기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
에 대한 모범 사례 AWS Database Migration Service
AWS Database Migration Service (AWS DMS)를 가장 효과적으로 사용하려면 데이터를 마이그레이션하는 가장 효율적인 방법에 대한이 섹션의 권장 사항을 참조하세요.
주제
AWS Database Migration Service마이그레이션 계획
를 사용하여 데이터베이스 마이그레이션을 계획할 때는 다음 사항을 AWS Database Migration Service고려하세요.
-
소스 및 대상 데이터베이스를 AWS DMS 복제 인스턴스에 연결하려면 네트워크를 구성합니다. 이 작업은 복제 인스턴스와 동일한 Virtual Private Cloud(VPC)에 있는 AWS 리소스 두 개를 연결하는 것만큼 간단할 수도 있고, 가상 프라이빗 네트워크(VPN)을 통해 온프레미스 데이터베이스를 Amazon RDS DB 인스턴스에 연결하는 등 더 복잡한 구성까지 다양할 수 있습니다. 자세한 내용은 데이터베이스 마이그레이션을 위한 네트워크 구성 단원을 참조하십시오.
-
소스 및 대상 엔드포인트 - 소스 데이터베이스의 어떤 정보와 테이블을 대상 데이터베이스로 마이그레이션해야 하는지 알아야 합니다.는 테이블 및 기본 키 생성을 포함한 기본 스키마 마이그레이션을 AWS DMS 지원합니다. 그러나는 대상 데이터베이스에 보조 인덱스, 외래 키, 사용자 계정 등을 자동으로 생성하지 AWS DMS 않습니다. 소스 및 대상 데이터베이스 엔진에 따라 소스 또는 대상 데이터베이스에 추가 로깅을 설정하거나 기타 설정을 수정해야 할 수 있습니다. 자세한 내용은 데이터 마이그레이션용 소스 및 마이그레이션에 적합한 대상 섹션을 참조하세요.
스키마 및 코드 마이그레이션 - 스키마 또는 코드 변환 AWS DMS 을 수행하지 않습니다. Oracle SQL Developer, MySQL Workbench, pgAdmin III와 같은 도구를 사용하여 스키마를 변환할 수 있습니다. 기존 스키마를 다른 데이터베이스 엔진으로 변환하려면 AWS Schema Conversion Tool ()를 사용할 수 있습니다AWS SCT. 대상 스키마를 생성하고 전체 스키마(테이블, 인덱스, 보기 등)을 생성할 수 있습니다. 또한 PL/SQL 또는 TSQL을 PgSQL 및 기타 형식으로 변환하는 도구를 사용할 수도 있습니다. 에 대한 자세한 내용은 AWS SCT 사용 설명서를 AWS SCT참조하세요.
지원되지 않는 데이터 형식 - 소스 데이터 형식을 대상 데이터베이스의 해당 데이터 형식으로 변환해야 합니다. 지원되는 데이터 형식에 대한 자세한 내용은 해당 데이터 스토어 설명서의 소스 또는 대상 섹션을 참조하세요.
-
진단 지원 스크립트 결과 - 마이그레이션을 계획할 때는 진단 지원 스크립트를 실행하는 것이 좋습니다. 이러한 스크립트의 결과를 통해 잠재적 마이그레이션 실패에 대한 사전 정보를 찾을 수 있습니다.
데이터베이스에 사용할 수 있는 지원 스크립트가 있는 경우 다음 단원의 해당 스크립트 주제에 있는 링크를 사용하여 다운로드하세요. 스크립트를 확인하고 검토한 후 로컬 환경에서 스크립트 주제에 설명된 절차에 따라 스크립트를 실행할 수 있습니다. 스크립트 실행이 완료되면 결과를 검토할 수 있습니다. 문제 해결의 첫 단계로 이러한 스크립트를 실행하는 것이 좋습니다. 결과는 AWS Support 팀과 함께 작업할 때 유용할 수 있습니다. 자세한 내용은 에서 진단 지원 스크립트 작업 AWS DMS 단원을 참조하십시오.
-
마이그레이션 전 평가 - 마이그레이션 전 평가는 데이터베이스 마이그레이션 태스크의 특정 구성 요소를 평가하여 마이그레이션 태스크가 예상대로 실행되는 데 방해가 될 수 있는 문제를 식별하는 데 도움이 됩니다. 이 평가를 사용하면 새 태스크 또는 수정된 태스크를 실행하기 전에 잠재적 문제를 식별할 수 있습니다. 마이그레이션 전 평가 작업에 대한 자세한 내용은 작업에 대한 마이그레이션 전 평가 활성화 및 활용 섹션을 참조하세요.
스키마 변환
AWS DMS 는 스키마 또는 코드 변환을 수행하지 않습니다. 기존 스키마를 다른 데이터베이스 엔진으로 변환하려는 경우를 사용할 수 있습니다 AWS SCT.는 소스 객체, 테이블, 인덱스, 뷰, 트리거 및 기타 시스템 객체를 대상 데이터 정의 언어(DDL) 형식으로 AWS SCT 변환합니다. AWS SCT 를 사용하여 PL/SQL 또는 TSQL과 같은 대부분의 애플리케이션 코드를 동등한 대상 언어로 변환할 수도 있습니다.
를 AWS SCT 에서 무료로 다운로드할 수 있습니다 AWS. 에 대한 자세한 내용은 AWS SCT 사용 설명서를 AWS SCT참조하세요.
소스 및 대상 엔드포인트가 동일한 데이터베이스 엔진인 경우 Oracle SQL Developer, MySQL Workbench 또는 PgAdmin4와 같은 도구를 사용하여 스키마를 이동 수 있습니다.
AWS DMS 공개 설명서 검토
첫 번째 마이그레이션 전에 소스 및 대상 엔드포인트에 대한 AWS DMS 공개 설명서 페이지를 살펴보는 것이 좋습니다. 이 설명서는 마이그레이션을 시작하기 전에 마이그레이션을 위한 사전 요구 사항을 식별하고 현재 제한 사항을 이해하는 데 도움이 될 수 있습니다. 자세한 내용은 AWS DMS 엔드포인트 작업 단원을 참조하십시오.
마이그레이션 중에 공개 설명서는 문제를 해결하는 데 도움이 될 수 있습니다 AWS DMS. 설명서의 페이지 문제를 해결하면 AWS DMS 및 선택한 엔드포인트 데이터베이스를 모두 사용하여 일반적인 문제를 해결하는 데 도움이 될 수 있습니다. 자세한 내용은 에서 마이그레이션 작업 문제 해결 AWS Database Migration Service 단원을 참조하십시오.
