AWS Glue Schema Registry와 통합
이 섹션에서는 AWS Glue 스키마 레지스트리와의 통합에 대해 설명합니다. 이 섹션의 예에서는 AVRO 데이터 포맷의 스키마를 보여줍니다. JSON 데이터 포맷의 스키마를 포함한 더 많은 예제는 AWS Glue Schema Registry 오픈 소스 리포지토리
주제
사용 사례: Amazon MSK 또는 Apache Kafka에 Schema Registry 연결
Apache Kafka 주제에 데이터를 쓰고 있다고 가정하고 다음 단계에 따라 시작할 수 있습니다.
하나 이상의 주제로 Amazon Managed Streaming for Apache Kafka(Amazon MSK) 또는 Apache Kafka 클러스터를 생성합니다. Amazon MSK 클러스터를 생성하는 경우 AWS Management Console을 사용할 수 있습니다. Amazon Managed Streaming for Apache Kafka Developer Guide의 Getting Started Using Amazon MSK에서 설명하는 지침을 따릅니다.
위의 SerDe 라이브러리 설치 단계를 따릅니다.
스키마 레지스트리, 스키마 또는 스키마 버전을 생성하려면 이 문서의 스키마 레지스트리 시작하기 섹션에 있는 지침을 따르세요.
생산자와 소비자가 Schema Registry를 사용하여 Amazon MSK 또는 Apache Kafka 주제에서 레코드를 쓰고 읽도록 시작합니다. 예제 생산자 및 소비자 코드는 Serde 라이브러리의 ReadMe 파일
에서 찾을 수 있습니다. 생산자의 Schema Registry 라이브러리는 자동으로 레코드를 직렬화하고 스키마 버전 ID로 레코드를 장식합니다. 이 레코드의 스키마가 입력되었거나 자동 등록이 설정되어 있으면 Schema Registry에 스키마가 등록됩니다.
AWS Glue Schema Registry 라이브러리를 사용하여 Amazon MSK 또는 Apache Kafka 주제에서 읽는 소비자는 Schema Registry에서 스키마를 자동으로 조회합니다.
사용 사례: AWS Glue Schema Registry와 Amazon Kinesis Data Streams 통합
이 통합을 위해서는 기존 Amazon Kinesis 데이터 스트림이 있어야 합니다. 자세한 내용은 Amazon Kinesis Data Streams Developer Guide의 Getting Started with Amazon Kinesis Data Streams를 참조하세요.
Kinesis 데이터 스트림의 데이터와 상호 작용할 수 있는 두 가지 방법이 있습니다.
Java의 Kinesis Producer Library(KPL) 및 Kinesis Client Library(KCL) 라이브러리를 통해 다국어 지원은 제공되지 않습니다.
AWS SDK for Java에서 사용 가능한
PutRecords,PutRecord및GetRecordsKinesis Data Streams API를 통해.
현재 KPL/KCL 라이브러리를 사용하는 경우 해당 방법을 계속 사용하는 것이 좋습니다. 예제와 같이 Schema Registry가 통합된 업데이트된 KCL 및 KPL 버전이 있습니다. 그렇지 않으면 AWS Glue KDS API를 직접 사용하는 경우 샘플 코드를 사용하여 Schema Registry를 활용할 수 있습니다.
Schema Registry 통합은 KPL v0.14.2 이상 및 KCL v2.3 이상에서만 사용할 수 있습니다. JSON 데이터 포맷과 Schema Registry 통합은 KPL v0.14.8 이상 및 KCL v2.3.6 이상에서 사용할 수 있습니다.
Kinesis SDK V2를 사용하여 데이터와 상호 작용
이 섹션에서는 Kinesis SDK V2를 사용한 Kinesis와의 상호 작용에 대해 설명합니다.
// Example JSON Record, you can construct a AVRO record also private static final JsonDataWithSchema record = JsonDataWithSchema.builder(schemaString, payloadString); private static final DataFormat dataFormat = DataFormat.JSON; //Configurations for Schema Registry GlueSchemaRegistryConfiguration gsrConfig = new GlueSchemaRegistryConfiguration("us-east-1"); GlueSchemaRegistrySerializer glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatSerializer dataFormatSerializer = new GlueSchemaRegistrySerializerFactory().getInstance(dataFormat, gsrConfig); Schema gsrSchema = new Schema(dataFormatSerializer.getSchemaDefinition(record), dataFormat.name(), "MySchema"); byte[] serializedBytes = dataFormatSerializer.serialize(record); byte[] gsrEncodedBytes = glueSchemaRegistrySerializer.encode(streamName, gsrSchema, serializedBytes); PutRecordRequest putRecordRequest = PutRecordRequest.builder() .streamName(streamName) .partitionKey("partitionKey") .data(SdkBytes.fromByteArray(gsrEncodedBytes)) .build(); shardId = kinesisClient.putRecord(putRecordRequest) .get() .shardId(); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatDeserializer gsrDataFormatDeserializer = glueSchemaRegistryDeserializerFactory.getInstance(dataFormat, gsrConfig); GetShardIteratorRequest getShardIteratorRequest = GetShardIteratorRequest.builder() .streamName(streamName) .shardId(shardId) .shardIteratorType(ShardIteratorType.TRIM_HORIZON) .build(); String shardIterator = kinesisClient.getShardIterator(getShardIteratorRequest) .get() .shardIterator(); GetRecordsRequest getRecordRequest = GetRecordsRequest.builder() .shardIterator(shardIterator) .build(); GetRecordsResponse recordsResponse = kinesisClient.getRecords(getRecordRequest) .get(); List<Object> consumerRecords = new ArrayList<>(); List<Record> recordsFromKinesis = recordsResponse.records(); for (int i = 0; i < recordsFromKinesis.size(); i++) { byte[] consumedBytes = recordsFromKinesis.get(i) .data() .asByteArray(); Schema gsrSchema = glueSchemaRegistryDeserializer.getSchema(consumedBytes); Object decodedRecord = gsrDataFormatDeserializer.deserialize(ByteBuffer.wrap(consumedBytes), gsrSchema.getSchemaDefinition()); consumerRecords.add(decodedRecord); }
KPL/KCL 라이브러리를 사용하여 데이터와 상호 작용
이 섹션에서는 KPL/KCL 라이브러리를 사용하여 Kinesis Data Streams를 Schema Registry와 통합하는 방법을 설명합니다. KPL/KCL 사용에 대한 자세한 내용은 Amazon Kinesis Data Streams Developer Guide의 Developing Producers Using the Amazon Kinesis Producer Library를 참조하세요.
