신규 고객은 Amazon Forecast를 더 이상 사용할 수 없습니다. Amazon Forecast의 기존 고객은 평소와 같이 서비스를 계속 사용할 수 있습니다. 자세히 알아보기
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
예측 설명 가능성
예측 설명 가능성을 통해 데이터 세트의 속성이 특정 시계열(항목 및 차원 조합) 및 시점에 대한 예측에 미치는 영향을 더 잘 이해할 수 있습니다. Forecast는 영향 점수라는 지표를 사용하여 각 속성의 상대적 영향을 정량화하고 예측 값을 증가시키는지 감소시키는지 결정합니다.
예를 들어 대상이 sales이고 price 및 color의 두 관련 속성이 있는 예측 시나리오를 생각해 보세요. Forecast는 항목의 색상이 특정 항목의 판매에 큰 영향을 미치지만 다른 항목에 미치는 영향은 미미하다는 것을 발견할 수 있습니다. 여름철 프로모션은 판매에 큰 영향을 주지만 겨울철 프로모션은 효과가 거의 없을 수도 있습니다.
예측 설명 가능성을 활성화하려면 예측기에 관련 시계열, 항목 메타데이터 또는 공휴일과 날씨 지수 같은 추가 데이터 세트 중 하나 이상이 포함되어야 합니다. 자세한 내용은 제한 및 모범 사례 섹션을 참조하세요.
데이터 세트의 모든 시계열 및 시점의 집계된 영향 점수를 보려면 예측 설명 가능성 대신 예측기 설명 가능성을 사용하세요. 예측기 설명 가능성을 참조하세요.
Python 노트북
예측 설명 가능성에 대한 단계별 안내는 항목 수준 설명 가능성
영향 점수 해석
영향 점수는 속성이 예측값에 미치는 상대적 영향을 측정합니다. 예를 들어 '가격' 속성의 영향 점수가 '매장 위치' 속성보다 두 배 높으면 항목 가격이 매장 위치보다 예측값에 미치는 영향이 두 배라는 결론을 내릴 수 있습니다.
영향 점수는 속성이 예측 값을 증가시키는지 감소시키는지에 대한 정보도 제공합니다. 콘솔에서 이는 두 개의 그래프로 표시됩니다. 파란색 막대가 있는 속성은 예측값을 증가시키고, 빨간색 막대가 있는 속성은 예측값을 감소시킵니다.
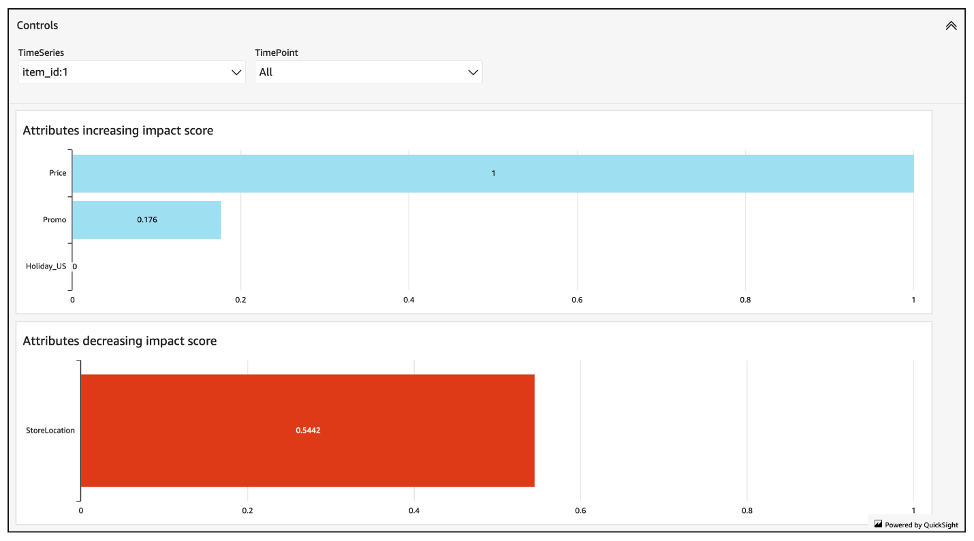
중요한 점은 영향 점수는 속성의 절대적 영향이 아니라 상대적 영향을 측정한다는 점입니다. 따라서 영향 점수를 사용하여 특정 속성이 모델 정확도를 향상시키는지 여부를 판단할 수는 없습니다. 속성의 영향 점수가 낮다고 해서 반드시 예측값에 미치는 영향이 적은 것은 아니며, 예측기가 사용하는 다른 속성보다 예측값에 미치는 영향이 적다는 뜻입니다.
