기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Kubernetes 컨트롤 플레인
Kubernetes 컨트롤 플레인은 Kubernetes API Server, Kubernetes Controller Manager, Scheduler 및 Kubernetes가 작동하는 데 필요한 기타 구성 요소로 구성됩니다. 이러한 구성 요소의 확장성 제한은 클러스터에서 실행 중인 항목에 따라 다르지만 조정에 가장 큰 영향을 미치는 영역에는 Kubernetes 버전, 사용률 및 개별 노드 조정이 포함됩니다.
EKS 1.24 이상 사용
EKS 1.24는 여러 가지 변경 사항을 도입하고 컨테이너 런타임을 docker 대신 containerd--container-runtime 부트스트랩 플래그를 사용하세요.
워크로드 및 노드 버스팅 제한
중요
컨트롤 플레인의 API 제한에 도달하지 않으려면 클러스터 크기를 한 번에 두 자릿수 백분율씩 늘리는 조정 스파이크를 제한해야 합니다(예: 노드 1,000개에서 노드 1,100개 또는 포드 4,000개에서 포드 4,500개로).
EKS 컨트롤 플레인은 클러스터가 증가함에 따라 자동으로 확장되지만, 확장 속도에는 제한이 있습니다. EKS 클러스터를 처음 생성할 때 컨트롤 플레인은 수백 개의 노드 또는 수천 개의 포드로 즉시 확장할 수 없습니다. EKS의 조정 개선 방식에 대한 자세한 내용은 이 블로그 게시물
대규모 애플리케이션을 확장하려면 인프라가 완전히 준비되도록 조정되어야 합니다(예: 워밍 로드 밸런서). 조정 속도를 제어하려면 애플리케이션에 적합한 지표를 기반으로 조정해야 합니다. CPU 및 메모리 조정은 애플리케이션 제약 조건을 정확하게 예측하지 못할 수 있으며 Kubernetes Horizontal Pod Autoscaler(HPA)에서 사용자 지정 지표(예: 초당 요청 수)를 사용하는 것이 더 나은 조정 옵션일 수 있습니다.
사용자 지정 지표를 사용하려면 Kubernetes 설명서
노드 및 포드를 안전하게 축소
장기 실행 인스턴스 교체
노드를 교체하면 구성 드리프트와 연장된 가동 시간 후에만 발생하는 문제(예: 느린 메모리 누수)를 방지하여 클러스터가 정기적으로 정상 상태로 유지됩니다. 자동 교체는 노드 업그레이드 및 보안 패치를 위한 좋은 프로세스와 사례를 제공합니다. 클러스터의 모든 노드를 정기적으로 교체하는 경우 지속적인 유지 관리를 위해 별도의 프로세스를 유지 관리하는 데 필요한 부담이 줄어듭니다.
Karpenter의 TTL(Time to Live)max-instance-lifetime 설정을 사용하여 노드를 자동으로 순환할 수 있습니다. 관리형 노드 그룹에는 현재이 기능이 없지만 GitHub에서 요청을 추적할 수 있습니다
사용률이 낮은 노드 제거
Kubernetes Cluster Autoscaler의 스케일 다운 임계값을 사용하여 실행 중인 워크로드가 없는 노드를 제거--scale-down-utilization-thresholdttlSecondsAfterEmpty 프로비저너 설정을 사용할 수 있습니다.
포드 중단 예산 및 안전한 노드 종료 사용
Kubernetes 클러스터에서 포드와 노드를 제거하려면 컨트롤러가 여러 리소스(예: EndpointSlices)를 업데이트해야 합니다. 이렇게 자주 또는 너무 빨리 수행하면 변경 사항이 컨트롤러에 전파될 때 API 서버 제한 및 애플리케이션 중단이 발생할 수 있습니다. 포드 중단 예산
Kubectl을 실행할 때 클라이언트 측 캐시 사용
kubectl 명령을 비효율적으로 사용하면 Kubernetes API 서버에 추가 로드를 추가할 수 있습니다. kubectl을 반복적으로 사용하는 스크립트 또는 자동화(예: 루프용에서)를 실행하거나 로컬 캐시 없이 명령을 실행하지 않아야 합니다.
kubectl 에는 필요한 API 호출 양을 줄이기 위해 클러스터에서 검색 정보를 캐싱하는 클라이언트 측 캐시가 있습니다. 캐시는 기본적으로 활성화되어 있으며 10분마다 새로 고쳐집니다.