KPL에서 Schema Registry 설정
AWS Glue Schema Registry에서 작성된 데이터, 데이터 포맷 및 스키마 이름에 대한 스키마 정의를 정의합니다.
필요에 따라
GlueSchemaRegistryConfiguration객체를 구성합니다.addUserRecord API로 스키마 객체를 전달합니다.private static final String SCHEMA_DEFINITION = "{"namespace": "example.avro",\n" + " "type": "record",\n" + " "name": "User",\n" + " "fields": [\n" + " {"name": "name", "type": "string"},\n" + " {"name": "favorite_number", "type": ["int", "null"]},\n" + " {"name": "favorite_color", "type": ["string", "null"]}\n" + " ]\n" + "}"; KinesisProducerConfiguration config = new KinesisProducerConfiguration(); config.setRegion("us-west-1") //[Optional] configuration for Schema Registry. GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration("us-west-1"); schemaRegistryConfig.setCompression(true); config.setGlueSchemaRegistryConfiguration(schemaRegistryConfig); ///Optional configuration ends. final KinesisProducer producer = new KinesisProducer(config); final ByteBuffer data = getDataToSend(); com.amazonaws.services.schemaregistry.common.Schema gsrSchema = new Schema(SCHEMA_DEFINITION, DataFormat.AVRO.toString(), "demoSchema"); ListenableFuture<UserRecordResult> f = producer.addUserRecord( config.getStreamName(), TIMESTAMP, Utils.randomExplicitHashKey(), data, gsrSchema); private static ByteBuffer getDataToSend() { org.apache.avro.Schema avroSchema = new org.apache.avro.Schema.Parser().parse(SCHEMA_DEFINITION); GenericRecord user = new GenericData.Record(avroSchema); user.put("name", "Emily"); user.put("favorite_number", 32); user.put("favorite_color", "green"); ByteArrayOutputStream outBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(outBytes, null); new GenericDatumWriter<>(avroSchema).write(user, encoder); encoder.flush(); return ByteBuffer.wrap(outBytes.toByteArray()); }
Kinesis 클라이언트 라이브러리 설정
Java로 Kinesis Client Library 소비자를 개발합니다. 자세한 내용은 Amazon Kinesis Data Streams Developer Guide의 Developing a Kinesis Client Library Consumer in Java를 참조하세요.
GlueSchemaRegistryConfiguration객체를 전달하여GlueSchemaRegistryDeserializer의 인스턴스를 생성합니다.retrievalConfig.glueSchemaRegistryDeserializer에GlueSchemaRegistryDeserializer를 전달합니다.kinesisClientRecord.getSchema()를 호출하여 수신 메시지의 스키마에 액세스합니다.GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration(this.region.toString()); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), schemaRegistryConfig); RetrievalConfig retrievalConfig = configsBuilder.retrievalConfig().retrievalSpecificConfig(new PollingConfig(streamName, kinesisClient)); retrievalConfig.glueSchemaRegistryDeserializer(glueSchemaRegistryDeserializer); Scheduler scheduler = new Scheduler( configsBuilder.checkpointConfig(), configsBuilder.coordinatorConfig(), configsBuilder.leaseManagementConfig(), configsBuilder.lifecycleConfig(), configsBuilder.metricsConfig(), configsBuilder.processorConfig(), retrievalConfig ); public void processRecords(ProcessRecordsInput processRecordsInput) { MDC.put(SHARD_ID_MDC_KEY, shardId); try { log.info("Processing {} record(s)", processRecordsInput.records().size()); processRecordsInput.records() .forEach( r -> log.info("Processed record pk: {} -- Seq: {} : data {} with schema: {}", r.partitionKey(), r.sequenceNumber(), recordToAvroObj(r).toString(), r.getSchema())); } catch (Throwable t) { log.error("Caught throwable while processing records. Aborting."); Runtime.getRuntime().halt(1); } finally { MDC.remove(SHARD_ID_MDC_KEY); } } private GenericRecord recordToAvroObj(KinesisClientRecord r) { byte[] data = new byte[r.data().remaining()]; r.data().get(data, 0, data.length); org.apache.avro.Schema schema = new org.apache.avro.Schema.Parser().parse(r.schema().getSchemaDefinition()); DatumReader datumReader = new GenericDatumReader<>(schema); BinaryDecoder binaryDecoder = DecoderFactory.get().binaryDecoder(data, 0, data.length, null); return (GenericRecord) datumReader.read(null, binaryDecoder); }
Kinesis Data Streams API를 사용하여 데이터와 상호 작용
이 섹션에서는 Kinesis Data Streams API를 사용하여 Kinesis Data Streams를 Schema Registry와 통합하는 방법을 설명합니다.
