Amazon RDS용 다중 AZ DB 클러스터 배포
다중 AZ DB 클러스터 배포는 읽을 수 있는 복제 DB 인스턴스가 2개 있는 Amazon RDS의 반동기식 고가용성 배포 모드입니다. 다중 AZ DB 클러스터에는 동일한 AWS 리전에 있는 세 개의 개별 가용 영역에 라이터 DB 인스턴스와 두 개의 리더 DB 인스턴스가 있습니다. 다중 AZ DB 클러스터는 다중 AZ DB 인스턴스 배포에 비해 고가용성, 높은 읽기 워크로드 용량, 낮은 쓰기 대기 시간을 지원합니다.
가동 중지 시간을 줄이면서 Amazon RDS for MySQL 데이터베이스로 데이터 가져오기의 지침에 따라 온프레미스 데이터베이스의 데이터를 다중 AZ DB 클러스터로 가져올 수 있습니다.
다중 AZ DB 클러스터에 대한 예약 DB 인스턴스를 구매할 수 있습니다. 자세한 내용은 다중 AZ DB 클러스터에 대한 예약 DB 인스턴스 섹션을 참조하세요.
기능 가용성 및 해당 지원은 각 데이터베이스 엔진의 특정 버전 및 AWS 리전 리전에 따라 다릅니다. 다중 AZ DB 클러스터가 포함된 Amazon RDS의 버전 및 리전 가용성에 대한 자세한 내용은 Amazon RDS에서 다중 AZ DB 클러스터를 지원하는 리전 및 DB 엔진 단원을 참조하세요.
주제
중요
다중 AZ DB 클러스터는 Aurora DB 클러스터와 동일하지 않습니다. Aurora DB 클러스터에 대한 자세한 내용은 Amazon Aurora 사용 설명서를 참조하세요.
다중 AZ DB 클러스터에서 사용 가능한 인스턴스 클래스
다중 AZ DB 클러스터 배포는 db.m5d, db.m6gd, db.m6id, db.m6idn, db.r5d, db.r6gd, db.x2iedn, db.r6id, db.r6idn 및 db.c6gd DB 인스턴스 클래스에 지원됩니다.
참고
c6gd 인스턴스 클래스는 medium 인스턴스 크기를 지원하는 유일한 인스턴스 클래스입니다.
DB 인스턴스 클래스에 대한 자세한 내용은 DB 인스턴스 클래스 섹션을 참조하세요.
다중 AZ DB 클러스터 아키텍처
다중 AZ DB 클러스터에서는 Amazon RDS가 DB 엔진의 네이티브 복제 기능을 사용하여 라이터 DB 인스턴스의 데이터를 두 리더 DB 인스턴스로 복제합니다. 라이터 DB 인스턴스가 변경되면 각 리더 DB 인스턴스로 전송됩니다.
다중 AZ DB 클러스터 배포에서는 변경 사항을 커밋하려면 하나 이상의 리더 DB 인스턴스의 승인을 받아야 하는 반동기식 복제를 사용합니다. 모든 복제본에서 이벤트가 완전히 실행되고 커밋되었음을 승인하는 작업은 필요하지 않습니다.
리더 DB 인스턴스는 자동 장애 조치 대상 역할을 하며 읽기 트래픽을 제공하여 애플리케이션 읽기 처리량을 높입니다. 라이터 DB 인스턴스에서 중단이 발생하는 경우 RDS는 어느 리더 DB 인스턴스가 장애 조치 대상이 되는지를 관리합니다. RDS는 어느 리더 DB 인스턴스의 가장 최근 변경 기록을 기준으로 이를 수행합니다.
다음 다이어그램은 다중 AZ DB 클러스터를 보여줍니다.