컨테이너에서 또는 클라이언트 측 캐시 없이 kubectl을 실행하는 경우 API 제한 문제가 발생할 수 있습니다. 불필요한 API 호출을 방지하려면를 탑재하여 클러스터 캐시--cache-dir를 유지하는 것이 좋습니다.
kubectl 압축 비활성화
kubeconfig 파일에서 kubectl 압축을 비활성화하면 API 및 클라이언트 CPU 사용량을 줄일 수 있습니다. 기본적으로 서버는 클라이언트로 전송된 데이터를 압축하여 네트워크 대역폭을 최적화합니다. 이렇게 하면 모든 요청에 대해 클라이언트 및 서버에 CPU 로드가 추가되고 적절한 대역폭이 있는 경우 압축을 비활성화하면 오버헤드와 지연 시간을 줄일 수 있습니다. 압축을 비활성화하려면 --disable-compression=true 플래그를 사용하거나 kubeconfig 파일에 disable-compression: true를 설정할 수 있습니다.
apiVersion: v1
clusters:
- cluster:
server: serverURL
disable-compression: true
name: cluster
샤드 클러스터 오토스케일러
Kubernetes Cluster Autoscaler는 최대 1,000개의 노드를 확장하도록 테스트되었습니다
ClusterAutoscaler-1
autoscalingGroups: - name: eks-core-node-grp-20220823190924690000000011-80c1660e-030d-476d-cb0d-d04d585a8fcb maxSize: 50 minSize: 2 - name: eks-data_m1-20220824130553925600000011-5ec167fa-ca93-8ca4-53a5-003e1ed8d306 maxSize: 450 minSize: 2 - name: eks-data_m2-20220824130733258600000015-aac167fb-8bf7-429d-d032-e195af4e25f5 maxSize: 450 minSize: 2 - name: eks-data_m3-20220824130553914900000003-18c167fa-ca7f-23c9-0fea-f9edefbda002 maxSize: 450 minSize: 2
ClusterAutoscaler-2
autoscalingGroups: - name: eks-data_m4-2022082413055392550000000f-5ec167fa-ca86-6b83-ae9d-1e07ade3e7c4 maxSize: 450 minSize: 2 - name: eks-data_m5-20220824130744542100000017-02c167fb-a1f7-3d9e-a583-43b4975c050c maxSize: 450 minSize: 2 - name: eks-data_m6-2022082413055392430000000d-9cc167fa-ca94-132a-04ad-e43166cef41f maxSize: 450 minSize: 2 - name: eks-data_m7-20220824130553921000000009-96c167fa-ca91-d767-0427-91c879ddf5af maxSize: 450 minSize: 2
API 우선 순위 및 공정성
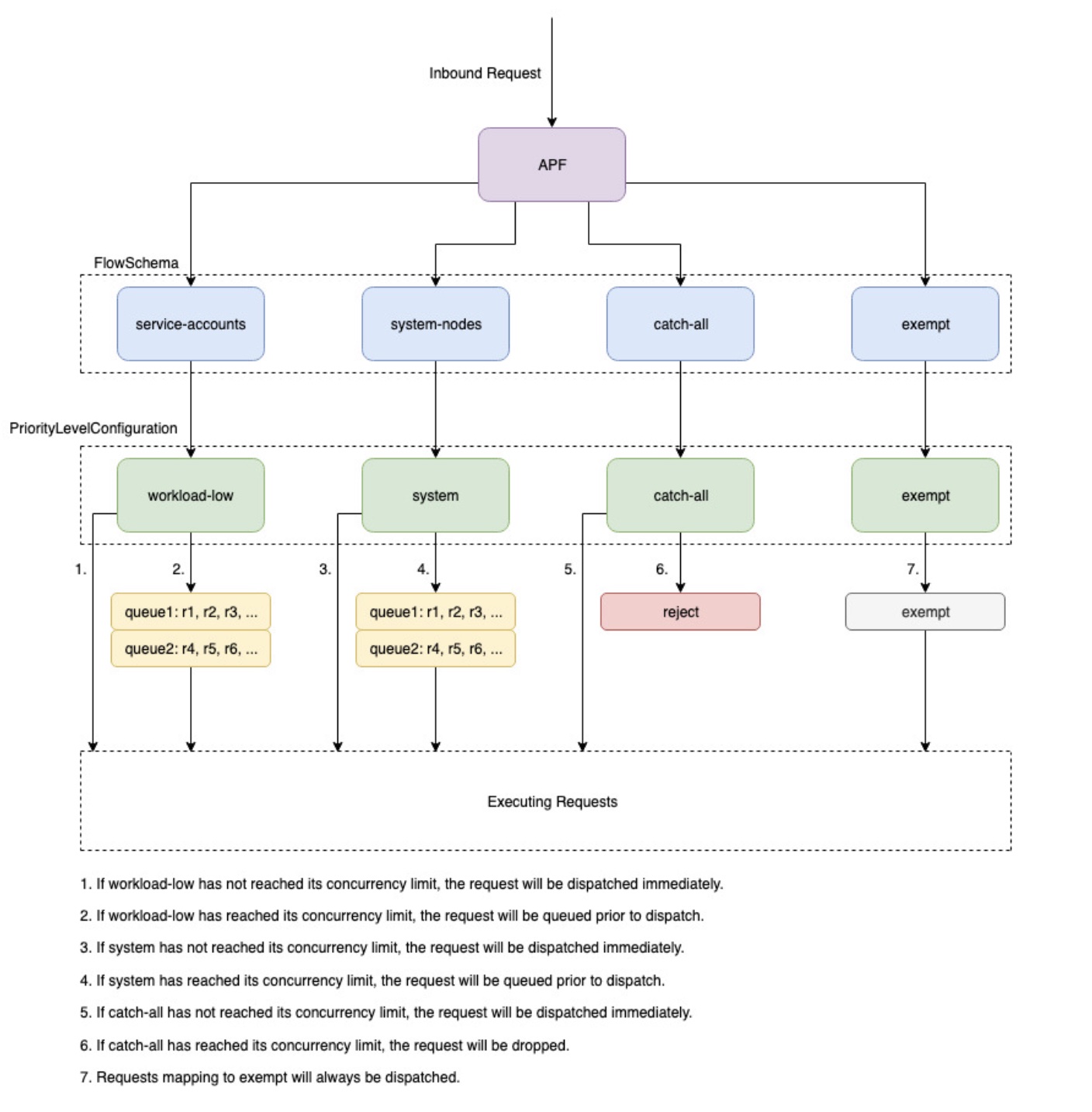
개요
요청이 증가하는 기간 동안 오버로드되지 않도록 API 서버는 지정된 시간에 미해결 상태일 수 있는 진행 중인 요청 수를 제한합니다. 이 한도를 초과하면 API 서버가 요청 거부를 시작하고 "요청이 너무 많음"에 대한 429 HTTP 응답 코드를 클라이언트에 반환합니다. 서버가 요청을 삭제하고 클라이언트가 나중에 다시 시도하도록 하는 것은 요청 수에 서버 측 제한이 없고 컨트롤 플레인에 과부하를 가하여 성능이 저하되거나 사용할 수 없게 될 수 있습니다.
