기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
모범 사례
스토리지 및 기술 모범 사례를 따르는 것이 좋습니다. 이러한 모범 사례는 데이터 중심 아키텍처를 최대한 활용하는 데 도움이 될 수 있습니다.
빅 데이터에 대한 스토리지 모범 사례
다음 표에서는 Amazon S3에서 빅 데이터 처리 로드를 위한 파일을 저장하는 일반적인 모범 사례를 설명합니다. 마지막 열은 설정할 수 있는 수명 주기 정책의 예입니다. Amazon S3 Intelligent-Tiering
데이터 계층 이름 | 설명 | 수명 주기 정책 전략의 예 |
원시 | 처리되지 않은 원시 데이터 포함 참고: 외부 데이터 소스의 경우 원시 데이터 계층은 일반적으로 데이터의 1:1 복사본이지만 AWS에서는 수집 프로세스 중에 데이터를 AWS 리전 또는 날짜를 기반으로 키로 분할할 수 있습니다. | 1년 후 파일을 S3 Standard-IA 스토리지 클래스로 이동합니다. S3 Standard-IA에서 2년 후 Amazon Simple Storage Service Glacier(Amazon S3 Glacier)에 파일을 보관합니다. |
단계 | 사용량에 최적화된 중간 처리 데이터 포함 예: CSV에서 Apache Parquet로 변환된 원시 파일 또는 데이터 변환 | 정의된 기간 이후에 또는 조직의 요구 사항에 따라 데이터를 삭제할 수 있습니다. 짧은 시간(예: 90일 후) 후에 데이터 레이크에서 일부 데이터 파생 항목(예: 원래 JSON 형식의 Apache Avro 변환)을 제거할 수 있습니다. |
분석 | 특정 사용 사례에 대한 집계된 데이터를 사용 준비 형식으로 포함합니다. 예: Apache Parquet | 데이터를 S3 Standard-IA로 이동한 다음 정의된 기간 이후에 또는 조직의 요구 사항에 따라 데이터를 삭제할 수 있습니다. |
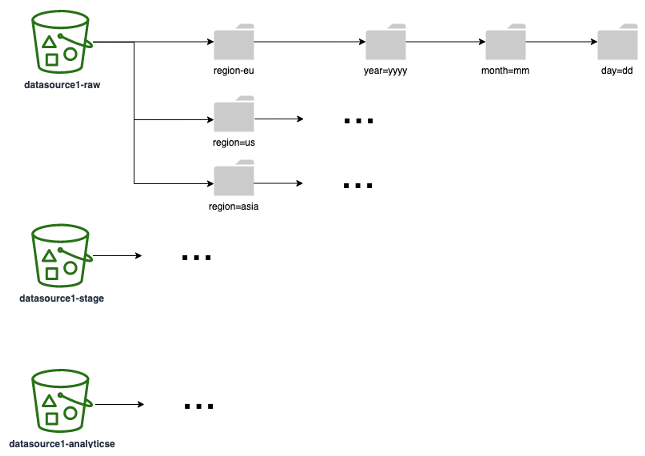
다음 다이어그램은 모든 데이터 계층에서 사용할 수 있는 파티셔닝 전략(하나의 S3 폴더/접두사에 해당)의 예를 보여줍니다. 다운스트림에서 데이터를 사용하는 방식에 따라 파티셔닝 전략을 선택하는 것이 좋습니다. 예를 들어, 보고서가 데이터를 기반으로 구축된 경우(보고서의 가장 일반적인 쿼리가 리전 및 날짜를 기준으로 결과를 필터링하는 경우) 쿼리 성능과 런타임을 개선하기 위해 리전과 날짜를 파티션으로 포함해야 합니다.
기술 모범 사례
기술 모범 사례는 데이터 중심 아키텍처를 설계하는 데 사용하는 특정 AWS 서비스 및 처리 기술에 따라 달라집니다. 그러나 다음 모범 사례를 염두에 두는 것이 좋습니다. 이러한 모범 사례는 일반적인 데이터 처리 사용 사례에 적용됩니다.
영역 | 모범 사례 |
SQL | 데이터에 속성을 프로젝션하여 쿼리해야 하는 데이터의 양을 줄입니다. 전체 테이블을 구문 분석하는 대신 데이터 프로젝션을 사용하여 테이블의 특정 필수 열만 스캔하고 반환할 수 있습니다. 여러 테이블 간의 조인은 리소스 집약적인 요구로 인해 성능에 큰 영향을 미칠 수 있으므로 가능하면 대규모 조인을 피합니다. |
Apache Spark | AWS Glue(AWS 빅 데이터 블로그)에서 워크로드 파티셔닝으로 Spark 애플리케이션을 최적화 AWS Glue(AWS 빅 데이터 블로그)에서 메모리 관리를 최적화 |
데이터베이스 설계 | 아키텍처 데이터베이스 모범 사례 |
데이터 정리 | 에서 서버 측 파티션 정리를 사용합니다 |
스케일링 | 수평적 조정 |
