기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
첫 번째 AWS DeepRacer 모델 훈련
이 안내에서는 AWS DeepRacer 콘솔을 사용하여 첫 번째 모델을 훈련시키는 방법을 보여줍니다.
AWS DeepRacer 콘솔을 사용하여 강화 훈련 모델을 훈련하려면
모델 훈련 과정을 시작하기 위해 AWS DeepRacer 콘솔에서 모델 생성 버튼을 어디에서 찾을 수 있는지 알아봅니다.
강화 훈련 모델을 훈련하려면
-
AWS DeepRacer를 처음 사용하는 경우, 서비스 랜딩 페이지에서 모델 생성을 선택하거나 기본 탐색 창의 강화 훈련 제목 아래에서 시작하기를 선택합니다.
-
강화 훈련 시작 페이지의 2단계: 모델 생성 아래에서 모델 생성을 선택합니다.
또는 기본 탐색 창의 강화 훈련 제목에서 모델을 선택합니다. Your models(모델) 페이지에서 모델 생성을 선택합니다.
모델 이름과 환경을 지정하십시오.
모델 이름을 지정하고 자신에게 적합한 시뮬레이션 트랙을 선택하는 방법을 알아봅니다.
모델 이름 및 환경 지정하기
-
모델 생성 페이지의 훈련 세부 정보에서 모델 이름을 입력합니다.
-
훈련 작업 설명을 추가할 수도 있습니다.
-
선택적 태그 추가에 대해 자세히 알아보려면 태그 지정 단원을 참조하십시오.
-
환경 시뮬레이션에서 AWS DeepRacer 에이전트의 훈련 환경으로 사용할 트랙을 선택합니다. 트랙 방향에서 시계 방향 또는 시계 반대방향을 선택합니다. 그리고 다음을 선택합니다.
첫 번째 달리기의 경우 간단한 모양과 부드러운 회전이 가능한 트랙을 선택합니다. 나중에 반복할 때 더욱 복잡한 트랙을 선택하여 모델을 점진적으로 향상시킬 수 있습니다. 특정 레이싱 이벤트에 사용할 목적으로 모델을 훈련하려면 이벤트 트랙과 가장 유사한 트랙을 선택합니다.
-
페이지 하단에서 다음을 선택합니다.
레이스 유형과 훈련 알고리즘을 선택하십시오.
AWS DeepRacer 콘솔에는 세 가지 레이스 유형과 두 가지 훈련 알고리즘 중에서 선택할 수 있습니다. 기술 수준 및 훈련 목표에 적합한 것이 무엇인지 알아봅니다.
레이스 유형과 트레이닝 알고리즘을 선택하려면
-
모델 생성 페이지의 레이스 유형에서 타임 트라이얼, 장애물 회피 또는 헤드-투-봇을 선택합니다.
처음 실행할 때는 타임 트라이얼을 선택하는 것이 좋습니다. 이 레이스 유형에 맞게 에이전트의 센서 구성을 최적화하는 방법에 대한 지침은 타임 트라이얼을 위한 AWS DeepRacer 훈련 조정을 참조하십시오.
-
선택 사항으로 이후 실행에서는 장애물 회피를 선택하여 선택한 트랙을 따라 고정 또는 무작위 위치에 배치된 정지 장애물을 우회할 수 있습니다. 자세한 내용은 장애물 회피 레이스를 위한 AWS DeepRacer 훈련 조정 섹션을 참조하십시오.
-
트랙의 두 차선에 걸쳐 사용자가 지정한 고정된 위치에 상자를 생성하려면 고정 위치를 선택하고 훈련 시뮬레이션의 각 에피소드가 시작될 때 두 차선에 걸쳐 무작위로 분포된 장애물을 생성하려면 무작위 위치를 선택합니다.
-
다음으로, 트랙에 있는 장애물 수 값을 선택합니다.
