기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Aurora 상태 및 Step Functions 상태 머신
이 섹션에서는 Amazon Aurora 클러스터의 장애 조치 및 장애 복구와 관련된 프로세스 및 상태 시스템을 다룹니다. 클러스터는 글로벌 데이터베이스로 구성됩니다.
참고
데모용으로 이 예제에서는 Aurora MySQL 호환 에디션을 사용합니다. Aurora PostgreSQL 호환 에디션에서도 비슷한 단계를 사용할 수 있습니다.
정상 상태
안정적인 상태에서 Amazon Aurora MySQL 호환 글로벌 데이터베이스 (dr-globaldb-cluster-mysql) 는 두 개의 DB 클러스터를 사용하여 생성되었습니다. 읽기/쓰기 워크로드를 처리하기 위해 첫 번째 DB 클러스터 (db-cluster-01) 가 기본 AWS 리전
(us-east-1) 에 생성되었습니다. 읽기 전용 워크로드를 처리하기 위해 보조 지역 (db-cluster-02) 에 두 번째 DB 클러스터 (us-west-2) 가 생성되었습니다.
DR 솔루션을 제공하는 것 외에도 애플리케이션의 읽기 쿼리를 보조 DB 클러스터로 라우팅하여 기본 DB 클러스터의 부하를 줄일 수 있습니다. 각 클러스터에는 각각 dbcluster-01-use1-instance-1 및 dbcluster-02-usw2-instance-2 라는 데이터베이스 인스턴스가 하나씩 포함되어 있습니다.
이벤트 상태
Amazon Aurora 글로벌 데이터베이스를 사용하면 재해에 대한 계획을 세우고 재해에 신속하게 복구할 수 있습니다. 재해 복구는 일반적으로 복구 시간 목표 (RTO) 및 복구 시점 목표 (RPO) 값을 사용하여 측정됩니다. 자세한 내용은 Amazon Aurora 글로벌 데이터베이스에서의 전환 또는 장애 조치 사용을 참조하십시오.
Aurora 글로벌 데이터베이스의 페일오버에는 두 가지 접근 방식이 있습니다.
-
전환 (관리형 계획된 페일오버)
-
페일오버 (계획되지 않은 수동 페일오버 또는 분리 및 프로모션)
전환
스위치오버는 운영 유지 관리 및 기타 계획된 운영 절차와 같은 통제된 환경을 위한 것입니다. 계획된 장애 조치 관리를 사용하면 Aurora 글로벌 데이터베이스의 기본 DB 클러스터를 보조 지역 중 하나로 재배치할 수 있습니다. 전환은 보조 DB 클러스터가 기본 데이터베이스와 동기화될 때까지 대기하므로 RPO는 0입니다 (데이터 손실 없음). 자세한 내용은 Amazon Aurora 글로벌 데이터베이스의 전환 수행을 참조하십시오.
이벤트 dr-orchestrator-stepfunction-FAILOVER 상태 중에 상태 머신이 호출되어 기본 클러스터를 선택한 보조 지역 () 으로 전환합니다. us-west-2
전환을 수행하려면 다음과 같이 하십시오.
-
AWS Management Console에 로그인합니다.
-
지역을 DR 지역 ()
us-west-2으로 변경합니다. -
서비스로 이동한 다음 Step Functions를 선택합니다.
-
