S3 Express One Zone 성능을 최적화하는 모범 사례
Amazon S3 Express One Zone에서 객체를 업로드 및 검색하는 애플리케이션을 빌드할 때 모범 사례 지침에 따라 성능을 최적화합니다. S3 Express One Zone 스토리지 클래스를 사용하려면 S3 디렉터리 버킷을 생성해야 합니다. S3 Express One Zone 스토리지 클래스는 S3 범용 버킷과 함께 사용할 수 없습니다.
기타 모든 Amazon S3 스토리지 클래스 및 S3 범용 버킷에 대한 성능 지침은 모범 사례 설계 패턴: Amazon S3 성능 최적화 섹션을 참조하세요.
대규모 워크로드에서 S3 Express One Zone 스토리지 클래스 및 디렉터리 버킷의 성능과 확장성을 최적화하려면 디렉터리 버킷이 범용 버킷과 어떻게 다른지 이해하는 것이 중요합니다. 그런 다음 디렉터리 버킷의 작동 방식에 맞게 애플리케이션을 조정하는 모범 사례가 제시되어 있습니다.
디렉터리 버킷의 작동 방식
Amazon S3 Express One Zone 스토리지 클래스는 디렉터리 버킷당 초당 최대 2,000,000개의 GET 및 최대 200,000개의 PUT 트랜잭션(TPS)으로 워크로드를 지원할 수 있습니다. S3 Express One Zone을 사용하면 데이터가 가용 영역의 S3 디렉터리 버킷에 저장됩니다. 디렉터리 버킷의 객체는 파일 시스템과 유사한 계층적 네임스페이스 내에서 액세스할 수 있으며, 이는 플랫 네임스페이스를 사용하는 S3 범용 버킷과는 대조적입니다. 범용 버킷과 달리 디렉터리 버킷은 키를 접두사 대신 디렉터리에 계층적으로 구성합니다. 접두사는 객체 키 이름의 시작 부분에 있는 문자열입니다. 범용 버킷에서는 접두사를 사용하여 데이터를 구성하고 플랫 객체 스토리지 아키텍처를 관리할 수 있습니다. 자세한 내용은 접두어를 사용한 객체 구성 섹션을 참조하세요.
디렉터리 버킷에서 객체는 유일하게 지원되는 구분 기호인 슬래시(/)를 사용하여 계층적 네임스페이스에 구성됩니다. dir1/dir2/file1.txt와 같은 키를 사용하여 객체를 업로드하면 Amazon S3에서 dir1/ 및 dir2/ 디렉터리가 자동으로 생성되고 관리됩니다. 디렉터리는 PutObject 또는 CreateMultiPartUpload 작업 중에 생성되며 DeleteObject 또는 AbortMultiPartUpload 작업 후 비어 있게 되면 자동으로 제거됩니다. 디렉터리의 객체 및 하위 디렉터리 수에는 상한이 없습니다.
객체가 디렉터리 버킷에 업로드될 때 생성되는 디렉터리는 HTTP 503 (Slow Down) 오류 발생 가능성을 줄이도록 즉시 규모가 조정될 수 있습니다. 이 자동 크기 조정을 통해 애플리케이션은 필요에 따라 디렉터리 내부 및 디렉터리 간 읽기 및 쓰기 요청을 병렬화할 수 있습니다. S3 Express One Zone의 경우 개별 디렉터리는 디렉터리 버킷의 최대 요청 속도를 지원하도록 설계되었습니다. 시스템이 균등한 로드 분배를 위해 객체를 자동으로 분산하므로 최적의 성능을 달성하기 위해 키 접두사를 무작위화할 필요는 없습니다. 하지만 그 결과로 키가 디렉터리 버킷에 사전순으로 저장되지 않습니다. 이는 사전순으로 더 가까운 키가 동일한 서버에 함께 위치할 가능성이 더 높은 S3 범용 버킷과는 대조적입니다.
디렉터리 버킷 작업 및 디렉터리 상호 작용의 예에 대한 자세한 내용은 디렉터리 버킷 작업 및 디렉터리 상호 작용 예시 섹션을 참조하세요.
