기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
자습서: OpenSearch Service 및 OpenSearch Dashboards를 사용하여 고객 지원 통화 시각화
이 장에서는 몇 차례의 고객 지원 문의 전화를 받은 기업에서 이를 분석하려는 상황에 대해 자세히 알아봅니다. 각 통화의 주제는 무엇입니까? 긍정적인 내용은 몇 통이었습니까? 부정적인 내용은 몇 통이었습니까? 관리자가 이러한 통화의 녹취록을 검색하거나 검토하려면 어떻게 해야 합니까?
수작업 워크플로우에서는 직원들이 녹음된 내용을 듣고, 각 통화의 주제를 기록하고, 고객 상담 내용이 긍정적이었는지를 판단합니다.
따라서 이러한 프로세스는 대단히 노동 집약적입니다. 평균 통화 시간이 10분이라고 가정하면 직원 한 명이 하루에 48건의 통화밖에 들을 수 없습니다. 인간의 편견이 작용하지 않는다면 이들은 매우 정확한 데이터를 생산해 내겠지만, 그 데이터의 양은 최소한에 불과하여 통화의 주제와 고객이 만족했는지 여부에 대한 부울 값 정도를 얻을 수 있을 것입니다. 전체 녹취록 등 그 이상의 결과물이 필요한 경우에는 막대한 시간이 소요됩니다.
Amazon S3
이 연습 단계를 그대로 사용해도 되지만, JSON 문서를 OpenSearch Service에 인덱싱하기 전에 문서를 보강하는 방법에 관한 아이디어를 얻는 것이 이 과정의 목표입니다.
추정 비용
일반적으로, 이 연습 단계를 수행하는 데 드는 비용은 2달러 미만입니다. 이 연습 단계에서는 다음 리소스를 사용합니다.
-
전송 및 저장량이 100MB 미만인 S3 버킷
자세한 내용은 Amazon S3 요금
을 참조하세요. -
몇 시간 동안의 10GiB EBS 스토리지와
t2.medium인스턴스 한 개가 있는 OpenSearch Service 도메인자세한 내용은 Amazon OpenSearch Service 요금
을 참조하세요. -
Amazon Transcribe에 대한 호출 여러 개
자세한 내용은 Amazon Transcribe 요금
을 참조하세요. -
Amazon Comprehend에 대한 자연어 처리 호출 여러 개
자세한 내용은 Amazon Comprehend 요금
을 참조하세요.
1단계: 사전 조건 구성
계속하려면 먼저 다음 리소스를 확보해야 합니다.
| 전제 조건 | 설명 |
|---|---|
| Amazon S3 버킷 | 자세한 내용은 Amazon Simple Storage Service 사용 설명서에서 버킷 생성을 참조하세요. |
| OpenSearch Service 도메인 | 데이터의 대상 주소입니다. 자세한 내용은 OpenSearch Service 도메인 생성을 참조하세요. |
이러한 리소스가 아직 없는 경우 다음 AWS CLI 명령을 사용하여 만들 수 있습니다.
aws s3 mb s3://my-transcribe-test --region us-west-2
aws opensearch create-domain --domain-name my-transcribe-test --engine-version OpenSearch_1.0 --cluster-config InstanceType=t2.medium.search,InstanceCount=1 --ebs-options EBSEnabled=true,VolumeType=standard,VolumeSize=10 --access-policies '{"Version":"2012-10-17","Statement":[{"Effect":"Allow","Principal":{"AWS":"arn:aws:iam::123456789012:root"},"Action":"es:*","Resource":"arn:aws:es:us-west-2:123456789012:domain/my-transcribe-test/*"}]}' --region us-west-2
참고
이 명령은 us-west-2 리전을 사용하지만, Amazon Comprehend가 지원하는 아무 리전이나 사용할 수 있습니다. 자세한 내용은 AWS 일반 참조 섹션을 참조하십시오.