개념 증명 실행
데이터베이스 마이그레이션 초기 단계에서 환경 문제를 발견하는 데 도움이 되도록 소규모 테스트 마이그레이션을 실행하는 것이 좋습니다. 이렇게 하면 마이그레이션 일정을 보다 현실적으로 설정하는 데도 도움이 될 수 있습니다. 또한 전체 규모 테스트 마이그레이션을 실행하여가 네트워크를 통해 데이터베이스의 처리량을 처리할 AWS DMS 수 있는지 여부를 측정해야 할 수 있습니다. 이 동안에는 초기 전체 로드 및 지속적 복제를 벤치마킹하고 최적화하는 것이 좋습니다. 이렇게 하면 네트워크 지연 시간을 파악하고 전반적인 성능을 측정하는 데 도움이 될 수 있습니다.
또한 이 시점에서 다음을 포함하여 데이터 프로파일 및 데이터베이스 규모를 파악할 수 있습니다.
-
대형, 중형 및 소형 테이블의 수.
-
가 데이터 유형 및 문자 집합 변환을 AWS DMS 처리하는 방법.
-
대형 객체(LOB) 열이 있는 테이블의 수
-
테스트 마이그레이션을 실행하는 데 걸리는 시간.
AWS DMS 마이그레이션 성능 개선
AWS DMS 마이그레이션 성능에는 다음과 같은 여러 요인이 영향을 미칩니다.
소스의 리소스 가용성.
가용 네트워크 처리량.
복제 서버의 리소스 용량.
대상이 변경 사항을 수집하는 능력.
소스 데이터의 형식 및 분포.
마이그레이션할 객체의 수.
아래에 언급된 모범 사례 중 일부 또는 전부를 사용하여 성능을 개선할 수 있습니다. 이러한 방법을 사용할 수 있는지 여부는 구체적인 사용 사례에 따라 다릅니다. 다음과 같은 몇 가지 제한 사항을 확인할 수 있습니다.
- 적절한 복제 서버를 프로비저닝
-
AWS DMS 는 Amazon EC2 인스턴스에서 실행되는 관리형 서비스입니다. 이 서비스는 소스 데이터베이스에 연결하고, 소스 데이터를 읽고, 대상 데이터베이스에서 사용할 수 있도록 데이터 형식을 지정하고, 대상 데이터베이스에 데이터를 로드합니다.
이 절차 대다수는 메모리에서 진행됩니다. 그렇지만, 대규모 트랜잭션은 디스크에서 일부 버퍼링이 필요할 수 있습니다. 캐시된 트랜잭션과 로그 파일도 디스크에 기록됩니다. 다음 단원에서 복제 서버를 선택할 때 고려해야 할 사항을 확인할 수 있습니다.
- CPU
-
AWS DMS 는 이기종 마이그레이션을 위해 설계되었지만 동종 마이그레이션도 지원합니다. 동종 마이그레이션을 수행하려면 먼저 각 소스 데이터 유형을 동등한 AWS DMS 데이터 유형으로 변환합니다. 그런 다음 각 AWS DMS 형식 데이터를 대상 데이터 형식으로 변환합니다. AWS DMS 사용 설명서에서 각 데이터베이스 엔진의 이러한 변환에 대한 참조를 찾을 수 있습니다.
가 이러한 변환을 최적으로 수행 AWS DMS 하려면 변환이 발생할 때 CPU를 사용할 수 있어야 합니다. CPU에 과부하가 걸리고 CPU 리소스가 충분하지 않으면 마이그레이션 속도가 느려지고 다른 부작용도 발생할 수 있습니다.
- 복제 인스턴스 클래스
-
소형 인스턴스 클래스 중에는 서비스를 테스트하거나 소규모 마이그레이션을 하기에 충분한 것이 있습니다. 마이그레이션에 대량의 테이블이 포함되어 있는 경우 또는 여러 동시 복제 태스크를 실행해야 하는 경우, 대형 인스턴스 중 하나를 사용하는 것이 좋습니다. 서비스가 상당한 양의 메모리 및 CPU를 소비하기 때문에 더 큰 용량의 인스턴스를 사용하는 것이 좋습니다.
- AWS DMS R5 및 C5 인스턴스 클래스 지원
-
R5 인스턴스 클래스는 메모리에서 대규모 데이터를 처리하는 워크로드에 대해 빠른 성능을 제공하도록 설계된 메모리 최적화 인스턴스입니다. 를 사용하여 처리량이 많은 트랜잭션 시스템을 지속적으로 마이그레이션하거나 복제하면 때때로 많은 양의 CPU와 메모리를 소비 AWS DMS 할 수 있습니다. R5 인스턴스는 R4보다 vCPU당 5%의 추가 메모리를 제공하며 가장 큰 크기는 768GiB의 메모리를 제공합니다. 또한 R5 인스턴스는 R4에 비해 GiB당 가격이 10% 향상되고 CPU 성능이 최대 20% 향상되었습니다.
C5 인스턴스 클래스는 컴퓨팅 집약적 워크로드에 최적화되어 있으며 높은 컴퓨팅 가성비로 비용 효율적인 고성능을 제공합니다. 네트워크 성능이 크게 향상되었습니다. Elastic Network Adapter(ENA)는 Amazon EBS에 최대 25Gbps의 네트워크 대역폭과 최대 14Gbps의 전용 대역폭을 C5 인스턴스에 제공합니다. 특히 Oracle에서 PostgreSQL로 마이그레이션하는 것과 같은 이기종 마이그레이션 및 복제를 수행할 때 CPU 집약적일 AWS DMS 수 있습니다. C5 인스턴스는 이러한 상황에서 훌륭한 선택이 될 수 있습니다.
- 스토리지
-
인스턴스 클래스에 따라 복제 인스턴스에는 50GB 또는 100GB의 데이터 스토리지가 포함되어 있습니다. 이 스토리지는 로그 파일과 로드 중에 수집되는 캐시된 변경 사항을 저장하는 데 사용됩니다. 소스 시스템이 사용 빈도가 높거나 대규모 트랜잭션을 처리하는 경우 스토리지를 늘려야 할 수 있습니다. 복제 서버에서 여러 태스크를 실행하는 경우 스토리지를 늘려야 할 수도 있습니다. 하지만 일반적으로 기본 용량으로도 충분합니다.
