기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
튜토리얼: 아마존 시작하기 EMR
워크플로를 따라 Amazon EMR 클러스터를 빠르게 설정하고 Spark 애플리케이션을 실행하십시오.
Amazon EMR 클러스터 설정
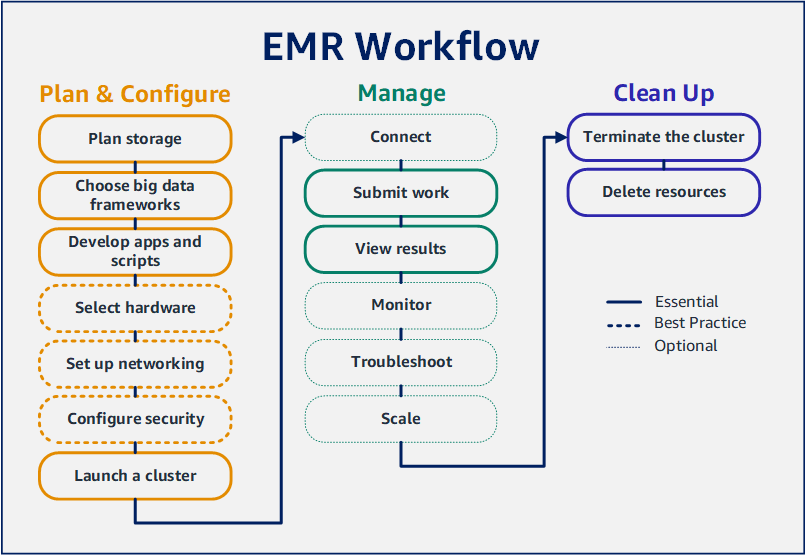
EMRAmazon을 사용하면 단 몇 분 만에 빅 데이터 프레임워크로 데이터를 처리하고 분석하도록 클러스터를 설정할 수 있습니다. 이 자습서에서는 Spark를 사용하여 샘플 클러스터를 시작하는 방법과 Amazon S3 버킷에 저장된 간단한 PySpark 스크립트를 실행하는 방법을 보여줍니다. 계획 및 구성, 관리, 정리라는 세 가지 주요 워크플로 범주에서 필수적인 Amazon EMR 작업을 다룹니다.
다음 단계 섹션에서는 자습서를 진행하면서 더 자세한 주제로 연결되는 링크와 추가 단계에 대한 아이디어를 제공합니다. 질문이 있거나 문제가 있는 경우 토론 포럼의
사전 조건
-
Amazon EMR 클러스터를 시작하기 전에 에서 작업을 완료해야 Amazon을 설정하기 전 EMR 합니다.
비용
-
사용자가 생성하는 샘플 클러스터는 실제 환경에서 실행됩니다. 클러스터에는 최소 요금이 누적됩니다. 추가 요금이 발생하지 않도록 하려면 이 자습서의 마지막 단계에서 정리 작업을 완료해야 합니다. 요금은 Amazon 요금에 따라 초당 요율로 부과됩니다. EMR 요금은 리전에 따라서도 다릅니다. 자세한 내용은 Amazon EMR 요금을
참조하십시오. -
Amazon S3에 저장하는 작은 파일에도 최소 요금이 누적될 수 있습니다. 다음의 사용량 한도 내에 있는 경우 Amazon S3에 대한 요금의 일부 또는 전부가 면제될 수 있습니다. AWS 프리 티어. 자세한 내용은 Amazon S3 요금을
참조하십시오. AWS 프리 티어 .
1단계: 데이터 리소스 구성 및 Amazon EMR 클러스터 시작
Amazon용 스토리지 준비 EMR
EMRAmazon을 사용하면 다양한 파일 시스템 중에서 선택하여 입력 데이터, 출력 데이터 및 로그 파일을 저장할 수 있습니다. 이 자습서에서는 S3 버킷에 데이터를 저장하는 EMRFS 데 사용합니다. EMRFSAmazon S3에서 일반 파일을 읽고 쓸 수 있게 해주는 하둡 파일 시스템의 구현입니다. 자세한 내용은 스토리지 및 파일 시스템 사용 단원을 참조하십시오.
이 자습서에서 사용할 버킷을 생성하려면 Amazon Simple Storage Service 사용 설명서에서 S3 버킷을 생성하려면 어떻게 해야 하나요?의 지침을 따릅니다. 동일한 위치에 버킷을 생성합니다. AWS Amazon EMR 클러스터를 시작하려는 지역 예를 들어, 미국 서부(오레곤) us-west-2와 같습니다.
Amazon에서 사용하는 버킷 및 EMR 폴더에는 다음과 같은 제한이 있습니다.
-
이름에 소문자, 숫자, 마침표(.), 하이픈(-)을 포함할 수 있습니다.
-
이름은 숫자로 끝날 수 없습니다.