dr-orchestrator-stepfunction-FAILOVER스테이트 머신으로 이동합니다. -
[실행 시작] 을 선택하고
Input - optional섹션에 다음 JSON 코드를 입력합니다.{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "PlannedFailoverAurora", "resourceName": "Switchover (planned failover) of Amazon Aurora global databases (MySQL)", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier" } } ] } ] } -
dr-orchestrator-stepfunction-FAILOVER상태 머신은 리소스 유형을PlannedFailoverAuroraMySQL로 읽고dr-orchestrator-stepfunction-planned-Aurora-failover상태 머신을 호출하여 Aurora 글로벌 데이터베이스를 페일오버합니다.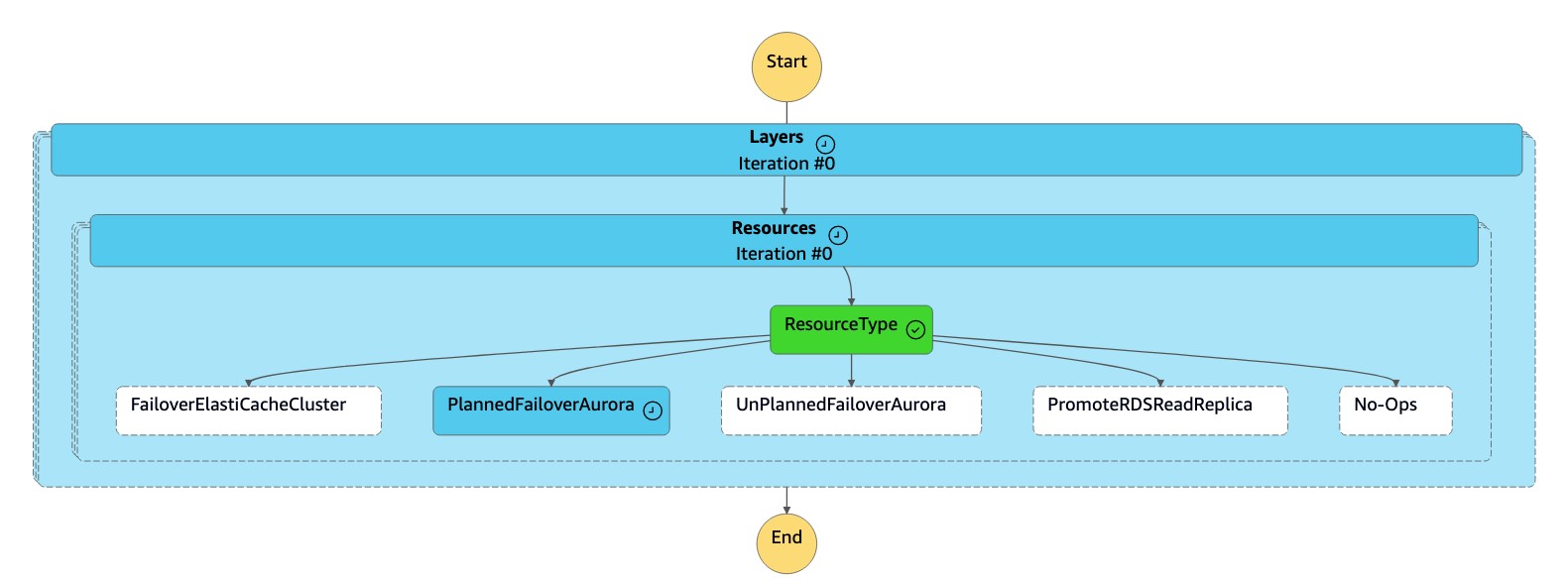
-
dr-orchestrator-stepfunction-planned-Aurora-failover상태 머신은 다음 단계를 수행하여 Aurora MySQL 호환 글로벌 데이터베이스 역할을 전환합니다.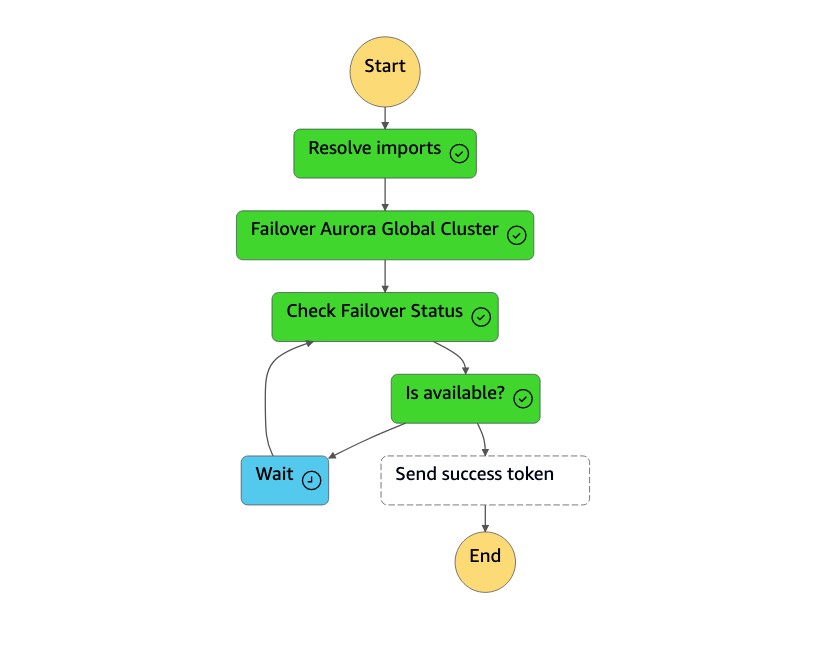
단계 설명 예상 값 임포트 문제 해결 Lambda 함수는 값을 실제 이름으로 !Import <variable name>대체합니다."!Import dr-globaldb-cluster-mysql-global-identifier"로 대체됩니다."dr-globaldb-cluster-mysql"페일오버 Aurora 글로벌 클러스터 Lambda 함수는 failover_global_cluster Boto3 API를 호출하여 Aurora 글로벌 데이터베이스를 페일오버합니다. { 'GlobalCluster': { 'GlobalClusterIdentifier': 'dr-globaldb-cluster-mysql', 'GlobalClusterResourceId': 'cluster-cce7f9bec2846db4', 'GlobalClusterArn': 'arn:aws:rds::xxx', 'Status': 'failing-over', .... .... } }페일오버 상태 확인 Lambda 함수는 describe_db_cluster Boto3 API를 호출하여 페일오버의 상태를 확인합니다. 수정, 사용 가능 성공 토큰 전송 Lambda 함수는 send_task_success Boto3 API를 호출하고 성공 토큰을 상태 머신에 다시 보냅니다. DR Orchestrator FailoverRiCdLtdH7x dMccoxlzFhglsdkzp /83P1e0 K9MBVKZSP7D9YRT1w -
Amazon RDS 콘솔로 이동합니다. 상태에서 Aurora 글로벌 데이터베이스의 값이 사용 가능에서 전환 또는 수정 중으로 변경됩니다.
