신중한 고려 끝에 두 단계로 Amazon Kinesis Data Analytics for SQL 애플리케이션을 단종하기로 결정했습니다.
1. 2025년 10월 15일부터 새 Kinesis Data Analytics for SQL 애플리케이션을 생성할 수 없습니다.
2. 2026년 1월 27일부터 애플리케이션이 삭제됩니다. Amazon Kinesis Data Analytics for SQL 애플리케이션을 시작하거나 작동할 수 없게 됩니다. 그 시점부터 Amazon Kinesis Data Analytics for SQL에 대한 지원을 더 이상 이용할 수 없습니다. 자세한 내용은 Amazon Kinesis Data Analytics for SQL 애플리케이션 단종 단원을 참조하십시오.
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Managed Service for Apache Flink Studio로 마이그레이션하는 예
신중한 고려 끝에 Amazon Kinesis Data Analytics for SQL 애플리케이션을 단종하기로 결정했습니다. Amazon Kinesis Data Analytics for SQL 애플리케이션을 계획하고 마이그레이션하는 데 도움이 되도록 15개월에 걸쳐 오퍼링을 점진적으로 단종할 예정입니다. 알아두어야 할 중요한 두 날짜는 2025년 10월 15일과 2026년 1월 27일입니다.
-
2025년 10월 15일부터는 새 Amazon Kinesis Data Analytics for SQL 애플리케이션을 생성할 수 없습니다.
-
2026년 1월 27일부터 애플리케이션이 삭제됩니다. Amazon Kinesis Data Analytics for SQL 애플리케이션을 시작하거나 작동할 수 없게 됩니다. 그 시점부터 Amazon Kinesis Data Analytics for SQL 애플리케이션에 대한 지원을 더 이상 이용할 수 없습니다. 자세한 내용은 Amazon Kinesis Data Analytics for SQL 애플리케이션 단종을 참조하십시오.
Amazon Managed Service for Apache Flink를 사용하는 것이 좋습니다. 사용 편의성과 고급 분석 기능을 결합하여 몇 분 만에 스트림 처리 애플리케이션을 빌드할 수 있습니다.
이 섹션에서는 Amazon Kinesis Data Analytics for SQL 애플리케이션 워크로드를 Managed Service for Apache Flink로 이동하는 데 도움이 되는 코드 및 아키텍처 예를 제공합니다.
자세한 내용은 AWS 블로그 게시물: Migrate from Amazon Kinesis Data Analytics for SQL Applications to Managed Service for Apache Flink Studio
워크로드를 Managed Service for Apache Flink Studio 또는 Managed Service for Apache Flink로 마이그레이션하기 위해 이 섹션에서는 일반적인 사용 사례에 사용할 수 있는 쿼리 번역을 제공합니다.
이러한 예를 살펴보기 전에 먼저 Managed Service for Apache Flink가 포함된 Studio 노트북 사용을 검토하는 것이 좋습니다.
Managed Service for Apache Flink Studio에서 Kinesis Data Analytics for SQL 쿼리를 다시 만들기
아래 옵션에서는 일반적인 SQL 기반 Kinesis Data Analytics 애플리케이션 쿼리를 Managed Service for Apache Flink Studio로 변환하는 것을 보여줍니다.
Random Cut Forest를 사용하는 워크로드를 Kinesis Analytics for SQL에서 Managed Service for Apache Flink로 이동하려는 경우, 이 AWS 블로그 게시물
전체 튜토리얼은 Converting-KDASQL-KDAStudio/
다음 연습에서는 Amazon Managed Service for Apache Flink Studio를 사용하도록 데이터 흐름을 변경해 보겠습니다. Amazon Kinesis Data Firehose에서 Amazon Kinesis Data Streams로 전환하는 것도 의미합니다.
먼저 일반적인 KDA-SQL 아키텍처를 공유하고, Amazon Managed Service for Apache Flink Studio 및 Amazon Kinesis Data Streams를 사용하여 이를 대체할 수 있는 방법을 보여줍니다. 또는 여기에서 AWS CloudFormation 템플릿을 시작할 수 있습니다
Amazon Kinesis Data Analytics-SQL 및 Amazon Kinesis Data Firehose
Amazon Kinesis Data Analytics SQL 아키텍처 흐름은 다음과 같습니다:
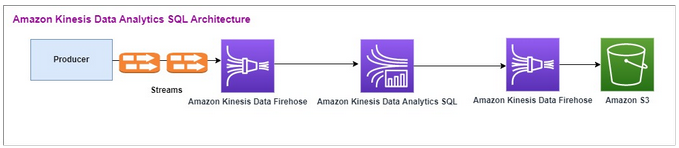
먼저 기존 Amazon Kinesis Data Analytics-SQL과 Amazon Kinesis Data Firehose의 설정을 살펴봅니다. 사용 사례는 주식 시세 및 가격을 포함한 거래 데이터가 외부 소스에서 Amazon Kinesis 시스템으로 스트리밍되는 거래 시장입니다. Amazon Kinesis Data Analytics for SQL은 입력 스트림을 사용하여 텀블링 윈도우와 같은 윈도우 쿼리를 실행하여 각 주식 시세 표시기에 대해 1분 기간의 거래량 및 min, max, average 거래 가격을 결정합니다.