모범 사례
디렉터리 버킷 성능을 최적화하고 시간이 지남에 따라 워크로드 규모를 조정할 수 있도록 하려면 모범 사례를 따르세요.
많은 항목(객체 또는 하위 디렉터리)을 포함하는 디렉터리 사용
디렉터리 버킷은 기본적으로 모든 워크로드에 대해 높은 성능을 제공합니다. 특정 작업의 성능을 더욱 최적화하기 위해 더 많은 항목(객체 또는 하위 디렉터리)을 디렉터리에 통합하면 지연 시간이 단축되고 요청 속도가 빨라집니다.
PutObject,DeleteObject,CreateMultiPartUpload,AbortMultiPartUpload와 같은 변형 API 작업은 수천 개의 항목을 포함하는 적은 수의 고밀도 디렉터리를 사용하여 구현할 때 최적의 성능을 발휘하며, 많은 수의 작은 디렉터리를 사용하는 것보다 더 효과적입니다.ListObjectsV2작업은 결과 페이지를 채우기 위해 탐색해야 하는 디렉터리 수가 적을수록 더 나은 성능을 발휘합니다.
접두사에 엔트로피를 사용하지 않음
Amazon S3 작업에서 엔트로피는 접두사 이름 지정의 무작위성을 의미하며, 이는 스토리지 파티션 간에 워크로드를 균등하게 분산하는 데 도움이 됩니다. 그러나 디렉터리 버킷은 로드 분산을 내부적으로 관리하므로 최상의 성능을 위해 접두사에 엔트로피를 사용하지 않는 것이 좋습니다. 디렉터리 버킷의 경우 엔트로피로 인해 이미 생성된 디렉터리가 재사용되지 않아 요청이 느려질 수 있기 때문입니다.
$HASH/directory/object와 같은 키 패턴은 많은 중간 디렉터리를 생성할 수 있습니다. 다음 예시에서 모든 job-1은 상위 디렉터리가 다르기 때문에 서로 다른 디렉터리입니다. 디렉터리의 밀도가 낮아지고 변형 및 목록 요청 속도가 느려집니다. 이 예시에는 모두 단일 항목을 가진 중간 디렉터리가 12개 있습니다.
s3://my-bucket/0cc175b9c0f1b6a831c399e269772661/job-1/file1 s3://my-bucket/92eb5ffee6ae2fec3ad71c777531578f/job-1/file2 s3://my-bucket/4a8a08f09d37b73795649038408b5f33/job-1/file3 s3://my-bucket/8277e0910d750195b448797616e091ad/job-1/file4 s3://my-bucket/e1671797c52e15f763380b45e841ec32/job-1/file5 s3://my-bucket/8fa14cdd754f91cc6554c9e71929cce7/job-1/file6
대신 더 나은 성능을 위해 $HASH 구성 요소를 제거하고 job-1을 단일 디렉터리로 만들어 디렉터리 밀도를 높일 수 있습니다. 다음 예시에서 6개의 항목을 가진 단일 중간 디렉터리가 이전 예시에 비해 더 나은 성능을 낼 수 있습니다.
s3://my-bucket/job-1/file1 s3://my-bucket/job-1/file2 s3://my-bucket/job-1/file3 s3://my-bucket/job-1/file4 s3://my-bucket/job-1/file5 s3://my-bucket/job-1/file6
이러한 성능 이점은 객체 키가 처음 생성되고 키 이름에 디렉터리가 포함되면 해당 객체에 대한 디렉터리가 자동으로 생성되기 때문에 발생합니다. 이후에 동일한 디렉터리에 객체를 업로드할 때는 디렉터리를 생성할 필요가 없으므로 기존 디렉터리로 객체를 업로드하는 데 걸리는 지연 시간이 줄어듭니다.
ListObjectsV2 직접 호출 시 객체를 논리적으로 그룹화하는 기능이 필요 없다면 구분 기호 / 이외의 다른 구분 기호를 사용하여 키의 각 부분을 구분
디렉터리 버킷의 경우 / 구분 기호가 특수하게 처리되므로 분명한 목적을 갖고 사용해야 합니다. 디렉터리 버킷은 객체를 사전순으로 정렬하지 않지만 디렉터리 내의 객체는 여전히 ListObjectsV2 출력에서 함께 그룹화됩니다. 이 기능이 필요하지 않다면 구분 기호 /를 다른 문자로 바꾸어 중간 디렉터리가 생성되지 않도록 할 수 있습니다.