다음 Maven 종속성을 업데이트합니다.
<dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-bom</artifactId> <version>1.11.884</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-kinesis</artifactId> </dependency> <dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-serde</artifactId> <version>1.1.5</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.dataformat</groupId> <artifactId>jackson-dataformat-cbor</artifactId> <version>2.11.3</version> </dependency> </dependencies>생산자에서 Kinesis Data Streams의
PutRecords또는PutRecordAPI를 사용하여 스키마 헤더 정보를 추가합니다.//The following lines add a Schema Header to the record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(getConfigs())); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes);생산자에서
PutRecords또는PutRecordAPI를 사용하여 레코드를 데이터 스트림에 넣습니다.소비자의 헤더에서 스키마 레코드를 제거하고 Avro 스키마 레코드를 직렬화합니다.
//The following lines remove Schema Header from record GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), getConfigs()); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); }
Kinesis Data Streams API를 사용하여 데이터와 상호 작용
다음은 PutRecords 및 GetRecords API 사용을 위한 예제 코드입니다.
//Full sample code import com.amazonaws.services.schemaregistry.deserializers.GlueSchemaRegistryDeserializerImpl; import com.amazonaws.services.schemaregistry.serializers.GlueSchemaRegistrySerializerImpl; import com.amazonaws.services.schemaregistry.utils.AVROUtils; import com.amazonaws.services.schemaregistry.utils.AWSSchemaRegistryConstants; import org.apache.avro.Schema; import org.apache.avro.generic.GenericData; import org.apache.avro.generic.GenericDatumReader; import org.apache.avro.generic.GenericDatumWriter; import org.apache.avro.generic.GenericRecord; import org.apache.avro.io.Decoder; import org.apache.avro.io.DecoderFactory; import org.apache.avro.io.Encoder; import org.apache.avro.io.EncoderFactory; import software.amazon.awssdk.auth.credentials.DefaultCredentialsProvider; import software.amazon.awssdk.services.glue.model.DataFormat; import java.io.ByteArrayOutputStream; import java.io.File; import java.io.IOException; import java.nio.ByteBuffer; import java.util.Collections; import java.util.HashMap; import java.util.Map; public class PutAndGetExampleWithEncodedData { static final String regionName = "us-east-2"; static final String streamName = "testStream1"; static final String schemaName = "User-Topic"; static final String AVRO_USER_SCHEMA_FILE = "src/main/resources/user.avsc"; KinesisApi kinesisApi = new KinesisApi(); void runSampleForPutRecord() throws IOException { Object testRecord = getTestRecord(); byte[] recordAsBytes = convertRecordToBytes(testRecord); String schemaDefinition = AVROUtils.getInstance().getSchemaDefinition(testRecord); //The following lines add a Schema Header to a record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes); //Use PutRecords api to pass a list of records kinesisApi.putRecords(Collections.singletonList(recordWithSchemaHeader), streamName, regionName); //OR //Use PutRecord api to pass single record //kinesisApi.putRecord(recordWithSchemaHeader, streamName, regionName); } byte[] runSampleForGetRecord() throws IOException { ByteBuffer recordWithSchemaHeader = kinesisApi.getRecords(streamName, regionName); //The following lines remove the schema registry header GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); } return record; } private byte[] convertRecordToBytes(final Object record) throws IOException { ByteArrayOutputStream recordAsBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(recordAsBytes, null); GenericDatumWriter datumWriter = new GenericDatumWriter<>(AVROUtils.getInstance().getSchema(record)); datumWriter.write(record, encoder); encoder.flush(); return recordAsBytes.toByteArray(); } private GenericRecord convertBytesToRecord(Schema avroSchema, byte[] record) throws IOException { final GenericDatumReader<GenericRecord> datumReader = new GenericDatumReader<>(avroSchema); Decoder decoder = DecoderFactory.get().binaryDecoder(record, null); GenericRecord genericRecord = datumReader.read(null, decoder); return genericRecord; } private Map<String, String> getMetadata() { Map<String, String> metadata = new HashMap<>(); metadata.put("event-source-1", "topic1"); metadata.put("event-source-2", "topic2"); metadata.put("event-source-3", "topic3"); metadata.put("event-source-4", "topic4"); metadata.put("event-source-5", "topic5"); return metadata; } private GlueSchemaRegistryConfiguration getConfigs() { GlueSchemaRegistryConfiguration configs = new GlueSchemaRegistryConfiguration(regionName); configs.setSchemaName(schemaName); configs.setAutoRegistration(true); configs.setMetadata(getMetadata()); return configs; } private Object getTestRecord() throws IOException { GenericRecord genericRecord; Schema.Parser parser = new Schema.Parser(); Schema avroSchema = parser.parse(new File(AVRO_USER_SCHEMA_FILE)); genericRecord = new GenericData.Record(avroSchema); genericRecord.put("name", "testName"); genericRecord.put("favorite_number", 99); genericRecord.put("favorite_color", "red"); return genericRecord; } }
사용 사례: Amazon Managed Service for Apache Flink
Apache Flink는 무제한 및 제한 데이터 스트림에 대한 상태 저장 계산에 널리 사용되는 오픈 소스 프레임워크 및 분산 처리 엔진입니다. Amazon Managed Service for Apache Flink는 스트리밍 데이터를 처리하는 Apache Flink 애플리케이션을 구축 및 관리할 수 있는 완전관리형 AWS 서비스입니다.