Amazon Kinesis Data Analytics-SQL은 Amazon Kinesis Data Firehose API에서 데이터를 수집하도록 설정되어 있습니다. 처리가 끝나면 Amazon Kinesis Data Analytics-SQL은 처리된 데이터를 다른 Amazon Kinesis Data Firehose로 보내고, 이 서비스는 출력을 Amazon S3 버킷에 저장합니다.
이 경우에는 Amazon Kinesis 데이터 생성기를 사용합니다. Amazon Kinesis 데이터 생성기를 사용하면 Amazon Kinesis Data Streams 또는 Amazon Kinesis Data Firehose 전송 스트림으로 테스트 데이터를 전송할 수 있습니다. 시작하려면 여기
AWS CloudFormation 템플릿을 실행하면 출력 섹션에 Amazon Kinesis Data Generator URL이 제공됩니다. 여기
다음은 Amazon Kinesis 데이터 생성기를 사용하는 샘플 페이로드입니다. 데이터 생성기는 입력 Amazon Kinesis Firehose 스트림을 대상으로 하여 데이터를 지속적으로 스트리밍합니다. Amazon Kinesis SDK 클라이언트는 다른 생산자로부터도 데이터를 전송할 수 있습니다.
2023-02-17 09:28:07.763,"AAPL",5032023-02-17 09:28:07.763, "AMZN",3352023-02-17 09:28:07.763, "GOOGL",1852023-02-17 09:28:07.763, "AAPL",11162023-02-17 09:28:07.763, "GOOGL",1582
다음 JSON은 일련의 거래 시간 및 날짜, 주식 시세 표시기, 주가를 무작위로 생성하는 데 사용됩니다.
date.now(YYYY-MM-DD HH:mm:ss.SSS), "random.arrayElement(["AAPL","AMZN","MSFT","META","GOOGL"])", random.number(2000)
데이터 보내기를 선택하면 생성기가 모의 데이터 전송을 시작합니다.
외부 시스템은 Amazon Kinesis Data Firehose로 데이터를 스트리밍합니다. Amazon Kinesis Data Analytics for SQL 애플리케이션을 사용하면 표준 SQL을 사용하여 스트리밍 데이터를 분석할 수 있습니다. 이 서비스를 사용하면 스트리밍 소스에 대해 SQL 코드를 작성하고 실행하여 시계열 분석을 수행하고, 실시간 대시보드를 공급하고, 실시간 지표를 생성할 수 있습니다. Amazon Kinesis Data Analytics for SQL 애플리케이션은 입력 스트림의 SQL 쿼리에서 대상 스트림을 생성하고 대상 스트림을 다른 Amazon Kinesis Data Firehose로 보낼 수 있습니다. 대상 Amazon Kinesis Data Firehose는 분석 데이터를 Amazon S3에 최종 상태로 보낼 수 있습니다.
Amazon Kinesis Data Analytics-SQL 레거시 코드는 SQL 표준의 확장을 기반으로 합니다.
Amazon Kinesis Data Analytics-SQL에서 다음 쿼리를 사용합니다. 먼저 쿼리 출력을 위한 대상 스트림을 생성합니다. 그런 다음 연속적 INSERT INTO stream SELECT ... FROM 쿼리 기능 실행을 제공하는 Amazon Kinesis Data Analytics 리포지토리 객체(SQL 표준의 확장)인 PUMP를 사용하여 쿼리 결과를 명명된 스트림에 지속적으로 입력할 수 있습니다.
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (EVENT_TIME TIMESTAMP, INGEST_TIME TIMESTAMP, TICKER VARCHAR(16), VOLUME BIGINT, AVG_PRICE DOUBLE, MIN_PRICE DOUBLE, MAX_PRICE DOUBLE); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM STEP("SOURCE_SQL_STREAM_001"."tradeTimestamp" BY INTERVAL '60' SECOND) AS EVENT_TIME, STEP("SOURCE_SQL_STREAM_001".ROWTIME BY INTERVAL '60' SECOND) AS "STREAM_INGEST_TIME", "ticker", COUNT(*) AS VOLUME, AVG("tradePrice") AS AVG_PRICE, MIN("tradePrice") AS MIN_PRICE, MAX("tradePrice") AS MAX_PRICEFROM "SOURCE_SQL_STREAM_001" GROUP BY "ticker", STEP("SOURCE_SQL_STREAM_001".ROWTIME BY INTERVAL '60' SECOND), STEP("SOURCE_SQL_STREAM_001"."tradeTimestamp" BY INTERVAL '60' SECOND);
앞의 SQL은 두 개의 시간 윈도우를 사용합니다. 하나는 수신 스트림 페이로드에서 오는 tradeTimestamp이고, 다른 하나는 Event Time 또는 client-side time이라고도 하는 ROWTIME.tradeTimestamp입니다. 이벤트가 발생한 시간이기 때문에 분석에서 이 시간을 사용하는 것이 바람직한 경우가 많습니다. 그러나 스마트폰 및 웹 클라이언트와 같은 많은 이벤트 소스가 신뢰할 만한 시계를 갖추고 있지 않아 부정확한 시간을 야기할 수 있습니다. 또한 연결 문제로 인해 레코드가 이벤트가 발생한 순서대로 스트림에 나타나지 않을 수 있습니다.
