기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
참조 아키텍처
다음 다이어그램은이 가이드의 자동 솔루션을 일일 운영 보고서에 적용한 후의 워크플로를 보여줍니다. 새 파일이 Amazon Simple Storage Service(Amazon S3)에 수집되면 처리된 후 QuickSight 대시보드에서 즉시 시각화할 수 있습니다.
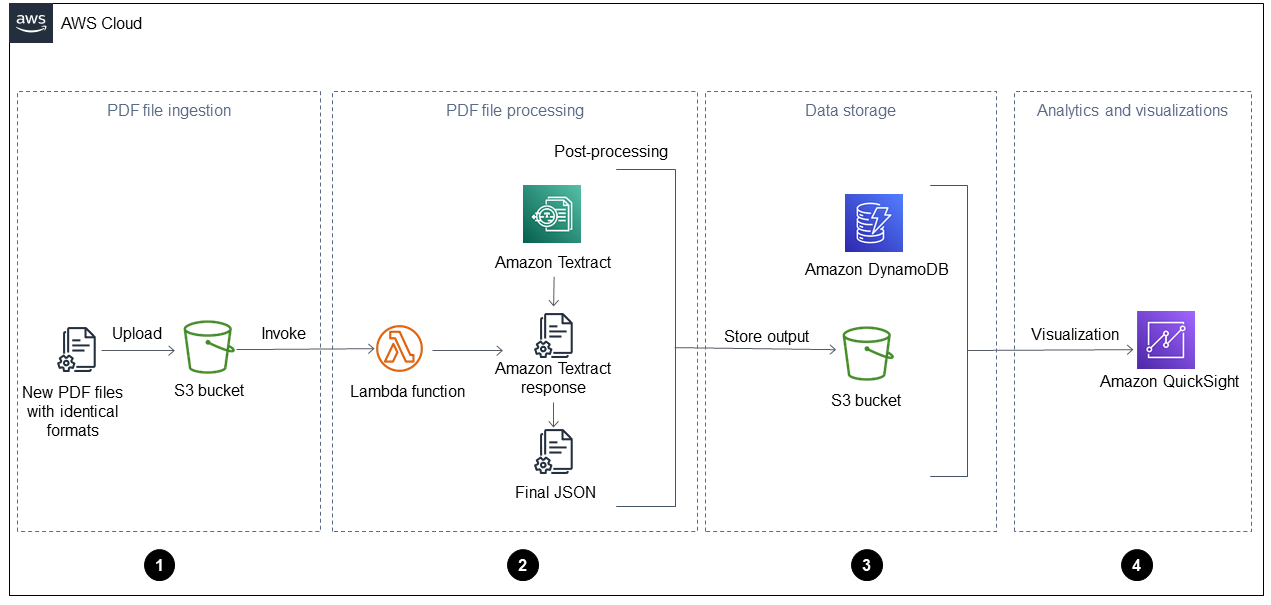
다이어그램은 다음 4단계를 보여줍니다.
-
PDF 파일 수집 - 애플리케이션이 동일한 형식(예: 일일 작업 보고서)의 새 PDF 파일을 Amazon Simple Storage Service(Amazon S3) 버킷에 자동으로 수집합니다. Amazon S3는 버킷에 새 PDF 파일이 추가되고 이를 통해 AWS Lambda 함수가 호출될 때
ObjectCreated이벤트를 시작합니다. 이에 대한 자세한 내용은 Amazon S3 설명서의 Amazon S3 트리거를 사용하여 Lambda 함수 호출을 참조하세요. Amazon S3 -
PDF 파일 처리 - Lambda 함수는 하나의 PDF 파일을 Amazon Textract로 전송하여 콘텐츠를 추출합니다. 사후 처리 스크립트는 Amazon Textract 응답을 실행하고 구문 분석하며이 유형의 PDF 파일에 사전 정의된 템플릿을 사용합니다. 이 템플릿에는 올바른 속성이 포함되어 있으며 모든 키-값 페어, 테이블 및 기타 원시 텍스트를 올바르게 추출하는 데 도움이 됩니다. 이에 대한 자세한 내용은 AWS 권장 가이드 웹 사이트의 Amazon Textract를 사용하여 PDF 파일에서 콘텐츠 자동 추출 패턴을 참조하세요.
-
데이터 스토리지 - 추출되고 수정된 데이터는 각 PDF 파일에 대한 JSON 파일 외에도 Amazon DynamoDB 테이블에 저장됩니다. JSON 파일은 Amazon Amazon Athena, QuickSight 또는 Amazon Amazon SageMakerS3 버킷에 저장됩니다.
-
분석 및 시각화 - QuickSight는 데이터를 분석하고 처리된 모든 PDF 파일에 대한 인사이트를 생성하는 데 도움이 되는 시각화를 생성합니다. QuickSight에서 대시보드를 생성한 후 최종 사용자 및 비즈니스 팀과 공유할 수 있습니다.
고려 사항
이 가이드의 솔루션은 형식이 동일하고 양식 및 테이블의 레이아웃이 일관된 PDF 파일을 처리하는 데 적합합니다. 그러나 템플릿을 정의하고 미리 편집하여 프로세스를 완전히 자동화하고 추출된 데이터를 분석에 사용할 수 있도록 해야 합니다. 그런 다음이 템플릿은 Lambda 함수로 처리하는 동안 사용됩니다.
이 솔루션은 여러 PDF 파일 유형에 동시에 적용할 수 있지만 각 PDF 파일 유형에 대해 별도의 템플릿을 생성 및 정의하고 액세스 가능한 위치(예: Amazon S3)에 저장해야 합니다. 각 PDF 파일 유형에 대해 PDF 파일 이름 또는 S3 버킷의 다른 폴더와 같은 고유 식별자를 사용하는 것이 좋습니다. 그러면 Lambda 함수가 PDF 파일 유형을 처리할 때 적절한 템플릿을 호출할 수 있습니다.