-
고정 위치를 선택한 경우 트랙에서의 각 장애물 배치를 조정할 수 있습니다. 차선 배치의 경우 안쪽 차선과 바깥쪽 차선 중에서 선택합니다. 기본적으로 장애물은 트랙 전체에 고르게 분포됩니다. 장애물의 시작선과 결승선 사이의 거리를 변경하려면 시작과 끝 사이의 위치(%) 필드에 해당 거리의 7~90 사이의 백분율을 입력합니다.
-
-
선택 사항으로 좀 더 야심찬 레이스를 원한다면 헤드-투-봇 레이스를 선택하여 일정한 속도로 움직이는 최대 4대의 로봇 차량과 레이스할 수도 있습니다. 자세한 내용은 헤드-투-봇 레이스를 위한 AWS DeepRacer 훈련 조정을 참조하십시오.
-
로봇 차량 수 선택에서 에이전트가 훈련시킬 로봇 차량 수를 선택합니다.
-
다음으로 로봇 차량이 트랙을 돌아다닐 속도를 초당 밀리미터 단위로 선택합니다.
-
선택 사항으로 차선 변경 활성화 체크박스를 선택하여 로봇 차량이 1~5초마다 차선을 임의로 변경할 수 있도록 할 수 있습니다.
-
-
훈련 알고리즘 및 하이퍼파라미터에서 소프트 액터 크리틱(SAC) 또는 근접 정책 최적화(PPO) 알고리즘을 선택합니다. AWS DeepRacer 콘솔에서는 SAC 모델은 연속 행동 공간에서 훈련해야 합니다. PPO 모델은 연속 또는 이산 행동 공간에서 훈련할 수 있습니다.
-
모델 생성 페이지의 훈련 알고리즘 및 하이퍼파라미터에서 기본 하이퍼파라미터 값을 그대로 사용합니다.
나중에 훈련 성과를 향상시키려면 하이퍼파라미터를 확장하고 다음과 같이 기본 하이퍼파라미터 값을 수정합니다.
-
경사 하강 배치 크기에서 available options(사용 가능한 옵션)를 선택합니다.
-
에포크 수에서 valid value(유효 값)를 설정합니다.
-
학습 속도에서 valid value(유효 값)를 설정합니다.
-
SAC 알파 값(SAC 알고리즘만 해당)의 경우 유효한 값을 설정하십시오.
-
엔트로피에서 valid value(유효 값)를 설정합니다.
-
할인 계수에서 valid value(유효 값)를 설정합니다.
-
손실 유형에서 available options(사용 가능한 옵션)를 선택합니다.
-
각 정책 업데이트 반복 간 경험 에피소드 수에서 valid value(유효 값)를 설정합니다.
하이퍼파라미터에 대한 자세한 내용은 체계적인 하이퍼파라미터 튜닝 단원을 참조하십시오.
-
-
다음을 선택합니다.
행동 공간 정의
행동 공간 정의 페이지에서 소프트 액터 크리틱(SAC) 알고리즘으로 훈련하도록 선택한 경우 기본 행동 공간은 연속 행동 공간입니다. 근접 정책 최적화(PPO) 알고리즘으로 훈련하기로 선택한 경우 연속 작업 공간과 불연속 작업 공간 중에서 선택합니다. 각 행동 공간 및 알고리즘이 에이전트의 훈련 경험을 어떻게 형성하는지 자세히 알아보려면 AWS DeepRacer 행동 공간 및 보상 함수을 참조하십시오.