애플리케이션 내 스트림에는 ROWTIME이라고 하는 특수 열이 포함됩니다. Amazon Kinesis Data Analytics가 첫 번째 애플리케이션 내 스트림에 행을 삽입하면 타임스탬프를 저장합니다. ROWTIME은 Amazon Kinesis Data Analytics가 스트리밍 소스에서 읽은 후 첫 번째 애플리케이션 내 스트림을 레코드에 삽입한 타임스탬프를 나타냅니다. 그런 다음 이 ROWTIME 값은 애플리케이션 전체에 걸쳐 유지됩니다.
SQL은 티커 수를 60초 간격 내의 volume, min, max, average 가격으로 결정합니다.
시간 기반 창 모드 쿼리에서 이들 시간 각각을 사용하는 것은 장점과 단점이 있습니다. 이들 시간 중 하나 이상을 선택하고 사용 시나리오를 바탕으로 관련 단점을 처리할 전략을 선택하십시오.
두 개의 시간 기반 창, 즉 ROWTIME과 이벤트 시간 같은 다른 시간인 두 가지의 시간 기반을 사용하는 전략
-
다음 예에서와 같이 쿼리가 결과를 방출하는 빈도를 제어하는 첫 번째 창으로
ROWTIME을 사용합니다. 논리 시간으로는 사용되지 않습니다. -
분석과 연관시키고자 하는 논리 시간인 다른 시간 중 하나를 사용하십시오. 이 시간은 이벤트가 발생한 시간을 나타냅니다. 다음 예에서 분석 목적은 레코드를 그룹화하고 티커별 카운트를 반환하는 것입니다.
Amazon Managed Service for Apache Flink Studio
업데이트된 아키텍처에서는 Amazon Kinesis Data Firehose를 Amazon Kinesis Data Streams로 교체합니다. Amazon Kinesis Data Analytics for SQL 애플리케이션은 Amazon Managed Service for Apache Flink Studio로 대체되었습니다. Apache Flink 코드는 Apache Zeppelin Notebook 내에서 대화형 방식으로 실행됩니다. Amazon Managed Service for Apache Flink Studio에서 집계된 거래 데이터를 Amazon S3 버킷으로 전송하여 저장합니다. 단계는 다음과 같습니다:
Amazon Managed Service for Apache Flink Studio 아키텍처 흐름은 다음과 같습니다:

Kinesis Data Stream 생성
콘솔을 사용하여 데이터 스트림을 만들려면
에 로그인 AWS Management Console 하고 https://console.aws.amazon.com/kinesis
Kinesis 콘솔을 엽니다. -
탐색 모음에서 리전 선택기를 확장하고 리전을 선택합니다.
-
데이터 스트림 생성을 선택합니다.
-
Kinesis 스트림 생성 페이지에서 데이터 스트림의 명칭을 입력하고 기본 온디맨드 용량 모드를 수락합니다.
온디맨드 모드를 사용하면 Kinesis 스트림 생성을 선택하여 데이터 스트림을 생성할 수 있습니다.
스트림이 생성 중인 동안 Kinesis streams(Kinesis 스트림) 페이지에서 스트림의 Status(상태)는 Creating(생성 중)입니다. 스트림을 사용할 준비가 되면 Status(상태)가 Active(활성)로 변경됩니다.
-
스트림 명칭을 선택합니다. 스트림 세부 정보 페이지에 모니터링 정보와 함께 스트림 구성 요약이 표시됩니다.
-
Amazon Kinesis 데이터 생성기에서 스트림/전송 스트림을 새 Amazon Kinesis Data Streams 으로 변경합니다: TRADE_SOURCE_STREAM.
JSON과 페이로드는 Amazon Kinesis Data Analytics-SQL에서 사용한 것과 동일합니다. Amazon Kinesis 데이터 생성기를 사용하여 몇 가지 샘플 거래 페이로드 데이터를 생성하고 TRADE_SOURCE_STREAM 데이터 스트림을 이 연습의 대상으로 삼으십시오.
{{date.now(YYYY-MM-DD HH:mm:ss.SSS)}}, "{{random.arrayElement(["AAPL","AMZN","MSFT","META","GOOGL"])}}", {{random.number(2000)}} -
에서 Managed Service for Apache Flink로 AWS Management Console 이동한 다음 애플리케이션 생성을 선택합니다.
-
왼쪽 탐색 창에서 Studio 노트북을 선택한 다음 Studio 노트북 생성을 선택합니다.
-
스튜디오 노트북의 명칭을 입력합니다.
-
AWS Glue 데이터베이스에서 소스 및 대상의 메타데이터를 정의할 기존 AWS Glue 데이터베이스를 입력합니다. AWS Glue 데이터베이스가 없는 경우 생성을 선택하고 다음을 수행합니다.
-
AWS Glue 콘솔의 왼쪽 메뉴에 있는 데이터 카탈로그에서 데이터베이스를 선택합니다.
-
데이터베이스 생성을 선택합니다.
-
데이터베이스 생성 페이지에서 데이터베이스의 명칭을 입력합니다. 위치 - 옵션 섹션에서 Browse Amazon S3 검색을 선택하고 Amazon S3 버킷을 선택합니다. Amazon S3 버킷이 아직 설정되지 않은 경우 이 단계를 건너뛰고 나중에 다시 돌아올 수 있습니다.