의 모든 스토리지 볼륨 AWS DMS 은 GP2 또는 범용 SSD(SSDs. GP2 볼륨의 기본 성능은 3IOPS(초당 I/O 작업)이며 크레딧 기준으로 최대 3,000IOPS까지 버스트할 수 있습니다. 경험상 복제 인스턴스의
ReadIOPS및WriteIOPS지표를 확인하는 것이 좋습니다. 이러한 값의 합계가 해당 볼륨의 기본 성능을 초과하지 않는지 확인하세요. - Multi-AZ
-
다중 AZ 인스턴스를 선택하면 스토리지 장애로부터 마이그레이션을 보호할 수 있습니다. 대부분의 마이그레이션은 일시적이며 장기간 실행되지 않습니다. 지속적 복제 AWS DMS 를 위해를 사용하는 경우 스토리지 문제가 발생할 경우 다중 AZ 인스턴스를 선택하면 가용성이 향상될 수 있습니다.
단일 AZ 또는 다중 AZ 복제 인스턴스를 사용하여 전체 로드를 수행하는 동안 장애 조치 또는 호스트 교체가 발생하는 경우 전체 로드 태스크는 실패할 것으로 예상됩니다. 완료되지 않았거나 오류 상태인 나머지 테이블의 경우 실패 지점부터 태스크를 다시 시작할 수 있습니다.
- 여러 개의 테이블을 병렬로 로드
기본적으로는 한 번에 8개의 테이블을 AWS DMS 로드합니다. dms.c4.xlarge 이상 인스턴스와 같은 매우 큰 복제 서버를 사용하는 경우 이 값을 약간 높이면 성능이 어느 정도 향상될 수 있습니다. 하지만 어느 시점에서는 이 병렬 처리를 높이면 성능이 저하됩니다. 복제 서버가 dms.t2.medium과 같이 비교적 소형인 경우에는 병렬로 로드되는 테이블 수를 줄이는 것이 좋습니다.
에서이 번호를 변경하려면 콘솔을 AWS Management Console열고 작업을 선택한 다음 작업을 생성하거나 수정하도록 선택한 다음 고급 설정을 선택합니다. 튜닝 설정에서 병렬로 로드할 최대 테이블 수 옵션을 변경합니다.
를 사용하여이 번호를 변경하려면에서
MaxFullLoadSubTasks파라미터를 AWS CLI변경합니다TaskSettings.- 병렬 전체 로드 사용
-
Oracle, Microsoft SQL Server, MySQL, Sybase 및 IBM Db2 LUW 소스에서 파티션 및 하위 파티션을 기반으로 병렬 로드를 사용할 수 있습니다. 이렇게 하면 전체 로드 기간을 전반적으로 개선할 수 있습니다. 또한 AWS DMS 마이그레이션 태스크를 실행하는 동안 대형 테이블 또는 파티셔닝된 테이블의 마이그레이션 속도를 높일 수 있습니다. 이렇게 하려면 테이블을 세그먼트로 분할하고 동일한 마이그레이션 태스크에서 세그먼트를 병렬로 로드하세요.
병렬 로드를 사용하려면
parallel-load옵션을 사용하여table-settings유형의 테이블 매핑 규칙을 생성합니다.table-settings규칙 내에서 병렬로 로드하려는 테이블의 선택 기준을 지정할 수 있습니다. 선택 기준을 지정하려면parallel-load의type요소를 다음 중 하나로 설정합니다.-
partitions-auto -
subpartitions-auto -
partitions-list -
ranges -
none
이러한 설정에 대한 자세한 내용은 테이블 및 컬렉션 설정 규칙과 작업 섹션을 참조하세요.
-
- 인덱스, 트리거 및 참조 무결성 제약 조건 사용
인덱스, 트리거, 참조 무결성 제약 조건은 마이그레이션 성능에 영향을 미치고 마이그레이션 실패를 초래할 수 있습니다. 이러한 제약 조건이 마이그레이션에 미치는 영향은 복제 태스크가 전체 로드 태스크인지 지속적 복제(변경 데이터 캡처(CDC_) 태스크인지에 따라 달라집니다.
전체 로드 태스크의 경우 프라이머리 키 인덱스, 보조 인덱스, 참조 무결성 제약 조건 및 데이터 조작 언어(DML) 트리거를 삭제하는 것이 좋습니다. 또는 전체 로드 태스크가 완료될 때까지 생성을 연기할 수도 있습니다. 전체 로드 태스크 중에는 인덱스가 필요하지 않으며 인덱스가 있는 경우 유지 관리 오버헤드가 발생합니다. 전체 로드 태스크는 테이블 그룹을 한 번에 로드하므로 참조 무결성 제약 조건이 위반됩니다. 마찬가지로 삽입, 업데이트 및 삭제 트리거로 인해 오류가 발생할 수 있습니다(예: 이전에 대량으로 로드된 테이블에 대해 행 삽입이 트리거되는 경우). 다른 유형의 트리거도 추가 처리로 인해 성능에 영향을 줍니다.
데이터 볼륨이 비교적 작고 추가 마이그레이션 시간이 문제가 되지 않는 경우 전체 로드 태스크 전에 프라이머리 키와 세컨더리 인덱스를 구축할 수 있습니다. 참조 무결성 제약 조건 및 트리거는 항상 비활성화하세요.
전체 로드 + CDC 태스크의 경우 CDC 단계 전에 보조 색인을 추가하는 것이 좋습니다. AWS DMS 는 논리적 복제를 사용하므로 전체 테이블 스캔을 방지하기 위해 DML 작업을 지원하는 보조 인덱스가 있는지 확인합니다. CDC 단계 전에 복제 작업을 일시 중지하여 인덱스를 빌드하고 참조 무결성 제약 조건을 생성한 후 작업을 재개할 수 있습니다.
트리거는 전환 직전에 활성화해야 합니다.
- 백업 및 트랜잭션 로깅을 비활성화하세요.
Amazon RDS 데이터베이스로 마이그레이션하려면 전환 준비가 될 때까지 대상에서 백업과 다중 AZ를 비활성화하는 것이 좋습니다. 마찬가지로, Amazon RDS가 아닌 다른 시스템으로 마이그레이션할 때는 일반적으로 전환 이후까지 대상에서의 로깅을 비활성화하는 것이 좋습니다.
- 여러 개의 태스크 사용
경우에 따라 단일 마이그레이션에 여러 태스크를 사용하면 성능이 향상될 수 있습니다. 일반적인 트랜잭션에 참여하지 않는 테이블 집합이 있는 경우 마이그레이션을 여러 태스크로 나눌 수 있습니다. 트랜잭션 일관성은 태스크 내에서 유지되므로 별도의 태스크에 있는 테이블이 일반적인 트랜잭션에 참여하지 않도록 하는 것이 중요합니다. 또한 각 태스크는 독립적으로 트랜잭션 스트림을 읽으므로 소스 데이터베이스에 너무 많은 부하가 걸리지 않도록 주의해야 합니다.