모든 영향 점수나 일부 영향 점수가 0이 될 수도 있습니다. 이런 현상은 특성이 예측값에 영향을 주지 않거나, AutoPredictor가 ML이 아닌 알고리즘만 사용했거나, 관련 시계열 또는 항목 메타데이터를 제공하지 않은 경우 발생할 수 있습니다.
예측 설명 가능성의 영향 점수는 정규화된 영향 점수와 원시 영향 점수의 두 가지 형태입니다. 원시 영향 점수는 Shapley 값을 기반으로 하며 규모가 조정되거나 제한되지 않습니다. 정규화된 영향 점수는 원시 점수를 -1에서 1 사이의 값으로 조정합니다.
원시 영향 점수는 다양한 설명 가능성 리소스의 점수를 조합하고 비교하는 데 유용합니다. 예를 들어 예측기에 50개 이상의 시계열 또는 500개 이상의 시점이 포함된 경우 여러 개의 예측 설명 가능성 리소스를 생성하여 더 많은 수의 시계열이나 시점을 포괄하고 속성의 원시 영향 점수를 직접 비교할 수 있습니다. 그러나 서로 다른 예측의 예측 설명 가능성 리소스 원시 영향 점수는 직접 비교할 수 없습니다.
콘솔에서 영향 점수를 볼 때는 정규화된 영향 점수만 볼 수 있습니다. 설명 가능성을 내보내면 원시 점수와 정규화된 점수를 모두 얻을 수 있습니다.
예측 설명 가능성 생성
예측 설명 가능성을 사용하면 속성이 특정 시점에 특정 시계열의 예측값에 어떤 영향을 미치는지 살펴볼 수 있습니다. Amazon Forecast는 시계열 및 시점을 지정한 후 해당 특정 시계열 및 시점의 영향 점수만 계산합니다.
소프트웨어 개발 키트(SDK) 또는 Amazon Forecast 콘솔을 사용하여 예측기의 예측 설명 가능성을 활성화할 수 있습니다. SDK를 사용할 때는 CreateExplainability 작업을 사용하세요.
시계열 지정
참고
시계열은 항목(item_id)과 데이터 세트의 모든 차원의 조합입니다.
예측 설명 가능성의 시계열(항목 및 차원 조합)을 지정하면 Amazon Forecast는 해당 특정 시계열의 속성에 대한 영향 점수만 계산합니다.
시계열 목록을 지정하려면 item_id와 차원 값으로 시계열을 식별하는 CSV 파일을 S3 버킷에 업로드하세요. 최대 50개의 시계열을 지정할 수 있습니다. 또한 스키마에서 시계열의 속성 및 속성 유형을 정의해야 합니다.
예를 들어 소매업체는 프로모션이 특정 매장 위치(store_location)에서의 특정 항목(item_id) 판매에 어떤 영향을 미치는지 알고 싶어 할 수 있습니다. 이 사용 사례에서는 item_id와 store_location의 조합인 시계열을 지정합니다.
다음 CSV 파일은 다음과 같은 다섯 개의 시계열을 선택합니다.
-
Item_id: 001, store_location: 시애틀
-
Item_id: 001, store_location: 뉴욕
-
Item_id: 002, store_location: 시애틀
-
Item_id: 002, store_location: 뉴욕
-
Item_id: 003, store_location: 덴버
001, Seattle 001, New York 002, Seattle 002, New York 003, Denver
스키마는 첫 번째 열을 item_id로 정의하고 두 번째 열을 store_location으로 정의합니다.
Forecast 콘솔 또는 Forecast 소프트웨어 개발 키트(SDK)를 사용하여 시계열을 지정할 수 있습니다.
시점 지정
참고
시점("TimePointGranularity":
"ALL")을 지정하지 않으면 Amazon Forecast는 영향 점수를 계산할 때 전체 예측 기간을 고려합니다.
예측 설명 가능성의 시점을 지정하면 Amazon Forecast는 해당 특정 시간 범위 동안의 속성 영향 점수를 계산합니다. 예측 기간 내에 최대 500개의 연속 시점을 지정할 수 있습니다.
