기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
EKS 제어 플레인
Amazon Elastic Kubernetes Service(EKS)는 자체 Kubernetes 컨트롤 플레인 또는 작업자 노드를 설치, 운영 및 유지 관리할 필요 없이 AWS에서 Kubernetes를 쉽게 실행할 수 있는 관리형 Kubernetes 서비스입니다. 업스트림 Kubernetes를 실행하며 Kubernetes 준수 인증을 받았습니다. 이러한 적합성을 통해 EC2 또는 온프레미스에 설치할 수 있는 오픈 소스 커뮤니티 버전과 마찬가지로 EKS가 Kubernetes APIs를 지원할 수 있습니다. 업스트림 Kubernetes에서 실행되는 기존 애플리케이션은 Amazon EKS와 호환됩니다.
EKS는 Kubernetes 컨트롤 플레인 노드의 가용성과 확장성을 자동으로 관리하고 비정상 컨트롤 플레인 노드를 자동으로 교체합니다.
EKS 아키텍처
EKS 아키텍처는 Kubernetes 컨트롤 플레인의 가용성과 내구성을 손상시킬 수 있는 단일 장애 지점을 제거하도록 설계되었습니다.
EKS에서 관리하는 Kubernetes 컨트롤 플레인은 EKS 관리형 VPC 내에서 실행됩니다. EKS 컨트롤 플레인은 Kubernetes API 서버 노드 등 클러스터로 구성됩니다. API 서버, 스케줄러와 같은 구성 요소를 실행하고 Auto Scaling 그룹에서 kube-controller-manager 실행되는 Kubernetes API 서버 노드입니다. EKS는 AWS 리전 내 개별 가용 영역(AZs)에서 최소 2개의 API 서버 노드를 실행합니다. 마찬가지로 내구성을 위해 etcd 서버 노드는 세 개의 AZs. EKS는 각 AZ에서 NAT 게이트웨이를 실행하고 API 서버 및 etcd 서버는 프라이빗 서브넷에서 실행됩니다. 이 아키텍처는 단일 AZ의 이벤트가 EKS 클러스터의 가용성에 영향을 미치지 않도록 합니다.
새 클러스터를 생성하면 Amazon EKS는 클러스터와 통신하는 데 사용하는 관리형 Kubernetes API 서버에 대해 가용성이 높은 엔드포인트를 생성합니다(와 같은 도구 사용kubectl). 관리형 엔드포인트는 NLB를 사용하여 Kubernetes API 서버를 로드 밸런싱합니다. 또한 EKS는 작업자 노드와의 통신을 용이하게 하기 위해 서로 다른 AZs에 두 개의 ENI를 프로비저닝합니다.
EKS 데이터 영역 네트워크 연결
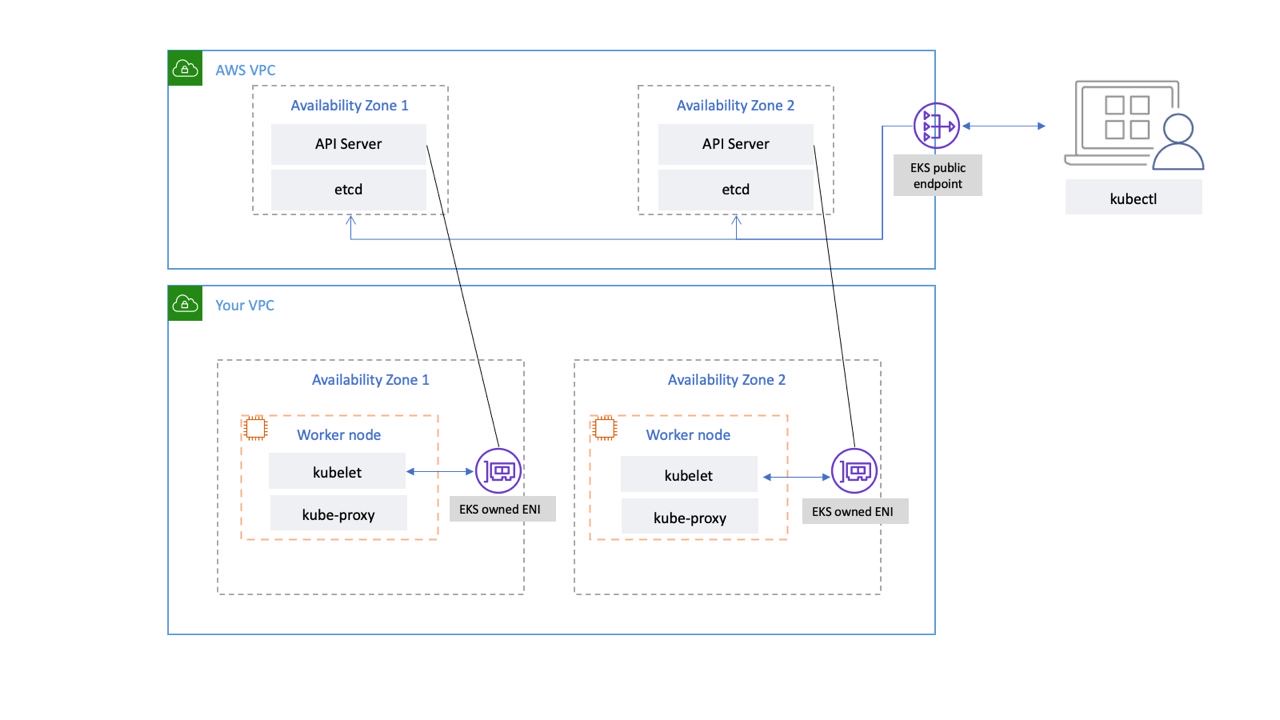
퍼블릭 인터넷(퍼블릭 엔드포인트 사용) 또는 VPC(EKS 관리형 ENIs 사용) 또는 둘 다에서 Kubernetes 클러스터의 API 서버에 연결할 수 있는지 여부를 구성할 수 있습니다.