여러 태스크를 사용하여 별도의 복제 스트림을 생성할 수 있습니다. 이렇게 하면 소스에서의 읽기, 복제 인스턴스의 프로세스, 대상 데이터베이스에 대한 쓰기를 병렬화할 수 있습니다.
- 변경 처리 최적화
기본적으로는 트랜잭션 모드에서 변경 사항을 AWS DMS 처리하여 트랜잭션 무결성을 유지합니다. 트랜잭션 무결성이 일시적으로 저하될 여지가 있다면 배치 최적화 적용 옵션을 대신 사용할 수 있습니다. 이 옵션은 효율성을 위해 트랜잭션을 효율적으로 그룹화하고 일괄적으로 적용합니다. 배치 최적화 적용 옵션을 사용하면 거의 항상 참조 무결성 제약 조건을 위반합니다. 따라서 마이그레이션 프로세스 중에 이러한 제약 조건을 해제한 다음, 전환 프로세스의 일부로 다시 설정하는 것이 좋습니다.
자체 온프레미스 이름 서버 사용
일반적으로 AWS DMS 복제 인스턴스는 Amazon EC2 인스턴스의 도메인 이름 시스템(DNS) 해석기를 사용하여 도메인 엔드포인트를 확인합니다. 그러나 Amazon Route 53 Resolver를 사용하는 경우 자체 온프레미스 이름 서버를 사용하여 특정 엔드포인트를 확인할 수 있습니다. 이 도구를 사용하면 인바운드 및 아웃바운드 엔드포인트, 전달 규칙 및 프라이빗 연결을 AWS 사용하여 온프레미스와 간에 쿼리할 수 있습니다. 온프레미스 이름 서버를 사용하면 보안이 향상되고 방화벽 뒤에서의 사용 편의성이 향상된다는 이점이 있습니다.
인바운드 엔드포인트가 있는 경우 온프레미스에서 시작된 DNS 쿼리를 사용하여 AWS호스팅된 도메인을 확인할 수 있습니다. 엔드포인트를 구성하려면 해석기를 제공하려는 각 서브넷의 IP 주소를 할당합니다. 온프레미스 DNS 인프라와 간에 연결을 설정하려면 AWS Direct Connect 또는 가상 프라이빗 네트워크(VPN)를 AWS사용합니다.
아웃바운드 엔드포인트는 온프레미스 이름 서버에 연결됩니다. 이름 서버는 허용 목록에 포함되고 아웃바운드 엔드포인트에 설정된 IP 주소에만 액세스 권한을 부여합니다. 이름 서버의 IP 주소는 대상 IP 주소입니다. 아웃바운드 엔드포인트에 대한 보안 그룹을 선택할 때는 복제 인스턴스에서 사용하는 것과 동일한 보안 그룹을 선택하세요.
선택된 도메인을 이름 서버로 전달하려면 다음 규칙을 사용합니다. 아웃바운드 엔드포인트는 여러 전달 규칙을 처리할 수 있습니다. 전달 규칙의 범위는 Virtual Private Cloud(VPC)입니다. VPC와 연결된 전달 규칙을 사용하여 AWS 클라우드의 논리적으로 격리된 섹션을 프로비저닝할 수 있습니다. 이 논리적으로 격리된 섹션에서 가상 네트워크에서 AWS 리소스를 시작할 수 있습니다.
온프레미스 DNS 인프라 내에서 호스팅되는 도메인을 아웃바운드 DNS 쿼리를 설정하는 조건부 전달 규칙으로 구성할 수 있습니다. 이러한 도메인 중 하나에 대한 쿼리가 수행되면 규칙은 규칙으로 구성된 서버로 DNS 요청을 전달하려는 시도를 트리거합니다. 다시 말하지만 AWS Direct Connect 또는 VPN을 통한 프라이빗 연결이 필요합니다.
다음 다이어그램은 Route 53 Resolver 아키텍처입니다.
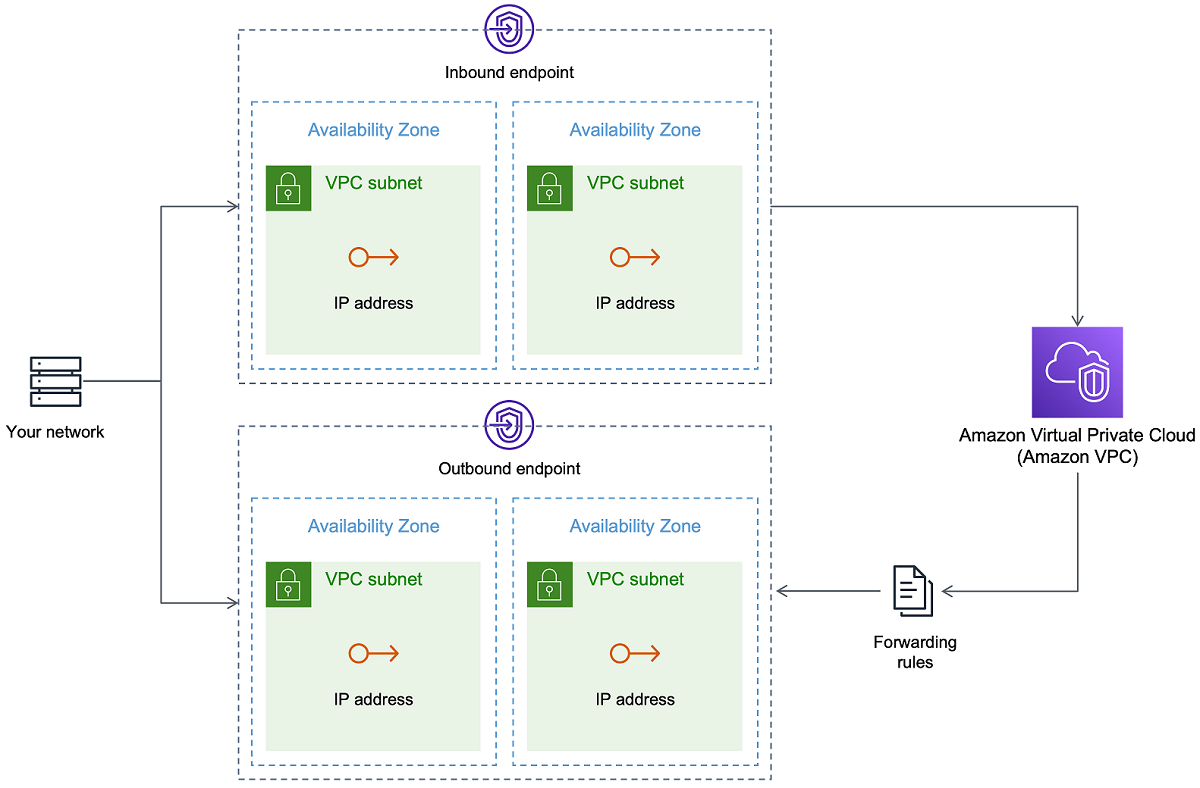
Route 53 DNS Resolver에 대한 자세한 내용은 Amazon Route 53 개발자 안내서의 Route 53 Resolver 시작하기를 참조하세요.
