로 Aurora는 빠른 저 오버헤드 복제에 데이터베이스 엔진이 아닌 클러스터 스토리지 볼륨을 사용합니다. 자세한 내용은 Amazon Aurora 스토리지 개요를 참조하세요.
Aurora Global Database는 전 세계 설치 공간을 갖춘 애플리케이션 용으로 설계되었습니다. 읽기 전용 보조 DB 클러스터는 여러 AWS 리전에서 애플리케이션 사용자와 근접하게 읽기 작업 최적화를 지원합니다. 쓰기 전달 기능을 사용하면 보조 클러스터가 기본 클러스터로 쓰기 요청을 보내도록 글로벌 데이터베이스를 구성할 수도 있습니다. 자세한 내용은 Amazon Aurora 글로벌 데이터베이스에서 쓰기 전달 사용 섹션을 참조하세요.
Aurora Global Database는 2가지 시나리오(Aurora Global Database 전환 및 Aurora Global Database 장애 조치)에 따라 기본 DB 클러스터의 리전을 변경하는 2가지 작업을 지원합니다.
-
리전 순환과 같이 계획된 운영 절차의 경우 전환 메커니즘(이전 명칭: '계획된 관리형 장애 조치')을 사용하세요. 이 기능을 사용하면 정상적인 Aurora Global Database의 기본 클러스터를 데이터 손실 없이 보조 리전 중 하나로 재배치할 수 있습니다. 자세한 내용은 Amazon Aurora Global Database에서 전환 수행를 참조하세요.
-
기본 리전에서 중단된 후 Aurora Global Database를 복구하려면 장애 조치 메커니즘을 사용하세요. 이 기능을 사용하면 기본 DB 클러스터에서 다른 리전으로 장애 조치를 수행할 수 있습니다(리전 간 장애 조치). 자세한 내용은 Aurora Global Database에서 계획된 관리형 장애 조치 수행를 참조하세요.
Amazon Aurora Global Database의 장점
Aurora Global Database를 사용하면 다음과 같은 이점을 얻을 수 있습니다.
로컬 대기 시간으로 글로벌 읽기 – 전 세계에 지사를 두고 있는 경우, Aurora Global Database를 사용하여 기본 AWS 리전에서 정보의 주요 소스를 최신 상태로 유지할 수 있습니다. 다른 리전의 사무실은 로컬 지연 시간을 사용하여 해당 리전의 정보에 액세스할 수 있습니다.
확장 가능한 보조 Aurora DB 클러스터 – AWS 리전에 읽기 전용 인스턴스를 추가하여 보조 클러스터를 확장할 수 있습니다. 세컨더리 클러스터는 읽기 전용이므로 단일 Aurora 클러스터에 대하여 일반적인 제한인 15개가 아닌 최대 16개의 읽기 전용 DB 인스턴스를 지원할 수 있습니다.
기본 DB클러스터에서 보조 Aurora DB 클러스터로의 빠른 복제 – Aurora Global Database에서 수행되는 복제는 기본 DB 클러스터의 성능에 거의 영향을 미치지 않습니다. DB 인스턴스의 리소스는 애플리케이션 읽기/쓰기 워크로드 처리 전용입니다.
리전 전체의 운영 중단으로부터 복구 – 보조 클러스터를 사용하면 기존 복제 솔루션보다 적은 데이터 손실(더 낮은 RPO)로 새로운 기본 AWS 리전에서 Aurora Global Database를 보다 신속하게(더 낮은 RTO) 가용 상태로 만들 수 있습니다.
리전 및 버전 사용 가능 여부
기능에 관한 가용성 및 지원은 각 Aurora 데이터베이스 엔진의 특정 버전 및 AWS 리전에 따라 다릅니다. Aurora Global Database의 버전 및 리전 가용성에 대한 자세한 정보는 Aurora Global Database를 지원하는 리전 및 DB 엔진 섹션을 참조하세요.