2단계: 샘플 코드 복사
-
다음 Python 3 샘플 코드를 복사하여
call-center.py라는 새 파일에 붙여넣습니다.import boto3 import datetime import json import requests from requests_aws4auth import AWS4Auth import time import urllib.request # Variables to update audio_file_name = '' # For example, 000001.mp3 bucket_name = '' # For example, my-transcribe-test domain = '' # For example, https://search-my-transcribe-test-12345.us-west-2.es.amazonaws.com index = 'support-calls' type = '_doc' region = 'us-west-2' # Upload audio file to S3. s3_client = boto3.client('s3') audio_file = open(audio_file_name, 'rb') print('Uploading ' + audio_file_name + '...') response = s3_client.put_object( Body=audio_file, Bucket=bucket_name, Key=audio_file_name ) # # Build the URL to the audio file on S3. # # Only for the us-east-1 region. # mp3_uri = 'https://' + bucket_name + '.s3.amazonaws.com/' + audio_file_name # Get the necessary details and build the URL to the audio file on S3. # For all other regions. response = s3_client.get_bucket_location( Bucket=bucket_name ) bucket_region = response['LocationConstraint'] mp3_uri = 'https://' + bucket_name + '.s3-' + bucket_region + '.amazonaws.com/' + audio_file_name # Start transcription job. transcribe_client = boto3.client('transcribe') print('Starting transcription job...') response = transcribe_client.start_transcription_job( TranscriptionJobName=audio_file_name, LanguageCode='en-US', MediaFormat='mp3', Media={ 'MediaFileUri': mp3_uri }, Settings={ 'ShowSpeakerLabels': True, 'MaxSpeakerLabels': 2 # assumes two people on a phone call } ) # Wait for the transcription job to finish. print('Waiting for job to complete...') while True: response = transcribe_client.get_transcription_job(TranscriptionJobName=audio_file_name) if response['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break else: print('Still waiting...') time.sleep(10) transcript_uri = response['TranscriptionJob']['Transcript']['TranscriptFileUri'] # Open the JSON file, read it, and get the transcript. response = urllib.request.urlopen(transcript_uri) raw_json = response.read() loaded_json = json.loads(raw_json) transcript = loaded_json['results']['transcripts'][0]['transcript'] # Send transcript to Comprehend for key phrases and sentiment. comprehend_client = boto3.client('comprehend') # If necessary, trim the transcript. # If the transcript is more than 5 KB, the Comprehend calls fail. if len(transcript) > 5000: trimmed_transcript = transcript[:5000] else: trimmed_transcript = transcript print('Detecting key phrases...') response = comprehend_client.detect_key_phrases( Text=trimmed_transcript, LanguageCode='en' ) keywords = [] for keyword in response['KeyPhrases']: keywords.append(keyword['Text']) print('Detecting sentiment...') response = comprehend_client.detect_sentiment( Text=trimmed_transcript, LanguageCode='en' ) sentiment = response['Sentiment'] # Build the Amazon OpenSearch Service URL. id = audio_file_name.strip('.mp3') url = domain + '/' + index + '/' + type + '/' + id # Create the JSON document. json_document = {'transcript': transcript, 'keywords': keywords, 'sentiment': sentiment, 'timestamp': datetime.datetime.now().isoformat()} # Provide all details necessary to sign the indexing request. credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, 'opensearchservice', session_token=credentials.token) # Index the document. print('Indexing document...') response = requests.put(url, auth=awsauth, json=json_document, headers=headers) print(response) print(response.json()) -
처음 여섯 개의 변수를 업데이트합니다.
-
다음 명령을 사용하여 필요한 패키지를 설치합니다.
pip install boto3 pip install requests pip install requests_aws4auth -
MP3를
call-center.py와 동일한 디렉터리에 넣고 스크립트를 실행합니다. 샘플 출력은 다음과 같습니다.$ python call-center.py Uploading 000001.mp3... Starting transcription job... Waiting for job to complete... Still waiting... Still waiting... Still waiting... Still waiting... Still waiting... Still waiting... Still waiting... Detecting key phrases... Detecting sentiment... Indexing document... <Response [201]> {u'_type': u'call', u'_seq_no': 0, u'_shards': {u'successful': 1, u'failed': 0, u'total': 2}, u'_index': u'support-calls4', u'_version': 1, u'_primary_term': 1, u'result': u'created', u'_id': u'000001'}
call-center.py는 다음 몇 가지 작업을 수행합니다.
-
이 스크립트는 S3 버킷에 오디오 파일(이 경우에는 MP3지만, Amazon Transcribe는 다른 형식도 지원함)을 업로드합니다.
-
오디오 파일의 URL을 Amazon Transcribe로 보낸 다음 녹취 작업이 완료되기를 기다립니다.
녹취 작업의 완료 시간은 오디오 파일의 길이에 따라 달라집니다. 몇 초가 아니라 몇 분이 걸립니다.
작은 정보
녹취 품질을 높이기 위해 Amazon Transcribe에 대한 사용자 지정 어휘를 구성할 수 있습니다.
-
녹취 작업이 완료되면 스크립트가 녹취록을 추출하고, 5,000자로 정리한 다음 키워드 및 감정 분석을 위해 Amazon Comprehend로 보냅니다.