에서 Amazon Route 53 Resolver 사용 AWS DMS
를 사용하여 엔드포인트를 확인하기 AWS DMS 위해 용 온프레미스 이름 서버를 생성할 수 있습니다Amazon Route 53 Resolver
Route 53을 AWS DMS 기반으로 용 온프레미스 이름 서버를 생성하려면
에 로그인 AWS Management Console 하고 https://console.aws.amazon.com/route53/
Route 53 콘솔을 엽니다. -
Route 53 콘솔에서 Route 53 Resolver를 구성할 AWS 리전을 선택합니다. Route 53 Resolver는 리전별 서비스입니다.
쿼리 방향(인바운드, 아웃바운드 또는 둘 다)을 선택합니다.
인바운드 쿼리 구성을 제공합니다.
엔드포인트 이름을 입력하고 VPC를 선택합니다.
VPC 내에서 하나 이상의 서브넷을 할당합니다(예: 가용성을 위해 2개 선택).
엔드포인트로 사용할 특정 IP 주소를 할당하거나 Route 53 Resolver가 자동으로 할당하도록 합니다.
VPC 내부의 워크로드가 DNS 쿼리를 DNS 인프라로 라우팅할 수 있도록 온프레미스 도메인에 대한 규칙을 생성합니다.
온프레미스 DNS 서버에 대한 IP 주소를 하나 이상 입력합니다.
규칙을 제출합니다.
모든 것이 생성되면 VPC가 인바운드 및 아웃바운드 규칙과 연결되어 트래픽 라우팅을 시작할 수 있습니다.
Route 53 Resolver에 대한 자세한 내용은 Amazon Route 53 개발자 안내서의 Route 53 Resolver 시작하기를 참조하세요.
대용량 이진 객체(LOB) 마이그레이션
일반적으로는 LOB 데이터를 다음 두 단계로 AWS DMS 마이그레이션합니다.
AWS DMS 는 대상 테이블에 새 행을 생성하고 연결된 LOB 값을 제외한 모든 데이터로 행을 채웁니다.
AWS DMS 는 대상 테이블의 행을 LOB 데이터로 업데이트합니다.
이 LOB 마이그레이션 프로세스를 수행하려면 마이그레이션 중에 대상 테이블의 모든 LOB 열에 Null을 허용해야 합니다. 이는 소스 테이블에서 LOB 열을 Null로 설정할 수 없는 경우에도 마찬가지입니다. 가 대상 테이블을 AWS DMS 생성하면 기본적으로 LOB 열이 null로 설정됩니다. 경우에 따라 가져오기 또는 내보내기와 같은 다른 메커니즘을 사용하여 대상 테이블을 생성할 수 있습니다. 이러한 경우 마이그레이션 태스크를 시작하기 전에 LOB 열이 Null 허용인지 확인하세요.
이 요구 사항에는 한 가지 예외가 있습니다. Oracle 소스에서 Oracle 대상으로 동종 마이그레이션을 수행하고 제한적 LOB 모드를 선택한다고 가정해 보겠습니다. 이 경우 LOB 값을 포함하여 전체 행이 한 번에 채워집니다. 이러한 경우 AWS DMS 는 필요한 경우 null할 수 없는 제약 조건이 있는 대상 테이블 LOB 열을 생성할 수 있습니다.
제한적 LOB 모드 사용
AWS DMS 는 마이그레이션에 LOB 값이 포함된 경우 성능과 편의성의 균형을 맞추는 두 가지 방법을 사용합니다.
제한적 LOB 모드에서는 모든 LOB 값을 사용자가 지정한 크기 제한(기본값은 32KB)까지 마이그레이션합니다. 크기 제한보다 큰 LOB 값은 수동으로 마이그레이션해야 합니다. 모든 마이그레이션 태스크의 기본값인 제한적 LOB 모드가 일반적으로 최상의 성능을 제공합니다. 하지만 최대 LOB 크기 파라미터 설정이 올바른지 확인해야 합니다. 이 파라미터를 모든 테이블에서 가장 큰 LOB 크기로 설정하세요.
전체 LOB 모드는 크기에 관계없이 테이블의 모든 LOB 데이터를 마이그레이션합니다. 전체 LOB 모드를 사용하면 테이블의 모든 LOB 데이터를 편리하게 이동할 수 있지만 프로세스가 성능에 상당한 영향을 미칠 수 있습니다.
PostgreSQL과 같은 일부 데이터베이스 엔진의 경우 LOBs와 같은 JSON 데이터 형식을 AWS DMS 처리합니다. 제한적 LOB 모드를 선택한 경우 최대 LOB 크기 옵션이 JSON 데이터가 잘리지 않는 값으로 설정되어 있는지 확인하세요.
AWS DMS 는 대규모 객체 데이터 유형(BLOBs, CLOBs 및 NCLOBs) 사용을 완벽하게 지원합니다. 다음 소스 엔드포인트는 전체 LOB 지원을 제공합니다.
Oracle
Microsoft SQL Server
ODBC
다음 대상 엔드포인트는 전체 LOB 지원을 제공합니다.
Oracle
Microsoft SQL Server
다음 대상 엔드포인트는 제한적 LOB 지원을 제공합니다. 이 대상 엔드포인트에는 무제한 LOB 크기를 사용할 수 없습니다.
Amazon Redshift
-
Amazon S3
전체 LOB를 지원하는 엔드포인트의 경우 LOB 데이터 형식에 대한 크기 제한을 설정할 수도 있습니다.
개선된 LOB 성능
LOB 데이터를 마이그레이션하는 동안 다음과 같은 다양한 LOB 최적화 설정을 지정할 수 있습니다.
테이블별 LOB 설정
테이블별 LOB 설정을 사용하여 테이블 일부 또는 전부에 대한 태스크 수준 LOB 설정을 재정의할 수 있습니다. 이렇게 하려면 table-settings 규칙에서 lob-settings를 정의합니다. 다음은 몇 가지 큰 LOB 값이 포함된 예제 테이블입니다.
