기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon EMR on EKS 시작하기
이 주제는 가상 클러스터에 Spark 애플리케이션을 배포하여 Amazon EMR on EKS 사용을 시작하는 데 도움이 됩니다. 여기에는 올바른 권한을 설정하고 작업을 시작하는 단계가 포함되어 있습니다. 시작하기 전에 먼저 Amazon EMR on EKS 설정의 단계를 완료해야 합니다. 이렇게 하면 가상 클러스터를 생성하기 전에 AWS CLI 설정과 같은 도구를 얻을 수 있습니다. 시작하는 데 도움이 되는 다른 템플릿은 GitHub의 EMR Containers Best Practices Guide
설정 단계에서 다음 정보가 필요합니다.
-
Amazon EMR에 등록된 Amazon EKS 클러스터 및 Kubernetes 네임스페이스의 가상 클러스터 ID
중요
EKS 클러스터를 생성할 때 m5.xlarge를 인스턴스 유형으로 사용하거나 CPU와 메모리가 더 큰 다른 인스턴스 유형으로 사용해야 합니다. m5.xlarge보다 CPU 또는 메모리가 더 적은 인스턴스 유형을 사용하면 클러스터에서 사용 가능한 리소스가 부족하여 작업이 실패할 수 있습니다.
-
작업 실행에 사용되는 IAM 역할의 이름
-
Amazon EMR 릴리스의 릴리스 레이블(예:
emr-6.4.0-latest) -
로깅 및 모니터링을 위한 대상:
-
Amazon CloudWatch 로그 그룹 이름 및 로그 스트림 접두사
-
이벤트 및 컨테이너 로그를 저장하는 Amazon S3 위치
-
중요
Amazon EMR on EKS 작업은 모니터링 및 로깅을 위한 대상으로 Amazon CloudWatch 및 Amazon S3를 사용합니다. 이러한 대상으로 전송된 작업 로그를 확인하여 작업 진행 상황을 모니터링하고 실패 문제를 해결할 수 있습니다. 로깅을 활성화하려면 작업 실행을 위해 IAM 역할과 연결된 IAM 정책에 대상 리소스에 액세스하는 데 필요한 권한이 있어야 합니다. IAM 정책에 필요한 권한이 없는 경우 이 샘플 작업을 실행하기 전에 작업 실행 역할의 신뢰 정책 업데이트, Amazon S3 로그를 사용하도록 작업 실행 구성 및 CloudWatch Logs를 사용하도록 작업 실행 구성에 설명된 단계를 따라야 합니다.
Spark 애플리케이션 실행
Amazon EMR on EKS에서 간단한 Spark 애플리케이션을 실행하려면 다음 단계를 수행합니다. Spark Python 애플리케이션의 애플리케이션 entryPoint 파일은 s3://에 있습니다. REGION.elasticmapreduce/emr-containers/samples/wordcount/scripts/wordcount.pyREGION은 Amazon EMR on EKS 가상 클러스터가 상주하는 리전(예: us-east-1)입니다.
-
다음 정책 명령문에서 볼 수 있듯이 작업 실행 역할에 대한 IAM 정책을 필요한 권한으로 업데이트합니다.
-
이 정책의 첫 번째
ReadFromLoggingAndInputScriptBuckets문에서는 다음 Amazon S3 버킷에ListBucket및GetObjects액세스 권한을 부여합니다.-
REGION.elasticmapreduceentryPoint파일이 있는 버킷. -
amzn-s3-demo-destination-bucket- 출력 데이터에 대해 정의하는 버킷. -
amzn-s3-demo-logging-bucket‐ 로깅 데이터에 대해 정의하는 버킷.
-
-
이 정책의 두 번째
WriteToLoggingAndOutputDataBuckets문에서는 출력 및 로깅 버킷에 각각 데이터를 쓸 수 있는 작업 권한을 부여합니다. -
세 번째
DescribeAndCreateCloudwatchLogStream문에서는 Amazon CloudWatch Logs를 설명하고 생성할 수 있는 작업 권한을 부여합니다. -
네 번째
WriteToCloudwatchLogs문에서는my_log_stream_prefixmy_log_group_name
-
-
Spark Python 애플리케이션을 실행하려면 다음 명령을 사용합니다. 모든 교체 가능한
빨간색 기울임꼴값을 적절한 값으로 바꿉니다.REGION은 Amazon EMR on EKS 가상 클러스터가 상주하는 리전(예:us-east-1)입니다.aws emr-containers start-job-run \ --virtual-cluster-idcluster_id\ --namesample-job-name\ --execution-role-arnexecution-role-arn\ --release-labelemr-6.4.0-latest\ --job-driver '{ "sparkSubmitJobDriver": { "entryPoint": "s3://REGION.elasticmapreduce/emr-containers/samples/wordcount/scripts/wordcount.py", "entryPointArguments": ["s3://amzn-s3-demo-destination-bucket/wordcount_output"], "sparkSubmitParameters": "--conf spark.executor.instances=2 --conf spark.executor.memory=2G --conf spark.executor.cores=2 --conf spark.driver.cores=1" } }' \ --configuration-overrides '{ "monitoringConfiguration": { "cloudWatchMonitoringConfiguration": { "logGroupName": "my_log_group_name", "logStreamNamePrefix": "my_log_stream_prefix" }, "s3MonitoringConfiguration": { "logUri": "s3://amzn-s3-demo-logging-bucket" } } }'이 작업의 출력 데이터는
s3://에서 확인할 수 있습니다.amzn-s3-demo-destination-bucket/wordcount_output작업 실행을 위해 지정된 파라미터를 사용하여 JSON 파일을 생성할 수도 있습니다. 그런 다음 JSON 파일 경로와 함께
start-job-run명령을 실행합니다. 자세한 내용은 StartJobRun을 사용하여 작업 실행 제출 단원을 참조하십시오. 작업 실행 파라미터 구성에 대한 자세한 내용은 작업 실행 구성 옵션 섹션을 참조하세요. -
Spark SQL 애플리케이션을 실행하려면 다음 명령을 사용합니다. 모든
빨간색 기울임꼴값을 적절한 값으로 바꿉니다.REGION은 Amazon EMR on EKS 가상 클러스터가 상주하는 리전(예:us-east-1)입니다.aws emr-containers start-job-run \ --virtual-cluster-idcluster_id\ --namesample-job-name\ --execution-role-arnexecution-role-arn\ --release-labelemr-6.7.0-latest\ --job-driver '{ "sparkSqlJobDriver": { "entryPoint": "s3://query-file.sql", "sparkSqlParameters": "--conf spark.executor.instances=2 --conf spark.executor.memory=2G --conf spark.executor.cores=2 --conf spark.driver.cores=1" } }' \ --configuration-overrides '{ "monitoringConfiguration": { "cloudWatchMonitoringConfiguration": { "logGroupName": "my_log_group_name", "logStreamNamePrefix": "my_log_stream_prefix" }, "s3MonitoringConfiguration": { "logUri": "s3://amzn-s3-demo-logging-bucket" } } }'샘플 SQL 쿼리 파일은 다음과 같습니다. 테이블의 데이터가 저장되는 외부 파일 스토어(예: S3)가 있어야 합니다.