Kubernetes가 이러한 진행 중인 요청을 서로 다른 요청 유형으로 나누는 방법을 구성하는 데 사용하는 메커니즘을 API 우선 순위 및 공정성--max-requests-inflight 및 --max-mutating-requests-inflight 플래그로 지정된 값을 합산하여 수락할 수 있는 총 진행 중인 요청 수를 구성합니다. EKS는 이러한 플래그에 대해 400 및 200 요청의 기본값을 사용하므로 지정된 시간에 총 600개의 요청을 디스패치할 수 있습니다. 그러나 사용률 및 워크로드 이탈 증가에 대응하여 컨트롤 플레인을 더 큰 크기로 확장하면 이에 따라 2000년까지 진행 중인 요청 할당량이 증가합니다(변경될 수 있음). APF는 이러한 진행 중인 요청 할당량을 서로 다른 요청 유형으로 더 세분화하는 방법을 지정합니다. EKS 컨트롤 플레인은 각 클러스터에 등록된 API 서버가 2개 이상 있는 고가용성입니다. 즉, 클러스터가 처리할 수 있는 총 진행 중인 요청 수가 kube-apiserver당 설정된 진행 중인 할당량의 두 배(또는 수평적으로 더 확장된 경우 더 높음)입니다. 이는 가장 큰 EKS 클러스터에서 초당 수천 개의 요청에 해당합니다.
PriorityLevelConfigurations 및 FlowSchemas라는 두 종류의 Kubernetes 객체는 총 요청 수를 서로 다른 요청 유형으로 나누는 방법을 구성합니다. 이러한 객체는 API Server에서 자동으로 유지 관리되며 EKS는 지정된 Kubernetes 마이너 버전에 대해 이러한 객체의 기본 구성을 사용합니다. PriorityLevelConfigurations는 허용된 총 요청 수의 일부를 나타냅니다. 예를 들어 워크로드가 높은 PriorityLevelConfiguration에는 총 600개의 요청 중 98개가 할당됩니다. 모든 PriorityLevelConfigurations에 할당된 요청의 합계는 600과 같습니다(또는 지정된 레벨에 요청의 일부가 부여되면 API 서버가 반올림되기 때문에 600보다 약간 높음). 클러스터의 PriorityLevelConfigurations와 각각에 할당된 요청 수를 확인하려면 다음 명령을 실행할 수 있습니다. 다음은 EKS 1.24의 기본값입니다.
$ kubectl get --raw /metrics | grep apiserver_flowcontrol_request_concurrency_limit apiserver_flowcontrol_request_concurrency_limit{priority_level="catch-all"} 13 apiserver_flowcontrol_request_concurrency_limit{priority_level="global-default"} 49 apiserver_flowcontrol_request_concurrency_limit{priority_level="leader-election"} 25 apiserver_flowcontrol_request_concurrency_limit{priority_level="node-high"} 98 apiserver_flowcontrol_request_concurrency_limit{priority_level="system"} 74 apiserver_flowcontrol_request_concurrency_limit{priority_level="workload-high"} 98 apiserver_flowcontrol_request_concurrency_limit{priority_level="workload-low"} 245
두 번째 유형의 객체는 FlowSchemas입니다. 지정된 속성 집합이 있는 API Server 요청은 동일한 FlowSchema로 분류됩니다. 이러한 속성에는 인증된 사용자 또는 API 그룹, 네임스페이스 또는 리소스와 같은 요청의 속성이 포함됩니다. FlowSchema는이 유형의 요청을 매핑해야 하는 PriorityLevelConfiguration도 지정합니다. 두 객체는 함께 "이 유형의 요청이이 진행 중인 요청 공유에 포함되기를 원합니다."라고 말합니다. 요청이 API 서버에 도달하면 필요한 모든 속성과 일치하는 FlowSchemas를 확인합니다. 여러 FlowSchemas가 요청과 일치하는 경우 API 서버는 객체의 속성으로 지정된 가장 작은 일치 우선 순위로 FlowSchema를 선택합니다.