Amazon Aurora Global Database에 적용되는 제한 사항
현재 다음 제한이 Aurora Global Database에 적용됩니다.
Aurora Global Database는 특정 AWS 리전에서 사용할 수 있으며 특정 Aurora MySQL 및 Aurora PostgreSQL 버전에 사용할 수 있습니다. 자세한 내용은 Aurora Global Database를 지원하는 리전 및 DB 엔진 섹션을 참조하세요.
Aurora Global Database에는 지원되는 Aurora DB 인스턴스 클래스, 최대 AWS 리전 수 등에 대한 구성 관련 특정 요구 사항이 있습니다. 자세한 내용은 Amazon Aurora Global Database의 구성 요구 사항 섹션을 참조하세요.
MySQL 5.7과 호환되는 Aurora MySQL의 경우 Aurora Global Database 전환에는 버전 2.09.1 이상의 마이너 버전이 필요합니다.
-
기본 및 보조 DB 클러스터에 있는 메이저 및 마이너 엔진 버전이 동일한 경우에만 Aurora Global Database에서 관리형 리전 간 전환 또는 장애 조치를 수행할 수 있습니다. 엔진 및 엔진 버전에 따라 패치 수준이 동일해야 하거나 패치 수준이 다를 수 있습니다. 패치 수준이 다른 기본 클러스터와 보조 클러스터 간에 이러한 작업을 허용하는 엔진 및 엔진 버전 목록은 관리형 리전 간 전환 및 장애 조치를 위한 패치 수준 호환성 섹션을 참조하세요. 엔진 버전에 동일한 패치 수준이 필요한 경우 Aurora Global Database에서 수동 장애 조치 수행에 나온 단계에 따라 수동으로 장애 조치를 수행할 수 있습니다.
Aurora Global Database는 현재 다음 Aurora 기능을 지원하지 않습니다.
-
Aurora Serverless v1
-
Aurora 내 역추적
-
RDS 프록시 기능을 글로벌 데이터베이스에서 사용할 때의 제한 사항은 글로벌 데이터베이스에서 RDS 프록시의 제한 사항 섹션을 참조하세요.
자동 마이너 버전 업그레이드는 Aurora MySQL 및 글로벌 데이터베이스의 부분인 Aurora PostgreSQL 클러스터에는 적용되지 않습니다. 글로벌 데이터베이스 클러스터의 일부인 DB 인스턴스에 대해 이 설정을 지정할 수 있지만 이 설정은 아무런 영향을 미치지 않습니다.
Aurora Global Database는 현재 DB 데이터베이스 클러스터에 대해 Aurora Auto Scaling을 지원하지 않습니다.
Aurora MySQL 5.7을 실행하는 Aurora Global Database에서 데이터베이스 활동 스트림(DAS)을 사용하려면 엔진 버전이 버전 2.08 이상이어야 합니다. DAS에 대한 자세한 내용은 데이터베이스 활동 스트림을 사용하여 Amazon Aurora 모니터링 섹션을 참조하세요.
-
현재 다음 제한이 Aurora Global Database 업그레이드에 적용됩니다.
해당 Aurora 전역 데이터베이스의 메이저 버전 업그레이드를 수행하는 동안에는 전역 데이터베이스 클러스터에 대한 사용자 지정 파라미터 그룹을 적용할 수 없습니다. 전역 클러스터의 각 리전에 사용자 지정 파라미터 그룹을 생성한 다음 업그레이드 후 리전 클러스터에 수동으로 적용합니다.
-
Aurora MySQL 기반 Aurora Global Database 사용 시
lower_case_table_names파라미터가 활성화 되어 있는 경우 Aurora MySQL 버전 2에서 버전 3으로 현재 위치 업그레이드를 수행할 수 없습니다. 사용할 수 있는 메서드에 대한 자세한 내용은 메이저 버전 업그레이드 섹션을 참조하세요. Aurora Global Database 사용 시 목표 복구 시점(RPO) 기능이 켜져 있는 경우 Aurora PostgreSQL DB 엔진의 메이저 버전 업그레이드를 수행할 수 없습니다. RPO 기능에 대한 자세한 내용은 Aurora PostgreSQL–기반 전역 데이터베이스에 대한 RPO 관리 섹션을 참조하세요.