SET SERVEROUTPUT ON CREATE TABLE TEST_CLOB ( ID NUMBER, C1 CLOB, C2 VARCHAR2(4000) ); DECLARE bigtextstring CLOB := '123'; iINT; BEGIN WHILE Length(bigtextstring) <= 60000 LOOP bigtextstring := bigtextstring || '000000000000000000000000000000000'; END LOOP; INSERT INTO TEST_CLOB (ID, C1, C2) VALUES (0, bigtextstring,'AnyValue'); END; / SELECT * FROM TEST_CLOB; COMMIT
다음으로 마이그레이션 태스크를 생성하고 새 lob-settings 규칙을 사용하여 테이블의 LOB 처리를 수정합니다. bulk-max-siz 값에 따라 최대 LOB 크기(KB)가 결정됩니다. 지정된 크기보다 크면 잘립니다.
{ "rules": [{ "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "HR", "table-name": "TEST_CLOB" }, "rule-action": "include" }, { "rule-type": "table-settings", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "HR", "table-name": "TEST_CLOB" }, "lob-settings": { "mode": "limited", "bulk-max-size": "16" } } ] }
이 AWS DMS 작업이 로 생성되더라도 테이블FullLobMode : true별 LOB 설정은이 특정 테이블의 LOB 데이터를 16,000 AWS DMS 으로 자르도록 지시합니다. 태스크 로그를 확인하여 이를 확인할 수 있습니다.
721331968: 2018-09-11T19:48:46:979532 [SOURCE_UNLOAD] W: The value of column 'C' in table 'HR.TEST_CLOB' was truncated to length 16384
인라인 LOB 설정
AWS DMS 작업을 생성할 때 LOB 모드에 따라 LOBs 방법이 결정됩니다.
전체 LOB 모드와 제한적 LOB 모드는 각각 장단점이 있습니다. 인라인 LOB 모드는 전체 LOB 모드와 제한적 LOB 모드의 장점을 결합합니다.
큰 LOB와 작은 LOB를 모두 복제해야 하지만 대부분의 LOB가 작은 경우 인라인 LOB 모드를 사용할 수 있습니다. 이 옵션을 선택하면 전체 로드 중에 AWS DMS 작업이 작은 LOBs 인라인으로 전송하므로 더 효율적입니다. AWS DMS 작업은 소스 테이블에서 조회를 수행하여 대용량 LOBs를 전송합니다.
변경 처리 중에는 소스 테이블에서 검색을 수행하여 작은 LOB와 큰 LOB를 모두 복제합니다.
인라인 LOB 모드를 사용하는 경우 AWS DMS 작업은 모든 LOB 크기를 확인하여 인라인으로 전송할 LOB 크기를 결정합니다. 지정된 크기보다 큰 LOB는 전체 LOB 모드를 사용하여 복제됩니다. 따라서 대부분의 LOB가 지정된 설정보다 큰 경우 이 옵션을 사용하지 않는 것이 좋습니다. 대신 LOB 크기를 무제한으로 허용하세요.
가 true로 FullLobMode 설정된 경우에만 사용할 수 있는 작업 설정 InlineLobMaxSize의 속성을 사용하여이 옵션을 구성합니다. InlineLobMaxSize의 기본값은 0이고 범위는 1~102400킬로바이트(100MB)입니다. InlineLobMaxSize를 32Kb보다 큰 값으로 설정하면 워크로드에 따라 메모리 압력과 성능 저하가 발생할 수 있습니다.
예를 들어 다음 AWS DMS 작업 설정을 사용할 수 있습니다. 여기서 InlineLobMaxSize 값을 5로 설정하면 5KiB(5,120바이트)보다 작거나 같은 모든 LOB가 인라인으로 전송됩니다.
{ "TargetMetadata": { "TargetSchema": "", "SupportLobs": true, "FullLobMode": true, "LobChunkSize": 64, "LimitedSizeLobMode": false, "LobMaxSize": 32, "InlineLobMaxSize": 5, "LoadMaxFileSize": 0, "ParallelLoadThreads": 0, "ParallelLoadBufferSize":0, "BatchApplyEnabled": false, "TaskRecoveryTableEnabled": false}, . . . }
리소스 할당
-
적절한 복제 인스턴스 크기를 선택하고 LOB 처리에 충분한 스토리지를 할당해야 합니다. 자세한 내용은 복제 인스턴스에 가장 적합한 크기 선택을 참조하세요.
-
대상에 LOB 열이 포함된 테이블에 대한 충분한 여유 공간이 있는지 확인합니다.
-
다양한 특성을 가진 LOBs
-
자주 업데이트LOBs와 거의 수정되지 않는 LOBs
-
대형 LOBs 소형 LOBs 비교
-
자주 액세스하는 테이블과 자주 액세스하지 않는 테이블 비교
-
행 필터링을 사용하여 큰 테이블 마이그레이션 시 성능 향상
대형 테이블을 마이그레이션할 때 성능을 개선하려면 마이그레이션을 두 개 이상의 태스크로 나누세요. 행 필터링을 사용하여 마이그레이션을 여러 태스크로 나누려면 키 또는 파티션 키를 사용합니다. 예를 들어 1에서 8,000,000까지의 정수 프라이머리 키 ID가 있는 경우 행 필터링을 사용하여 8개의 태스크를 생성하여 각각 1백만 개의 레코드를 마이그레이션할 수 있습니다.
콘솔에서 행 필터링을 적용하려면
를 엽니다 AWS Management Console.
태스크를 선택하고 새 태스크를 생성합니다.
테이블 매핑 탭을 선택하고 선택 규칙을 확장합니다.
새 선택 규칙 추가를 선택합니다. 이제 작거나 같음, 크거나 같음, 같음 또는 두 값 사이의 범위 조건을 사용하여 열 필터를 추가할 수 있습니다. 열 필터링에 대한 자세한 내용은 콘솔에서 테이블 선택 및 변환 규칙 지정 섹션을 참조하세요.
날짜별로 분할된 큰 파티션된 테이블이 있는 경우 날짜를 기준으로 데이터를 마이그레이션할 수 있습니다. 예를 들어, 월별로 분할된 테이블이 있고 현재 월의 데이터만 업데이트된다고 가정합시다. 이 경우 각 고정 월별 파티션에 대해 전체 로드 태스크를 생성하고 현재 업데이트된 파티션에 대해 전체 로드 + CDC 태스크를 생성할 수 있습니다.
테이블에 단일 열 기본 키 또는 고유 인덱스가 있는 경우 작업에서 범위 유형의 병렬 로드를 사용하여 테이블을 AWS DMS 분할하여 데이터를 병렬로 로드하도록 할 수 있습니다. 자세한 내용은 테이블 및 컬렉션 설정 규칙과 작업 단원을 참조하십시오.