다음 명령을 사용하여 FlowSchemas를 PriorityLevelConfigurations에 매핑할 수 있습니다.
$ kubectl get flowschemas NAME PRIORITYLEVEL MATCHINGPRECEDENCE DISTINGUISHERMETHOD AGE MISSINGPL exempt exempt 1 <none> 7h19m False eks-exempt exempt 2 <none> 7h19m False probes exempt 2 <none> 7h19m False system-leader-election leader-election 100 ByUser 7h19m False endpoint-controller workload-high 150 ByUser 7h19m False workload-leader-election leader-election 200 ByUser 7h19m False system-node-high node-high 400 ByUser 7h19m False system-nodes system 500 ByUser 7h19m False kube-controller-manager workload-high 800 ByNamespace 7h19m False kube-scheduler workload-high 800 ByNamespace 7h19m False kube-system-service-accounts workload-high 900 ByNamespace 7h19m False eks-workload-high workload-high 1000 ByUser 7h14m False service-accounts workload-low 9000 ByUser 7h19m False global-default global-default 9900 ByUser 7h19m False catch-all catch-all 10000 ByUser 7h19m False
PriorityLevelConfigurations에는 대기열, 거부 또는 면제 유형이 있을 수 있습니다. 대기열 및 거부 유형의 경우 해당 우선 순위 수준의 최대 진행 중 요청 수에 제한이 적용되지만 해당 제한에 도달하면 동작이 달라집니다. 예를 들어 워크로드가 높은 PriorityLevelConfiguration은 대기열 유형을 사용하며 컨트롤러 관리자, 엔드포인트 컨트롤러, 스케줄러,eks 관련 컨트롤러 및 kube 시스템 네임스페이스에서 실행되는 포드에서 사용할 수 있는 98개의 요청이 있습니다. 대기열 유형이 사용되므로 API 서버는 요청을 메모리에 유지하려고 시도하며 이러한 요청의 제한 시간이 초과되기 전에 진행 중인 요청 수가 98개 미만으로 감소하기를 기대합니다. 지정된 요청이 대기열에서 시간 초과되거나 너무 많은 요청이 이미 대기열에 있는 경우 API 서버는 요청을 삭제하고 클라이언트에 429를 반환할 수밖에 없습니다. 대기열에 추가하면 요청이 429를 수신하지 못할 수 있지만 요청에 대한 end-to-end 지연 시간이 증가한다는 단점이 있습니다.
이제 거부 유형으로 catch-all PriorityLevelConfiguration에 매핑되는 catch-all FlowSchema를 살펴보겠습니다. 클라이언트가 13개의 진행 중인 요청 한도에 도달하면 API 서버는 대기열을 실행하지 않고 429 응답 코드로 요청을 즉시 삭제합니다. 마지막으로 유형이 Exempt인 PriorityLevelConfiguration에 매핑된 요청은 429를 수신하지 않으며 항상 즉시 디스패치됩니다. 이는 healthz 요청 또는 system:masters 그룹에서 오는 요청과 같은 우선순위가 높은 요청에 사용됩니다.
APF 및 삭제된 요청 모니터링
APF로 인해 요청이 삭제되고 있는지 확인하기 위해에 대한 API 서버 지표를 모니터링하여 영향을 받는 FlowSchemas 및 PriorityLevelConfigurations를 확인할 apiserver_flowcontrol_rejected_requests_total 수 있습니다. 예를 들어이 지표는 워크로드가 적은 대기열에서 요청 제한 시간이 초과되어 서비스 계정 FlowSchema의 요청 100개가 삭제되었음을 보여줍니다.
% kubectl get --raw /metrics | grep apiserver_flowcontrol_rejected_requests_total
apiserver_flowcontrol_rejected_requests_total{flow_schema="service-accounts",priority_level="workload-low",reason="time-out"} 100
주어진 PriorityLevelConfiguration이 429를 수신하거나 대기열에 추가되어 지연 시간이 증가하는지 확인하려면 동시성 제한과 사용 중인 동시성 간의 차이를 비교할 수 있습니다. 이 예제에는 요청 100개의 버퍼가 있습니다.
% kubectl get --raw /metrics | grep 'apiserver_flowcontrol_request_concurrency_limit.*workload-low' apiserver_flowcontrol_request_concurrency_limit{priority_level="workload-low"} 245 % kubectl get --raw /metrics | grep 'apiserver_flowcontrol_request_concurrency_in_use.*workload-low' apiserver_flowcontrol_request_concurrency_in_use{flow_schema="service-accounts",priority_level="workload-low"} 145
지정된 PriorityLevelConfiguration에서 대기열에 추가되지만 반드시 삭제되지는 않는 요청이 있는지 확인하기 위해에 대한 지표를 참조할 apiserver_flowcontrol_current_inqueue_requests 수 있습니다.