사용자 및 작업자 노드가 퍼블릭 엔드포인트를 사용하여 API 서버에 연결하든 EKS 관리형 ENI를 사용하여 API 서버에 연결하든, 연결을 위한 중복 경로가 있습니다.
추천
다음 권장 사항을 검토합니다.
컨트롤 플레인 지표 모니터링
Kubernetes API 지표를 모니터링하면 컨트롤 플레인 성능에 대한 인사이트를 얻고 문제를 식별할 수 있습니다. 비정상 컨트롤 플레인은 클러스터 내에서 실행되는 워크로드의 가용성을 손상시킬 수 있습니다. 예를 들어, 잘못 작성된 컨트롤러는 API 서버를 오버로드하여 애플리케이션의 가용성에 영향을 미칠 수 있습니다.
Kubernetes는 /metrics 엔드포인트에서 컨트롤 플레인 지표를 노출합니다.
를 사용하여 노출된 지표를 볼 수 있습니다kubectl.
kubectl get --raw /metrics
이러한 지표는 Prometheus 텍스트 형식으로
Prometheus를 사용하여 이러한 지표를 수집하고 저장할 수 있습니다. 2020년 5월에 CloudWatch는 CloudWatch Container Insights에서 Prometheus 지표 모니터링에 대한 지원을 추가했습니다. 따라서 Amazon CloudWatch를 사용하여 EKS 컨트롤 플레인을 모니터링할 수도 있습니다. 자습서를 사용하여 새 Prometheus 스크레이프 대상 추가: Prometheus KPI 서버 지표를 사용하여 지표를 수집하고 CloudWatch 대시보드를 생성하여 클러스터의 컨트롤 플레인을 모니터링할 수 있습니다. CloudWatch
여기에서 Kubernetes API 서버 지표를 찾을 수 있습니다apiserver_request_duration_seconds 수 있습니다.
다음 컨트롤 플레인 지표를 모니터링하는 것이 좋습니다.
API 서버
| 지표 | 설명 |
|---|---|
|
|
각 동사, 드라이 런 값, 그룹, 버전, 리소스, 범위, 구성 요소 및 HTTP 응답 코드에 대해 분류된 apiserver 요청의 카운터. |
|
|
각 동사, 모의 실행 값, 그룹, 버전, 리소스, 하위 리소스, 범위 및 구성 요소에 대한 초 단위의 응답 지연 시간 히스토그램입니다. |
|
|
이름별로 식별되고 각 작업 및 API 리소스 및 유형(검증 또는 승인)에 대해 구분된 초 단위의 허용 컨트롤러 지연 시간 히스토그램입니다. |
|
|
승인 웹후크 거부 수입니다. 이름, 작업, rejection_code, 유형(검증 또는 승인), error_type(calling_webhook_error, apiserver_internal_error, no_error)으로 식별됨 |
|
|
초 단위로 지연 시간 히스토그램을 요청합니다. 동사 및 URL로 분류됩니다. |
|
|
상태 코드, 메서드 및 호스트로 분할된 HTTP 요청 수. |
-
히스토그램 지표에는 _bucket, _sum 및 _count 접미사가 포함됩니다.
etcd
| 지표 | 설명 |
|---|---|
|
|
각 작업 및 객체 유형에 대한 Etcd 요청 지연 시간 히스토그램. |
|
|
Etcd 데이터베이스 크기입니다. |
-
히스토그램 지표에는 _bucket, _sum 및 _count 접미사가 포함됩니다.