오픈 소스 Apache Flink는 다양한 소스와 싱크를 제공합니다. 예를 들어 사전 정의된 데이터 원본에는 파일, 디렉터리 및 소켓에서 읽기와 컬렉션 및 반복기에서 데이터 수집이 포함됩니다. Apache Flink DataStream 커넥터는 Apache Flink가 소스 및/또는 싱크로 Apache Kafka 또는 Kinesis와 같은 다양한 서드 파티 시스템과 인터페이스할 수 있는 코드를 제공합니다.
자세한 내용은 Amazon Kinesis Data Analytics Developer Guide를 참조하세요.
Apache Flink Kafka 커넥터
Apache Flink는 정확히 1회 보장으로 Kafka 주제에서 데이터를 읽고 쓰기 위한 Apache Kafka 데이터 스트림 커넥터를 제공합니다. Flink의 Kafka 소비자인 FlinkKafkaConsumer는 하나 이상의 Kafka 주제에서 읽을 수 있는 액세스를 제공합니다. Apache Flink의 Kafka Producer인 FlinkKafkaProducer를 사용하면 하나 이상의 Kafka 주제에 대한 레코드 스트림을 작성할 수 있습니다. 자세한 내용은 Apache Kafka 커넥터
Apache Flink Kinesis 스트림 커넥터
Kinesis 데이터 스트림 커넥터는 Amazon Kinesis Data Streams에 대한 액세스를 제공합니다. FlinkKinesisConsumer는 동일한 AWS 서비스 리전 내에서 여러 Kinesis 스트림을 구독하는 정확히 1회 병렬 스트리밍 데이터 원본이며 작업이 실행되는 동안 스트림의 다시 샤딩을 투명하게 처리할 수 있습니다. 소비자의 각 하위 태스크는 여러 Kinesis 샤드에서 데이터 레코드를 가져오는 일을 담당합니다. 각 하위 태스크에서 가져온 샤드 수는 샤드가 다히고 Kinesis에서 생성됨에 따라 변경됩니다. FlinkKinesisProducer는 Kinesis Producer Library(KPL)를 사용하여 Apache Flink 스트림의 데이터를 Kinesis 스트림에 넣습니다. 자세한 내용은 Amazon Kinesis Streams 커넥터
자세한 내용은 AWS Glue 스키마 Github 리포지토리
Apache Flink와의 통합
Schema Registry와 함께 제공되는 SerDes 라이브러리는 Apache Flink와 통합됩니다. Apache Flink를 사용하려면 Apache Flink 커넥터에 연결할 수 있는 GlueSchemaRegistryAvroSerializationSchema 및 GlueSchemaRegistryAvroDeserializationSchema라는 SerializationSchemaDeserializationSchema
Apache Flink 애플리케이션에 AWS Glue Schema Registry 종속성 추가
Apache Flink 애플리케이션에서 AWS Glue Schema Registry에 대한 통합 종속성을 설정하려면
종속 프로그램을
pom.xml파일에 추가합니다.<dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-flink-serde</artifactId> <version>1.0.0</version> </dependency>
pache Flink와 Kafka 또는 Amazon MSK 통합
Kafka를 소스나 싱크로 사용하여 Apache Flink용 Managed Service for Apache Flink를 사용할 수 있습니다.
소스형 Kafka
다음 다이어그램에서는 Kafka를 소스로 사용하여 Kinesis Data Streams를 Apache Flink용 Managed Service for Apache Flink와 통합하는 방법을 보여줍니다.
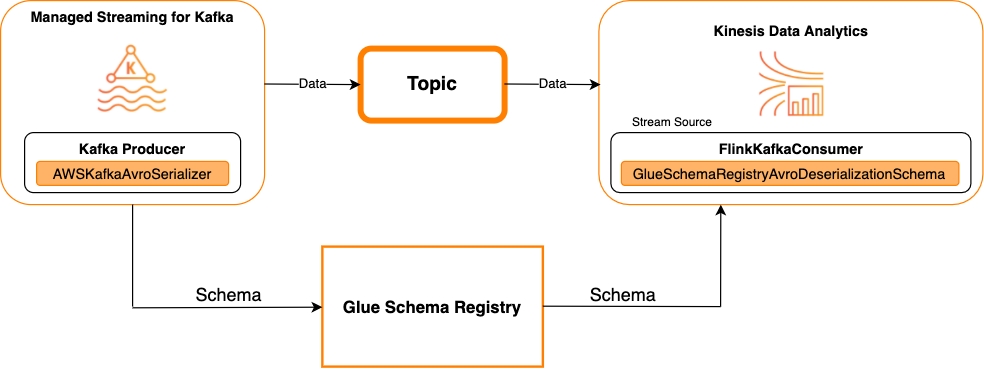
싱크로 Kafka
다음 다이어그램에서는 Kafka를 싱크로 사용하여 Kinesis Data Streams를 Apache Flink용 Managed Service for Apache Flink와 통합하는 방법을 보여줍니다.

Kafka를 소스 또는 싱크로 사용하여 Kafka(또는 Amazon MSK)를 Apache Flink용 Managed Service for Apache Flink와 통합하려면 아래와 같이 코드를 변경합니다. 굵게 표시된 코드 블록을 유사한 섹션의 해당 코드에 추가합니다.
Kafka가 소스인 경우 deserializer 코드를 사용합니다(블록 2). Kafka가 싱크인 경우 serializer 코드(블록 3)를 사용합니다.