% kubectl get --raw /metrics | grep 'apiserver_flowcontrol_current_inqueue_requests.*workload-low'
apiserver_flowcontrol_current_inqueue_requests{flow_schema="service-accounts",priority_level="workload-low"} 10
기타 유용한 Prometheus 지표는 다음과 같습니다.
-
apiserver_flowcontrol_dispatched_requests_total
-
apiserver_flowcontrol_request_execution_seconds
-
apiserver_flowcontrol_request_wait_duration_seconds
APF 지표
삭제된 요청 방지
워크로드를 변경하여 429s 방지
지정된 PriorityLevelConfiguration이 허용되는 최대 기내 요청 수를 초과하여 APF가 요청을 삭제하는 경우 영향을 받는 FlowSchemas의 클라이언트는 지정된 시간에 실행되는 요청 수를 줄일 수 있습니다. 이는 429개가 발생하는 기간 동안 이루어진 총 요청 수를 줄여 수행할 수 있습니다. 값비싼 목록 호출과 같은 장기 실행 요청은 실행 중인 전체 기간 동안 진행 중인 요청으로 계산되므로 특히 문제가 됩니다. 이러한 비용이 많이 드는 요청 수를 줄이거나 이러한 목록 호출의 지연 시간을 최적화하면(예: 요청당 가져온 객체 수를 줄이거나 감시 요청을 사용하여 로 전환) 주어진 워크로드에 필요한 총 동시성을 줄이는 데 도움이 될 수 있습니다.
APF 설정을 변경하여 429 방지
주의
수행 중인 작업을 알고 있는 경우에만 기본 APF 설정을 변경합니다. APF 설정을 잘못 구성하면 API 서버 요청이 삭제되고 워크로드가 크게 중단될 수 있습니다.
삭제된 요청을 방지하는 또 다른 방법은 EKS 클러스터에 설치된 기본 FlowSchemas 또는 PriorityLevelConfigurations를 변경하는 것입니다. EKS는 지정된 Kubernetes 마이너 버전에 대해 FlowSchemas 및 PriorityLevelConfigurations에 대한 업스트림 기본 설정을 설치합니다. 객체에 대한 다음 주석이 false로 설정되지 않는 한 API 서버는 이러한 객체를 수정하면 자동으로 기본값으로 다시 조정합니다.
metadata:
annotations:
apf.kubernetes.io/autoupdate-spec: "false"
상위 수준에서 APF 설정은 다음 중 하나로 수정할 수 있습니다.
-
관심 있는 요청에 더 많은 기내 용량을 할당합니다.
-
다른 요청 유형에 대한 용량을 부족하게 만들 수 있는 필수적이지 않거나 비용이 많이 드는 요청을 격리합니다.
이는 기본 FlowSchemas 및 PriorityLevelConfigurations를 변경하거나 이러한 유형의 새 객체를 생성하여 수행할 수 있습니다. 연산자는 관련 PriorityLevelConfigurations 객체의 assuredConcurrencyShares 값을 늘려 할당된 진행 중인 요청의 비율을 늘릴 수 있습니다. 또한 애플리케이션이 전송되기 전에 대기 중인 요청으로 인한 추가 지연 시간을 처리할 수 있는 경우 지정된 시간에 대기할 수 있는 요청 수도 증가할 수 있습니다.
또는 고객의 워크로드에 특정한 새로운 FlowSchema 및 PriorityLevelConfigurations 객체를 생성할 수 있습니다. 기존 PriorityLevelConfigurations 또는 새 PriorityLevelConfigurations에 더 많은 assuredConcurrencyShares를 할당하면 전체 제한이 API 서버당 600개의 진행 중 상태로 유지되므로 다른 버킷에서 처리할 수 있는 요청 수가 줄어듭니다.
APF 기본값을 변경할 때 비프로덕션 클러스터에서 이러한 지표를 모니터링하여 설정을 변경해도 의도하지 않은 429가 발생하지 않도록 해야 합니다.
-
모든 FlowSchemas에 대해에 대한 지표를 모니터링하여 요청을 삭제하기 시작하는 버킷이 없는지 확인해야
apiserver_flowcontrol_rejected_requests_total합니다. -
apiserver_flowcontrol_request_concurrency_limit및의 값을 비교하여 사용 중인 동시성이 해당 우선 순위 수준에 대한 제한을 위반할 위험이 없도록apiserver_flowcontrol_request_concurrency_in_use해야 합니다.
새 FlowSchema 및 PriorityLevelConfiguration을 정의하는 일반적인 사용 사례 중 하나는 격리용입니다. 장기 실행 목록 이벤트 호출을 포드에서 자체 요청 공유로 격리하려고 한다고 가정해 보겠습니다. 이렇게 하면 기존 서비스 계정 FlowSchema를 사용하는 포드의 중요한 요청이 429를 수신하고 요청 용량이 부족해지는 것을 방지할 수 있습니다. 진행 중인 요청의 총 수는 유한하지만,이 예제에서는 지정된 워크로드에 대한 요청 용량을 더 잘 분할하도록 APF 설정을 수정할 수 있음을 보여줍니다.