-
dr-orchestrator-stepfunction-planned-Aurora-failover상태 머신이 완료되면 상태 머신에 성공 토큰을dr-orchestrator-stepfunction-FAILOVER다시 보냅니다.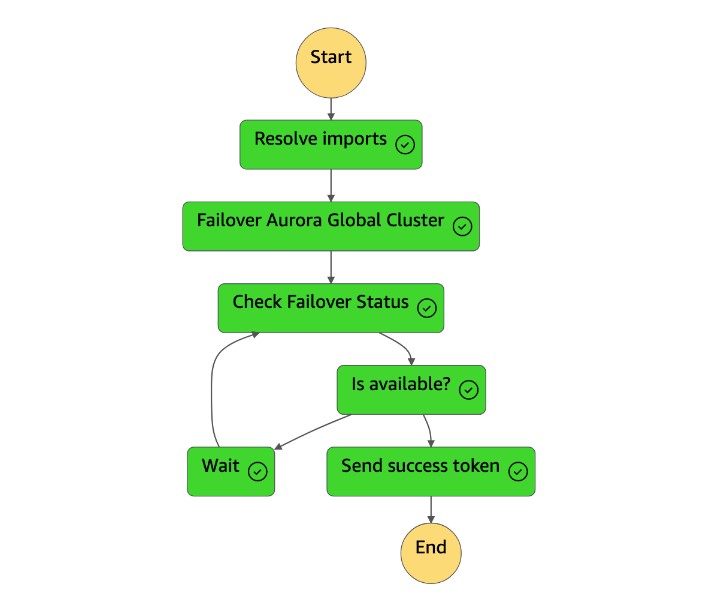
-
dr-orchestrator-stepfunction-FAILOVER스테이트 머신이 완료되었습니다.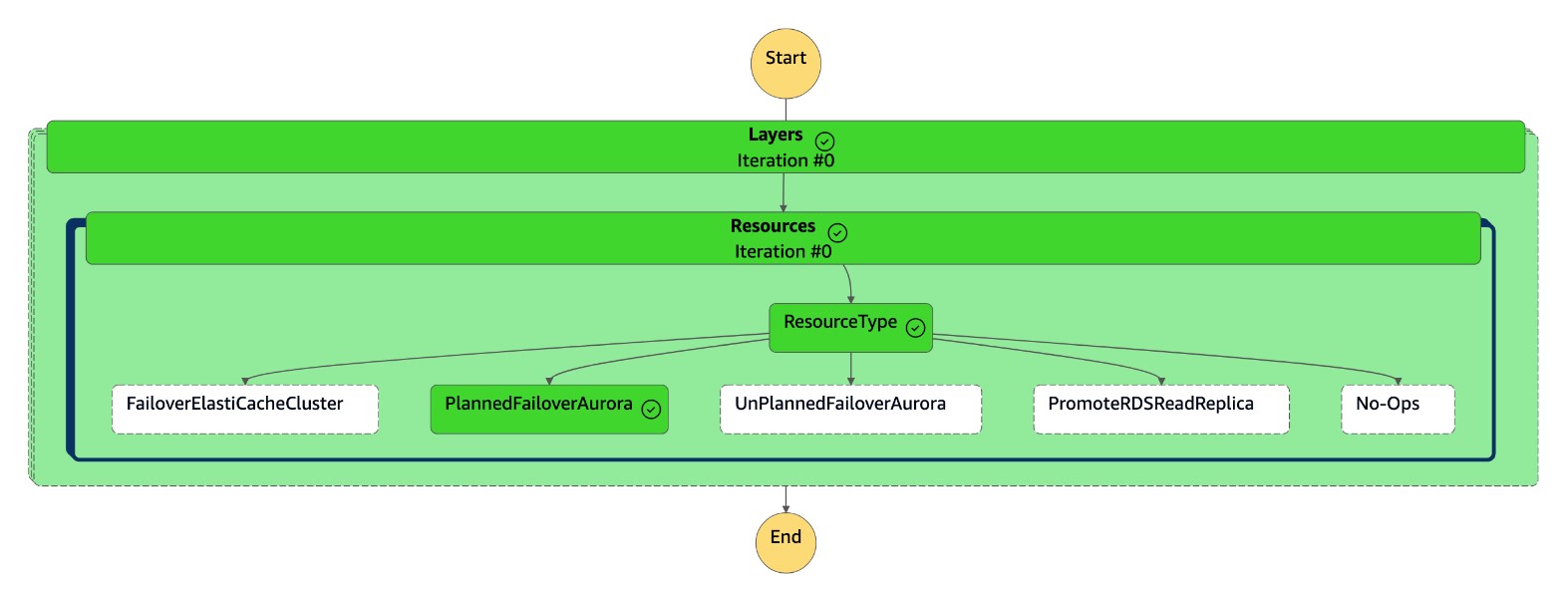
콘솔에서 보조 클러스터 (dbcluster-02) 의 역할은 이제 기본 클러스터이며 클러스터는 읽기/쓰기 워크로드를 처리할 준비가 되었습니다. 원래 기본 클러스터 (dbcluster-01) 의 역할은 이제 보조 클러스터로 표시됩니다.