-
마지막으로 이 스크립트는 전체 녹취록, 키워드, 감정 분석, 현재 타임스탬프 등을 JSON 문서에 추가하고 OpenSearch Service에서 이를 인덱싱합니다.
작은 정보
LibriVox
(선택 사항) 3단계: 샘플 데이터 인덱싱
다수의 통화 레코딩을 바로 사용할 수 없는 경우 call-center.py에서 생성하는 것에 해당하는 샘플 문서를 sample-calls.zip으로 인덱스할 수 있습니다.
-
bulk-helper.py라는 이름의 파일을 만듭니다.import boto3 from opensearchpy import OpenSearch, RequestsHttpConnection import json from requests_aws4auth import AWS4Auth host = '' # For example, my-test-domain.us-west-2.es.amazonaws.com region = '' # For example, us-west-2 service = 'es' bulk_file = open('sample-calls.bulk', 'r').read() credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) search = OpenSearch( hosts = [{'host': host, 'port': 443}], http_auth = awsauth, use_ssl = True, verify_certs = True, connection_class = RequestsHttpConnection ) response = search.bulk(bulk_file) print(json.dumps(response, indent=2, sort_keys=True)) -
host및region의 처음 두 변수를 업데이트합니다. -
다음 명령을 사용하여 필요한 패키지를 설치합니다.
pip install opensearch-py -
sample-calls.zip을 다운로드하여 압축을 풉니다.
-
sample-calls.bulk를bulk-helper.py와 동일한 디렉터리에 넣고 도움말을 실행합니다. 샘플 출력은 다음과 같습니다.$ python bulk-helper.py { "errors": false, "items": [ { "index": { "_id": "1", "_index": "support-calls", "_primary_term": 1, "_seq_no": 42, "_shards": { "failed": 0, "successful": 1, "total": 2 }, "_type": "_doc", "_version": 9, "result": "updated", "status": 200 } },...], "took": 27 }
4단계: 데이터 분석 및 시각화
OpenSearch Service에 데이터가 있으므로 OpenSearch Dashboards를 사용하여 시각화할 수 있습니다.
-
https://search-로 이동합니다.domain.region.es.amazonaws.com/_dashboards -
OpenSearch Dashboards를 사용하려면 먼저 인덱스 패턴이 있어야 합니다. Dashboards는 인덱스 패턴을 사용하여 분석 범위를 하나 이상의 인덱스로 좁혀 줍니다.
call-center.py에서 생성된support-calls인덱스를 일치시키려면 스택 관리(Stack Management), 인덱스 패턴(Index Patterns)으로 이동하여support*의 인덱스 패턴을 정의한 다음, 다음 단계(Next step)를 선택합니다. -
시간 필터 필드 이름(Time Filter field name)에서 타임스탬프(timestamp)를 선택합니다.
-
이제 시각화를 생성할 수 있습니다. 시각화(Visualize)를 선택한 다음, 새 시각화를 추가합니다.
-
파이 차트와
support*인덱스 패턴을 선택합니다. -
시각화의 기본값은 기본이므로 조각 분할(Split Slices)을 선택하여 보다 흥미로운 시각화를 만듭니다.
집계(Aggregation)에서 조건(Terms)을 선택합니다. 필드(Field)에서 sentiment.keyword를 선택합니다. 그런 다음 변경 사항 적용(Apply changes) 및 저장(Save)을 선택합니다.