-
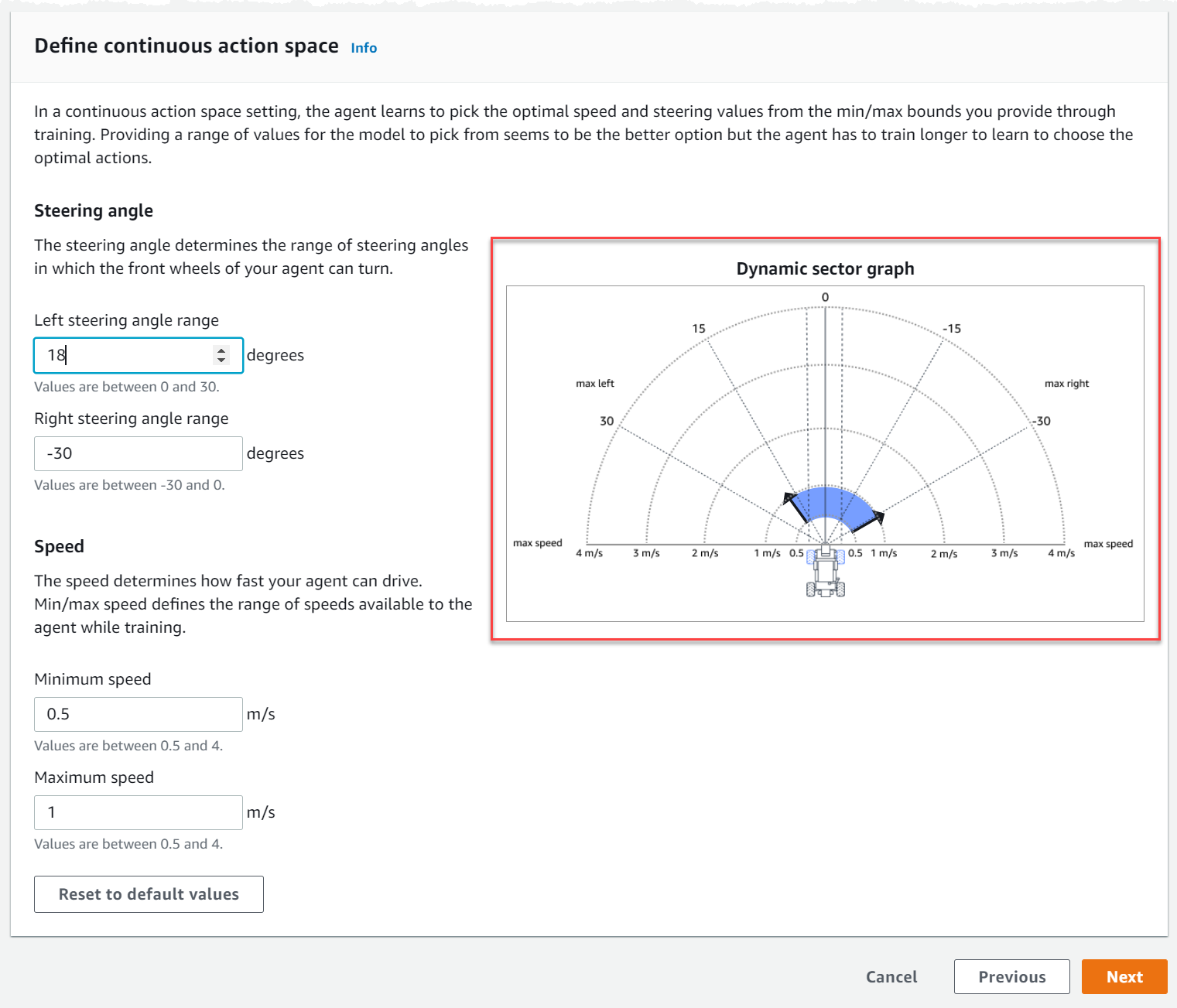
연속 행동 공간 정의에서 왼쪽 조향 각도 범위와 오른쪽 조향 각도 범위를 선택합니다.
각 조향 각도 범위에 대해 다른 각도를 입력하고 범위 변화를 시각화를 관찰하여 동적 섹터 그래프에 선택 사항을 표시해 봅니다.
-
속도에서 에이전트의 최소 및 최대 속도를 초당 밀리미터 단위로 입력합니다.
변경 사항이 동적 섹터 그래프에 어떻게 반영되는지 확인하십시오.