예상치 못한 수동 페일오버
드문 경우이긴 하지만 Aurora 글로벌 데이터베이스의 기본 데이터베이스에서 예상치 못한 중단이 발생할 수 있습니다. AWS 리전이 경우, 기본 Aurora DB 클러스터와 해당 라이터 노드를 사용할 수 없으며 기본 클러스터와 보조 클러스터 간의 복제가 중단됩니다. 다운타임 (RTO) 과 데이터 손실 (RPO) 을 모두 최소화하려면 신속하게 작업하여 지역 간 페일오버를 수행하고 Aurora 글로벌 데이터베이스를 재구성하십시오. 자세한 내용은 예상치 못한 중단으로부터 Amazon Aurora 글로벌 데이터베이스 복구를 참조하십시오.
계획되지 않은 페일오버를 수행하려면 Aurora 글로벌 데이터베이스에서 보조 클러스터를 분리해야 합니다. 계획되지 않은 장애 조치를 수행하기 전에 기본 Aurora DB 클러스터에서 애플리케이션 쓰기를 중지하십시오. 장애 조치가 성공적으로 완료되면 새 기본 DB 클러스터에 쓰도록 애플리케이션을 재구성하십시오. 이 접근 방식은 데이터 손실을 방지하는 데 도움이 됩니다. 또한 페일오버 프로세스 중에 주 작성기 노드가 다시 온라인 상태가 되는 경우 데이터 불일치를 방지하는 데도 도움이 됩니다.
계획되지 않은 페일오버를 수행하려면 상태 머신을 호출하십시오. dr-orchestrator-stepfunction-FAILOVER 이 예시에서는 보조 클러스터 (db-cluster-02) 가 DR 지역 (us-west-2) 에 정상 상태입니다.
페일오버를 수행하려면 다음과 같이 하십시오.
-
콘솔에 로그인합니다.
-
지역을 DR 지역 (
us-west-2) 으로 변경합니다. -
서비스로 이동한 다음 Step Functions를 선택합니다.
-
dr-orchestrator-stepfunction-FAILOVER스테이트 머신으로 이동합니다. -
실행 시작을 선택하고 다음과