예를 들어 다음 키가 YYYY/MM/DD/HH/ 접두사 패턴을 갖는다고 가정해 보겠습니다.
s3://my-bucket/2024/04/00/01/file1 s3://my-bucket/2024/04/00/02/file2 s3://my-bucket/2024/04/00/03/file3 s3://my-bucket/2024/04/01/01/file4 s3://my-bucket/2024/04/01/02/file5 s3://my-bucket/2024/04/01/03/file6
ListObjectsV2 결과에서 시간 또는 날짜별로 객체를 그룹화할 필요가 없지만 월별로 객체를 그룹화해야 하는 경우 다음과 같은 YYYY/MM/DD-HH- 키 패턴을 사용하면 ListObjectsV2 작업의 디렉터리가 크게 줄어들고 성능이 향상됩니다.
s3://my-bucket/2024/04/00-01-file1 s3://my-bucket/2024/04/00-01-file2 s3://my-bucket/2024/04/00-01-file3 s3://my-bucket/2024/04/01-02-file4 s3://my-bucket/2024/04/01-02-file5 s3://my-bucket/2024/04/01-02-file6
가능하면 구분 기호로 구분된 목록 작업 사용
delimiter가 없는 ListObjectsV2 요청은 모든 디렉터리에 대해 깊이 우선 재귀 탐색을 수행합니다. delimiter가 있는 ListObjectsV2 요청은 prefix 파라미터로 지정된 디렉터리의 항목만 검색하므로 요청 지연 시간이 줄고 초당 집계 키 수가 늘어납니다. 디렉터리 버킷의 경우 가능하면 구분 기호로 구분된 목록 작업을 사용하도록 합니다. 구분 기호로 목록을 구분하면 디렉터리 방문 횟수가 줄어들어 초당 키 수가 늘어나고 요청 지연 시간이 단축됩니다.
예를 들어 디렉터리 버킷에 다음 디렉터리 및 객체가 있다고 해보겠습니다.
s3://my-bucket/2024/04/12-01-file1 s3://my-bucket/2024/04/12-01-file2 ... s3://my-bucket/2024/05/12-01-file1 s3://my-bucket/2024/05/12-01-file2 ... s3://my-bucket/2024/06/12-01-file1 s3://my-bucket/2024/06/12-01-file2 ... s3://my-bucket/2024/07/12-01-file1 s3://my-bucket/2024/07/12-01-file2 ...
ListObjectsV2 성능 향상을 위해 애플리케이션의 로직에서 허용하는 경우 구분 기호로 구분된 목록을 사용하여 하위 디렉터리와 객체를 나열합니다. 예를 들어 구분 기호로 구분된 목록 작업을 위해 다음 명령을 실행할 수 있습니다.
aws s3api list-objects-v2 --bucket my-bucket --prefix '2024/' --delimiter '/'
출력은 하위 디렉터리 목록입니다.
{ "CommonPrefixes": [ { "Prefix": "2024/04/" }, { "Prefix": "2024/05/" }, { "Prefix": "2024/06/" }, { "Prefix": "2024/07/" } ] }
더 나은 성능으로 각 하위 디렉터리를 나열하려면 다음 예시와 같은 명령을 실행할 수 있습니다.
명령:
aws s3api list-objects-v2 --bucket my-bucket --prefix '2024/04' --delimiter '/'
출력:
{ "Contents": [ { "Key": "2024/04/12-01-file1" }, { "Key": "2024/04/12-01-file2" } ] }
S3 Express One Zone 스토리지를 컴퓨팅 리소스와 같은 위치에 배치
S3 Express One Zone을 사용하면 각 디렉터리 버킷이 버킷을 생성할 때 선택한 단일 가용 영역에 위치하게 됩니다. 컴퓨팅 워크로드 또는 리소스와 같은 위치의 로컬 가용 영역에 새 디렉터리 버킷을 생성하여 시작할 수 있습니다. 그러면 지연 시간이 매우 짧은 읽기 및 쓰기를 즉시 시작할 수 있습니다. 디렉터리 버킷은 컴퓨팅과 스토리지 간의 지연 시간을 줄이기 위해 AWS 리전 내에서 가용 영역을 선택할 수 있는 S3 버킷 유형입니다.