Aurora Global Database 사용 시 표준 프로세스를 사용하여 Aurora MySQL 버전 3.01 또는 3.02에서 3.03 이상으로 마이너 버전 업그레이드를 수행할 수 없습니다. 사용할 프로세스에 대한 자세한 내용은 엔진 버전을 수정하여 Aurora MySQL 업그레이드 섹션을 참조하세요.
Aurora Global Database 업그레이드에 대한 자세한 내용은 Amazon Aurora Global Database 업그레이드 섹션을 참조하세요.
글로벌 데이터베이스에서 Aurora DB 클러스터를 개별적으로 중지하거나 시작할 수는 없습니다. 자세한 내용은 Amazon Aurora DB 클러스터 중지 및 시작를 참조하세요.
보조 Aurora DB 클러스터에 연결된 Aurora 리더 DB 인스턴스는 특정 상황에서 다시 시작될 수 있습니다. 기본 AWS 리전의 라이터 DB 인스턴스에 재시작 또는 장애 조치가 발생할 경우 보조 리전의 리더 DB 인스턴스도 다시 시작됩니다. 모든 리더 DB 인스턴스가 기본 DB 클러스터의 라이터 인스턴스와 다시 동기화될 때까지 보조 클러스터를 사용할 수 없습니다. 재부팅 시 또는 장애 조치 중에 기본 클러스터의 동작은 단일 비글로벌 DB 클러스터의 동작과 동일합니다. 자세한 내용은 Amazon Aurora를 사용한 복제 섹션을 참조하세요.
기본 DB 클러스터를 변경하기 전에 전역 데이터베이스에 대한 영향을 이해해야 합니다. 자세한 내용은 계획되지 않은 중단으로부터 Amazon Aurora Global Database 복구를 참조하세요.
Aurora Global Database에서는 현재 Amazon Aurora가 DB 클러스터의 AWS KMS 키에 대한 액세스 권한을 상실할 때
inaccessible-encryption-credentials-recoverable상태를 지원하지 않습니다. 이 경우 암호화된 DB 클러스터는 바로 최종inaccessible-encryption-credentials상태가 됩니다. 이러한 상태에 대한 자세한 내용은 DB 클러스터 상태 보기 섹션을 참조하세요.-
Secrets Manager는 Aurora Global Database를 지원하지 않습니다. 글로벌 데이터베이스에 리전을 추가할 때는 먼저 DB 인스턴스에 대한 Secrets Manager 통합을 꺼야 합니다.
-
Aurora Global Database를 사용하는 Aurora PostgreSQL 기반 DB 클러스터에는 다음과 같은 제한 사항이 있습니다:
Aurora 글로벌 데이터베이스의 일부인 Aurora PostgreSQL 보조 DB 클러스터에는 클러스터 캐시 관리가 지원되지 않습니다.
-
글로벌 데이터베이스의 기본 DB 클러스터가 Amazon RDS PostgreSQL 인스턴스의 복제본을 기반으로 하는 경우 보조 클러스터를 생성할 수 없습니다. AWS Management Console, AWS CLI, 또는
CreateDBClusterAPI 작업을 사용하여 해당 클러스터에서 보조 클러스터를 생성하지 마십시오. 이렇게 하면 시간이 초과되며 세컨더리 클러스터가 생성되지 않습니다.
기본 DB 엔진과 동일한 버전의 DB 엔진을 사용하여 글로벌 데이터베이스에 대한 보조 Aurora DB 클러스터를 생성하는 것이 좋습니다. 자세한 내용은 Amazon Aurora 글로벌 데이터베이스 생성 섹션을 참조하세요.