-
(선택 사항). 데이터베이스에 대한 설명을 입력합니다.
-
데이터베이스 생성를 선택합니다.
-
-
노트북 생성을 선택합니다.
-
노트북이 생성되면 실행을 선택합니다.
-
노트북이 성공적으로 시작되면 Apache Zeppelin에서 열기를 선택하여 Zeppelin 노트북을 실행합니다.
-
Zeppelin 노트북 페이지에서 새 노트 만들기를 선택하고 명칭을 MarketDataFeed로 지정합니다.
Flink SQL 코드에 대한 설명은 다음과 같지만, 먼저 Zeppelin 노트북 화면의 모양은 다음과 같습니다
Amazon Managed Service for Apache Flink Studio 코드
Amazon Managed Service for Apache Flink Studio는 Zeppelin 노트북을 사용하여 코드를 실행합니다. 이 예에서는 Apache Flink 1.13에 근거한 ssql 코드에 매핑했습니다. Zeppelin 노트북의 코드는 한 번에 한 블록씩 아래에 나와 있습니다.
Zeppelin 노트북에서 코드를 실행하기 전에 Flink 구성 명령을 실행해야 합니다. 코드(ssql, Python 또는 Scala)를 실행한 후 구성 설정을 변경해야 하는 경우 노트북을 중지하고 다시 시작해야 합니다. 이 예에서는 체크포인트를 설정해야 합니다. Amazon S3의 파일로 데이터를 스트리밍하려면 체크포인트가 요구됩니다. 이렇게 하면 Amazon S3로 스트리밍되는 데이터를 파일로 플러싱할 수 있습니다. 다음 명령문은 간격을 5,000밀리초로 설정합니다.
%flink.conf execution.checkpointing.interval 5000
%flink.conf은 이 블록이 구성 명령문임을 나타냅니다. 체크포인트를 포함한 Flink 구성에 대한 자세한 내용은 Apache Flink 체크포인트
소스 Amazon Kinesis Data Streams의 입력 테이블은 다음 Flink ssql 코드를 사용하여 생성됩니다. 참고로 TRADE_TIME 필드에는 데이터 생성기가 생성한 날짜/시간이 저장됩니다.
%flink.ssql DROP TABLE IF EXISTS TRADE_SOURCE_STREAM; CREATE TABLE TRADE_SOURCE_STREAM (--`arrival_time` TIMESTAMP(3) METADATA FROM 'timestamp' VIRTUAL, TRADE_TIME TIMESTAMP(3), WATERMARK FOR TRADE_TIME as TRADE_TIME - INTERVAL '5' SECOND,TICKER STRING,PRICE DOUBLE, STATUS STRING)WITH ('connector' = 'kinesis','stream' = 'TRADE_SOURCE_STREAM', 'aws.region' = 'us-east-1','scan.stream.initpos' = 'LATEST','format' = 'csv');
다음 명령문을 사용하여 입력 스트림을 볼 수 있습니다:
%flink.ssql(type=update)-- testing the source stream select * from TRADE_SOURCE_STREAM;
Amazon S3로 집계 데이터를 전송하기 전에 Amazon Managed Service for Apache Flink Studio에서 텀블링 창 선택 쿼리를 사용하여 직접 데이터를 볼 수 있습니다. 이렇게 하면 거래 데이터가 1분 단위로 집계됩니다. 참고로 %flink.ssql 문에는 (유형=업데이트) 라는 대상이 있어야 합니다:
%flink.ssql(type=update) select TUMBLE_ROWTIME(TRADE_TIME, INTERVAL '1' MINUTE) as TRADE_WINDOW, TICKER, COUNT(*) as VOLUME, AVG(PRICE) as AVG_PRICE, MIN(PRICE) as MIN_PRICE, MAX(PRICE) as MAX_PRICE FROM TRADE_SOURCE_STREAMGROUP BY TUMBLE(TRADE_TIME, INTERVAL '1' MINUTE), TICKER;
그런 다음 Amazon S3에서 대상 주소에 대한 표를 생성할 수 있습니다. 워터마크를 사용해야 합니다. 워터마크는 지연된 이벤트가 더 이상 발생하지 않을 것으로 확신하는 시점을 나타내는 진행률 지표입니다. 워터마크를 사용하는 이유는 늦게 도착하는 사람들을 고려하기 위함입니다. 간격 ‘5’ Second을 통해 거래가 5초 늦게 Amazon Kinesis Data Stream에 입력될 수 있으며, 기간 내에 타임스탬프가 있는 거래는 여전히 포함됩니다. 자세한 내용은 워터마크 생성
%flink.ssql(type=update) DROP TABLE IF EXISTS TRADE_DESTINATION_S3; CREATE TABLE TRADE_DESTINATION_S3 ( TRADE_WINDOW_START TIMESTAMP(3), WATERMARK FOR TRADE_WINDOW_START as TRADE_WINDOW_START - INTERVAL '5' SECOND, TICKER STRING, VOLUME BIGINT, AVG_PRICE DOUBLE, MIN_PRICE DOUBLE, MAX_PRICE DOUBLE) WITH ('connector' = 'filesystem','path' = 's3://trade-destination/','format' = 'csv');
이 명령문은 데이터를 TRADE_DESTINATION_S3에 삽입합니다. TUMPLE_ROWTIME는 텀블링 창의 포함 상한선의 타임스탬프입니다.