예를 들어 소매업체는 해당 속성이 겨울철 매출에 어떤 영향을 미치는지 알고 싶어 할 수 있습니다. 이 사용 사례에서는 예측 기간의 겨울 기간만 포함하도록 시점을 지정합니다.
Forecast 콘솔 또는 Forecast 소프트웨어 개발 키트(SDK)를 사용하여 시점을 지정할 수 있습니다.
예측 설명 가능성 시각화
콘솔에서 예측 설명 가능성을 생성하면 Forecast는 영향 점수를 자동으로 시각화합니다. CreateExplainability 작업을 사용하여 예측 설명 가능성을 생성하는 경우 EnableVisualization을 “true”로 설정하면 해당 예측 설명 가능성 리소스의 영향 점수가 콘솔 내에서 시각화됩니다.
영향 점수 시각화는 설명 가능성 생성 날짜로부터 30일 동안 지속됩니다. 시각화를 다시 생성하려면 새 예측 설명 가능성을 생성하세요.
예측 설명 가능성 내보내기
참고
내보내기 파일은 데이터 세트 가져오기의 정보를 직접 반환할 수 있습니다. 따라서 가져온 데이터에 수식이나 명령이 포함된 경우 파일이 CSV 삽입에 취약해집니다. 이러한 이유로, 파일을 내보내는 경우 보안 경고가 표시될 수 있습니다. 악의적인 활동을 방지하려면 내보낸 파일을 읽을 때 링크와 매크로를 비활성화하세요.
Forecast를 사용하면 영향 점수의 CSV 파일을 S3 위치로 내보낼 수 있습니다.
내보내기에는 지정된 시계열의 원시 영향 점수와 정규화된 영향 점수뿐만 아니라 지정된 모든 시계열과 지정된 모든 시점의 정규화된 집계 영향 점수도 포함됩니다. 시점을 지정하지 않은 경우 예측 기간의 모든 시점에 대해 이미 영향 점수가 집계되어 있습니다.
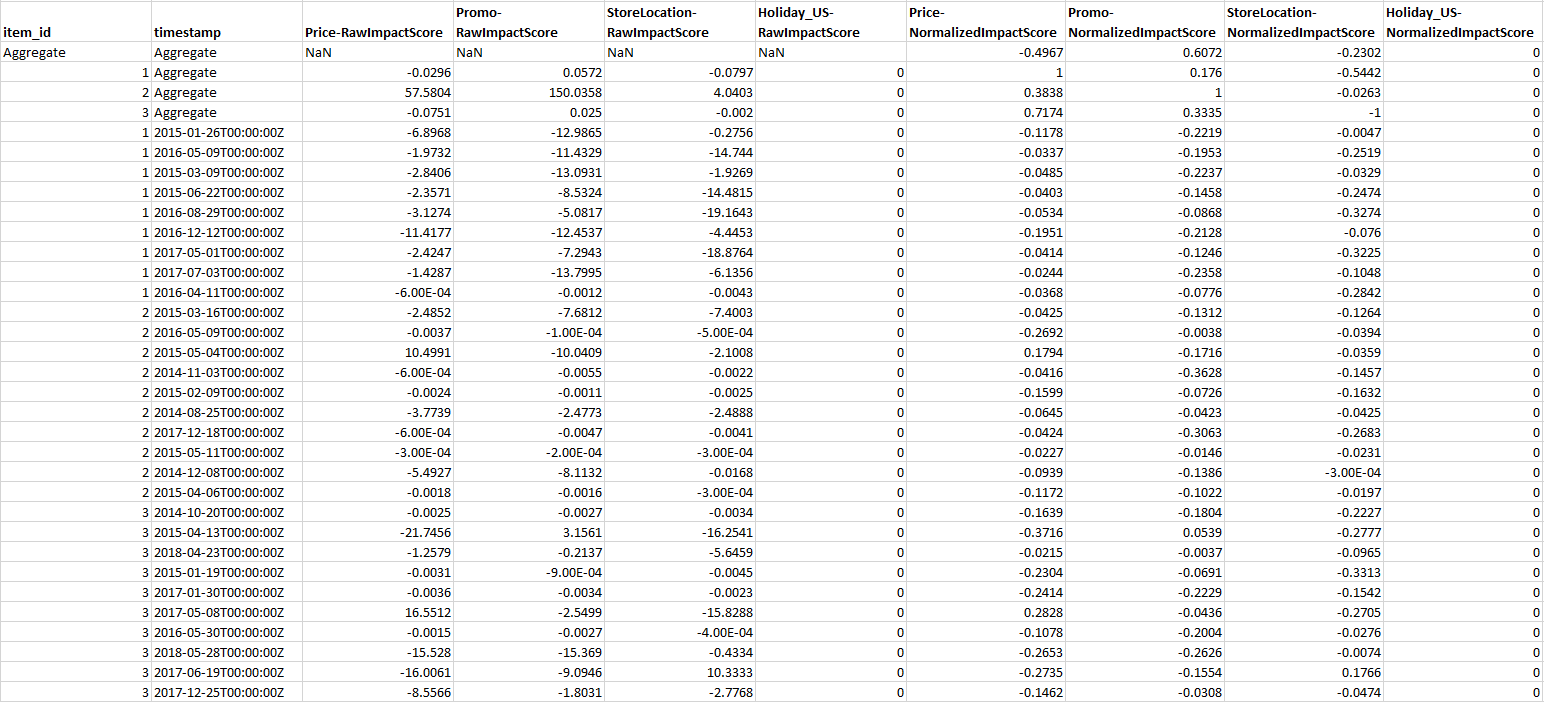
Amazon Forecast 소프트웨어 개발 키트(SDK)와 Amazon Forecast 콘솔을 사용하여 예측 설명 가능성을 내보낼 수 있습니다.
제한 및 모범 사례
예측 설명 가능성을 사용할 때는 다음 제한 및 모범 사례를 고려하세요.
-
예측 설명 가능성은 AutoPredictor에서 생성된 일부 예측에만 사용할 수 있습니다. 레거시 예측기(AutoML 또는 수동 선택)에서 생성된 예측에 대해 예측 설명 가능성을 활성화할 수 없습니다. AutoPredictor로 업그레이드를 참조하세요.