목록 이벤트 요청을 격리하는 FlowSchema 객체의 예:
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: FlowSchema
metadata:
name: list-events-default-service-accounts
spec:
distinguisherMethod:
type: ByUser
matchingPrecedence: 8000
priorityLevelConfiguration:
name: catch-all
rules:
- resourceRules:
- apiGroups:
- '*'
namespaces:
- default
resources:
- events
verbs:
- list
subjects:
- kind: ServiceAccount
serviceAccount:
name: default
namespace: default
-
이 FlowSchema는 기본 네임스페이스에서 서비스 계정이 수행한 모든 목록 이벤트 호출을 캡처합니다.
-
일치하는 우선 순위 8000은 기존 서비스 계정 FlowSchema에서 사용하는 값 9000보다 낮으므로 이러한 목록 이벤트 호출은 서비스 list-events-default-service-accounts 일치합니다.
-
catch-all PriorityLevelConfiguration을 사용하여 이러한 요청을 격리합니다. 이 버킷은 이러한 장기 실행 목록 이벤트 호출에서 13개의 진행 중인 요청만 사용하도록 허용합니다. 포드는 이러한 요청 중 13개 이상을 동시에 실행하려고 시도하는 즉시 429개를 수신하기 시작합니다.
API 서버에서 리소스 검색
API 서버에서 정보를 가져오는 것은 모든 크기의 클러스터에서 예상되는 동작입니다. 클러스터의 리소스 수를 조정하면 요청 빈도와 데이터 볼륨이 컨트롤 플레인의 병목 현상이 빠르게 발생하여 API 지연 시간과 속도가 느려질 수 있습니다. 지연 시간의 심각도에 따라 주의하지 않으면 예기치 않은 가동 중지가 발생합니다.
요청하는 내용과가 이러한 유형의 문제를 방지하기 위한 첫 번째 단계인 빈도를 인식합니다. 다음은 조정 모범 사례에 따라 쿼리 볼륨을 제한하는 지침입니다. 이 섹션의 제안은 최상의 규모 조정으로 알려진 옵션부터 순서대로 제공됩니다.
공유 인포머 사용
Kubernetes API와 통합되는 컨트롤러 및 자동화를 구축할 때 Kubernetes 리소스에서 정보를 가져와야 하는 경우가 많습니다. 이러한 리소스를 정기적으로 폴링하면 API 서버에 상당한 부하가 발생할 수 있습니다.
client-go 라이브러리의 정보 제공자
컨트롤러는 특히 대규모 클러스터에서 레이블 및 필드 선택기 없이 클러스터 전체 리소스를 폴링하지 않아야 합니다. 필터링되지 않은 각 폴링은 API 서버를 통해 etcd에서 많은 불필요한 데이터를 전송해야 클라이언트가 필터링할 수 있습니다. 레이블 및 네임스페이스를 기준으로 필터링하면 API 서버가 클라이언트로 전송된 요청 및 데이터를 가득 채우기 위해 수행해야 하는 작업량을 줄일 수 있습니다.
Kubernetes API 사용량 최적화
사용자 지정 컨트롤러 또는 자동화를 사용하여 Kubernetes API를 호출할 때는 호출을 필요한 리소스로만 제한하는 것이 중요합니다. 제한이 없으면 API 서버 등에 불필요한 부하가 발생할 수 있습니다.
가능하면 감시 인수를 사용하는 것이 좋습니다. 인수가 없는 경우 기본 동작은 객체를 나열하는 것입니다. 목록 대신 감시를 사용하려면 API 요청 끝에 ?watch=true를 추가할 수 있습니다. 예를 들어, 감시를 사용하여 기본 네임스페이스의 모든 포드를 가져오려면 다음을 수행합니다.
/api/v1/namespaces/default/pods?watch=true
객체를 나열하는 경우 나열하는 항목의 범위와 반환되는 데이터의 양을 제한해야 합니다. 요청에 limit=500 인수를 추가하여 반환된 데이터를 제한할 수 있습니다. fieldSelector 인수와 /namespace/ 경로는 목록의 범위를 필요에 따라 좁히는 데 유용할 수 있습니다. 예를 들어 기본 네임스페이스에서 실행 중인 포드만 나열하려면 다음 API 경로와 인수를 사용합니다.
/api/v1/namespaces/default/pods?fieldSelector=status.phase=Running&limit=500
또는 다음을 사용하여 실행 중인 모든 포드를 나열합니다.
/api/v1/pods?fieldSelector=status.phase=Running&limit=500
감시 호출 또는 나열된 객체를 제한하는 또 다른 옵션은 resourceVersions Kubernetes 설명서에서 읽을 수 있는를resourceVersion 인수가 없으면 데이터베이스에서 가장 비싸고 가장 느린 읽기인 etcd 쿼럼 읽기가 필요한 사용 가능한 최신 버전을 받게 됩니다. resourceVersion은 쿼리하려는 리소스에 따라 다르며 metadata.resourseVersion 필드에서 찾을 수 있습니다. 이는 통화 나열뿐만 아니라 감시 통화를 사용하는 경우에도 권장됩니다.