%flink.ssql(type=update) insert into TRADE_DESTINATION_S3 select TUMBLE_ROWTIME(TRADE_TIME, INTERVAL '1' MINUTE), TICKER, COUNT(*) as VOLUME, AVG(PRICE) as AVG_PRICE, MIN(PRICE) as MIN_PRICE, MAX(PRICE) as MAX_PRICE FROM TRADE_SOURCE_STREAM GROUP BY TUMBLE(TRADE_TIME, INTERVAL '1' MINUTE), TICKER;
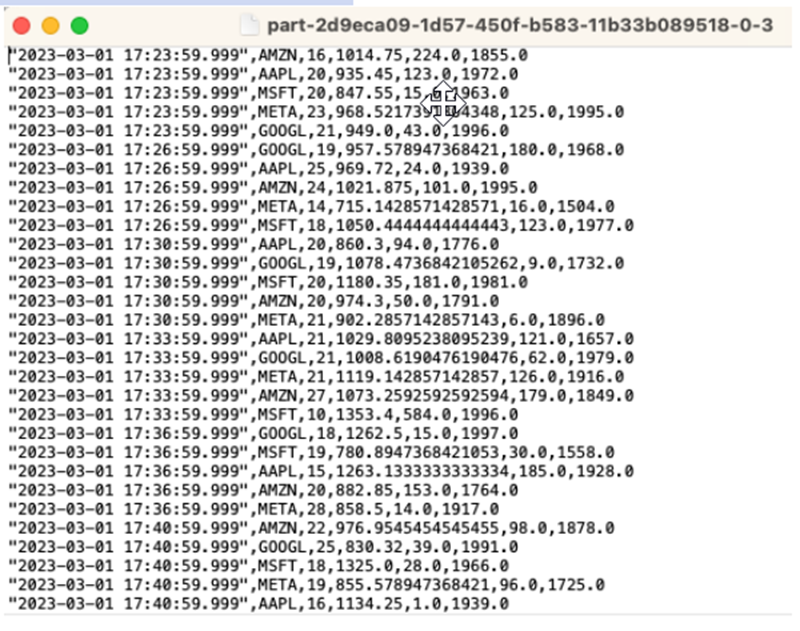
명령문을 10~20분 동안 실행하여 Amazon S3에 일부 데이터를 누적하십시오. 그런 다음 명령문을 중단하십시오.
그러면 Amazon S3의 파일이 닫히고 해당 파일을 볼 수 있게 됩니다.
내용은 다음과 같습니다:
AWS CloudFormation 템플릿
AWS CloudFormation 는 AWS 계정에 다음 리소스를 생성합니다.
-
Amazon Kinesis Data Streams
-
Amazon Managed Service for Apache Flink Studio
-
AWS Glue 데이터베이스
-
Amazon S3 버킷
-
Amazon Managed Service for Apache Flink Studio에서 적절한 리소스에 액세스하기 위한 IAM 역할 및 정책
노트북을 가져오고에서 생성한 새 Amazon S3 버킷으로 Amazon S3 버킷 이름을 변경합니다 AWS CloudFormation.

자세한 내용을 참조하십시오.
다음은 Managed Service for Apache Flink Studio를 사용하는 방법에 대해 자세히 알아볼 수 있는 몇 가지 추가 리소스입니다.
이 패턴의 목적은 Kinesis Data Analytics-Studio Zeppelin 노트북에서 UDF를 활용하여 Kinesis 스트림의 데이터를 처리하는 방법을 시연하는 것입니다. Managed Service for Apache Flink Studio는 Apache Flink를 사용하여 정확히 한 번 처리되는 의미 체계를 비롯한 고급 분석 기능, 이벤트 시간 윈도우, 사용자 정의 함수 및 고객 통합을 사용한 확장성, 명령형 언어 지원, 안정적인 애플리케이션 상태, 수평적 스케일링, 다중 데이터 소스 지원, 확장 가능한 통합 기능 등을 제공합니다. 이는 데이터 스트림 처리의 정확성, 완전성, 일관성 및 안정성을 보장하는 데 중요하며 Amazon Kinesis Data Analytics for SQL에서는 사용할 수 없습니다.
이 샘플 애플리케이션에서는 KDA-Studio Zeppelin 노트북의 UDF를 활용하여 Kinesis 스트림의 데이터를 처리하는 방법을 보여줍니다. Kinesis Data Analytics용 Studio 노트북을 사용하면 실시간으로 대화형 방식으로 데이터 스트림을 쿼리하고 표준 SQL, Python 및 Scala를 사용하여 스트림 처리 애플리케이션을 쉽게 구축하고 실행할 수 있습니다. 에서 몇 번의 클릭만으로 서버리스 노트북을 시작하여 데이터 스트림을 쿼리하고 몇 초 만에 결과를 얻을 AWS Management Console수 있습니다. 자세한 설명은 Kinesis Data Analytics for Apache Flink와 함께 Studio 노트북 사용하기를 참조하십시오.