-
버킷 이름은 모든 버킷에서 고유해야 합니다. AWS 계정.
-
출력 폴더는 비어 있어야 합니다.
Amazon용 입력 데이터로 애플리케이션 준비 EMR
Amazon용 애플리케이션을 준비하는 가장 일반적인 방법은 애플리케이션과 해당 입력 데이터를 Amazon EMR S3에 업로드하는 것입니다. 그런 다음 클러스터에 작업을 제출할 때 스크립트와 데이터에 대한 Amazon S3 위치를 지정합니다.
이 단계에서는 Amazon S3 버킷에 샘플 PySpark 스크립트를 업로드합니다. 사용할 수 있는 PySpark 스크립트를 제공했습니다. 스크립트는 식품 시설 검사 데이터를 처리하고 S3 버킷에 결과 파일을 반환합니다. 결과 파일에는 'Red' 유형 위반이 가장 많은 상위 10개 시설이 나열됩니다.
또한 PySpark 스크립트에서 처리할 샘플 입력 데이터를 Amazon S3에 업로드합니다. 입력 데이터는 2006년부터 2020년까지 워싱턴 주 킹 카운티의 보건부 검사 결과를 수정한 버전입니다. 자세한 내용은 King County Open Data: Food Establishment Inspection Data
name, inspection_result, inspection_closed_business, violation_type, violation_points 100 LB CLAM, Unsatisfactory, FALSE, BLUE, 5 100 PERCENT NUTRICION, Unsatisfactory, FALSE, BLUE, 5 7-ELEVEN #2361-39423A, Complete, FALSE, , 0
예제 PySpark 스크립트를 준비하려면 EMR
-
원하는 편집기에서 아래 예제 코드를 새 파일에 복사합니다.
import argparse from pyspark.sql import SparkSession def calculate_red_violations(data_source, output_uri): """ Processes sample food establishment inspection data and queries the data to find the top 10 establishments with the most Red violations from 2006 to 2020. :param data_source: The URI of your food establishment data CSV, such as 's3://DOC-EXAMPLE-BUCKET/food-establishment-data.csv'. :param output_uri: The URI where output is written, such as 's3://DOC-EXAMPLE-BUCKET/restaurant_violation_results'. """ with SparkSession.builder.appName("Calculate Red Health Violations").getOrCreate() as spark: # Load the restaurant violation CSV data if data_source is not None: restaurants_df = spark.read.option("header", "true").csv(data_source) # Create an in-memory DataFrame to query restaurants_df.createOrReplaceTempView("restaurant_violations") # Create a DataFrame of the top 10 restaurants with the most Red violations top_red_violation_restaurants = spark.sql("""SELECT name, count(*) AS total_red_violations FROM restaurant_violations WHERE violation_type = 'RED' GROUP BY name ORDER BY total_red_violations DESC LIMIT 10""") # Write the results to the specified output URI top_red_violation_restaurants.write.option("header", "true").mode("overwrite").csv(output_uri) if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument( '--data_source', help="The URI for you CSV restaurant data, like an S3 bucket location.") parser.add_argument( '--output_uri', help="The URI where output is saved, like an S3 bucket location.") args = parser.parse_args() calculate_red_violations(args.data_source, args.output_uri) -
파일을
health_violations.py(으)로 저장합니다. -
이 자습서에서 생성한 Amazon S3의 버킷에
health_violations.py를 업로드합니다. 지침을 보려면 Amazon Simple Storage Service 시작하기 안내서에서 버킷에 객체 업로드를 참조하세요.
샘플 입력 데이터를 준비하려면 EMR
-
zip 파일(food_establishment_data.zip)를 다운로드합니다.
-
압축을 풀고 컴퓨터에
food_establishment_data.zip을food_establishment_data.csv으로 저장합니다. -
이 자습서에서 생성한 S3 버킷에 CSV 파일을 업로드합니다. 지침을 보려면 Amazon Simple Storage Service 시작하기 안내서에서 버킷에 객체 업로드를 참조하세요.
데이터 설정에 대한 자세한 내용은 EMR 을 참조하십시오처리를 위한 입력 데이터 준비.
Amazon EMR 클러스터 시작
스토리지 위치와 애플리케이션을 준비한 후 샘플 Amazon EMR 클러스터를 시작할 수 있습니다. 이 단계에서는 최신 Amazon EMR 릴리스 버전을 사용하여 Apache Spark 클러스터를 시작합니다.