-
필요에 따라 기본값으로 재설정을 선택하여 원하지 않는 값을 지울 수 있습니다. 그래프에서 다양한 값을 시험해 보면서 실험하고 훈련해 보는 것이 좋습니다.
-
Next(다음)를 선택합니다.
-
드롭다운 목록에서 조향 각도 세분성 값을 선택합니다.
-
에이전트의 최대 조향 각도를 1~30 사이의 각도로 선택하십시오.
-
드롭다운 목록에서 속도 세분성 값을 선택합니다.
-
에이전트의 최대 속도 값을 0.1~4 사이의 초당 밀리미터 단위로 선택합니다.
-
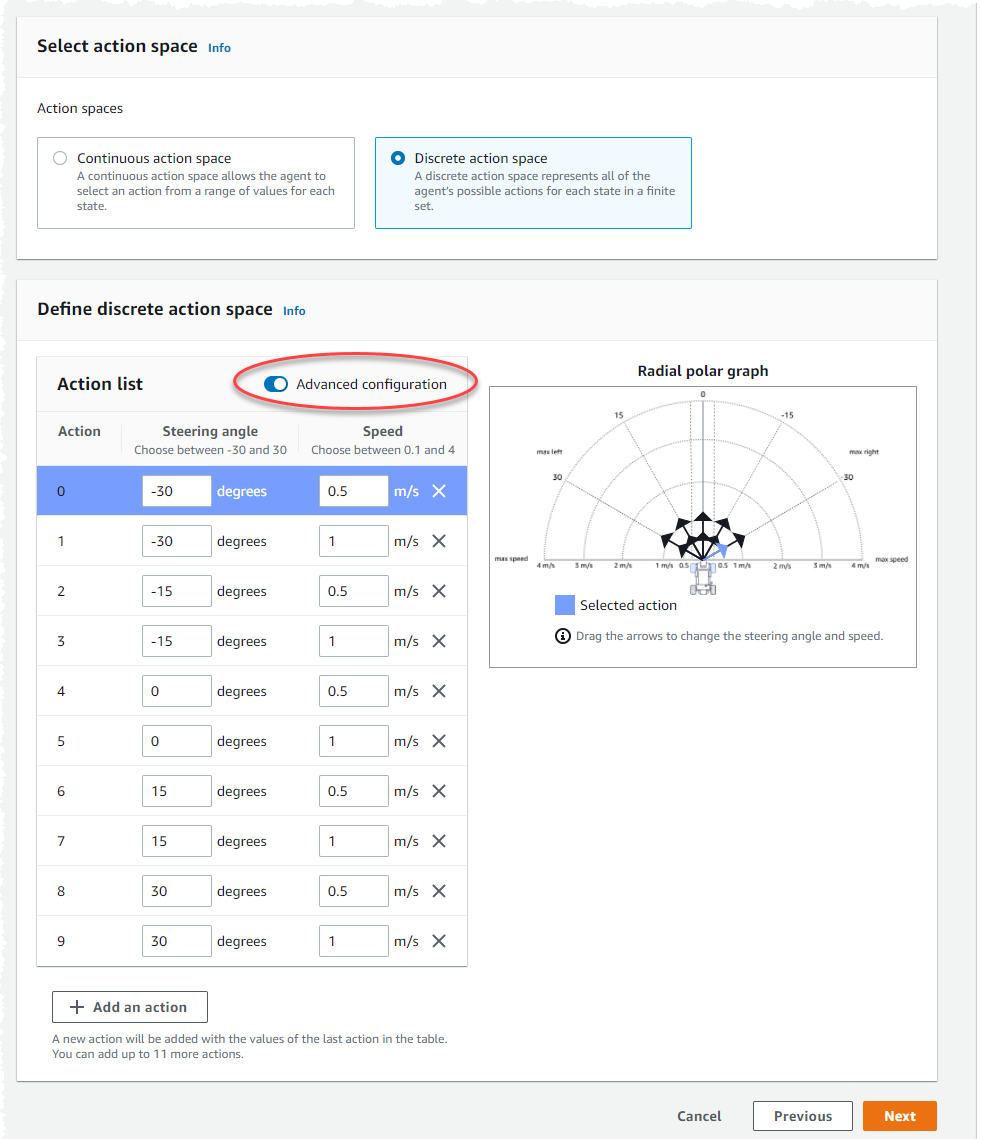
작업 목록의 기본 작업 설정을 사용하거나 선택적으로 고급 구성을 켜서 설정을 미세 조정할 수 있습니다. 값을 조정한 후 이전을 선택하거나 고급 구성을 끄면 변경 내용이 손실됩니다.