KDA-SQL 애플리케이션에서 데이터의 사전/사후 처리에 사용되는 Lambda 함수:
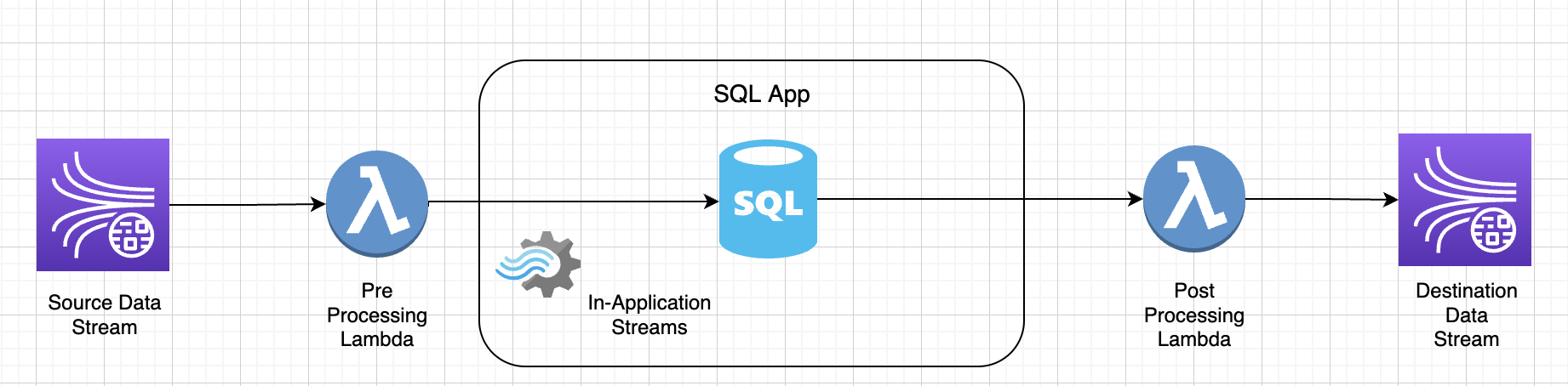
KDA-Studio Zeppelin 노트북을 사용하여 데이터를 사전/사후 처리하기 위한 사용자 정의 함수
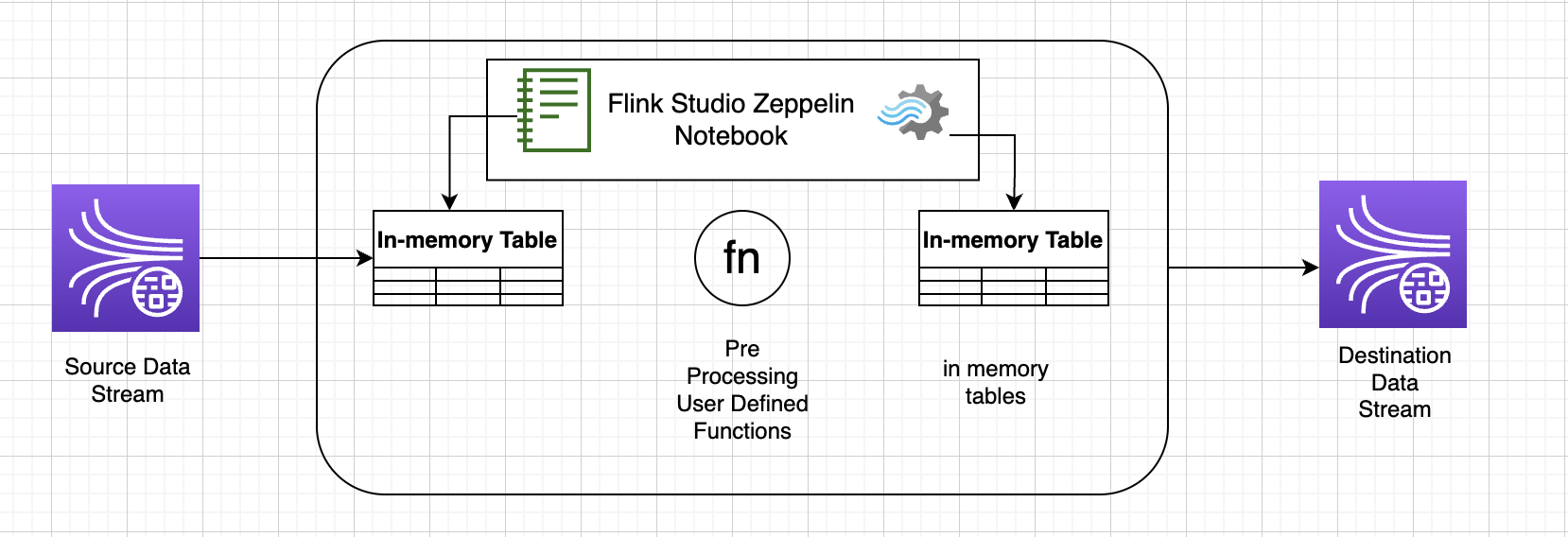
사용자 정의 함수(UDF)
일반적인 비즈니스 로직을 연산자로 재사용하려면 사용자 정의 함수를 참조하여 데이터 스트림을 변환하는 것이 유용할 수 있습니다. 이 작업은 Managed Service for Apache Flink Studio 노트북 내에서 수행하거나 외부에서 참조되는 애플리케이션 jar 파일로 수행할 수 있습니다. 사용자 정의 함수를 활용하면 스트리밍 데이터를 통해 수행할 수 있는 변환 또는 데이터 강화를 단순화할 수 있습니다.