API 서버 캐시의 결과를 반환할 resourceVersion=0 수 있는 특별한 기능이 있습니다. 이렇게 하면 etcd 부하를 줄일 수 있지만 페이지 매김을 지원하지 않습니다.
/api/v1/namespaces/default/pods?resourceVersion=0
resourceVersion이 이전 목록 또는 감시에서 수신한 가장 최근 알려진 값으로 설정된 감시를 사용하는 것이 좋습니다. 이는 client-go에서 자동으로 처리됩니다. 그러나 다른 언어로 k8s 클라이언트를 사용하는 경우 다시 확인하는 것이 좋습니다.
/api/v1/namespaces/default/pods?watch=true&resourceVersion=362812295
인수 없이 API를 호출하면 API 서버 및 등에 가장 많은 리소스가 사용됩니다. 이 호출은 페이지 매김이나 범위 제한 없이 모든 네임스페이스의 모든 포드를 가져오고 etcd에서 쿼럼 읽기가 필요합니다.
/api/v1/pods
DaemonSet 천둥 군집 방지
DaemonSet는 모든(또는 일부) 노드가 포드의 복사본을 실행하도록 합니다. 노드가 클러스터에 조인하면 데몬 세트 컨트롤러가 해당 노드에 대한 포드를 생성합니다. 노드가 클러스터에서 나가면 해당 포드가 가비지 수집됩니다. DaemonSet를 삭제하면 생성된 포드가 정리됩니다.
DaemonSet의 일반적인 용도는 다음과 같습니다.
-
모든 노드에서 클러스터 스토리지 데몬 실행
-
모든 노드에서 로그 수집 데몬 실행
-
모든 노드에서 노드 모니터링 데몬 실행
수천 개의 노드가 있는 클러스터에서 새 DaemonSet를 생성하거나, DaemonSet를 업데이트하거나, 노드 수를 늘리면 컨트롤 플레인에 부하가 높아질 수 있습니다. DaemonSet 포드가 포드 시작 시 비용이 많이 드는 API 서버 요청을 발행하면 많은 수의 동시 요청으로 인해 컨트롤 플레인에서 리소스 사용량이 높아질 수 있습니다.
정상 작동에서는를 사용하여 새 DaemonSet 포드를 점진적으로 롤아웃RollingUpdate할 수 있습니다. RollingUpdate 업데이트 전략을 사용하면 DaemonSet 템플릿을 업데이트한 후 컨트롤러는 오래된 DaemonSet 포드를 종료하고 제어된 방식으로 새 DaemonSet 포드를 자동으로 생성합니다. DaemonSet의 포드는 전체 업데이트 프로세스 중에 각 노드에서 최대 1개까지 실행됩니다. 를 1, maxUnavailable를 0, maxSurge를 60으로 설정하여 점진적 롤아웃minReadySeconds을 수행할 수 있습니다. 업데이트 전략을 지정하지 않으면 Kubernetes는 기본적으로가 1, maxUnavailable가 0, RollingUpdate가 0maxSurge인 minReadySeconds를 생성합니다.
minReadySeconds: 60
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 0
maxUnavailable: 1
DaemonSet가 이미 생성되어 있고 모든 노드RollingUpdate에서 예상 포드 수가 있는 경우 Ready는 새 DaemonSet 포드를 점진적으로 롤아웃합니다. RollingUpdate 전략에서 다루지 않는 특정 조건에서는 군집 문제를 우회할 수 있습니다.
DaemonSet 생성 시 천둥 군집 방지
기본적으로 RollingUpdate 구성에 관계없이 kube-controller-manager는 새 DaemonSet를 생성할 때 일치하는 모든 노드에 대한 포드를 동시에 생성합니다. DaemonSet를 생성한 후 포드를 점진적으로 롤아웃하려면 NodeSelector 또는를 사용할 수 있습니다NodeAffinity. 그러면 0개의 노드와 일치하는 DaemonSet가 생성되고 제어된 속도로 DaemonSet에서 포드를 실행할 수 있도록 노드를 점진적으로 업데이트할 수 있습니다. 다음 접근 방식을 따를 수 있습니다.
-
의 모든 노드에 레이블을 추가합니다
run-daemonset=false.
kubectl label nodes --all run-daemonset=false
-
run-daemonset=false레이블이 없는 노드와 일치하도록NodeAffinity설정으로 DaemonSet를 생성합니다. 처음에는 DaemonSet에 해당 포드가 없습니다.
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: run-daemonset
operator: NotIn
values:
- "false"
-
노드에서 제어된 속도로
run-daemonset=false레이블을 제거합니다. 이 bash 스크립트를 예로 사용할 수 있습니다.