서로 다른 가용 영역에서 디렉터리 버킷에 액세스하는 경우 지연 시간이 약간 늘어날 수 있습니다. 성능을 최적화하려면 가능하면 동일한 가용 영역에 있는 Amazon Elastic Container Service, Amazon Elastic Kubernetes Service 및 Amazon Elastic Compute Cloud 인스턴스에서 디렉터리 버킷에 액세스하는 것이 좋습니다.
1MB가 넘는 객체의 경우 높은 처리량을 달성하기 위해 동시 연결 사용
디렉터리 버킷으로 여러 건의 동시 요청을 보내 요청을 별도의 연결로 분산하여 액세스 가능한 대역폭을 극대화함으로써 최상의 성능을 달성할 수 있습니다. 범용 버킷과 마찬가지로 S3 Express One Zone은 디렉터리 버킷에 대한 연결 수 제한이 없습니다. 개별 디렉터리는 동일한 디렉터리에 많은 수의 동시 쓰기가 발생하는 경우 성능을 수평적으로 자동 확장할 수 있습니다.
디렉터리 버킷에 대한 개별 TCP 연결에는 초당 업로드하거나 다운로드할 수 있는 바이트 수의 상한이 고정되어 있습니다. 객체가 커지면 요청 시간이 트랜잭션 처리가 아닌 바이트 스트리밍에 좌우됩니다. 여러 연결을 사용하여 더 큰 객체의 업로드 또는 다운로드를 병렬화하려면 엔드투엔드 지연 시간을 줄일 수 있습니다. Java 2.x SDK를 사용하는 경우 멀티파트 업로드 API 작업 및 바이트 범위 가져오기와 같은 성능 향상 기능을 활용하여 데이터에 병렬로 액세스하는 S3 Transfer Manager를 사용하는 것이 좋습니다.
게이트웨이 VPC 엔드포인트 사용
게이트웨이 엔드포인트를 사용하면 VPC에 대한 인터넷 게이트웨이 또는 NAT 디바이스 없이 VPC에서 디렉터리 버킷으로 직접 연결할 수 있습니다. 패킷이 네트워크에서 소비하는 시간을 줄이기 위해 디렉터리 버킷에 게이트웨이 VPC 엔드포인트를 사용하여 VPC를 구성해야 합니다. 자세한 내용은 디렉터리 버킷에 대한 네트워킹 섹션을 참조하세요.
세션 인증 사용 및 유효한 기간 동안 세션 토큰 재사용
디렉터리 버킷은 성능에 민감한 API 작업의 지연 시간을 줄이기 위해 세션 토큰 인증 메커니즘을 제공합니다. CreateSession을 한 번 직접적으로 호출하여 세션 토큰을 얻을 수 있으며, 이 토큰은 이후 5분 동안 모든 요청에 유효합니다. API 직접 호출에서 지연 시간을 최소화하려면 세션 토큰을 획득하여 해당 토큰의 전체 수명 동안 재사용한 후 새로 고쳐야 합니다.
AWS SDK를 사용하면 SDK가 세션 토큰 새로 고침을 자동으로 처리하여 세션이 만료될 때 서비스가 중단되지 않도록 합니다. AWS SDK를 사용하여 CreateSession API 작업에 대한 요청을 시작하고 관리하는 것이 좋습니다.
CreateSession에 대한 자세한 정보는 CreateSession을 사용하여 영역 엔드포인트 API 작업 권한 부여 섹션을 참조하세요.
CRT 기반 클라이언트 사용
AWS 공통 런타임(CRT)은 C 언어로 작성된 모듈식의 고성능 고효율 라이브러리 세트로, AWS SDK의 기반 역할을 합니다. CRT를 사용하면 처리량이 증가하고, 연결 관리가 향상되며, 시작 시간이 단축됩니다. CRT는 Go를 제외한 모든 AWS SDK에서 사용할 수 있습니다.