UnPlannedFailoverAurora같이Input - optional섹션에 다음 JSON 코드를 입력합니다.resourceType{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "UnPlannedFailoverAurora", "resourceName": "Performing unplanned failover for Amazon Aurora global databases (MySQL)", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier", "ClusterRegion": "!Import dr-globaldb-cluster-mysql-cluster-region" } } ] } ] } -
dr-orchestrator-stepfunction-FAILOVER상태 머신은 리소스 유형을 그대로UnPlannedFailoverAuroraMySQL읽고dr-orchestrator-stepfunction-unplanned-Aurora-failover상태Detach Cluster from Global Database머신에서 작업을 호출합니다.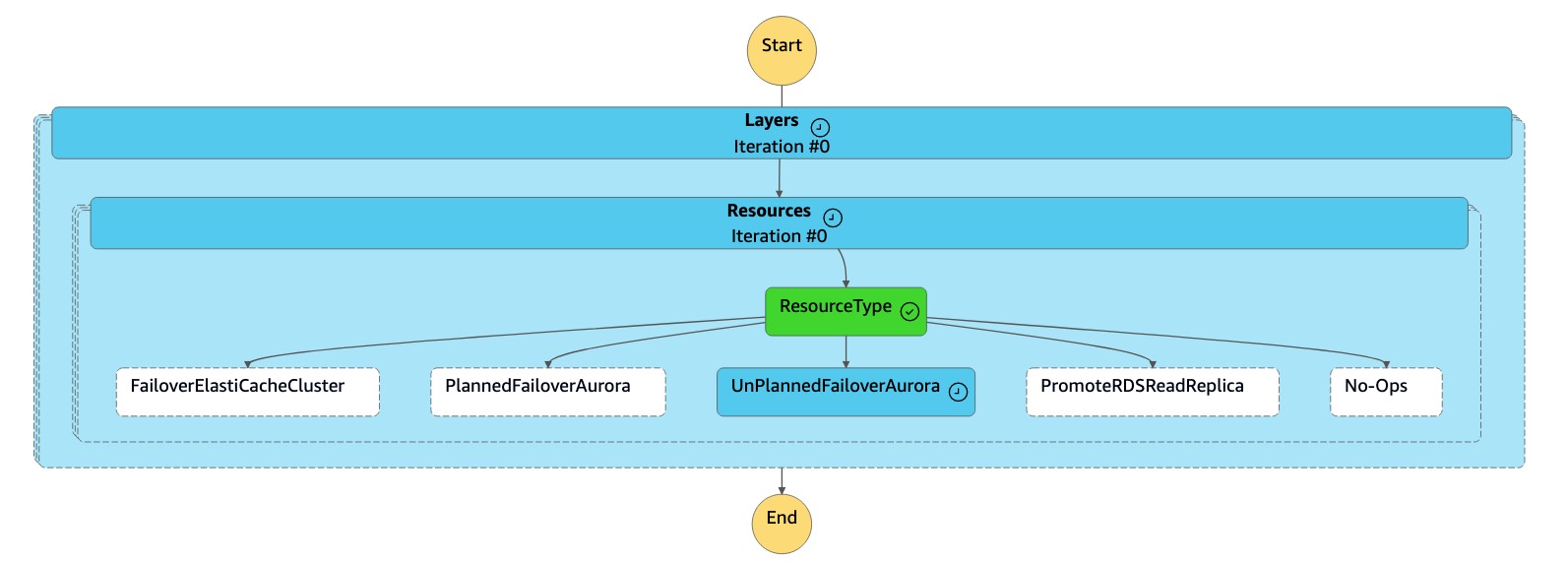
-
이
Detach Cluster from Global Database작업은 글로벌 데이터베이스에서 보조 클러스터를 분리 (제거) 합니다.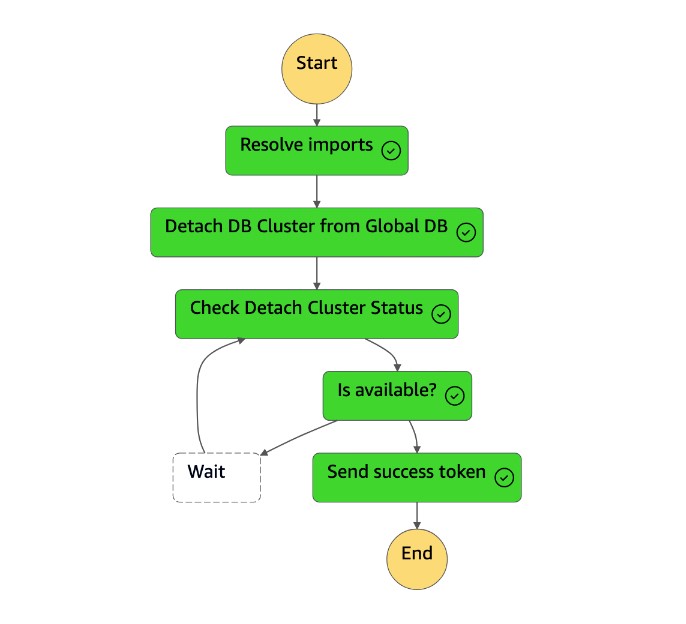
-
보조 클러스터 (
dbcluster-02) 는 독립형 클러스터로 승격되어 읽기/쓰기 워크로드를 처리할 수 있습니다. -
dr-orchestrator-stepfunction-FAILOVER스테이트 머신이 완료되었습니다.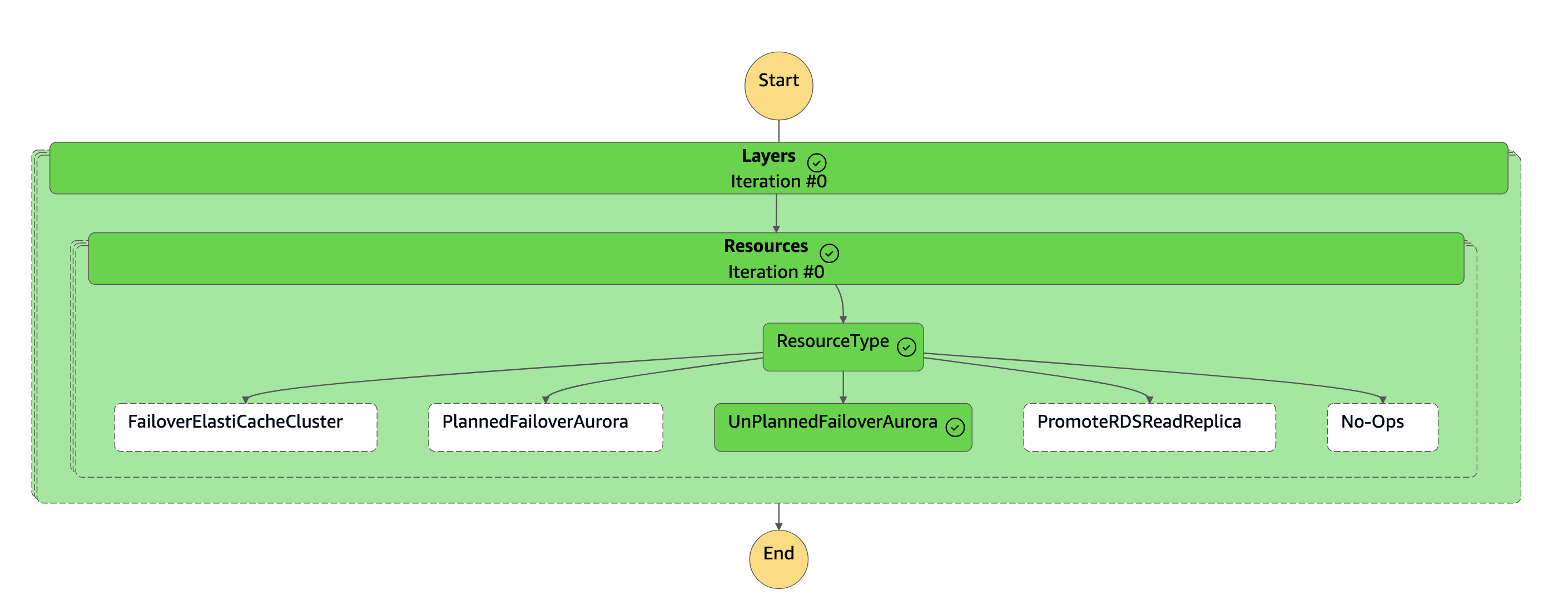
-
보조 클러스터 (
dbcluster-02) 는 Aurora 글로벌 데이터베이스에서 분리되며 읽기/쓰기 워크로드를 지원하는 독립 실행형 클러스터가 됩니다. -
새 클러스터 엔드포인트를 사용하여 이 새로운 독립형 Aurora DB 클러스터로 모든 쓰기 작업을 전송하도록 애플리케이션을 재구성하십시오.