-
조향 각도 열에 -30도에서 30도 사이의 값을 입력합니다.
-
속도 열에 최대 9개의 동작에 대해 초당 0.1~4 밀리미터 사이의 값을 입력합니다.
-
선택 사항으로 작업 추가를 선택하여 작업 목록의 행 수를 늘릴 수도 있습니다.
-
필요에 따라 행에서 X를 선택하여 제거할 수도 있습니다.
-
-
Next(다음)를 선택합니다.
가상 자동차 선택
가상 자동차를 시작하는 방법을 알아봅니다. 매달 Open Division에서 경쟁하여 새로운 커스텀 자동차, 페인트 작업, 개조 작업을 획득하십시오.
가상 자동차를 선택하려면
-
차량 쉘 및 센서 구성 선택 페이지에서 레이스 유형 및 행동 공간과 호환되는 쉘을 선택하십시오. 차고에 해당 차량이 없는 경우, 기본 탐색 창의 강화 훈련 제목 아래에 있는 내 차고로 이동하여 새로 만드십시오.
타임 트라이얼 트레이닝의 경우 오리지널 DeepRacer의 기본 센서 구성과 단안 카메라만 있으면 되지만, 다른 모든 쉘 및 센서 구성은 행동 공간이 일치하기만 하면 작동합니다. 자세한 내용은 타임 트라이얼을 위한 AWS DeepRacer 훈련 조정 섹션을 참조하십시오.
장애물 회피 훈련에는 스테레오 카메라가 유용하지만 고정된 위치에 고정된 장애물을 피하는 데에 단일 카메라를 사용할 수 있습니다. LiDAR 센서는 선택 사항입니다. AWS DeepRacer 행동 공간 및 보상 함수 섹션을 참조하십시오.
헤드-투-봇 훈련의 경우 단일 카메라 또는 스테레오 카메라 외에도 LiDAR 장치는 움직이는 다른 차량을 추월하는 동안 사각지대를 감지하고 피하는 데 최적입니다. 자세한 내용은 헤드-투-봇 레이스를 위한 AWS DeepRacer 훈련 조정을 참조하십시오.
-
Next(다음)를 선택합니다.
보상 함수를 사용자 지정하십시오.
보상 함수는 강화 훈련의 핵심 부분입니다. 차량(에이전트)이 트랙(환경)을 탐색할 때 특정 조치를 취하도록 장려하는 데 이 기능을 사용하는 방법을 알아보십시오. 반려동물의 특정 행동을 장려하거나 억제하는 것과 마찬가지로 이 도구를 사용하여 자동차가 최대한 빨리 랩을 끝내고 트랙을 벗어나거나 물체와 충돌하지 않도록 할 수 있습니다.
보상 함수를 사용자 지정하려면
-
모델 생성 페이지의 보상 함수에서 첫 번째 모델에 대해 기본 보상 기능 예제를 그대로 사용합니다.