Kubernetes 모니터링 개요 대시보드
중요
데이터베이스 크기 제한을 초과하면 etcd는 스페이스 없음 경보를 내보내고 추가 쓰기 요청 수행을 중지합니다. 즉, 클러스터는 읽기 전용이 되며 새 포드 생성, 배포 조정 등과 같은 객체를 변경하기 위한 모든 요청은 클러스터의 API 서버에서 거부됩니다.
클러스터 인증
EKS는 현재 보유자/서비스 계정 토큰
EKS 클러스터를 생성하는 IAM 사용자 또는 역할은 클러스터에 대한 모든 액세스 권한을 자동으로 얻습니다. aws-auth configmap을 편집하여 EKS 클러스터에 대한 액세스를 관리할 수 있습니다.
aws-auth 구성 맵을 잘못 구성하고 클러스터에 대한 액세스 권한을 잃더라도 클러스터 생성자의 사용자 또는 역할을 사용하여 EKS 클러스터에 액세스할 수 있습니다.
드물지만 AWS 리전에서 IAM 서비스를 사용할 수 없는 경우 Kubernetes 서비스 계정의 보유자 토큰을 사용하여 클러스터를 관리할 수도 있습니다.
클러스터에서 모든 작업을 수행할 수 있는 super-admin 계정을 생성합니다.
kubectl -n kube-system create serviceaccount super-admin
수퍼 관리자 클러스터 관리자 역할을 제공하는 역할 바인딩을 생성합니다.
kubectl create clusterrolebinding super-admin-rb --clusterrole=cluster-admin --serviceaccount=kube-system:super-admin
서비스 계정의 보안 암호 가져오기:
SECRET_NAME=`kubectl -n kube-system get serviceaccount/super-admin -o jsonpath='{.secrets[0].name}'`
보안 암호와 연결된 토큰 가져오기:
TOKEN=`kubectl -n kube-system get secret $SECRET_NAME -o jsonpath='{.data.token}'| base64 --decode`
에 서비스 계정 및 토큰 추가kubeconfig:
kubectl config set-credentials super-admin --token=$TOKEN
수퍼 관리자 계정을 사용하려면에서 현재 컨텍스트kubeconfig를 설정합니다.
kubectl config set-context --current --user=super-admin
최종는 다음과 같아kubeconfig야 합니다.
apiVersion: v1 clusters: - cluster: certificate-authority-data:<REDACTED> server: https://<CLUSTER>.gr7.us-west-2.eks.amazonaws.com name: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> contexts: - context: cluster: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> user: super-admin name: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> current-context: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> kind: Config preferences: {} users: #- name: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> # user: # exec: # apiVersion: client.authentication.k8s.io/v1beta1 # args: # - --region # - us-west-2 # - eks # - get-token # - --cluster-name # - <<cluster name>> # command: aws # env: null - name: super-admin user: token: <<super-admin sa's secret>>
Admission Webhook
Kubernetes에는 승인 웹후크 검증과 승인 웹후크 변경이라는 두 가지 유형의 승인 웹후크가 있습니다
클러스터 중요 작업에 영향을 주지 않도록 하려면 다음과 같이 "catch-all" 웹후크를 설정하지 마십시오.
- name: "pod-policy.example.com" rules: - apiGroups: ["*"] apiVersions: ["*"] operations: ["*"] resources: ["*"] scope: "*"
또는 웹후크를 사용할 수 없는 경우 클러스터 중요 워크로드가 손상되지 않도록 웹후크에 제한 시간이 30초 미만인 페일 오픈 정책이 있는지 확인합니다.
안전하지 않은 블록 포드 sysctls
Sysctl는 사용자가 런타임 중에 커널 파라미터를 수정할 수 있는 Linux 유틸리티입니다. 이러한 커널 파라미터는 네트워크, 파일 시스템, 가상 메모리, 프로세스 관리 등 운영 체제 동작의 다양한 측면을 제어합니다.
Kubernetes를 사용하면 포드에 대한 sysctl 프로필을 할당할 수 있습니다. Kubernetes는 안전 및 안전하지 않은 systcls 것으로 분류됩니다. 안전sysctls은 컨테이너 또는 포드에 네임스페이스가 있으며, 이를 설정해도 노드 또는 노드 자체의 다른 포드에는 영향을 주지 않습니다. 반면 안전하지 않은 sysctl은 다른 포드를 중단하거나 노드를 불안정하게 만들 수 있으므로 기본적으로 비활성화됩니다.