2단계: Amazon EMR 클러스터에 작업 제출
작업 제출 및 결과 보기
클러스터를 시작한 후 실행 중인 클러스터에 작업을 제출하여 데이터를 처리하고 분석할 수 있습니다. 한 단계로 Amazon EMR 클러스터에 작업을 제출합니다. 단계는 하나 이상의 작업으로 구성된 작업 단위입니다. 예를 들어 값을 계산하거나 데이터를 전송 및 처리하는 단계를 제출할 수 있습니다. 단계는 클러스터를 실행할 때 제출하거나 실행 중인 클러스터에 제출할 수도 있습니다. 자습서의 이 부분에서는 실행 중인 클러스터에 단계로 health_violations.py를 제출합니다. 단계에 대한 자세한 내용은 클러스터에 작업 제출 섹션을 참조하세요.
단계 수명 주기에 대한 자세한 내용은 단계를 실행하여 데이터 처리 섹션을 참조하세요.
결과 보기
단계가 성공적으로 실행되면 Amazon S3 출력 폴더에서 출력 결과를 볼 수 있습니다.
health_violations.py의 결과를 보는 방법
에서 Amazon S3 콘솔을 엽니다 https://console.aws.amazon.com/s3/
. -
버킷 이름을 선택하고 단계를 제출할 때 지정한 출력 폴더를 선택합니다. 예:
DOC-EXAMPLE-BUCKET그리고 나서myOutputFolder. -
출력 폴더에 다음 항목이 나타나는지 확인합니다.
-
_SUCCESS라고 하는 작은 크기의 객체. -
접두사로 시작하는 CSV 파일로,
part-결과가 들어 있습니다.
-
-
결과를 포함하는 개체를 선택하고 다운로드를 선택하여 결과를 로컬 파일 시스템에 저장합니다.
-
원하는 편집기에서 결과를 엽니다. 출력 파일에는 Red 위반이 가장 많은 상위 10개 식품 시설이 나열됩니다. 또한 출력 파일에는 각 시설의 총 Red 위반 건수도 표시됩니다.
다음은
health_violations.py결과 예제입니다.name, total_red_violations SUBWAY, 322 T-MOBILE PARK, 315 WHOLE FOODS MARKET, 299 PCC COMMUNITY MARKETS, 251 TACO TIME, 240 MCDONALD'S, 177 THAI GINGER, 153 SAFEWAY INC #1508, 143 TAQUERIA EL RINCONSITO, 134 HIMITSU TERIYAKI, 128
Amazon EMR 클러스터 출력에 대한 자세한 내용은 을 참조하십시오Amazon EMR 클러스터 출력 위치 구성.
EMRAmazon을 사용하는 경우 실행 중인 클러스터에 연결하여 로그 파일을 읽거나 클러스터를 디버깅하거나 Spark 셸과 같은 CLI 도구를 사용하는 것이 좋습니다. EMRAmazon에서는 Secure Shell (SSH) 프로토콜을 사용하여 클러스터에 연결할 수 있습니다. 이 섹션에서는 Spark의 구성SSH, 클러스터 연결 및 로그 파일 확인 방법을 다룹니다. 클러스터에 연결하는 방법에 대한 자세한 내용은 Amazon EMR 클러스터 노드에 인증 섹션을 참조하세요.
클러스터 SSH 연결을 승인하세요.
클러스터에 연결하기 전에 클러스터 보안 그룹을 수정하여 SSH 인바운드 연결을 승인해야 합니다. Amazon EC2 보안 그룹은 클러스터로 향하는 인바운드 및 아웃바운드 트래픽을 제어하는 가상 방화벽 역할을 합니다. 이 자습서를 위해 클러스터를 생성할 때 Amazon은 사용자를 대신하여 다음과 같은 보안 그룹을 EMR 생성했습니다.
- ElasticMapReduce-마스터
-
기본 노드와 연결된 기본 Amazon EMR 관리형 보안 그룹입니다. Amazon EMR 클러스터에서 기본 노드는 클러스터를 관리하는 Amazon EC2 인스턴스입니다.
- ElasticMapReduce-슬레이브
-
코어 및 태스크 노드에 연결된 기본 보안 그룹.
를 사용하여 클러스터에 연결 AWS CLI
운영 체제와 상관없이 다음을 사용하여 클러스터에 SSH 연결할 수 있습니다. AWS CLI.
를 사용하여 클러스터에 연결하고 로그 파일을 보려면 AWS CLI
-
다음 명령을 사용하여 클러스터에 대한 SSH 연결을 엽니다. Replace
<mykeypair.key>키 페어 파일의 전체 경로와 파일 이름을 포함합니다. 예:C:\Users\<username>\.ssh\mykeypair.pem.aws emr ssh --cluster-id<j-2AL4XXXXXX5T9>--key-pair-file<~/mykeypair.key> -
/mnt/var/log/spark로 이동하여 클러스터의 프라이머리 노드에서 Spark 로그에 액세스합니다. 그런 다음 해당 위치에 있는 파일을 봅니다. 프라이머리 노드의 추가 로그 파일 목록은 프라이머리 노드에서 로그 파일 보기 섹션을 참조하세요.cd /mnt/var/log/spark ls
3단계: Amazon EMR 리소스 정리
클러스터 종료
이제 클러스터에 작업을 제출하고 PySpark 신청 결과를 확인했으므로 클러스터를 종료할 수 있습니다. 클러스터를 종료하면 클러스터와 관련된 모든 Amazon EMR 요금 및 Amazon EC2 인스턴스가 중지됩니다.