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String topic = "topic"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "localhost:9092"); properties.setProperty("group.id", "test"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKafkaConsumer<GenericRecord> consumer = new FlinkKafkaConsumer<>( topic, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKafkaProducer<GenericRecord> producer = new FlinkKafkaProducer<>( topic, // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
Apache Flink와 Kinesis Data Streams 통합
Kinesis Data Streams를 소스 또는 싱크로 사용하여 Apache Flink용 Managed Service for Apache Flink를 사용할 수 있습니다.
소스로 Kinesis Data Streams
다음 다이어그램에서는 Kinesis Data Streams를 소스로 사용하여 Kinesis Data Streams를 Apache Flink용 Managed Service for Apache Flink와 통합하는 방법을 보여줍니다.
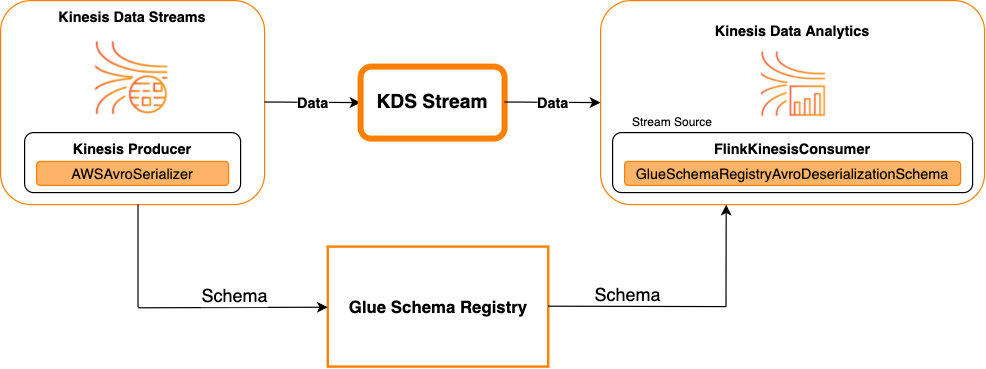
싱크로 Kinesis Data Streams
다음 다이어그램에서는 Kinesis Data Streams를 싱크로 사용하여 Kinesis Data Streams를 Apache Flink용 Managed Service for Apache Flink와 통합하는 방법을 보여줍니다.
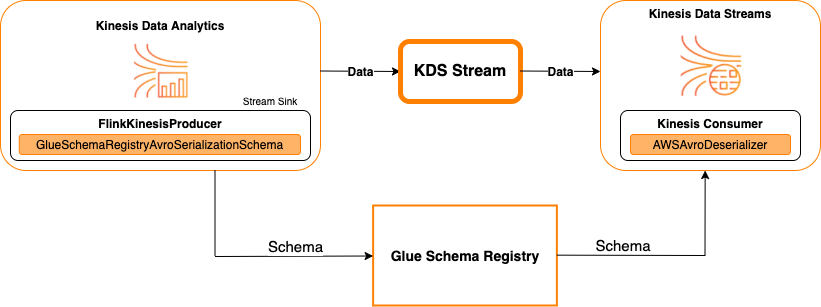
Kinesis Data Streams를 소스 또는 싱크로 사용하여 Kinesis Data Streams를 Apache Flink용 Managed Service for Apache Flink와 통합하려면 아래와 같이 코드를 변경합니다. 굵게 표시된 코드 블록을 유사한 섹션의 해당 코드에 추가합니다.
Kinesis Data Streams가 소스인 경우 deserializer 코드(블록 2)를 사용합니다. Kinesis Data Streams가 싱크인 경우 serializer 코드(블록 3)를 사용합니다.
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String streamName = "stream"; Properties consumerConfig = new Properties(); consumerConfig.put(AWSConfigConstants.AWS_REGION, "aws-region"); consumerConfig.put(AWSConfigConstants.AWS_ACCESS_KEY_ID, "aws_access_key_id"); consumerConfig.put(AWSConfigConstants.AWS_SECRET_ACCESS_KEY, "aws_secret_access_key"); consumerConfig.put(ConsumerConfigConstants.STREAM_INITIAL_POSITION, "LATEST"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKinesisConsumer<GenericRecord> consumer = new FlinkKinesisConsumer<>( streamName, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKinesisProducer<GenericRecord> producer = new FlinkKinesisProducer<>( // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); producer.setDefaultStream(streamName); producer.setDefaultPartition("0"); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
사용 사례: AWS Lambda와 통합
AWS Lambda 함수를 Apache Kafka/Amazon MSK 소비자로 사용하고 AWS Glue Schema Registry를 사용하여 Avro 인코딩 메시지를 역직렬화하려면 MSK Labs 페이지
사용 사례: AWS Glue Data Catalog
AWS Glue 테이블은 수동으로 지정하거나 AWS Glue Schema Registry를 참조하여 지정할 수 있는 스키마를 지원합니다. Schema Registry는 데이터 카탈로그와 통합되어 데이터 카탈로그에서 AWS Glue 테이블 또는 파티션을 생성하거나 업데이트할 때 Schema Registry에 저장된 스키마를 선택적으로 사용할 수 있습니다. Schema Registry에서 스키마 정의를 식별하려면 최소한 스키마가 속한 스키마의 ARN을 알아야 합니다. 스키마 정의를 포함하는 스키마의 스키마 버전은 해당 UUID 또는 버전 번호로 참조할 수 있습니다. 버전 번호나 UUID를 몰라도 조회할 수 있는 "최신" 버전이라는 하나의 스키마 버전이 항상 있습니다.