노트북에서는 개인 전화번호를 익명화하는 기능이 있는 간단한 Java 애플리케이션 항아리를 참조하게 될 것입니다. 노트북 내에서 사용할 Python 또는 Scala UDF를 작성할 수도 있습니다. 애플리케이션 jar를 Pyflink 노트북으로 가져오는 기능을 강조하기 위해 Java 애플리케이션 jar를 선택했습니다.
환경 설정
이 가이드를 따르고 스트리밍 데이터와 상호 작용하려면 AWS CloudFormation 스크립트를 사용하여 다음 리소스를 시작해야 합니다.
-
소스 및 대상 Kinesis 데이터 스트림
-
Glue 데이터베이스
-
IAM 역할
-
Managed Service for Apache Flink 애플리케이션
-
Managed Service for Apache Flink 애플리케이션을 시작하기 위한
-
위의 Lambda 함수를 실행하기 위한 Lambda 역할
-
Lambda 함수를 간접적으로 호출할 사용자 지정 리소스
여기에서 AWS CloudFormation 템플릿을 다운로드합니다
AWS CloudFormation 스택 생성
-
로 이동하여 서비스 목록에서 CloudFormation을 AWS Management Console 선택합니다.
-
CloudFormation 페이지에서 스택을 선택하고 새 리소스로 스택 생성(표준)을 선택합니다.
-
스택 생성 페이지에서 템플릿 파일 업로드를 선택한 다음 이전에 다운로드한
kda-flink-udf.yml을 선택합니다. 파일을 업로드하고 다음을 선택합니다. -
기억하기 쉽도록 템플릿에
kinesis-UDF같은 명칭을 지정하고 다른 명칭을 원하면 input-stream과 같은 입력 파라미터를 업데이트하십시오. Next(다음)를 선택합니다. -
스택 옵션 구성 페이지에서 원하는 경우 태그를 추가하고 다음을 선택합니다.
-
검토 페이지에서 IAM 리소스 생성을 허용하는 확인란을 선택한 다음 제출을 선택합니다.
시작하려는 리전에 따라 AWS CloudFormation 스택을 시작하는 데 10~15분이 걸릴 수 있습니다. 전체 스택의 CREATE_COMPLETE 상태가 확인되면 계속할 준비가 된 것입니다.
Managed Service for Apache Flink Studio 노트북을 사용하여 작업하기
Kinesis Data Analytics용 Studio 노트북을 사용하면 실시간으로 대화형 방식으로 데이터 스트림을 쿼리하고 표준 SQL, Python 및 Scala를 사용하여 스트림 처리 애플리케이션을 쉽게 구축하고 실행할 수 있습니다. 에서 몇 번의 클릭만으로 서버리스 노트북을 시작하여 데이터 스트림을 쿼리하고 몇 초 만에 결과를 얻을 AWS Management Console수 있습니다.
노트북은 웹 기반 개발 환경입니다. 노트북을 사용하면 Apache Flink에서 제공하는 고급 데이터 스트림 처리 기능과 결합된 간단한 대화형 개발 환경을 얻을 수 있습니다. Studio 노트북은 Apache Zeppelin 기반 노트북을 사용하며 Apache Flink를 스트림 처리 엔진으로 사용합니다. Studio 노트북은 이러한 기술을 원활하게 결합하여 모든 기술을 갖춘 개발자가 데이터 스트림에 대한 고급 분석을 이용할 수 있도록 합니다.
Apache Zeppelin은 Studio 노트북에 다음을 포함한 완벽한 분석 도구 제품군을 제공합니다:
-
데이터 시각화
-
데이터를 파일로 내보내기
-
보다 쉬운 분석을 위한 출력 형식 제어
노트북 사용하기
-
로 이동하여 서비스 목록에서 Amazon Kinesis를 AWS Management Console 선택합니다.
-
왼쪽 탐색 페이지에서 Analytics 애플리케이션을 선택한 다음 Studio 노트북을 선택합니다.
-
KinesisDataAnalyticsStudio 노트북이 실행 중인지 확인하십시오.
-
노트북을 선택한 다음 Apache Zeppelin에서 열기를 선택합니다.
-
데이터를 읽고 Kinesis 스트림으로 로드하는 데 사용할 Data Producer Zeppelin Notebook
파일을 다운로드하십시오. -
Data ProducerZeppelin Notebook을 가져오십시오. 노트북 코드의 입력STREAM_NAME및REGION을 수정해야 합니다. 입력 스트림 명칭은 AWS CloudFormation 스택 출력에서 찾을 수 있습니다. -
입력 Kinesis Data Stream에 샘플 데이터를 삽입하려면 이 단락 실행 버튼을 선택하여 Data Producer 노트북을 실행합니다.