페일백
장애 복구는 재해 (또는 예정된 이벤트) 가 해결된 후 데이터베이스를 원래 (또는 새) 기본 위치로 되돌립니다. 예상치 못한 운영 중단이 해결되면 이전의 기본 지역을 Aurora 글로벌 데이터베이스에 다시 추가하는 것이 좋습니다. 먼저 이전의 기본 지역에서 기존 DB 클러스터를 삭제하고, 새 기본 지역에서 새 DB 클러스터를 만든 다음, 계획된 관리형 장애 조치 프로세스를 사용하여 새 클러스터의 역할을 전환해야 합니다.
이는 사용량이 적은 시간대나 주말에 수행할 수 있는 계획된 활동으로 간주할 수 있습니다.
이전 기본 지역 (us-east-1) 에서 DR Orchestrator FAILBACK 상태 머신을 실행하려면 DeletionProtection 먼저 Amazon Aurora DB 클러스터를 수동으로 수정하고 를 비활성화해야 합니다. DeletionProtection
DR Orchestrator Framework는 dr-orchestrator-stepfunction-FAILBACK 상태 머신을 사용하여 기존 클러스터를 삭제하고 이전의 기본 지역에 새 클러스터를 생성하는 단계를 자동화합니다.
DeletionProtection비활성화하려면 다음과 같이 하십시오.
-
콘솔에 로그인합니다.
-
지역을 이전의 기본 지역 (
us-east-1) 으로 변경합니다. -
Amazon RDS 콘솔로 이동하여 클러스터 이름 (
dbcluster-01) 을 선택하고 [Modify] 를 선택합니다. -
삭제 보호에서 삭제 보호 활성화 확인란의 선택을 취소하고 계속을 선택합니다.
-
[즉시 적용] 을 선택한 다음 [클러스터 수정] 을 선택합니다.
DR Orchestrator FAILBACK상태 머신은 이전의 기본 지역 () us-east-1 에서 페일백 프로세스 중에 호출됩니다.
페일백을 수행하려면 다음과 같이 하십시오.
-
콘솔에 로그인합니다.
-
지역을 이전의 기본 지역 (
us-east-1) 으로 변경합니다. -
서비스로 이동한 다음 Step Functions를 선택합니다.
-
DR Orchestrator FAILBACK스테이트 머신으로 이동합니다. -
[실행 시작] 을 선택하고
