기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Flink 오토스케일러
개요
Amazon EMR 릴리스 6.15.0 이상에서는 Flink 오토스케일러를 지원합니다. 작업 오토스케일러 조정 기능은 실행 중인 Flink 스트리밍 작업에서 지표를 수집하고 개별 작업 버텍스의 규모를 자동 조정합니다. 그 결과 역압이 줄고 설정한 사용률 목표를 달성할 수 있습니다.
자세한 내용을 확인하려면 Apache Flink Kubernetes 연산자 문서의 오토스케일러
고려 사항
-
Flink 오토스케일러는 Amazon EMR 6.15.0 이상에서 지원됩니다.
-
Flink 오토스케일러는 스트리밍 작업에 대해서만 지원됩니다.
-
적응형 스케줄러만 지원됩니다. 기본 스케줄러는 지원되지 않습니다.
-
동적 리소스 프로비저닝을 위해 클러스터 스케일링 기능을 활성화할 것을 권장합니다. Amazon EMR Managed Scaling이 선호되는 이유는 5~10초마다 지표 평가가 발생하기 때문입니다. 이 간격에서 클러스터는 필요한 클러스터 리소스의 변화에 더 쉽게 적응할 수 있습니다.
오토스케일러 활성화
EC2 클러스터에서 Amazon EMR을 만드는 경우 다음 단계를 사용하여 Flink 오토스케일러를 활성화하세요.
-
Amazon EMR 콘솔에서 새 EMR 클러스터를 생성합니다.
-
Amazon EMR 릴리스
emr-6.15.0이상을 선택합니다. Flink 애플리케이션 번들을 선택하고 클러스터에 포함하려는 다른 애플리케이션을 선택합니다.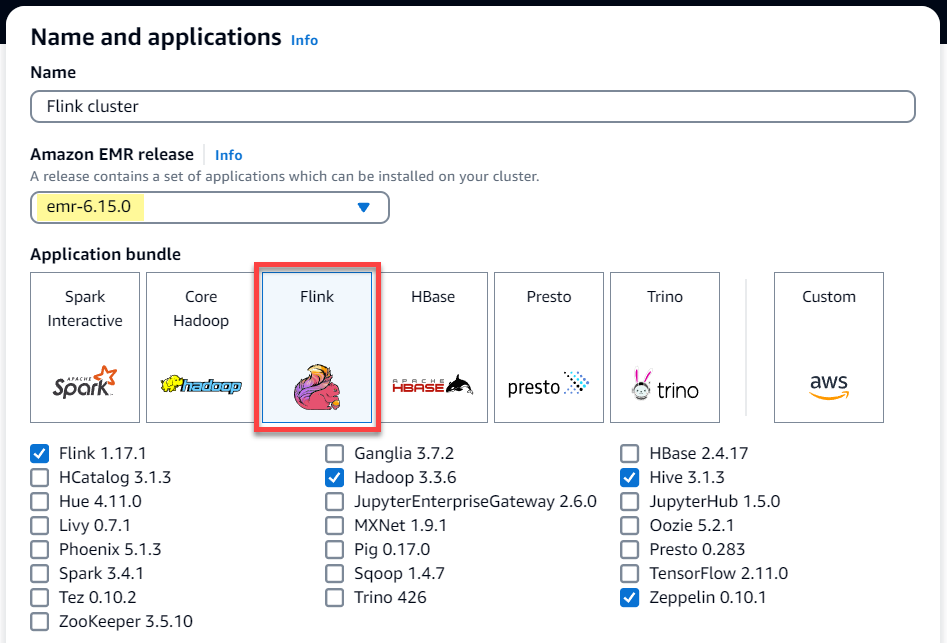
-
클러스터 크기 조정 및 프로비저닝 옵션에서 EMR 관리형 크기 조정 사용을 선택합니다.

-
-
소프트웨어 설정 섹션에서 다음 구성을 입력하고 Flink 오토스케일러를 활성화합니다. 테스트 시나리오의 경우에는, 결정 간격, 지표 창 간격 및 안정화 간격을 더 낮은 값으로 설정하여 작업에서 조정 결정이 즉시 내려져 검증이 수월해지도록 합니다.