지속적 복제
AWS DMS 는 데이터를 지속적으로 복제하여 소스 데이터베이스와 대상 데이터베이스를 동기화된 상태로 유지합니다. 제한된 양의 데이터 정의 언어(DDL) 문만 복제됩니다. AWS DMS 는 인덱스, 사용자, 권한, 저장 프로시저, 기타 테이블 데이터와 직접 관련되지 않은 데이터베이스 변경 사항과 같은 항목을 전파하지 않습니다.
지속적 복제를 사용하려는 경우 복제 인스턴스를 생성할 때 다중 AZ 옵션을 설정하세요. 다중 AZ를 선택하면 복제 인스턴스의 고가용성과 장애 조치 기능을 확보할 수 있습니다. 하지만 이 옵션은 성능에 영향을 줄 수 있으며 대상 시스템에 변경 사항을 적용하는 동안 복제 속도가 느려질 수 있습니다.
소스 또는 대상 데이터베이스를 업그레이드하기 전에 이러한 데이터베이스에서 실행 중인 모든 AWS DMS 태스크를 중지하는 것이 좋습니다. 업그레이드가 완료된 후 태스크를 재개하세요.
지속적 복제 중에는 소스 데이터베이스 시스템과 AWS DMS 복제 인스턴스 간의 네트워크 대역폭을 식별하는 것이 중요합니다. 복제가 진행되는 동안 네트워크로 인해 병목 현상이 발생하지 않는지 확인해야 합니다.
소스 데이터베이스 시스템의 시간당 변경 속도 및 아카이브 로그 생성을 파악하는 것도 중요합니다. 이렇게 하면 복제가 진행되는 동안 발생할 수 있는 처리량을 이해하는 데 도움이 될 수 있습니다.
소스 데이터베이스의 로드 감소
AWS DMS 는 소스 데이터베이스에서 일부 리소스를 사용합니다. 전체 로드 태스크 중에 AWS DMS 는 소스 테이블에서 병렬로 처리되는 각 테이블에 대해 전체 테이블 스캔을 수행합니다. 또한 마이그레이션의 일부로 생성하는 각 태스크는 CDC 프로세스의 일환으로 소스에 변경 사항을 쿼리합니다. AWS DMS 가 Oracle과 같은 일부 소스에 대해 CDC를 수행하려면 데이터베이스의 변경 로그에 기록된 데이터의 양을 늘려야 할 수 있습니다.
소스 데이터베이스에 과부하가 걸린다면 마이그레이션할 태스크 수 또는 각 태스크의 테이블 수를 줄이세요. 각 태스크마다 소스 변경 사항이 독립적으로 적용되므로 태스크를 통합하면 변경 사항 캡처 워크로드를 줄일 수 있습니다.
대상 데이터베이스에서 병목 현상 감소
마이그레이션하는 동안 대상 데이터베이스의 쓰기 리소스를 경합하는 프로세스를 모두 제거해 보세요.
-
불필요한 트리거를 비활성화하세요.
-
초기 로드 중에는 보조 인덱스를 비활성화하고 나중에 복제가 진행되는 동안 다시 활성화하세요.
-
Amazon RDS 데이터베이스의 경우 전환이 완료될 때까지 백업 및 다중 AZ를 비활성화하는 것이 좋습니다.
-
비 RDS 시스템으로 마이그레이션할 때는 전환 시까지 대상의 모든 로깅을 비활성화하는 것이 좋습니다.
마이그레이션 중에 데이터 유효성 검사 사용
데이터가 소스에서 대상으로 정확히 마이그레이션되었는지 확인하기 위해 데이터 유효성 검사를 사용하는 것이 좋습니다. 작업에 대한 데이터 검증을 켜면는 테이블에 대한 전체 로드가 수행된 직후 소스 데이터와 대상 데이터를 비교하기 AWS DMS 시작합니다.
데이터 검증은가 소스 및 대상 엔드포인트로 AWS DMS 지원하는 모든 곳에서 다음 데이터베이스와 함께 작동합니다.
-
Oracle
-
PostgreSQL
-
MySQL
-
MariaDB
-
Microsoft SQL Server
-
Amazon Aurora MySQL 호환 버전
-
Amazon Aurora PostgreSQL 호환 에디션
-
IBM Db2 LUW
-
Amazon Redshift
자세한 내용은 AWS DMS 데이터 검증 단원을 참조하십시오.
지표를 사용하여 AWS DMS 작업 모니터링
AWS DMS 콘솔을 사용하여 태스크의 지표를 모니터링할 수 있는 몇 가지 옵션이 있습니다.
- 호스트 지표
-
CloudWatch 지표 탭에서 각 특정 복제 인스턴스에 대한 호스트 지표를 찾을 수 있습니다. 여기에서 복제 인스턴스의 크기가 적절한지 모니터링할 수 있습니다.
- 복제 작업 지표
-
수신 및 커밋된 변경 사항, 복제 호스트와 소스/대상 데이터베이스 간의 지연 시간을 비롯한 복제 태스크 지표는 각 태스크에 대한 CloudWatch Metrics 탭에서 확인할 수 있습니다.
- 테이블 지표
-
개별 테이블 지표는 각 태스크에 대한 테이블 통계 탭에서 확인할 수 있습니다. 이러한 지표에는 다음과 같은 수치가 포함됩니다.
-
전체 로드 중에 로드된 행 수.
-
태스크 시작 이후 삽입, 업데이트 및 삭제 횟수.
-
태스크 시작 이후 DDL 작업 수.
-
지표 모니터링에 대한 자세한 정보는 AWS DMS 작업 모니터링 섹션을 참조하세요.
이벤트 및 알림
AWS DMS 는 Amazon SNS를 사용하여 복제 인스턴스 생성 또는 삭제와 같은 AWS DMS 이벤트가 발생할 때 알림을 제공합니다. AWS 리전에 대해 Amazon SNS에서 지원하는 모든 형식으로 이러한 알림을 사용할 수 있습니다. 여기에는 이메일 메시지, 문자 메시지 또는 HTTP 엔드포인트에 대한 호출이 포함될 수 있습니다.
자세한 내용은 AWS Database Migration Service에서 Amazon SNS 이벤트 및 알림 사용 단원을 참조하십시오.
마이그레이션 문제 해결을 위해 작업 로그 사용
경우에 따라에서 경고 또는 오류 메시지가 작업 로그에만 나타나는 문제가 AWS DMS 발생할 수 있습니다. 특히 데이터 잘림 문제나 외래 키 위반으로 인한 행 거부는 태스크 로그에만 기록됩니다. 따라서 데이터베이스를 마이그레이션할 때는 태스크 로그를 검토해야 합니다. 태스크 로그를 보려면 Amazon CloudWatch를 태스크 생성의 일부로 구성하세요.