Input - optional섹션에 다음 JSON 코드를 입력합니다.{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "CreateAuroraSecondaryDBCluster", "resourceName": "To create secondary Aurora MySQL Global Database Cluster", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier", "DBClusterName": "!Import dr-globaldb-cluster-mysql-cluster-name", "SourceDBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-source-cluster-identifier", "DBInstanceIdentifier": "!Import dr-globaldb-cluster-mysql-instance-identifier", "Port": "!Import dr-globaldb-cluster-mysql-port", "DBInstanceClass": "!Import dr-globaldb-cluster-mysql-instance-class", "DBSubnetGroupName": "!Import dr-globaldb-cluster-mysql-subnet-group-name", "VpcSecurityGroupIds": "!Import dr-globaldb-cluster-mysql-vpc-security-group-ids", "Engine": "!Import dr-globaldb-cluster-mysql-engine", "EngineVersion": "!Import dr-globaldb-cluster-mysql-engine-version", "KmsKeyId": "!Import dr-globaldb-cluster-mysql-KmsKeyId", "SourceRegion": "!Import dr-globaldb-cluster-mysql-source-region", "ClusterRegion": "!Import dr-globaldb-cluster-mysql-cluster-region", "BackupRetentionPeriod": "7", "MonitoringInterval": "60", "StorageEncrypted": "True", "EnableIAMDatabaseAuthentication": "True", "DeletionProtection": "True", "CopyTagsToSnapshot": "True", "AutoMinorVersionUpgrade": "True", "MonitoringRoleArn": "!Import rds-mysql-instance-RDSMonitoringRole" } } ] } ] } -
DR Orchestrator FAILBACK상태 머신은 리소스 유형을 로CreateAuroraSecondaryDBCluster읽고dr-orchestrator-stepfunction-create-Aurora-Secondary-cluster상태 머신을 호출합니다.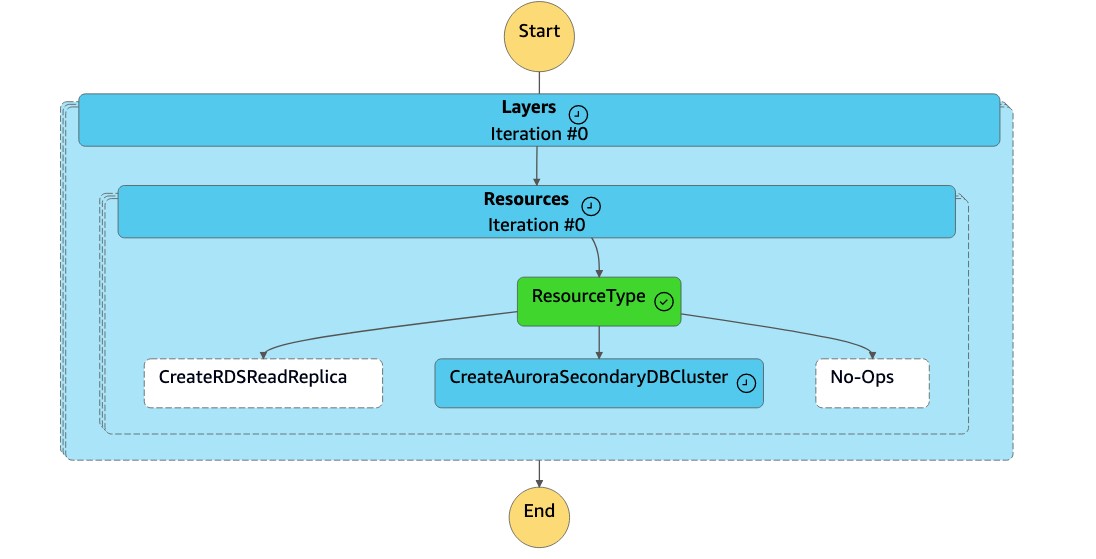
-
dr-orchestrator-stepfunction-create-Aurora-Secondary-cluster상태 머신은 이전의 기본 지역 (dbcluster-01) 에서 기존 클러스터 (us-east-1) 를 삭제합니다.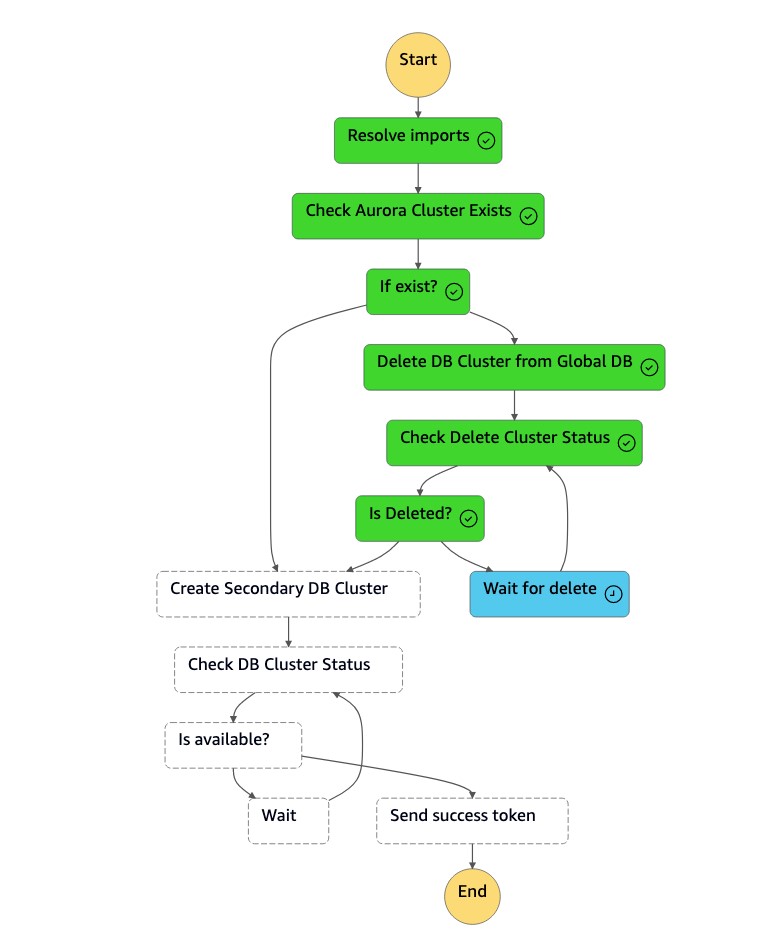
-
클러스터 (
dbcluster-01) 가 삭제되면 상태 머신은 DB 인스턴스와 함께 새 클러스터 (dbcluster-01) 를 생성하고 Aurora 글로벌 데이터베이스를 보조 클러스터로 결합하여 읽기 전용 워크로드를 처리합니다.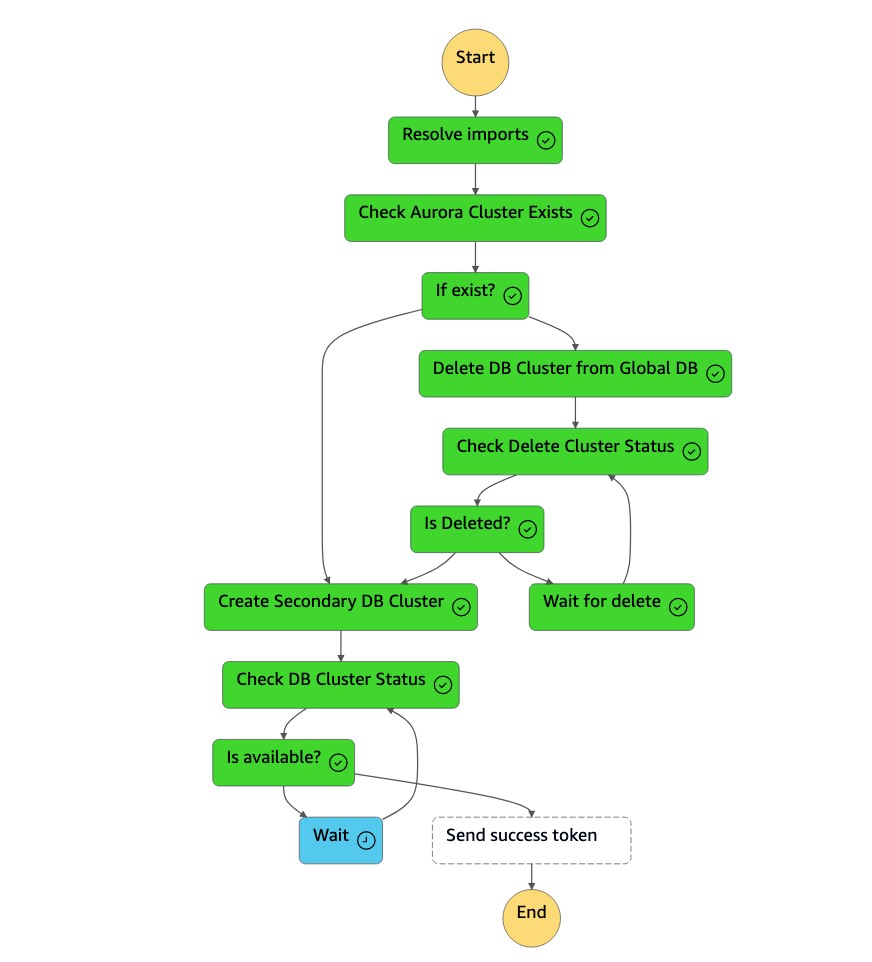
-
보조 클러스터를 사용할 수 있게 되면
dr-orchestrator-stepfunction-create-Aurora-Secondary-cluster상태 머신이 완료되고 상태 머신에 성공 토큰이DR Orchestrator Failback다시 전송됩니다.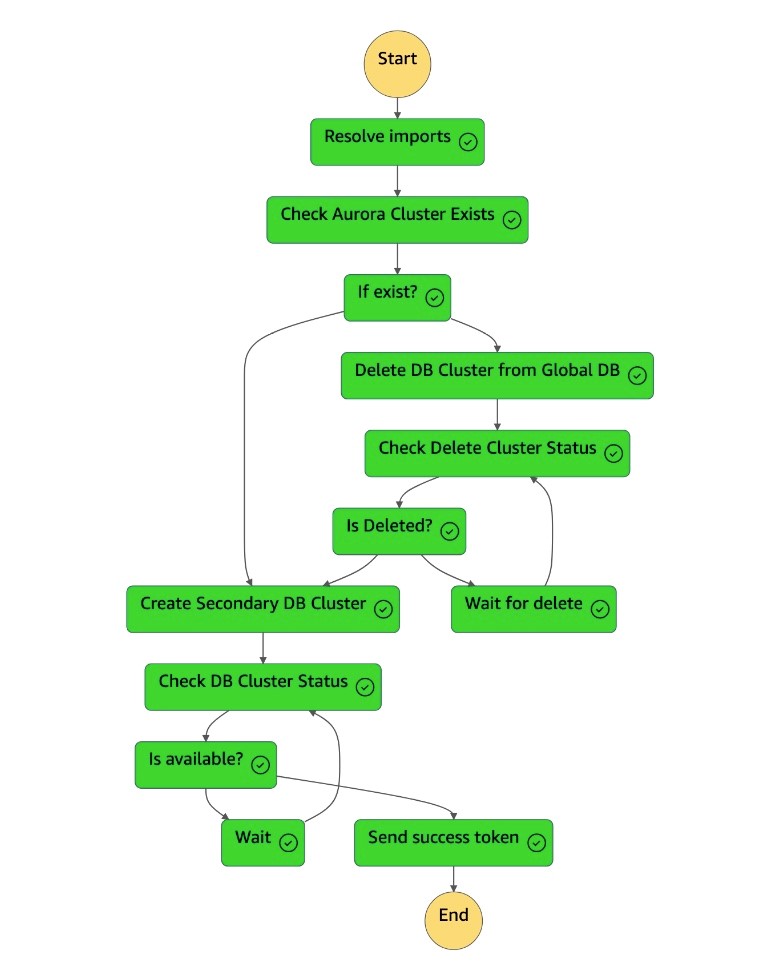
-
dr-orchestrator-stepfunction-FAILBACK스테이트 머신이 완료되었습니다.
-
Amazon RDS 콘솔에서 Aurora 글로벌 데이터베이스를 확인할 수 있습니다.
기본 DB 클러스터를 us-east-1로 재배치하려는 경우 전환 섹션에 설명된 단계를 따를 수 있습니다.