#!/bin/bash
nodes=$(kubectl get --raw "/api/v1/nodes" | jq -r '.items | .[].metadata.name')
for node in ${nodes[@]}; do
echo "Removing run-daemonset label from node $node"
kubectl label nodes $node run-daemonset-
sleep 5
done
-
필요에 따라 DaemonSet 객체에서
NodeAffinity설정을 제거합니다. DaemonSet 템플릿이 변경되었기 때문에 도 트리거RollingUpdate되고 기존의 모든 DaemonSet 포드가 점진적으로 교체됩니다.
노드 스케일 아웃 시 천둥 군집 방지
DaemonSet 생성과 마찬가지로 빠른 속도로 새 노드를 생성하면 많은 수의 DaemonSet 포드가 동시에 시작될 수 있습니다. 컨트롤러가 동일한 속도로 DaemonSet 포드를 생성하도록 제어된 속도로 새 노드를 생성해야 합니다. 이렇게 할 수 없는 경우를 사용하여 새 노드를 처음에 기존 DaemonSet에 적합하지 않게 만들 수 있습니다NodeAffinity. 그런 다음 데몬 세트 컨트롤러가 제어된 속도로 포드를 생성하도록 새 노드에 레이블을 점진적으로 추가할 수 있습니다. 다음 접근 방식을 따를 수 있습니다.
-
의 모든 기존 노드에 레이블 추가
run-daemonset=true
kubectl label nodes --all run-daemonset=true
-
DaemonSet를
run-daemonset=true레이블이 있는 노드와 일치하도록NodeAffinity설정으로 업데이트합니다. DaemonSet 템플릿이 변경되었기 때문에 도 트리거RollingUpdate되고 기존의 모든 DaemonSet 포드가 점진적으로 교체됩니다. 다음 단계로 진행하기 전에이RollingUpdate완료될 때까지 기다려야 합니다.
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: run-daemonset
operator: In
values:
- "true"
-
클러스터에 새 노드를 생성합니다. 이러한 노드에는
run-daemonset=true레이블이 없으므로 DaemonSet가 해당 노드와 일치하지 않습니다. -
제어된 속도로 새 노드(현재
run-daemonset=true레이블이 없음)에run-daemonset레이블을 추가합니다. 이 bash 스크립트를 예로 사용할 수 있습니다.
#!/bin/bash
nodes=$(kubectl get --raw "/api/v1/nodes?labelSelector=%21run-daemonset" | jq -r '.items | .[].metadata.name')
for node in ${nodes[@]}; do
echo "Adding run-daemonset=true label to node $node"
kubectl label nodes $node run-daemonset=true
sleep 5
done
-
필요에 따라 DaemonSet 객체에서
NodeAffinity설정을 제거하고 모든 노드에서run-daemonset레이블을 제거합니다.
DaemonSet 업데이트에서 폭동 군집 방지
RollingUpdate 정책은 인 DaemonSet 포드에 대한 maxUnavailable 설정만 준수합니다Ready. DaemonSet에 NotReady 포드만 있거나 NotReady 포드의 비율이 높고 템플릿을 업데이트하는 경우 데몬 세트 컨트롤러는 모든 포드에 대해 새 NotReady 포드를 동시에 생성합니다. 이로 인해 NotReady 포드가 지속적으로 충돌 루프 중이거나 이미지를 가져오지 못하는 경우와 같이 포드 수가 많은 경우 군집 문제가 폭증할 수 있습니다.
DaemonSet를 업데이트할 때 포드를 점진적으로 롤아웃하려면 DaemonSet의 업데이트 전략을에서 RollingUpdate로 일시적으로 변경할 NotReady 수 있습니다OnDelete. 를 사용하면 DaemonSet 템플릿을 업데이트OnDelete한 후 컨트롤러는 이전 포드를 수동으로 삭제한 후 새 포드를 생성하므로 새 포드의 롤아웃을 제어할 수 있습니다. 다음 접근 방식을 따를 수 있습니다.
-
DaemonSet에
NotReady포드가 있는지 확인합니다. -
그렇지 않은 경우 DaemonSet 템플릿을 안전하게 업데이트할 수 있으며
RollingUpdate전략은 점진적인 롤아웃을 보장합니다. -
그렇다면 먼저
OnDelete전략을 사용하도록 DaemonSet를 업데이트해야 합니다.
updateStrategy: type: OnDelete
-
그런 다음 DaemonSet 템플릿을 필요한 변경 사항으로 업데이트합니다.
-
이 업데이트 후 제어된 속도로 포드 삭제 요청을 실행하여 이전 DaemonSet 포드를 삭제할 수 있습니다. 이 bash 스크립트를 kube-system 네임스페이스에서 DaemonSet 이름이 fluentd-elasticsearch인 예제로 사용할 수 있습니다.
#!/bin/bash
daemonset_pods=$(kubectl get --raw "/api/v1/namespaces/kube-system/pods?labelSelector=name%3Dfluentd-elasticsearch" | jq -r '.items | .[].metadata.name')
for pod in ${daemonset_pods[@]}; do
echo "Deleting pod $pod"
kubectl delete pod $pod -n kube-system
sleep 5
done
-
마지막으로 DaemonSet를 이전
RollingUpdate전략으로 다시 업데이트할 수 있습니다.