CreateTable 또는 UpdateTable 작업을 호출할 때 Schema Registry의 기존 스키마에 SchemaReference가 있을 수 있는 StorageDescriptor를 포함하는 TableInput 구조를 전달합니다. 마찬가지로 GetTable 또는 GetPartition API를 호출할 때 응답에 스키마와 SchemaReference가 포함될 수 있습니다. 스키마 참조를 사용하여 테이블 또는 파티션이 생성되면 데이터 카탈로그는 이 스키마 참조에 대한 스키마를 가져오려고 시도합니다. Schema Registry에서 스키마를 찾을 수 없는 경우 GetTable 응답에서 빈 스키마를 반환합니다. 그렇지 않으면 응답에 스키마와 스키마 참조가 모두 포함됩니다.
AWS Glue 콘솔에서 작업을 수행할 수도 있습니다.
이러한 작업을 수행하고 스키마 정보를 생성, 업데이트 또는 보려면 GetSchemaVersion API에 대한 권한을 제공하는 호출 사용자에게 IAM 역할을 부여해야 합니다.
테이블 추가 또는 테이블에 대한 스키마 업데이트
기존 스키마에서 새 테이블을 추가하면 테이블이 특정 스키마 버전에 바인딩됩니다. 새 스키마 버전이 등록되면 AWS Glue 콘솔의 테이블 보기 페이지에서 또는 UpdateTable 작업(Python: update_table) API를 사용하여 이 테이블 정의를 업데이트할 수 있습니다.
기존 스키마에서 테이블 추가
AWS Glue 콘솔 또는 CreateTable API를 사용하여 레지스트리의 스키마 버전에서 AWS Glue 테이블을 생성할 수 있습니다.
AWS Glue API
CreateTable API를 호출할 때 Schema Registry의 기존 스키마에 SchemaReference가 있고 StorageDescriptor가 포함된 TableInput을 전달합니다.
AWS Glue 콘솔
AWS Glue 콘솔에서 테이블을 생성하려면
-
AWS Management Console에 로그인하여 https://console.aws.amazon.com/glue/
에서 AWS Glue 콘솔을 엽니다. 탐색 창의 [데이터 카탈로그(Data catalog)]에서 [테이블(Tables)]을 선택합니다.
[테이블 추가(Add Tables)] 메뉴에서 [기존 스키마에서 테이블 추가(Add table from existing schema)]를 선택합니다.
AWS Glue 개발자 안내서에 따라 테이블 속성 및 데이터 스토어를 구성합니다.
[Glue 스키마 선택(Choose a Glue schema)] 페이지에서 스키마가 있는 [레지스트리(Registry)]를 선택합니다.
[스키마 이름(Schema name)]을 선택하고 적용할 스키마의 [버전(Version)]을 선택합니다.
스키마 미리 보기를 검토하고 [다음(Next)]을 선택합니다.
테이블을 검토하고 생성합니다.
테이블에 적용된 스키마 및 버전은 테이블 목록의 [Glue 스키마(Glue schema)] 열에 나타납니다. 테이블을 보고 자세한 세부 정보를 확인할 수 있습니다.
테이블에 대한 스키마 업데이트
새 스키마 버전을 사용할 수 있게 되면 UpdateTable 작업(Python: update_table) API 또는 AWS Glue 콘솔을 사용하여 테이블의 스키마를 업데이트할 수 있습니다.
중요
AWS Glue 스키마가 수동으로 지정된 기존 테이블의 스키마를 업데이트할 때 Schema Registry에서 참조하는 새 스키마가 호환되지 않을 수 있습니다. 이로 인해 작업이 실패할 수 있습니다.
AWS Glue API
UpdateTable API를 호출할 때 Schema Registry의 기존 스키마에 SchemaReference가 있고 StorageDescriptor가 포함된 TableInput을 전달합니다.
AWS Glue 콘솔
AWS Glue 콘솔에서 테이블에 대한 스키마를 업데이트하려면
-
AWS Management Console에 로그인하여 https://console.aws.amazon.com/glue/
에서 AWS Glue 콘솔을 엽니다. 탐색 창의 [데이터 카탈로그(Data catalog)]에서 [테이블(Tables)]을 선택합니다.
테이블 목록에서 테이블을 봅니다.
새 버전에 대해 알려주는 상자에서 [스키마 업데이트(Update schema)]를 클릭합니다.
현재 스키마와 새 스키마의 차이점을 검토합니다.
[모든 스키마 차이점 표시(Show all schema differences)]를 선택 더 많은 세부 정보를 볼 수 있습니다.
[테이블 저장(Save table)]을 선택하여 새 버전을 수락합니다.
사용 사례: AWS Glue 스트리밍
AWS Glue 스트리밍은 출력 싱크에 쓰기 전에 스트리밍 소스의 데이터를 소비하고 ETL 작업을 수행합니다. 입력 스트리밍 소스는 데이터 테이블을 사용하여 지정하거나 소스 구성을 지정하여 직접 지정할 수 있습니다.
AWS Glue 스트리밍은 에 AWS Glue 스키마 레지스트리에 있는 스키마를 사용하여 생성된 스트리밍 소스에 대한 데이터 카탈로그 테이블을 지원합니다. AWS Glue 스키마 레지스트리에서 스키마를 생성하고 이 스키마를 사용하는 스트리밍 소스가 있는 AWS Glue 테이블을 생성할 수 있습니다. 이 AWS Glue 테이블을 입력 스트림의 데이터를 역직렬화하기 위한 AWS Glue 스트리밍 작업에 대한 입력으로 사용할 수 있습니다.
여기서 유의해야 할 점은 AWS Glue 스키마 레지스트리의 스키마가 변경되면 AWS Glue 스트리밍 작업을 다시 시작해야 스키마의 변경 사항이 반영된다는 것입니다.