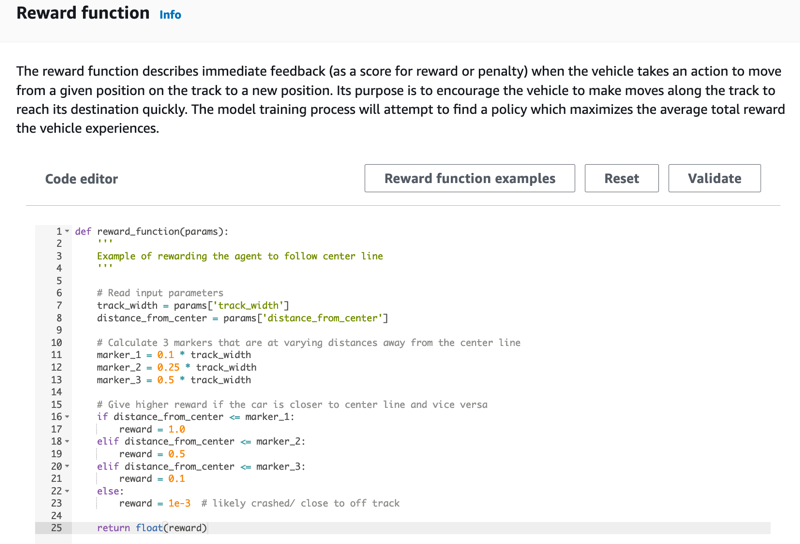
나중에 보상 함수 예제를 선택하여 다른 예제 함수를 선택한 다음 코드 사용를 선택하여 선택한 보상 함수를 수락할 수 있습니다.
시작할 수 있는 함수 예제는 4개입니다. 이들 함수는 트랙 중앙(기본값)을 따르는 방법, 에이전트를 트랙 경계 안에 유지하는 방법, 지그재그 주행을 방지하는 방법, 정지 장애물 또는 기타 이동 차량과 충돌을 방지하는 방법을 보여줍니다.
보상 함수에 대한 자세한 내용은 AWS DeepRacer 보상 함수 참조 단원을 참조하십시오.
-
중지 조건 아래에서 기본 최대 시간 값을 그대로 두거나 새 값을 설정해 훈련 작업을 종료하여 장기 실행(및 가능한 런어웨이) 훈련 작업을 방지합니다.
훈련 초기 단계에서 실험할 때는 이 파라미터를 작은 값으로 시작한 다음 점진적으로 훈련 시간을 늘려야 합니다.
-
AWS DeepRacer에 자동 제출에서는 훈련 완료 후 자동으로 이 모델을 AWS DeepRacer에 제출하고 상품을 받을 기회를 얻기 옵션이 기본적으로 선택되어 있습니다. 선택 사항으로, 체크 표시를 선택하여 모델 입력을 거부할 수도 있습니다.
-
리그 요구 사항에서 거주 국가를 선택하고 체크박스를 선택하여 이용 약관에 동의하십시오.
-
모델 생성 페이지에서 모델 생성을 선택하여 모델 생성 및 훈련 작업 인스턴스 프로비저닝을 시작합니다.
-
제출 후 훈련 작업이 초기화되는 것을 확인한 다음 실행합니다.
초기화 프로세스에서 초기화 중에서 진행 중으로 변경하는 데 몇 분 걸립니다.
-
보상 그래프 및 시뮬레이션 비디오 스트림을 시청하여 훈련 작업의 진행 상황을 관찰합니다. 훈련 작업이 완료될 때까지 보상 그래프 옆에 있는 새로 고침 버튼을 주기적으로 선택하여 보상 그래프를 새로 고칠 수 있습니다.