[ { "Classification": "flink-conf", "Properties": { "job.autoscaler.enabled": "true", "jobmanager.scheduler": "adaptive", "job.autoscaler.stabilization.interval": "60s", "job.autoscaler.metrics.window": "60s", "job.autoscaler.decision.interval": "10s", "job.autoscaler.debug.logs.interval": "60s" } } ] -
원하는 기타 설정을 선택하거나 구성한 후 Flink 오토스케일러를 사용하는 클러스터를 만드세요.
오토스케일러 구성
이 섹션에서는 특정한 요구 사항을 토대로 변경할 수 있는 구성들을 대부분 설명합니다.
참고
time, interval 및 window 설정과 같은 시간 기반 구성을 사용하는 경우, 단위가 지정되지 않은 경우의 기본 단위는 밀리초입니다. 따라서 접미사가 없는 30 값은 30밀리초입니다. 기타 시간 단위의 경우에는, 초의 경우 s, 분의 경우 m, 또는 시간의 경우 h를 적절한 접미사로 포함하세요.
오토스케일러 루프 구성
오토스케일러는 몇 개의 구성 가능 시간 간격마다 작업 버텍스 레벨 지표를 가져와 실행 가능한 규모로 배율로 변환하고, 신규 작업 버텍스 병렬 처리를 예측하며, 이를 작업 스케줄러에 권장합니다. 지표는 작업 재시작 시간과 클러스터 안정화 간격 이후에만 수집됩니다.
| Config 키 | 기본값 | 설명 | 예제 값 |
|---|---|---|---|
job.autoscaler.enabled |
false |
Flink 클러스터에서 오토스케일링을 활성화합니다. | true, false |
job.autoscaler.decision.interval |
60s |
오토스케일러 결정 간격입니다. | 30(기본 단위는 밀리초), 5m, 1h |
job.autoscaler.restart.time |
3m |
운영자가 기록을 통해 확실하게 판단할 수 있을 때까지 사용하는 예상 재시작 시간입니다. | 30(기본 단위는 밀리초), 5m, 1h |
job.autoscaler.stabilization.interval |
300s |
새로운 조정이 실행되지 않는 안정화 기간입니다. | 30(기본 단위는 밀리초), 5m, 1h |
job.autoscaler.debug.logs.interval |
300s |
오토스케일러 디버그 로그 간격입니다. | 30(기본 단위는 밀리초), 5m, 1h |
지표 집계 및 기록 구성
오토스케일러는 지표를 가져와 시간 기반 슬라이딩 창에 대해 집계하고, 이 항목에 대한 평가를 통해 규모 조정 결정이 내려집니다. 각 작업 버텍스에 대한 규모 조정 결정 기록은 새로운 병렬 처리를 추정하는 데 활용됩니다. 이러한 항목에는 연령 기반 만료일과 기록 크기(최소 1)가 모두 포함되어 있습니다.
| Config 키 | 기본값 | 설명 | 예제 값 |
|---|---|---|---|
job.autoscaler.metrics.window |
600s |
Scaling metrics aggregation window size. |
30(기본 단위는 밀리초), 5m, 1h |
job.autoscaler.history.max.count |
3 |
버텍스당 유지할 과거 규모 조정 결정의 최대 수입니다. | 1~Integer.MAX_VALUE |
job.autoscaler.history.max.age |
24h |
버텍스당 유지할 과거 규모 조정 결정의 최소 수입니다. | 30(기본 단위는 밀리초), 5m, 1h |
작업 버텍스 수준 구성
각 작업 버텍스의 병렬 처리는 목표 사용률을 근거로 수정되며 최소-최대 병렬 처리 한도에 의해 제한됩니다. 목표 사용률을 100%(즉, 값 1)에 가깝게 설정하는 것은 바람직하지 않으며 사용률 경계는 중간 부하 변동을 처리하기 위한 완충제 역할을 합니다.