자세한 내용은 Amazon CloudWatch를 사용하여 복제 지표 모니터링을 참조하세요.
Time Travel을 통한 복제 태스크 문제 해결
AWS DMS 마이그레이션 문제를 해결하기 위해 Time Travel을 사용할 수 있습니다. Time Travel에 대한 자세한 내용은 Time Travel 작업 설정 섹션을 참조하세요.
Time Travel로 작업할 때 다음 사항을 고려해야 합니다.
-
DMS 복제 인스턴스의 오버헤드를 방지하려면 디버깅이 필요한 태스크에만 Time Travel을 활성화합니다.
-
Time Travel을 사용하여 며칠 동안 실행될 수 있는 복제 태스크의 문제를 해결할 때는 복제 인스턴스 지표에서 리소스 오버헤드를 모니터링합니다. 이 접근 방식은 특히 소스 데이터베이스에서 장시간 동안 높은 트랜잭션 로드가 실행되는 경우에 적용됩니다. 자세한 내용은 AWS DMS 작업 모니터링을 참조하세요.
-
Time Travel 태스크 설정
EnableRawData를true로 설정하면 DMS 복제 중 태스크 메모리 사용량이 Time Travel이 활성화되어 있지 않을 때보다 많을 수 있습니다. Time Travel을 장시간 활성화하는 경우 태스크를 모니터링하세요. -
현재 Time Travel은 태스크 수준에서만 활성화할 수 있습니다. 모든 테이블의 변경 사항이 Time Travel 로그에 기록됩니다. 트랜잭션 볼륨이 많은 데이터베이스의 특정 테이블에 대한 문제를 해결하려면 별도의 태스크를 생성하세요.
Oracle 대상에서 사용자 및 스키마 변경
Oracle을 대상으로 사용하는 경우는 대상 엔드포인트의 사용자가 소유한 스키마로 데이터를 AWS DMS 마이그레이션합니다.
예를 들어 명명된 PERFDATA 스키마를 Oracle 대상 엔드포인트로 마이그레이션하는 중이고 대상 엔드포인트 사용자 이름은 MASTER이라고 가정해 보겠습니다. AWS DMS 는 MASTER로 Oracle 대상에 연결하고 MASTER 스키마를 PERFDATA의 데이터베이스 객체로 채웁니다.
이 동작을 재정의하려면 스키마 변환을 제공합니다. 예를 들어 PERFDATA 스키마 객체를 대상 엔드포인트의 PERFDATA 스키마로 마이그레이션하려면 다음 변환을 사용합니다.
{ "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "PERFDATA" }, "rule-target": "schema", "rule-action": "rename", "value": "PERFDATA" }
변환에 대한 자세한 내용은 JSON을 사용하여 테이블 선택 및 변환 지정 섹션을 참조하세요.
Oracle 대상에 대한 테이블 및 인덱스 테이블스페이스 변경
Oracle을 대상으로 사용하는 경우는 모든 테이블과 인덱스를 대상의 기본 테이블스페이스로 AWS DMS 마이그레이션합니다. 예를 들어 소스가 Oracle이 아닌 다른 데이터베이스 엔진이라고 가정해 보겠습니다. 모든 대상 테이블 및 인덱스가 동일한 기본 테이블스페이스로 마이그레이션됩니다.
이 동작을 재정의하려면 해당하는 테이블스페이스 변환을 제공합니다. 예를 들어, 테이블 및 인덱스를 소스의 스키마를 따라 명명된 Oracle 대상의 테이블 및 인덱스 테이블스페이스로 마이그레이션하려고 한다고 가정해 보겠습니다. 이 경우 다음과 같은 변형을 사용할 수 있습니다. 여기서 소스의 스키마는 이름이 INVENTORY이고 대상의 해당 테이블 및 인덱스 테이블스페이스는 이름이 각각 INVENTORYTBL 및 INVENTORYIDX입니다.
{ "rule-type": "transformation", "rule-id": "3", "rule-name": "3", "rule-action": "rename", "rule-target": "table-tablespace", "object-locator": { "schema-name": "INVENTORY", "table-name": "%", "table-tablespace-name": "%" }, "value": "INVENTORYTBL" }, { "rule-type": "transformation", "rule-id": "4 "rule-name": "4", "rule-action": "rename", "rule-target": "index-tablespace", "object-locator": { "schema-name": "INVENTORY", "table-name": "%", "index-tablespace-name": "%" }, "value": "INVENTORYIDX" }
변환에 대한 자세한 내용은 JSON을 사용하여 테이블 선택 및 변환 지정 섹션을 참조하세요.
Oracle이 소스와 대상인 경우 Oracle 소스 추가 접속 속성인 enableHomogenousTablespace=true를 설정하여 기존 테이블 또는 인덱스 테이블스페이스 할당을 유지할 수 있습니다. 자세한 내용은 Oracle을의 소스로 사용할 때 엔드포인트 설정 AWS DMS 단원을 참조하십시오.
복제 인스턴스 버전 업그레이드
AWS 는 새로운 기능 및 성능 개선과 함께 새로운 버전의 AWS DMS 복제 엔진 소프트웨어를 정기적으로 릴리스합니다. 복제 엔진 소프트웨어의 각 버전마다 고유한 버전 번호가 있습니다. AWS DMS 복제 인스턴스를 최신 버전으로 업그레이드하기 전에 프로덕션 워크로드를 실행하는 복제 인스턴스의 기존 버전을 테스트하는 것이 중요합니다. 사용 가능한 버전 업그레이드에 대한 자세한 내용은 AWS DMS 릴리스 정보 딘원을 참조하세요.
마이그레이션 비용 이해
AWS Database Migration Service 를 사용하면 저렴한 비용으로 데이터베이스를 로 AWS 쉽고 안전하게 마이그레이션할 수 있습니다. 복제 인스턴스 및 추가 로그 스토리지에 대한 비용만 지불하면 됩니다. 각 데이터베이스 마이그레이션 인스턴스에는 대부분의 복제에 충분한 스왑 공간, 복제 로그 및 데이터 캐시용 스토리지가 포함되어 있으며 인바운드 데이터 전송은 무료입니다.
초기 로드 또는 피크 로드 시간에는 더 많은 리소스가 필요할 수 있습니다. CloudWatch 지표를 사용하여 복제 인스턴스 리소스 사용률을 면밀히 모니터링할 수 있습니다. 그런 다음 사용량에 따라 복제 인스턴스 크기를 늘리거나 줄일 수 있습니다.
마이그레이션 비용 추정에 대한 자세한 내용은 다음을 참조하세요.