-
일부 모델에서는 예측 설명 가능성을 사용할 수 없습니다. ARIMA(AutoRegressive Integrated Moving Average), ETS(Exponential Smoothing State Space Model) 및 NPTS(Non-Parametric Time Series) 모델은 외부 시계열 데이터를 통합하지 않습니다. 따라서 이러한 모델은 추가 데이터 세트를 포함하더라도 설명 가능성 보고서를 생성하지 않습니다.
-
설명 가능성에는 속성이 필요합니다 - 예측기에는 관련 시계열, 항목 메타데이터, 공휴일 또는 날씨 지수 중 하나 이상이 포함되어야 합니다.
-
영향 점수 0은 영향이 없음을 나타냅니다 - 하나 이상의 속성의 영향 점수가 0인 경우 이러한 속성은 예측 값에 큰 영향을 미치지 않습니다. AutoPredictor가 비ML 알고리즘만 사용했거나 관련 시계열 또는 항목 메타데이터를 제공하지 않은 경우에도 점수는 0이 될 수 있습니다.
-
최대 50개의 시계열을 지정합니다 - 예측 설명 가능성당 최대 50개의 시계열을 지정할 수 있습니다.
-
최대 500개의 시점을 지정합니다 - 예측 설명 가능성당 최대 500개의 연속 시점을 지정할 수 있습니다.
-
Forecast는 일부 집계된 영향 점수도 계산합니다 - Forecast는 지정된 시계열 및 시점에 대해 집계된 영향 점수도 제공합니다.
-
단일 예측에 대해 여러 개의 예측 설명 가능성 리소스를 생성합니다 - 50개 이상의 시계열 또는 500개 이상의 시점에 대한 영향 점수를 원하는 경우 설명 가능성 리소스를 일괄 생성하여 더 넓은 범위를 포함할 수 있습니다.
-
다양한 예측 설명 가능성 리소스의 원시 영향 점수를 비교합니다 - 동일한 예측에서 여러 설명 가능성 리소스의 원시 영향 점수를 직접 비교할 수 있습니다.
-
예측 설명 가능성 시각화는 생성 후 30일 동안 사용할 수 있습니다 - 30일 후에도 시각화를 보려면 동일한 구성으로 새 예측 설명 가능성을 생성하세요.