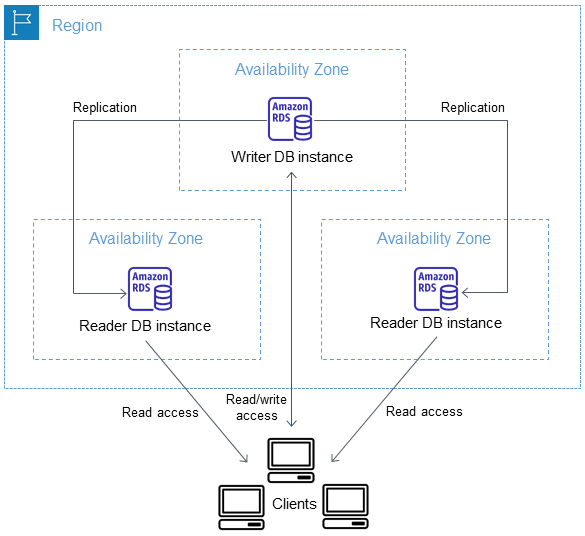
일반적으로 다중 AZ DB 클러스터는 다중 AZ DB 인스턴스 배포에 비해 쓰기 대기 시간이 짧습니다. 또한 읽기 전용 워크로드가 리더 DB 인스턴스에서 실행되도록 허용합니다. RDS 콘솔에는 라이터 DB 인스턴스의 가용 영역과 리더 DB 인스턴스의 가용 영역이 표시됩니다. describe-db-clusters CLI 명령이나 DescribeDBClusters API 작업을 사용하여 이 정보를 찾아볼 수도 있습니다.
중요
RDS for MySQL 다중 AZ DB 클러스터의 복제 오류를 방지하려면 모든 테이블에 프라이머리 키가 있는 것이 좋습니다.
다중 AZ DB 클러스터용 파라미터 그룹
다중 AZ DB 클러스터에서 DB 클러스터 파라미터 그룹은 다중 AZ DB 클러스터의 모든 DB 인스턴스에 적용되는 엔진 구성 값에 대한 컨테이너 역할을 합니다.
다중 AZ DB 클러스터에서 DB 파라미터 그룹은 DB 엔진 및 DB 엔진 버전에 대한 기본 DB 파라미터 그룹으로 설정됩니다. DB 클러스터 파라미터 그룹의 설정은 클러스터의 모든 DB 인스턴스에 사용됩니다.
파라미터 그룹에 대한 자세한 내용은 다중 AZ DB 클러스터용 DB 클러스터 파라미터 그룹 작업 단원을 참조하세요.
RDS 프록시를 다중 AZ DB 클러스터와 함께 사용
Amazon RDS 프록시를 사용하여 다중 AZ DB 클러스터의 프록시를 만들 수 있습니다. RDS 프록시를 사용하면 애플리케이션이 데이터베이스 연결을 풀링하고 공유할 수 있어 확장 기능을 향상할 수 있습니다. 각 프록시는 연결 재사용이라고도 하는 연결 멀티플렉싱을 수행합니다. 멀티플렉싱을 사용하면 RDS 프록시가 하나의 기본 데이터베이스 연결을 사용하여 한 트랜잭션에 대한 모든 작업을 수행합니다. 또한, RDS 프록시는 다중 AZ DB 클러스터의 마이너 버전 업그레이드로 인한 가동 중지 시간을 1초 이하로 줄일 수 있습니다. RDS 프록시의 이점에 대한 자세한 내용은 Amazon RDS Proxy 섹션을 참조하세요.
다중 AZ DB 클러스터에 프록시를 설정하려면 클러스터를 생성할 때 RDS 프록시 생성을 선택합니다. RDS 프록시 엔드포인트를 생성하고 관리하는 방법에 대한 지침은 Amazon RDS 프록시 엔드포인트 작업 섹션을 참조하세요.
복제본 지연 시간 및 다중 AZ DB 클러스터
복제본 지연 시간은 리더 DB 인스턴스에서 가장 최근에 적용된 트랜잭션과 라이터 DB 인스턴스에서 가장 최근 트랜잭션 사이의 시간 차이입니다. Amazon CloudWatch 지표 ReplicaLag는 이 시차를 나타냅니다. CloudWatch 지표에 대한 자세한 내용은 Amazon CloudWatch로 Amazon RDS 지표 모니터링 섹션을 참조하세요.
다중 AZ DB 클러스터는 높은 쓰기 성능을 허용하지만 엔진 기반 복제의 특성으로 인해 복제본 지연이 계속 발생할 수 있습니다. 모든 장애 조치는 새 라이터 DB 인스턴스를 승격하기 전에 먼저 복제본 지연을 해결해야 하므로 이 복제본 지연을 모니터링하고 관리하는 것이 고려 사항입니다.