사용하는 SDK에 CRT를 구성하는 방법에 대한 자세한 내용은 AWS 공통 런타임(CRT) 라이브러리, Accelerate Amazon S3 throughput with the AWS Common Runtime
최신 AWS SDK 버전 사용
AWS SDK는 Amazon S3 성능을 최적화하기 위한 다양한 권장 지침을 기본적으로 지원합니다. SDK는 애플리케이션 내에서 Amazon S3를 활용할 수 있는 더 간단한 API를 제공하며 최신 모범 사례를 따르기 위해 정기적으로 업데이트됩니다. 예를 들어 SDK는 HTTP 503 오류 후 요청을 자동으로 재시도하고 느린 연결 응답을 처리합니다.
Java 2.x SDK를 사용하는 경우 S3 Transfer Manager를 사용하는 것이 좋습니다. S3 Transfer Manager는 필요에 따라 바이트 범위 요청을 사용하여 초당 수천 개의 요청을 처리할 수 있도록 연결 규모를 수평적으로 자동 조정합니다. 바이트 범위 요청은 S3에 대한 동시 연결을 사용하여 동일한 객체 내에서 다양한 바이트 범위를 가져올 수 있으므로 성능을 향상시킬 수 있습니다. 그러면 전체 객체 요청 한 건에 비해 집계 처리량을 높일 수 있습니다. 최신 성능 최적화 기능을 활용하려면 최신 버전의 AWS SDK를 사용하는 것이 중요합니다.
성능 문제 해결
지연 시간에 민감한 애플리케이션에 재시도 요청을 설정하고 있나요?
S3 Express One Zone은 추가 조정 없이 일관된 수준의 고성능을 제공하도록 특별히 설계되었습니다. 하지만 제한 시간 값과 재시도를 적극적으로 설정하면 지연 시간과 성능을 일관되게 유지하는 데 도움이 될 수 있습니다. AWS SDK에는 특정 애플리케이션의 허용 오차에 따라 튜닝할 수 있는 구성 가능한 제한 시간 및 재시도 값이 있습니다.
AWS 공통 런타임(CRT) 라이브러리와 최적의 Amazon EC2 인스턴스 유형을 사용하고 있나요?
다수의 읽기 및 쓰기 작업을 수행하는 애플리케이션은 그렇지 않은 애플리케이션보다 메모리 또는 컴퓨팅 용량이 훨씬 더 많이 필요합니다. 성능이 요구되는 워크로드를 위해 Amazon Elastic Compute Cloud(Amazon EC2) 인스턴스를 시작할 때는 애플리케이션에 필요한 만큼의 리소스를 포함하는 인스턴스 유형을 선택하세요. S3 Express One Zone 고성능 스토리지는 고성능 스토리지의 이점을 활용할 수 있는 더 큰 용량의 시스템 메모리와 더 강력한 CPU 및 GPU를 갖춘 더 큰 신규 인스턴스 유형과 함께 사용하는 것이 이상적입니다. 또한 읽기 및 쓰기 요청을 병렬로 더 빠르게 처리할 수 있는 최신 버전의 CRT 지원 AWS SDK를 사용하는 것이 좋습니다.
세션 기반 인증에 AWS SDK를 사용하고 있나요?
Amazon S3를 사용하면 AWS SDK의 일부 모범 사례와 동일한 모범 사례를 따라 HTTP REST API 요청을 사용할 때 성능을 최적화할 수 있습니다. 하지만 S3 Express One Zone에서 사용하는 세션 기반 권한 부여 및 인증 메커니즘을 사용하면 AWS SDK를 사용하여 CreateSession 및 관리형 세션 토큰을 관리하는 것이 좋습니다. AWS SDK는 CreateSession API 작업을 사용하여 사용자를 대신하여 자동으로 토큰을 생성하고 새로 고칩니다. CreateSession을 사용하면 각 요청을 승인하는 데 필요한 AWS Identity and Access Management(IAM)로의 요청당 왕복 지연 시간을 줄일 수 있습니다.