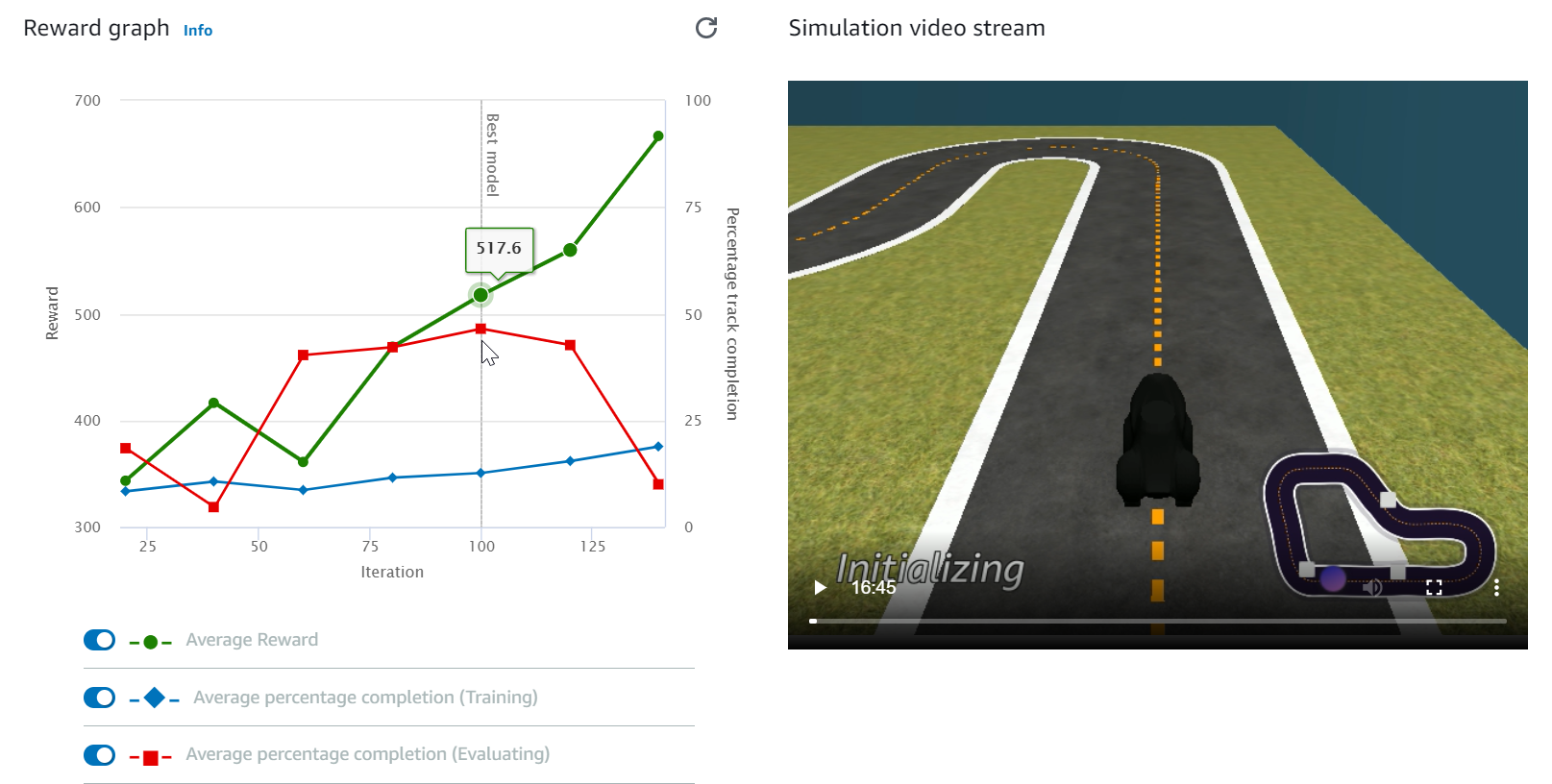
훈련 작업은 AWS 클라우드에서 실행되므로 AWS DeepRacer 콘솔을 열어 둘 필요가 없습니다. 그러나 작업이 진행되는 동안 언제든지 콘솔로 돌아와 모델을 확인할 수 있습니다.
시뮬레이션 비디오 스트림 창이나 보상 그래프 디스플레이가 응답하지 않는 경우 브라우저 페이지를 새로 고쳐 훈련 진행 상황을 업데이트합니다.