RDS for MySQL 다중 AZ DB 클러스터용 장애 조치 시간은 나머지 리더 DB 인스턴스의 복제본 지연에 따라 달라집니다. 두 리더 DB 인스턴스는 모두 적용되지 않은 트랜잭션을 적용해야 그 중 하나가 새 라이터 DB 인스턴스로 승격됩니다.
RDS for PostgreSQL 다중 AZ DB 클러스터용 장애 조치 시간은 가장 낮은 나머지 리더 DB 인스턴스의 복제본 지연에 따라 달라집니다. 가장 낮은 복제본 지연을 가진 리더 DB 인스턴스는 모두 적용되지 않은 트랜잭션을 적용해야 새 라이터 DB 인스턴스로 승격됩니다.
복제본 지연이 설정된 시간을 초과할 때 CloudWatch 경보를 생성하는 방법을 보여주는 자습서는 자습서: Amazon RDS에 대한 다중 AZ DB 클러스터 복제본 지연에 대한 Amazon CloudWatch 경보 생성 섹션을 참조하세요.
복제본 지연의 일반적인 원인
일반적으로 복제본 지연은 쓰기 워크로드가 너무 높아 리더 DB 인스턴스가 트랜잭션을 효율적으로 적용할 수 없을 때 발생합니다. 다양한 워크로드로 인해 일시적 또는 지속적인 복제본 지연이 발생할 수 있습니다. 다음은 몇 가지 일반적인 원인의 예입니다.
-
라이터 DB 인스턴스의 높은 쓰기 동시성 또는 대량 일괄 업데이트로 인해 리더 DB 인스턴스의 적용 프로세스가 뒤쳐집니다.
-
하나 이상의 리더 DB 인스턴스의 리소스를 사용하는 대량 읽기 워크로드입니다. 느리거나 큰 쿼리를 실행하면 적용 프로세스에 영향이 있고 복제본 지연이 발생할 수 있습니다.
-
데이터베이스가 커밋 순서를 유지해야 하기 때문에 대량의 데이터 또는 DDL 문을 수정하는 트랜잭션으로 인해 복제본 지연 시간이 일시적으로 증가하는 경우가 있습니다.
복제본 지연 완화
RDS for MySQL 및 RDS for PostgreSQL용 다중 AZ DB 클러스터의 경우 라이터 DB 인스턴스의 로드를 줄여 복제본 지연을 완화할 수 있습니다. 흐름 제어를 사용하여 복제본 지연을 줄일 수도 있습니다. 흐름 제어는 라이터 DB 인스턴스에서 쓰기를 제한하여 작동하므로 복제본 지연 시간이 계속해서 무제한으로 증가하지 않도록 합니다. 쓰기 제한은 트랜잭션 끝에 지연을 추가하여 수행되며, 이로 인해 라이터 DB 인스턴스의 쓰기 처리량이 감소합니다. 흐름 제어가 지연 제거를 보장하지는 않지만 많은 워크로드에서 전반적인 지연을 줄이는 데 도움이 될 수 있습니다. 다음 섹션에서는 RDS for MySQL 및 RDS PostgreSQL로 흐름 제어를 사용하는 방법을 제공합니다.
RDS for MySQL에 대한 흐름 제어를 통해 복제본 지연 완화
RDS for MySQL 다중 AZ DB 클러스터를 사용하는 경우 동적 파라미터 rpl_semi_sync_master_target_apply_lag을 사용하면 흐름 제어가 기본적으로 활성화됩니다. 이 파라미터는 복제본 지연에 대해 원하는 상한을 지정합니다. 복제본 지연이 구성된 제한에 가까워지면 흐름 제어는 라이터 DB 인스턴스의 쓰기 트랜잭션을 제한하여 지정된 값보다 낮은 복제본 지연을 포함하려고 시도합니다. 경우에 따라 복제본 지연이 지정된 제한을 초과할 수 있습니다. 기본적으로 이 파라미터는 120초로 설정됩니다. 흐름 제어를 비활성화하려면 이 파라미터를 최대 값 86,400초(하루)로 설정합니다.