디렉터리 버킷 작업 및 디렉터리 상호 작용 예시
다음은 디렉터리 버킷의 작동 방식에 대한 세 가지 예시입니다.
예시 1: 디렉터리 버킷에 대한 S3 PutObject 요청이 디렉터리와 상호 작용하는 방식
-
빈 버킷에서
PUT(<bucket>, "documents/reports/quarterly.txt")작업을 실행하면 버킷 루트 내에documents/디렉터리가 생성되고,documents/내에reports/디렉터리가 생성되며,reports/내에quarterly.txt객체가 생성됩니다. 이 작업의 경우 객체 외에 두 개의 디렉터리가 생성되었습니다.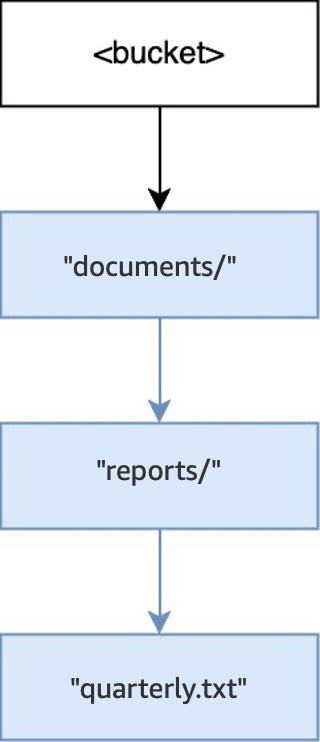
-
그런 다음 또 다른 작업
PUT(<bucket>, "documents/logs/application.txt")가 실행되면documents/디렉터리는 이미 존재하고,documents/내의logs/디렉터리는 존재하지 않고 새로 생성되며,logs/디렉터리 내에application.txt객체가 생성됩니다. 이 작업의 경우 객체 외에 하나의 디렉터리만 생성되었습니다.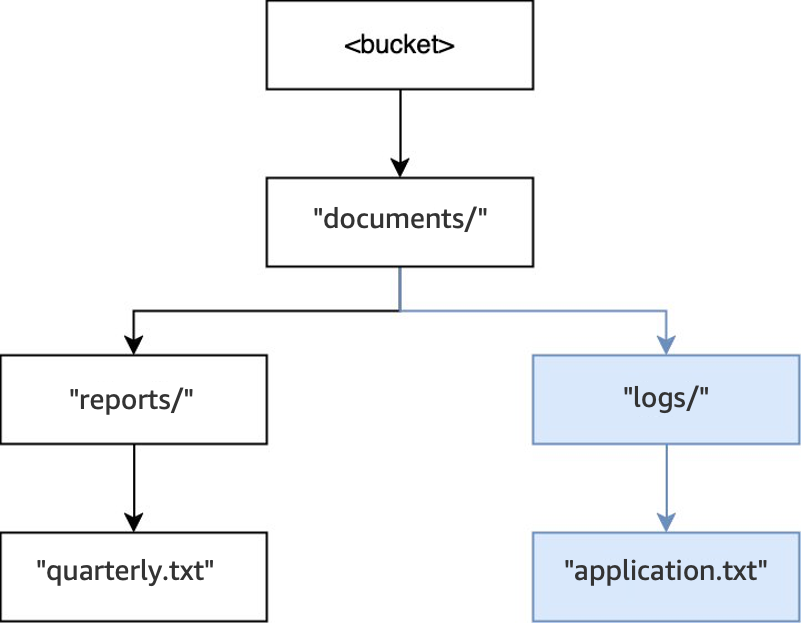
-
마지막으로,
PUT(<bucket>, "documents/readme.txt")작업이 실행되면 루트 내의documents/디렉터리가 이미 존재하고readme.txt객체가 생성됩니다. 이 작업의 경우 디렉터리가 생성되지 않습니다.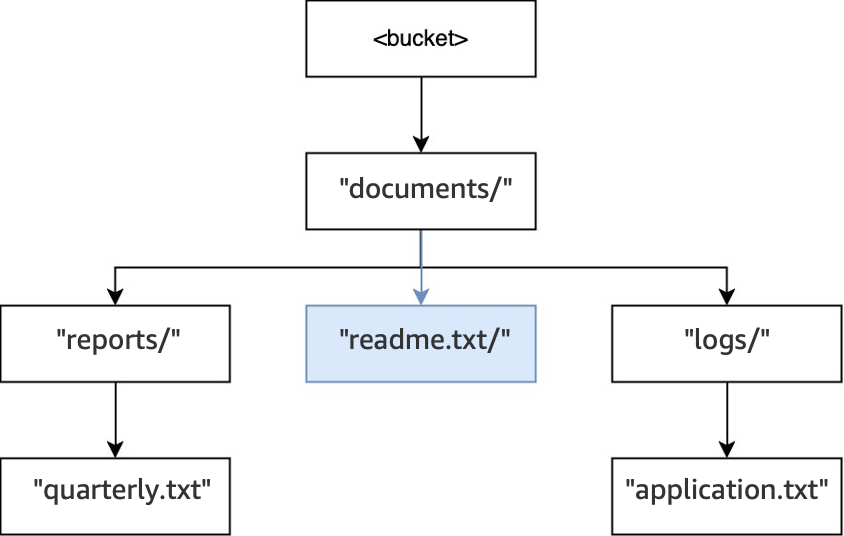