클러스터를 종료하면 Amazon은 클러스터에 대한 메타데이터를 2개월 동안 무료로 EMR 보관합니다. 아카이브된 메타데이터는 새 작업을 위해 클러스터를 복제하거나 참조용으로 클러스터 구성을 다시 검토하는 데 도움이 됩니다. 클러스터가 S3에 쓰는 데이터나 HDFS 클러스터에 저장된 데이터는 메타데이터에 포함되지 않습니다.
참고
Amazon EMR 콘솔에서는 클러스터를 종료한 후 목록 보기에서 클러스터를 삭제할 수 없습니다. Amazon이 메타데이터를 EMR 지우면 종료된 클러스터가 콘솔에서 사라집니다.
S3 리소스 삭제
추가 비용을 피하려면 Amazon S3 버킷을 삭제해야 합니다. 버킷을 삭제하면 이 자습서의 모든 Amazon S3 리소스가 제거됩니다. 버킷에는 다음이 포함되어야 합니다.
-
스크립트 PySpark
-
입력 데이터 세트
-
출력 결과 폴더
-
로그 파일 폴더
PySpark 스크립트나 출력을 다른 위치에 저장한 경우 저장된 파일을 삭제하려면 추가 단계를 수행해야 할 수 있습니다.
참고
버킷을 삭제하기 전에 클러스터를 종료해야 합니다. 그렇지 않으면 버킷을 비울 수 없습니다.
버킷을 삭제하려면 Amazon Simple Storage Service 사용 설명서에서 S3 버킷을 삭제하려면 어떻게 해야 하나요?의 지침을 따릅니다.
다음 단계
이제 첫 번째 Amazon EMR 클러스터를 처음부터 끝까지 시작했습니다. 빅 데이터 애플리케이션 준비 및 제출, 결과 보기, 클러스터 종료와 같은 필수 EMR 작업도 완료했습니다.
Amazon EMR 워크플로를 사용자 지정하는 방법에 대해 자세히 알아보려면 다음 주제를 참조하십시오.
Amazon용 빅 데이터 애플리케이션 살펴보기 EMR
Amazon EMR 릴리스 가이드에서 클러스터에 설치할 수 있는 빅 데이터 애플리케이션을 검색하고 비교해 보십시오. 릴리스 안내서에는 각 EMR 릴리스 버전이 자세히 설명되어 있으며 Amazon에서 Spark 및 Hadoop과 같은 프레임워크를 사용하기 위한 팁이 포함되어 있습니다. EMR
클러스터 하드웨어, 네트워킹 및 보안 계획
이 자습서에서는 고급 옵션을 EMR 구성하지 않고 간단한 클러스터를 생성했습니다. 고급 옵션을 사용하면 Amazon EC2 인스턴스 유형, 클러스터 네트워킹 및 클러스터 보안을 지정할 수 있습니다. 요구 사항을 충족하는 클러스터를 계획하고 시작하는 방법에 대한 자세한 내용은 Amazon EMR 클러스터 계획, 구성 및 시작 및 아마존의 보안 EMR 섹션을 참조하세요.
클러스터 관리
Amazon EMR 클러스터 관리에서 클러스터를 실행하는 작업에 대해 자세히 알아봅니다. 클러스터를 관리하기 위해 클러스터에 연결하고, 단계를 디버깅하며, 클러스터 활동 및 상태를 추적할 수 있습니다. 또한 EMR관리형 규모 조정을 통해 워크로드 수요에 따라 클러스터 리소스를 조정할 수 있습니다.
다른 인터페이스 사용
Amazon EMR 콘솔 외에도 다음을 EMR 사용하여 Amazon을 관리할 수 있습니다. AWS Command Line Interface, 웹 서비스 API 또는 지원되는 여러 서비스 중 하나 AWS SDKs. 자세한 내용은 관리 인터페이스 단원을 참조하십시오.
또한 다양한 방법으로 Amazon EMR 클러스터에 설치된 애플리케이션과 상호 작용할 수 있습니다. Apache Hadoop과 같은 일부 애플리케이션은 사용자가 볼 수 있는 웹 인터페이스를 게시합니다. 자세한 내용은 Amazon EMR 클러스터에서 호스팅되는 웹 인터페이스 보기 단원을 참조하십시오.
EMR기술 블로그 찾아보기
새로운 Amazon EMR 기능에 대한 샘플 안내 및 심층적인 기술 논의는 다음을 참조하십시오. AWS 빅 데이터 블로그.