사용 사례: Apache Kafka Streams
Apache Kafka Streams API는 Apache Kafka에 저장된 데이터를 처리하고 분석하기 위한 클라이언트 라이브러리입니다. 이 섹션에서는 데이터 스트리밍 애플리케이션에서 스키마를 관리하고 시행할 수 있는 AWS Glue Schema Registry와 Apache Kafka Streams의 통합에 대해 설명합니다. Apache Kafka Streams에 대한 자세한 내용은 Apache Kafka Streams
SerDes 라이브러리와의 통합
Streams 애플리케이션을 구성할 수 있는 GlueSchemaRegistryKafkaStreamsSerde 클래스가 있습니다.
Kafka Streams 애플리케이션 예 코드
Apache Kafka Streams 애플리케이션 내에서 AWS Glue Schema Registry를 사용하려면
Kafka Streams 애플리케이션을 구성합니다.
final Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "avro-streams"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, AWSKafkaAvroSerDe.class.getName()); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); props.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); props.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); props.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); props.put(AWSSchemaRegistryConstants.DATA_FORMAT, DataFormat.AVRO.name());주제 avro-input에서 스트림을 생성합니다.
StreamsBuilder builder = new StreamsBuilder(); final KStream<String, GenericRecord> source = builder.stream("avro-input");데이터 레코드를 처리합니다(이 예에서는 favorite_color 값이 pink이거나 양의 값이 15인 레코드를 필터링함).
final KStream<String, GenericRecord> result = source .filter((key, value) -> !"pink".equals(String.valueOf(value.get("favorite_color")))); .filter((key, value) -> !"15.0".equals(String.valueOf(value.get("amount"))));avro-output 주제에 결과를 다시 씁니다.
result.to("avro-output");Apache Kafka Streams 애플리케이션을 시작합니다.
KafkaStreams streams = new KafkaStreams(builder.build(), props); streams.start();
구현 결과
이 결과는 3단계에서 favorite_color "pink" 또는 값 "15.0"으로 필터링된 레코드의 필터링 프로세스를 보여줍니다.
필터링 전 레코드:
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"name": "Jay", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105} {"id": "commute_1","amount": 15}
필터링 후 레코드:
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105}
사용 사례: Apache Kafka Connect
Apache Kafka Connect와 AWS Glue Schema Registry의 통합으로 커넥터에서 스키마 정보를 가져올 수 있습니다. Apache Kafka 변환기는 Apache Kafka 내의 데이터 포맷과 이를 Apache Kafka Connect 데이터로 변환하는 방법을 지정합니다. 모든 Apache Kafka Connect 사용자는 Apache Kafka에서 로드하거나 Apache Kafka에 저장할 때 데이터를 원하는 포맷을 기반으로 이러한 변환기를 구성해야 합니다. 이러한 방식으로 Apache Kafka Connect 데이터를 AWS Glue Schema Registry(예: Avro)에서 사용되는 유형으로 변환하고 serializer를 사용하여 스키마를 등록하고 직렬화를 수행하는 변환기를 정의할 수 있습니다. 그런 다음 변환기는 deserializer를 사용하여 Apache Kafka에서 수신한 데이터를 역직렬화하고 이를 다시 Apache Kafka Connect 데이터로 변환할 수도 있습니다. 다음은 예제 워크플로 다이어그램입니다.
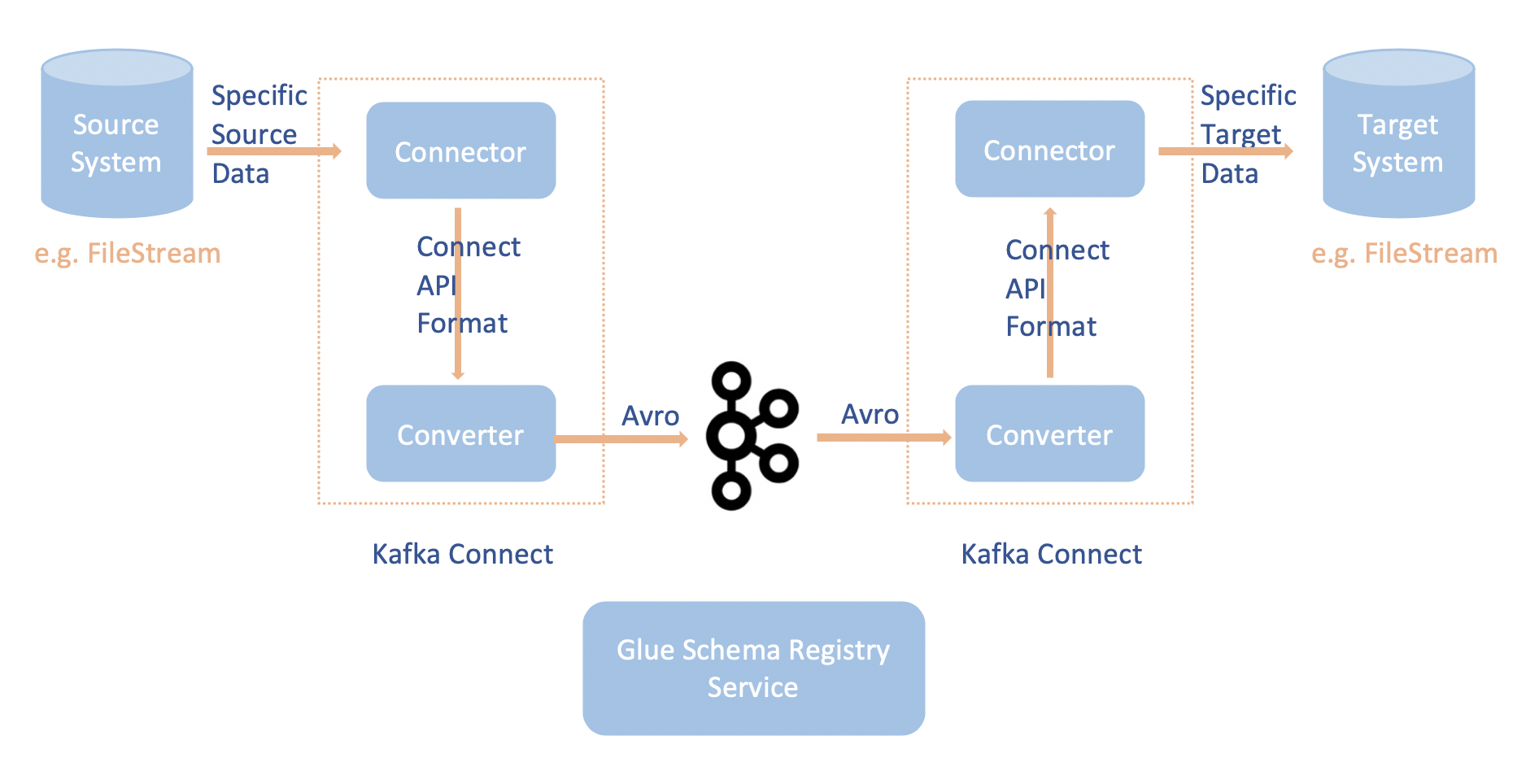
AWS Glue Schema Registry용 Github 리포지토리
를 복제하여 aws-glue-schema-registry프로젝트를 설치합니다.git clone git@github.com:awslabs/aws-glue-schema-registry.git cd aws-glue-schema-registry mvn clean install mvn dependency:copy-dependencies독립 실행형 모드에서 Apache Kafka Connect를 사용하려는 경우 이 단계에 대한 아래 지침을 사용하여 connect-standalone.properties를 업데이트합니다. 분산 모드에서 Apache Kafka Connect를 사용하려는 경우 동일한 지침을 사용하여 connect-avro-distributed.properties를 업데이트합니다.