예시 2: 디렉터리 버킷에 대한 S3 ListObjectsV2 요청이 디렉터리와 상호 작용하는 방식
구분 기호를 지정하지 않은 S3 ListObjectsV2 요청의 경우 버킷은 깊이 우선 방식으로 탐색됩니다. 출력은 일관된 순서로 반환됩니다. 그러나 이 순서는 요청 간에 동일하게 유지되지만 사전식 순서는 아닙니다. 이전 예시에서 생성된 버킷 및 디렉터리의 경우 다음과 같습니다.
-
LIST(<bucket>)가 실행되면documents/디렉터리로 이동하고 탐색이 시작됩니다. -
하위 디렉터리
logs/로 이동하고 탐색이 시작됩니다. -
logs/에서application.txt객체가 발견됩니다. -
logs/에 더 이상 항목이 없습니다. List 작업이logs/에서 나와documents/로 다시 이동합니다. -
documents/디렉터리 탐색이 계속되고readme.txt객체가 발견됩니다. -
documents/디렉터리는 계속 탐색되고 하위 디렉터리reports/로 이동하며 탐색이 시작됩니다. -
reports/에서quarterly.txt객체가 발견됩니다. -
reports/에 더 이상 항목이 없습니다. List가reports/에서 나와documents/로 다시 이동합니다. -
documents/에 더 이상 항목이 없으므로 List가 반환됩니다.
이 예시에서, logs/가 readme.txt보다 앞 순서이고, readme.txt가 reports/보다 앞 순서입니다.