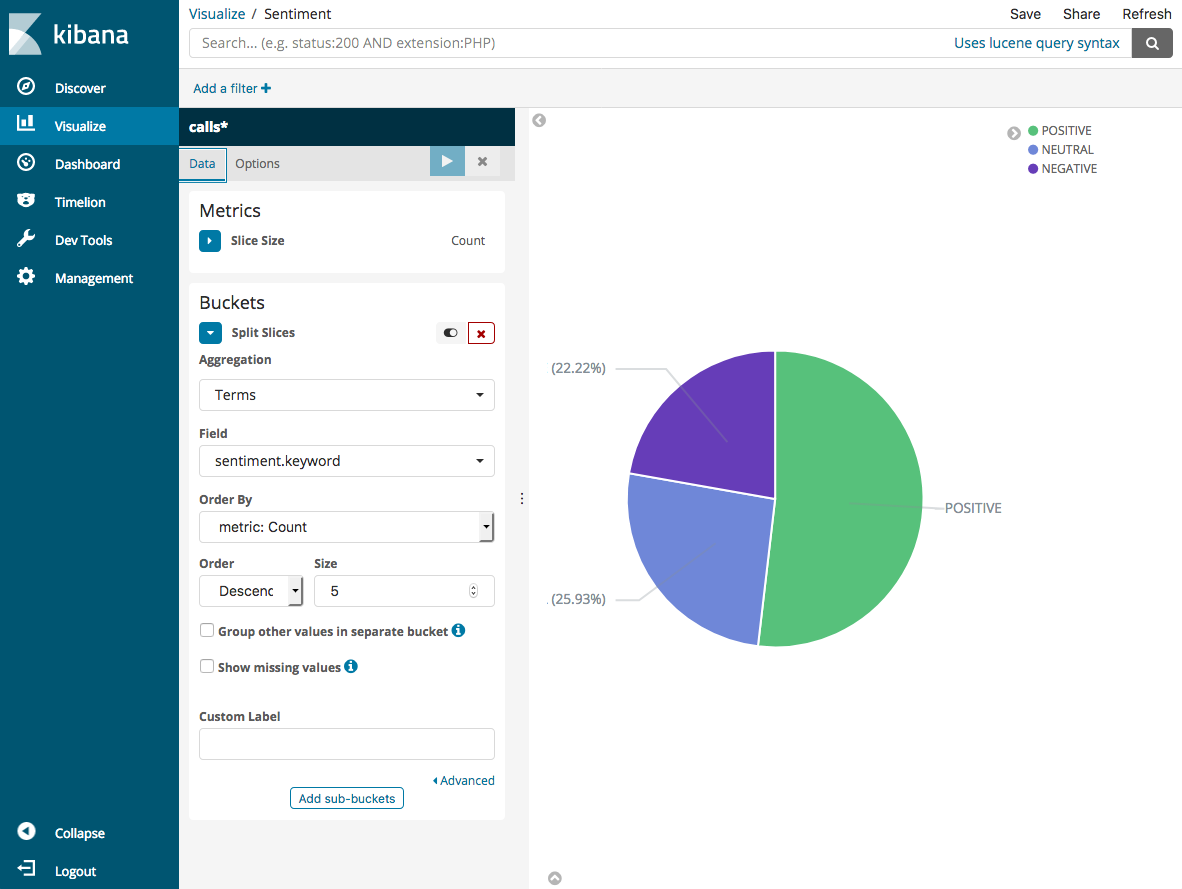
-
시각화(Visualize) 페이지로 돌아가서 다른 시각화를 추가합니다. 이번에는 가로 막대 차트를 선택합니다.
-
계열 분할(Split Series)을 선택합니다.
집계(Aggregation)에서 조건(Terms)을 선택합니다. 필드에서 keywords.keyword를 선택하고 크기(Size)를 20으로 변경합니다. 그런 다음 변경 사항 적용(Apply Changes) 및 저장(Save)을 선택합니다.

-
시각화(Visualize) 페이지로 돌아가서 마지막 시각화인 세로 막대 차트를 추가합니다.
-
계열 분할(Split Series)을 선택합니다. 집계(Aggregation)에서 날짜 히스토그램(Date Histogram)을 선택합니다. 필드(Field)에서 타임스탬프(timestamp)를 선택하고 간격(Interval)을 매일(Daily)로 변경합니다.
-
지표 및 축(Metrics & Axes)을 선택하고 모드(Mode)를 정상(normal)으로 변경합니다.
-
변경 사항 적용(Apply Changes) 및 저장(Save)을 선택합니다.

-
이제 시각화 세 개를 Dashboards 대시보드에 추가할 수 있습니다. 대시보드(Dashboard)를 선택하고, 대시보드를 만들고, 시각화를 추가합니다.

5단계: 리소스 정리 및 다음 단계
불필요한 요금 부과를 피하려면 S3 버킷과 OpenSearch Service 도메인을 삭제하세요. 자세한 내용은 Amazon Simple Storage Service 사용 설명서의 버킷 삭제 및 이 가이드의 OpenSearch Service 도메인 삭제 섹션을 참조하세요.
녹취록은 MP3 파일보다 필요한 디스크 공간이 훨씬 적습니다. MP3 보존 기간을 단축하고(예: 통화 레코딩 3개월에서 1개월로 단축) 스토리지 비용을 절감할 수 있습니다.
또한 AWS Step Functions 및 Lambda를 사용하여 트랜스크립션 프로세스를 자동화하거나, 인덱싱 전에 메타데이터를 추가하거나, 정확한 사용 사례에 맞게 더 복잡한 시각화를 만들 수 있습니다.