Apache Kafka 연결 속성 파일에도 다음 속성을 추가합니다.
key.converter.region=aws-regionvalue.converter.region=aws-regionkey.converter.schemaAutoRegistrationEnabled=true value.converter.schemaAutoRegistrationEnabled=true key.converter.avroRecordType=GENERIC_RECORD value.converter.avroRecordType=GENERIC_RECORDkafka-run-class.sh 아래의 [시작 모드(Launch mode)] 섹션에 아래 명령을 추가합니다.
-cp $CLASSPATH:"<your AWS GlueSchema Registry base directory>/target/dependency/*"
kafka-run-class.sh 아래의 [시작 모드(Launch mode)] 섹션에 아래 명령을 추가합니다.
-cp $CLASSPATH:"<your AWS GlueSchema Registry base directory>/target/dependency/*"형식은 다음과 같아야 합니다.
# Launch mode if [ "x$DAEMON_MODE" = "xtrue" ]; then nohup "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" > "$CONSOLE_OUTPUT_FILE" 2>&1 < /dev/null & else exec "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" fibash를 사용하는 경우 아래 명령을 실행하여 bash_profile에 CLASSPATH를 설정합니다. 다른 셸의 경우 그에 따라 환경을 업데이트합니다.
echo 'export GSR_LIB_BASE_DIR=<>' >>~/.bash_profile echo 'export GSR_LIB_VERSION=1.0.0' >>~/.bash_profile echo 'export KAFKA_HOME=<your Apache Kafka installation directory>' >>~/.bash_profile echo 'export CLASSPATH=$CLASSPATH:$GSR_LIB_BASE_DIR/avro-kafkaconnect-converter/target/schema-registry-kafkaconnect-converter-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/common/target/schema-registry-common-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/avro-serializer-deserializer/target/schema-registry-serde-$GSR_LIB_VERSION.jar' >>~/.bash_profile source ~/.bash_profile(선택 사항) 간단한 파일 소스로 테스트하려면 파일 소스 커넥터를 복제합니다.
git clone https://github.com/mmolimar/kafka-connect-fs.git cd kafka-connect-fs/소스 커넥터 구성에서 데이터 포맷을 Avro로, 파일 리더를
AvroFileReader으로 편집하고 읽고 있는 파일 경로에서 예제 Avro 객체를 업데이트합니다. 예:vim config/kafka-connect-fs.propertiesfs.uris=<path to a sample avro object> policy.regexp=^.*\.avro$ file_reader.class=com.github.mmolimar.kafka.connect.fs.file.reader.AvroFileReader소스 커넥터를 설치합니다.
mvn clean package echo "export CLASSPATH=\$CLASSPATH:\"\$(find target/ -type f -name '*.jar'| grep '\-package' | tr '\n' ':')\"" >>~/.bash_profile source ~/.bash_profile<your Apache Kafka installation directory>/config/connect-file-sink.propertiesfile=<output file full path> topics=<my topic>
소스 커넥터를 시작합니다 (이 예에서는 파일 소스 커넥터임).
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties config/kafka-connect-fs.properties싱크 커넥터를 실행합니다(이 예에서는 파일 싱크 커넥터임).
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties $KAFKA_HOME/config/connect-file-sink.propertiesKafka Connect 사용 예는 AWS Glue Schema Registry용 Github 리포지토리
의 integration-tests 폴더에 있는 run-local-tests.sh 스크립트를 참조하세요.