예시 3: 디렉터리 버킷에 대한 S3 DeleteObject 요청이 디렉터리와 상호 작용하는 방식
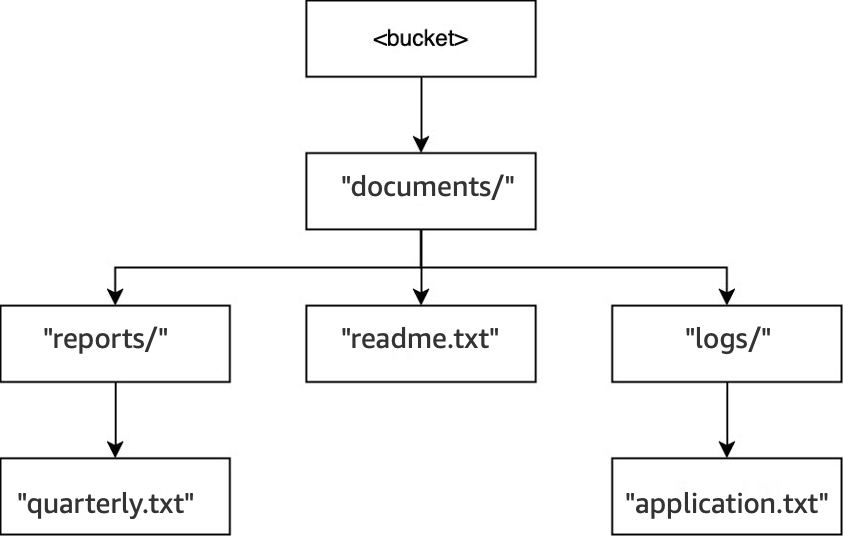
-
동일한 버킷에서
DELETE(<bucket>, "documents/reports/quarterly.txt")작업이 실행되면quarterly.txt객체가 삭제되어reports/디렉터리가 비어 있게 되고 즉시 삭제됩니다.documents/디렉터리는logs/디렉터리와readme.txt객체를 모두 포함하며 비어 있지 않으므로 삭제되지 않습니다. 이 작업의 경우 객체 하나와 디렉터리 하나만 삭제되었습니다.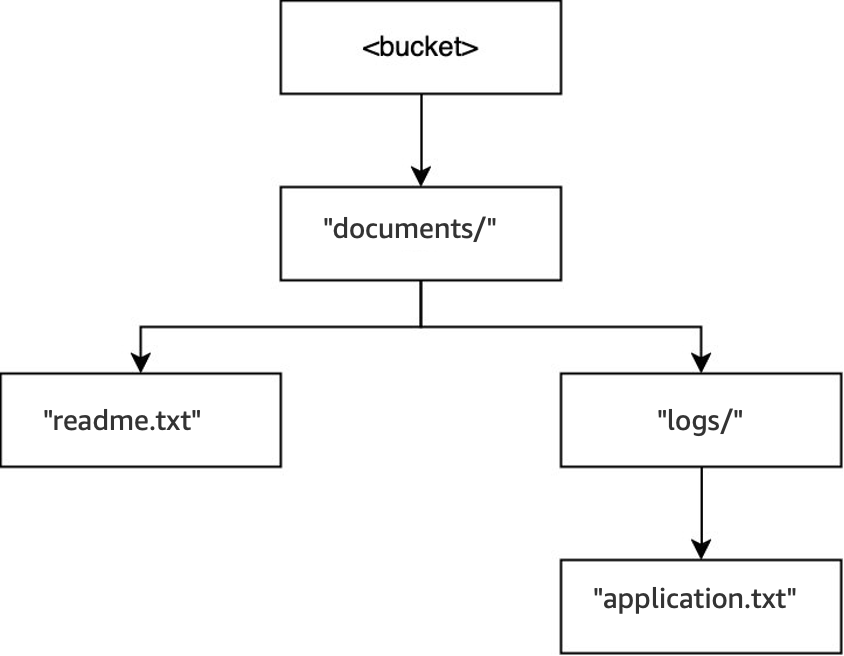
-
DELETE(<bucket>, "documents/readme.txt")작업이 실행되면readme.txt객체가 삭제됩니다.documents/는logs/디렉터리를 포함하며 비어 있지 않으므로 삭제되지 않습니다. 이 작업의 경우 디렉터리는 삭제되지 않으며 객체만 삭제됩니다.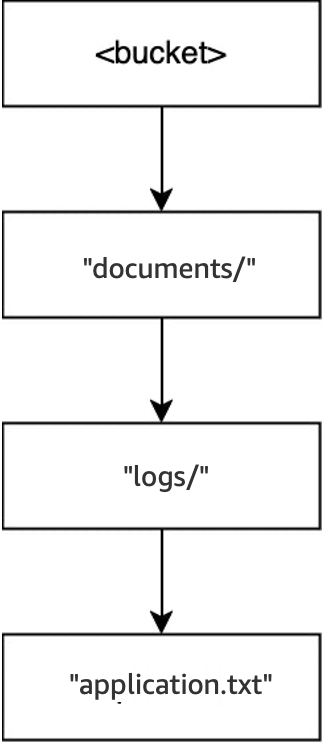
-
마지막으로,
DELETE(<bucket>, "documents/logs/application.txt")작업이 실행되면application.txt가 삭제되어logs/가 비어 있게 되고 즉시 삭제됩니다. 그러면documents/도 비어 있게 되어 즉시 삭제됩니다. 이 작업의 경우 디렉터리 두 개와 객체 한 개가 삭제됩니다. 이제 버킷이 비어 있습니다.