흐름 제어에 의해 주입된 현재 지연을 보려면 다음 쿼리를 실행하여 Rpl_semi_sync_master_flow_control_current_delay 파라미터를 표시하세요.
SHOW GLOBAL STATUS like '%flow_control%';
출력은 다음과 비슷한 형태가 됩니다.
+-------------------------------------------------+-------+
| Variable_name | Value |
+-------------------------------------------------+-------+
| Rpl_semi_sync_master_flow_control_current_delay | 2010 |
+-------------------------------------------------+-------+
1 row in set (0.00 sec)참고
지연은 마이크로초 단위로 표시됩니다.
RDS for MySQL Multi-AZ DB 클러스터에서 성능 개선 도우미를 활성화하면 흐름 제어에 의해 쿼리가 지연되었음을 나타내는 해당 SQL 문 대기 이벤트를 모니터링할 수 있습니다. 흐름 제어에 의해 지연이 발생했을 때 성능 개선 도우미 대시보드의 해당 SQL 문에서 /wait/synch/cond/semisync/semi_sync_flow_control_delay_cond 대기 이벤트를 볼 수 있습니다. 이러한 지표를 보려면 성능 스키마가 켜져 있는지 확인합니다. 성능 개선 도우미에 대한 자세한 내용은 성능 개선 도우미를 통한 Amazon RDS 모니터링 섹션을 참조하세요.
RDS for PostgreSQL에 대한 흐름 제어를 통해 복제본 지연 완화
RDS for PostgreSQL용 다중 AZ DB 클러스터를 사용하면 흐름 제어가 확장으로 배포됩니다. 이는 DB 클러스터의 모든 DB 인스턴스에 대해 백그라운드 작업자를 켭니다. 기본적으로 리더 DB 인스턴스의 백그라운드 작업자는 현재 복제본 지연을 라이터 DB 인스턴스의 백그라운드 작업자에게 알립니다. 리더 DB 인스턴스에서 지연이 2분을 초과하면 라이터 DB 인스턴스의 백그라운드 작업자가 트랜잭션 종료 시 지연을 추가합니다. 지연 임계값을 제어하려면 flow_control.target_standby_apply_lag 파라미터를 사용합니다.
흐름 제어가 PostgreSQL 프로세스를 제한하면 pg_stat_activity 및 성능 개선 도우미의 Extension 대기 이벤트가 이를 나타냅니다. 함수 get_flow_control_stats는 현재 추가되고 있는 지연 시간에 대한 세부 정보를 표시합니다.
흐름 제어는 짧지만 동시 트랜잭션이 많은 대부분의 온라인 트랜잭션 처리(OLTP) 워크로드에 이상적입니다. 배치 작업과 같은 장기 실행 트랜잭션으로 인해 지연이 발생하는 경우 흐름 제어는 큰 이점을 제공하지 않습니다.
shared_preload_libraries에서 확장을 제거하고 DB 인스턴스를 재부팅하여 흐름 제어를 해제할 수 있습니다.
다중 AZ DB 클러스터 스냅샷
Amazon RDS는 구성된 백업 기간 동안 다중 AZ DB 클러스터의 자동 백업을 생성하고 저장합니다. RDS는 개별 인스턴스가 아닌 전체 클러스터를 백업하여 DB 클러스터의 스토리지 볼륨 스냅샷을 생성합니다.
다중 AZ DB 클러스터의 수동 백업을 수행할 수도 있습니다. 매우 장기간 백업하려면 스냅샷 데이터를 Amazon S3로 내보내는 것을 고려합니다. 자세한 내용은 Amazon RDS용 다중 AZ DB 클러스터 스냅샷 생성 섹션을 참조하세요.
다중 AZ DB 클러스터를 특정 시점으로 복원하여 새 다중 AZ DB 클러스터를 생성할 수 있습니다. 지침은 다중 AZ DB 클러스터를 특정 시점으로 복원 섹션을 참조하세요.
또는 다중 AZ DB 클러스터 스냅샷을 단일 AZ 배포 또는 다중 AZ DB 인스턴스 배포에 복원할 수 있습니다. 지침은 다중 AZ DB 클러스터 스냅샷에서 DB 인스턴스로 복원 단원을 참조하세요.