| Config 키 | 기본값 | 설명 | 예제 값 |
|---|---|---|---|
job.autoscaler.target.utilization |
0.7 |
목표 버텍스 사용률. | 0 - 1 |
job.autoscaler.target.utilization.boundary |
0.4 |
목표 버텍스 사용률 경계. 현재 처리 속도가 범위 [target_rate /
(target_utilization - boundary)~(target_rate /
(target_utilization + boundary)] 이내인 경우에는 규모 조정이 수행되지 않습니다. |
0 - 1 |
job.autoscaler.vertex.min-parallelism |
1 |
오토스케일러에서 사용할 수 있는 최소 병렬 처리입니다. | 0 - 200 |
job.autoscaler.vertex.max-parallelism |
200 |
오토스케일러에서 사용할 수 있는 최대 병렬 처리입니다. 이 한도가 Flink 구성 또는 각 운영자에 구성된 최대 병렬 처리보다 더 높은 경우 이 한도는 무시됩니다. | 0 - 200 |
백로그 처리 구성
작업 버텍스에는 규모 조정 작업 기간 동안 누적되는 진행 중 이벤트 또는 백로그를 처리하기 위해 추가적인 리소스가 필요합니다. 이를 catch-up 기간이라고도 합니다. 백로그를 처리하는 데 걸리는 시간이 구성된 lag -threshold 값을 초과하면 작업 버텍스 목표 사용률이 최대 수준으로 높아집니다. 그 결과 백로그가 처리되는 동안 불필요한 규모 조정 작업을 막을 수 있습니다.
| Config 키 | 기본값 | 설명 | 예제 값 |
|---|---|---|---|
job.autoscaler.backlog-processing.lag-threshold |
5m |
지연 임계값은 불필요한 크기 조정 작업을 방지하는 동시에 지연을 발생시키는 진행 중 메시지를 제거합니다. | 30(기본 단위는 밀리초), 5m, 1h |
job.autoscaler.catch-up.duration |
15m |
규모 조정 작업 후에 백로그를 완전히 처리하는 데 걸리는 목표 기간입니다. 0으로 설정하여 백로그 기반 크기 조정을 비활성화합니다. | 30(기본 단위는 밀리초), 5m, 1h |
규모 조정 작업 구성
오토스케일러는 유예 기간 내에 스케일 업 작업 직후에 스케일 다운 작업을 수행하지 않습니다. 이 경우 일시적인 부하 변동으로 인해 스케일 업-다운-업-다운 작업이 불필요하게 반복되는 것을 막을 수 있습니다.
스케일 다운 작업 비율을 사용하여 병렬 처리를 단계적으로 줄이고 리소스를 릴리스하여 일시적인 부하 급상승에 대비할 수 있습니다. 이 작업을 통해 대규모 스케일 다운 작업 후에 불필요한 소규모 스케일 업 작업이 진행되는 것을 방지할 수도 있습니다.
과거 작업 버텍스 규모 조정 결정 기록을 근거로 무의미한 스케일 업 작업을 감지하여 추가적인 변경 처리의 변경을 방지할 할 수 있습니다.
| Config 키 | 기본값 | 설명 | 예제 값 |
|---|---|---|---|
job.autoscaler.scale-up.grace-period |
1h |
버텍스가 스케일 업된 후에 스케일 다운이 허용되지 않는 기간입니다. | 30(기본 단위는 밀리초), 5m, 1h |
job.autoscaler.scale-down.max-factor |
0.6 |
최대 스케일 다운 계수입니다. 값이 1이면 스케일 다운에 제한이 없음을 의미합니다. 0.6은 당초 병렬 처리의 60%로만 작업을 스케일 다운할 수 있음을 의미합니다. |
0 - 1 |
job.autoscaler.scale-up.max-factor |
100000. |
최대 스케일 업 비율입니다. 값이 2.0이면 작업은 현재 병렬 처리의 200%까지만 스케일 업될 수 있습니다. |
0 - Integer.MAX_VALUE |
job.autoscaler.scaling.effectiveness.detection.enabled |
false |
무의미한 규모 조정 작업을 감지하고 자동 스케일러가 추가 스케일 업을 차단하도록 허용할지 여부입니다. | true, false |