-
샘플 데이터가 로드되는 동안 MaskPhoneNumber-Interactive 노트북
을 다운로드하면 입력 데이터를 읽고, 입력 스트림에서 전화번호를 익명화하고, 익명화된 데이터를 출력 스트림에 저장할 수 있습니다. -
MaskPhoneNumber-interactiveZeppelin 노트북을 가져오십시오. -
노트북의 각 단락을 실행하십시오.
-
단락 1에서는 사용자 정의 함수를 가져와서 전화번호를 익명화합니다.
%flink(parallelism=1) import com.mycompany.app.MaskPhoneNumber stenv.registerFunction("MaskPhoneNumber", new MaskPhoneNumber()) -
다음 단락에서는 입력 스트림 데이터를 읽을 수 있는 메모리 내 표를 생성합니다. 스트림 이름과 AWS 리전이 올바른지 확인합니다.
%flink.ssql(type=update) DROP TABLE IF EXISTS customer_reviews; CREATE TABLE customer_reviews ( customer_id VARCHAR, product VARCHAR, review VARCHAR, phone VARCHAR ) WITH ( 'connector' = 'kinesis', 'stream' = 'KinesisUDFSampleInputStream', 'aws.region' = 'us-east-1', 'scan.stream.initpos' = 'LATEST', 'format' = 'json'); -
데이터가 메모리 내 표에 로드되었는지 확인하십시오.
%flink.ssql(type=update) select * from customer_reviews -
사용자 정의 함수를 호출하여 전화번호를 익명화합니다.
%flink.ssql(type=update) select customer_id, product, review, MaskPhoneNumber('mask_phone', phone) as phoneNumber from customer_reviews -
이제 전화번호가 마스킹되었으니 마스킹된 번호로 뷰를 만드십시오.
%flink.ssql(type=update) DROP VIEW IF EXISTS sentiments_view; CREATE VIEW sentiments_view AS select customer_id, product, review, MaskPhoneNumber('mask_phone', phone) as phoneNumber from customer_reviews -
데이터를 확인합니다.
%flink.ssql(type=update) select * from sentiments_view -
출력 Kinesis 스트림에 대한 메모리 내 표를 생성합니다. 스트림 이름과 AWS 리전이 올바른지 확인합니다.
%flink.ssql(type=update) DROP TABLE IF EXISTS customer_reviews_stream_table; CREATE TABLE customer_reviews_stream_table ( customer_id VARCHAR, product VARCHAR, review VARCHAR, phoneNumber varchar ) WITH ( 'connector' = 'kinesis', 'stream' = 'KinesisUDFSampleOutputStream', 'aws.region' = 'us-east-1', 'scan.stream.initpos' = 'TRIM_HORIZON', 'format' = 'json'); -
대상 Kinesis 스트림에 업데이트된 레코드를 삽입합니다.
%flink.ssql(type=update) INSERT INTO customer_reviews_stream_table SELECT customer_id, product, review, phoneNumber FROM sentiments_view -
대상 Kinesis 스트림의 데이터를 보고 확인합니다.
%flink.ssql(type=update) select * from customer_reviews_stream_table
-
노트북을 애플리케이션으로 승격
노트북 코드를 대화형 방식으로 테스트했으니 이제 코드를 지속 가능한 상태의 스트리밍 애플리케이션으로 배포해 보겠습니다. Amazon S3에서 코드를 저장할 위치를 지정하려면 먼저 애플리케이션 구성을 수정해야 합니다.
-
에서 노트북을 AWS Management Console선택하고 애플리케이션 구성으로 배포 - 선택 사항에서 편집을 선택합니다.
-
Amazon S3의 코드 대상에서AWS CloudFormation 스크립트로
생성된 Amazon S3 버킷을 선택합니다. 이 프로세스는 몇 분 정도 걸릴 수 있습니다. -
현재 상태로는 메모를 홍보할 수 없습니다. 내보내기를 시도하면
Select명령문이 지원되지 않으므로 오류가 발생합니다. 이 문제를 방지하려면 MaskPhoneNumber-Streaming Zeppelin Notebook을 다운로드하십시오. -
MaskPhoneNumber-streamingZeppelin Notebook을 가져오십시오. -
노트를 열고 KinesisDataAnalyticsStudio를 위한 조치를 선택합니다.
-
MaskPhoneNumber-Streaming 구축을 선택하고 S3로 내보내기를 선택합니다. 애플리케이션 명칭을 바꾸고 특수 문자를 포함하지 않도록 하십시오.
-
구축 및 내보내기를 선택합니다. 스트리밍 애플리케이션을 설정하는 데 몇 분 정도 걸립니다.
-
빌드가 완료되면 AWS 콘솔을 사용하여 배포를 선택합니다.
-
다음 페이지에서 설정을 검토하고 올바른 IAM 역할을 선택했는지 확인하십시오. 다음으로 스트리밍 애플리케이션 생성을 선택합니다.
-
몇 분 후 스트리밍 애플리케이션이 성공적으로 생성되었다는 메시지가 표시됩니다.
지속 가능한 상태 및 제한이 있는 애플리케이션을 배포하는 방법에 대한 자세한 설명은 지속 가능한 상태의 애플리케이션으로 배포를 참조하십시오.
정리
원하는 경우 이제 AWS CloudFormation 스택을 제거할 수 있습니다. 이렇게 하면 이전에 설정한 모든 서비스가 제거됩니다.