안전하지 않은 sysctls는 기본적으로 비활성화되어 있으므로 kubelet은 안전하지 않은 sysctl 프로파일이 있는 포드를 생성하지 않습니다. 이러한 포드를 생성하면 스케줄러는 노드를 시작하지 못하는 동안 해당 포드를 노드에 반복적으로 할당합니다. 이 무한 루프는 궁극적으로 클러스터 컨트롤 플레인을 변형시켜 클러스터를 불안정하게 만듭니다.
안전하지 않은 포드를 거부하려면 OPA Gatekeepersysctls.
클러스터 업그레이드 처리
2021년 4월 이후 Kubernetes 릴리스 주기가 연간 릴리스 4개(분기당 1회)에서 연간 릴리스 3개로 변경되었습니다. 약 15주마다
클러스터 엔드포인트 연결
Amazon EKS(Elastic Kubernetes Service)로 작업할 때 Kubernetes 컨트롤 플레인 조정 또는 패치 적용과 같은 이벤트 중에 연결 시간 초과 또는 오류가 발생할 수 있습니다. 이러한 이벤트로 인해 kube-apiserver 인스턴스가 교체되어 FQDN을 확인할 때 다른 IP 주소가 반환될 수 있습니다. 이 문서에서는 Kubernetes API 소비자가 안정적인 연결을 유지하기 위한 모범 사례를 간략하게 설명합니다.
참고
이러한 모범 사례를 구현하려면 새로운 DNS 재해상 및 재시도 전략을 효과적으로 처리하기 위해 클라이언트 구성 또는 스크립트를 업데이트해야 할 수 있습니다.
주요 문제는 DNS 클라이언트 측 캐싱과 퍼블릭 엔드포인트의 경우 퍼블릭 NLB 또는 프라이빗 엔드포인트의 경우 X-ENI인 EKS 엔드포인트의 오래된 IP 주소의 가능성에서 비롯됩니다. kube-apiserver 인스턴스가 교체되면 FQDN(정규화된 도메인 이름)이 새 IP 주소로 확인될 수 있습니다. 그러나 AWS 관리형 Route 53 영역에서 60초로 설정된 DNS TTL(Time to Live) 설정으로 인해 클라이언트는 짧은 시간 동안 오래된 IP 주소를 계속 사용할 수 있습니다.
이러한 문제를 완화하기 위해 Kubernetes API 소비자(예: kubectl, CI/CD 파이프라인 및 사용자 지정 애플리케이션)는 다음 모범 사례를 구현해야 합니다.
-
DNS 재분해 구현
-
백오프 및 지터를 사용하여 재시도를 구현합니다. 예를 들어 Failures Happen이라는 제목의이 문서를
참조하세요. -
클라이언트 제한 시간을 구현합니다. 장기 실행 요청이 애플리케이션을 차단하지 못하도록 적절한 제한 시간을 설정합니다. 일부 Kubernetes 클라이언트 라이브러리, 특히 OpenAPI 생성기에서 생성된 라이브러리는 사용자 지정 제한 시간을 쉽게 설정하지 못할 수 있습니다.
-
kubectl을 사용하는 예제 1:
kubectl get pods --request-timeout 10s # default: no timeout
-
Python을 사용하는 예제 2: Kubernetes 클라이언트는 _request_timeout 파라미터를 제공합니다
.
-
이러한 모범 사례를 구현하면 Kubernetes API와 상호 작용할 때 애플리케이션의 안정성과 복원력을 크게 개선할 수 있습니다. 특히 시뮬레이션된 장애 조건에서 이러한 구현을 철저히 테스트하여 실제 조정 또는 패치 적용 이벤트 중에 예상대로 작동하는지 확인해야 합니다.
대규모 클러스터 실행
EKS는 컨트롤 플레인 인스턴스의 로드를 능동적으로 모니터링하고 자동으로 규모를 조정하여 고성능을 보장합니다. 그러나 대규모 클러스터를 실행할 때 AWS 서비스의 Kubernetes 및 할당량 내에서 발생할 수 있는 성능 문제와 제한을 고려해야 합니다.
-
서비스가 1,000개 이상인 클러스터는 ProjectCalico 팀이 수행한 테스트
에 따라 kube-proxyiptables모드에서를 사용할 때 네트워크 지연 시간이 발생할 수 있습니다. 해결 방법은 ipvs 모드에서 실행 중으로 전환하는 kube-proxy 것입니다. -
CNI가 포드에 대한 IP 주소를 요청해야 하거나 새 EC2 인스턴스를 자주 생성해야 하는 경우에도 EC2 API 요청 제한이 발생할 수 있습니다. EC2 IP 주소를 캐싱하도록 CNI를 구성하여 EC2 API 호출을 줄일 수 있습니다. 더 큰 EC2 인스턴스 유형을 사용하여 EC2 조정 이벤트를 줄일 수 있습니다.
추가 리소스:
