기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon Bedrock Agents의 작동 방식
Amazon Bedrock Agents는 에이전트를 설정하고 실행하는 데 도움이 되는 다음과 같은 두 가지 주요 API 작업 세트로 구성됩니다.
-
에이전트 및 관련 리소스를 생성, 구성 및 관리하는 빌드 타임 API 작업
-
에이전트에 사용자 입력을 간접 호출하고 오케스트레이션을 시작하여 작업을 수행하는 런타임 API 작업
빌드 타임 구성
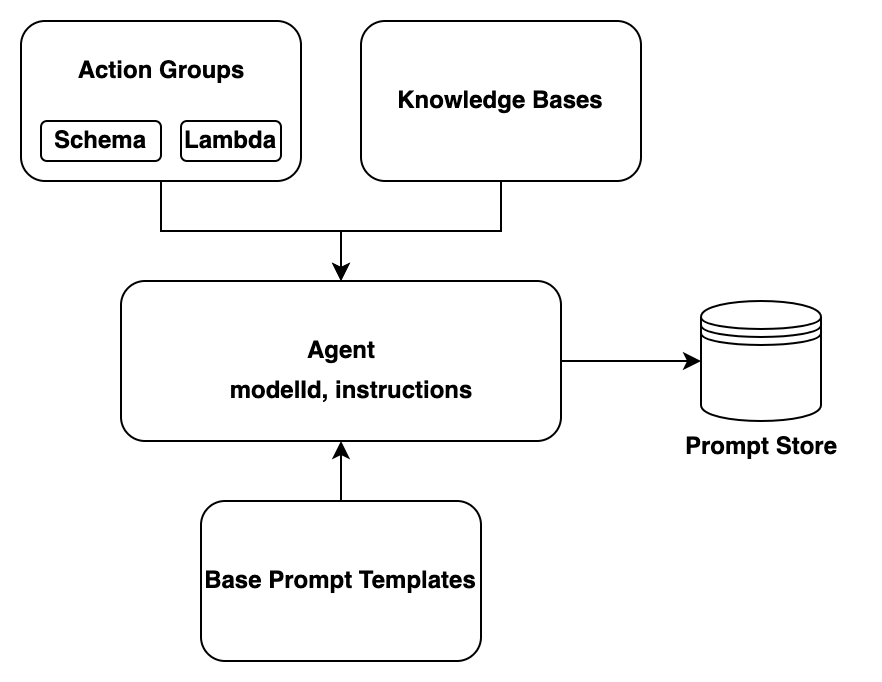
에이전트는 다음 구성 요소로 이뤄져 있습니다.
-
파운데이션 모델 - 에이전트가 오케스트레이션 프로세스에서 사용자 입력 및 후속 프롬프트를 해석하기 위해 간접적으로 호출할 파운데이션 모델(FM)을 선택합니다. 또한 에이전트는 FM을 간접 호출하여 프로세스에서 응답 및 후속 단계를 생성합니다.
-
지침 - 에이전트의 용도를 설명하는 지침을 작성합니다. 고급 프롬프트를 사용하면 오케스트레이션의 모든 단계에서 에이전트에 대한 지침을 추가로 사용자 지정하고 각 단계의 출력을 구문 분석하는 Lambda 함수를 포함할 수 있습니다.
-
다음 중 최소 하나 이상을 지정해야 합니다.
-
작업 그룹 - 에이전트가 사용자에 대해 수행해야 하는 작업을 정의합니다(다음 리소스 제공).
-
에이전트가 사용자로부터 유도해야 하는 파라미터를 정의하기 위한 다음 스키마 중 하나(각 작업 그룹은 서로 다른 스키마를 사용할 수 있음):
-
에이전트가 작업을 수행하기 위해 간접적으로 호출할 수 있는 API를 정의하는 OpenAPI 스키마. OpenAPI 스키마에는 사용자로부터 유도해야 하는 파라미터가 포함됩니다.
-
에이전트가 사용자로부터 유도할 수 있는 파라미터를 정의하는 함수 세부 정보 스키마입니다. 이후에 이러한 파라미터를 에이전트의 추가 오케스트레이션에 사용하거나 사용자의 애플리케이션에서 파라미터를 사용할 방법을 설정할 수 있습니다.
-
-
(선택 사항) 다음 입력 및 출력을 갖는 Lambda 함수:
-
입력 - 오케스트레이션 중에 식별된 API 및/또는 파라미터.
-
출력 - API 간접 호출의 응답 또는 함수 간접 호출의 응답.
-
-
-
지식 기반 - 지식 기반을 에이전트에 연결합니다. 에이전트는 추가 컨텍스트에 대해 지식 기반을 쿼리하여 응답 생성 및 오케스트레이션 프로세스의 단계에 대한 입력을 강화합니다.
-
-
프롬프트 템플릿 - 프롬프트 템플릿은 FM에 제공할 프롬프트를 생성하는 기반입니다. Amazon Bedrock Agents는 사전 처리, 오케스트레이션, 지식 기반 응답 생성 및 사후 처리 중에 사용되는 기본 기반 프롬프트 템플릿을 제공합니다. 필요한 경우 이러한 기본 프롬프트 템플릿을 편집하여 시퀀스의 각 단계에서 에이전트의 동작을 사용자 지정할 수 있습니다. 문제 해결을 위해 또는 어떤 단계가 불필요하다고 결정하는 경우에는 해당 단계를 뺄 수도 있습니다. 자세한 내용은 Amazon Bedrock의 고급 프롬프트 템플릿을 사용하여 에이전트의 정확도 향상 섹션을 참조하세요.
빌드 타임에는 이러한 모든 구성 요소를 수집하여 에이전트가 사용자 요청이 완료될 때까지 오케스트레이션을 수행할 수 있도록 기본 프롬프트를 구성합니다. 고급 프롬프트를 사용하면 추가 로직과 간단한 예제를 사용하여 이러한 기본 프롬프트를 수정함으로써 에이전트 간접 호출의 각 단계에 대한 정확도를 높일 수 있습니다. 기본 프롬프트 템플릿에는 지침, 작업 설명, 지식 기반 설명 및 대화 기록이 포함되어 있으며, 필요에 따라 에이전트를 수정하도록 사용자 지정할 수 있습니다. 그런 다음 에이전트를 준비하여 보안 구성을 포함한 에이전트의 모든 구성 요소를 패키징합니다. 에이전트를 준비하면 런타임에서 테스트할 수 있는 상태가 됩니다. 다음 이미지는 빌드 타임 API가 에이전트를 구성하는 방법을 보여줍니다.
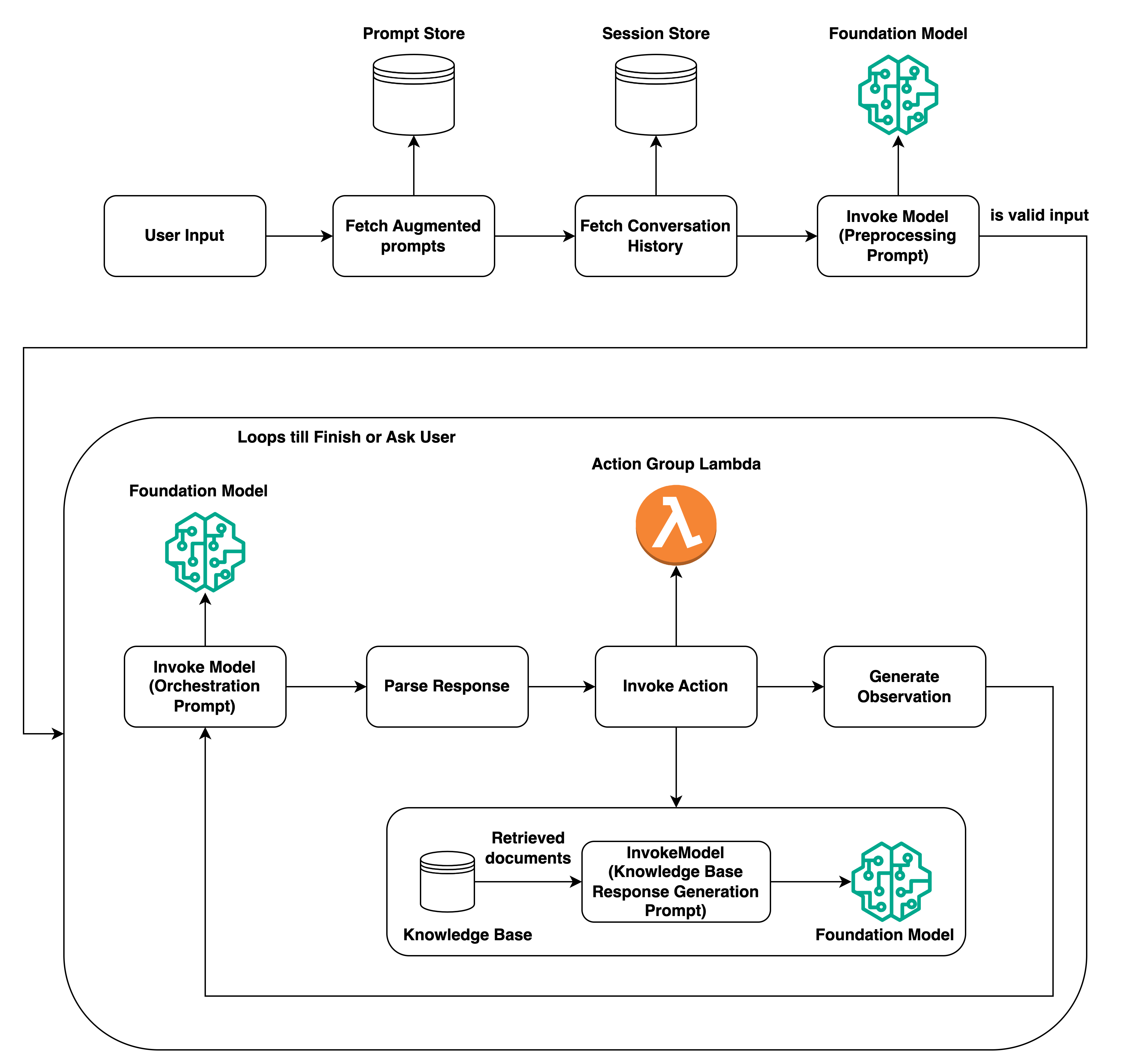
런타임 프로세스
런타임은 InvokeAgent API 작업에 의해 관리됩니다. 이 작업은 다음 세 가지 주요 단계로 구성된 에이전트 시퀀스를 시작합니다.
-
사전 처리 - 에이전트가 사용자 입력을 컨텍스트화하고 분류하는 방법과 입력이 유효한지 여부를 관리합니다.
-
오케스트레이션 - 사용자 입력을 해석하고, 작업 그룹을 간접적으로 호출하고, 지식 기반을 쿼리하고, 출력을 사용자에게 반환하거나 지속적인 오케스트레이션을 위한 입력으로 반환합니다. 오케스트레이션은 다음과 같은 단계로 구성됩니다.
-
에이전트는 파운데이션 모델을 사용하여 입력을 해석하고 취해야 할 다음 단계를 위한 논리를 제시하는 근거를 생성합니다.
-
에이전트는 간접적으로 호출해야 하는 작업 그룹의 작업 또는 쿼리해야 하는 지식 기반을 예측합니다.
-
에이전트가 작업을 간접적으로 호출해야 한다고 예측한 경우, 에이전트는 사용자 프롬프트에서 결정된 파라미터를 작업 그룹에 대해 구성된 Lambda 함수로 보내거나 InvokeAgent 응답의 파라미터를 보내 제어를 반환합니다. 에이전트에 작업을 간접적으로 호출할 정보가 충분하지 않은 경우, 에이전트는 다음 작업 중 하나를 수행할 수 있습니다.
-
연결된 지식 기반(지식 기반 응답 생성)을 쿼리하여 추가 컨텍스트를 검색하고 데이터를 요약하여 생성을 강화합니다.
-
작업에 필요한 모든 파라미터를 수집하도록 사용자를 다시 프롬프팅합니다.
-
-
에이전트는 작업을 간접적으로 호출하거나 지식 기반의 결과를 요약하여 관찰이라는 출력을 생성합니다. 에이전트는 관찰을 사용하여 기본 프롬프트를 보강한 다음 파운데이션 모델을 통해 이를 해석합니다. 그런 다음 에이전트는 오케스트레이션 프로세스를 반복해야 하는지 여부를 결정합니다.
-
이 루프는 에이전트가 사용자에게 응답을 반환할 준비가 될 때까지 또는 사용자에게 추가 정보를 요청해야 할 때까지 계속됩니다.
오케스트레이션 중에는 에이전트에 추가한 에이전트 지침, 작업 그룹, 지식 기반이 기본 프롬프트 템플릿에 추가됩니다. 그런 다음 보강된 기본 프롬프트를 사용하여 FM을 간접적으로 호출합니다. FM은 사용자 입력을 충족하기 위해 가능한 최상의 단계와 궤적을 예측합니다. FM은 오케스트레이션을 반복할 때마다 간접적으로 호출할 API 작업 또는 쿼리할 지식 기반을 예측합니다.
-
-
사후 처리 - 에이전트가 최종 응답을 포맷하여 사용자에게 반환합니다. 이 단계는 기본적으로 꺼져 있습니다.
에이전트를 간접적으로 호출할 때 런타임에 추적을 켤 수 있습니다. 추적을 사용하면 에이전트 시퀀스의 각 단계에서 에이전트의 이론적 근거, 작업, 쿼리 및 관찰을 추적할 수 있습니다. 추적에는 각 단계에서 파운데이션 모델에 전송된 전체 프롬프트와 파운데이션 모델의 출력, API 응답 및 지식 기반 쿼리가 포함됩니다. 추적을 사용하여 각 단계에서 에이전트의 추론을 이해할 수 있습니다. 자세한 내용은 trace를 사용하여 에이전트의 단계별 추론 프로세스 추적 섹션을 참조하세요.
더 많은 InvokeAgent 요청을 통해 에이전트와의 사용자 세션이 계속 진행되면서 대화 기록이 보존됩니다. 대화 기록은 컨텍스트를 통해 오케스트레이션 기본 프롬프트 템플릿을 지속적으로 강화하여 에이전트의 정확도와 성능을 개선합니다. 다음 다이어그램은 런타임 중 에이전트의 프로세스를 보여줍니다.