CREATE DATABASE demo; CREATE EXTERNAL TABLE IF NOT EXISTS demo.amazonreview( marketplace string, customer_id string, review_id string, product_id string, product_parent string, product_title string, star_rating integer, helpful_votes integer, total_votes integer, vine string, verified_purchase string, review_headline string, review_body string, review_date date, year integer) STORED AS PARQUET LOCATION 's3://URI to parquet files'; SELECT count(*) FROM demo.amazonreview; SELECT count(*) FROM demo.amazonreview WHERE star_rating = 3;이 작업에 대한 출력은 구성된
monitoringConfiguration에 따라 S3 또는 CloudWatch의 드라이버 stdout 로그에서 확인할 수 있습니다. -
작업 실행을 위해 지정된 파라미터를 사용하여 JSON 파일을 생성할 수도 있습니다. 그런 다음 JSON 파일 경로와 함께 start-job-run 명령을 실행합니다. 자세한 내용은 작업 실행 제출을 참조하세요. 작업 실행 파라미터 구성에 대한 자세한 내용은 작업 실행 구성 옵션을 참조하세요.
작업 진행 상황을 모니터링하거나 실패를 디버깅하기 위해 Amazon S3, CloudWatch Logs 또는 둘 다에 업로드된 로그를 검사할 수 있습니다. S3 로그를 사용하도록 작업 실행 구성에서 Amazon S3의 로그 경로를 참조하고, CloudWatch Logs를 사용하도록 작업 실행 구성에서 Cloudwatch 로그의 로그 경로를 참조하세요. CloudWatch Logs에서 로그를 보려면 아래 지침을 따릅니다.
-
https://console.aws.amazon.com/cloudwatch/
에서 CloudWatch 콘솔을 엽니다. -
탐색 창에서 로그를 선택합니다. 그리고 로그 그룹을 선택합니다.
-
Amazon EMR on EKS에 대한 로그 그룹을 선택하고 업로드된 로그 이벤트를 확인합니다.
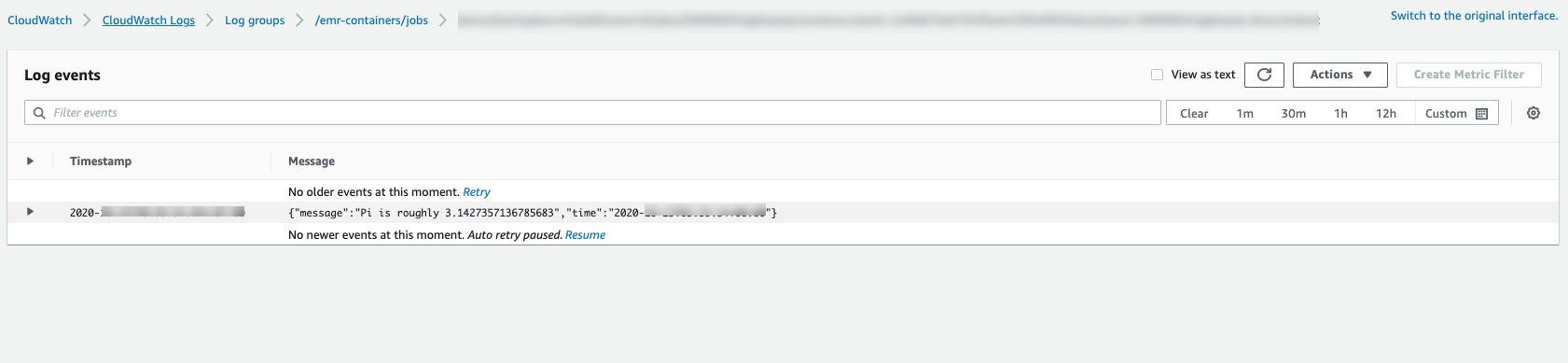
-
중요
작업에는 기본적으로 구성된 재시도 정책이 있습니다. 구성을 수정하거나 비활성화하는 방법에 대한 자세한 내용은 작업 재시도 정책 사용을 참조하세요.
