기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon Textract를 사용하여 PDF 파일에서 콘텐츠 자동 추출하기
Tianxia Jia, Amazon Web Services
요약
많은 조직에서는 비즈니스 애플리케이션에 업로드되는 PDF 파일에서 정보를 추출해야 합니다. 예를 들어, 조직은 세금 분석이나 의료 청구 처리를 위해 세금 또는 의료 PDF 파일에서 정보를 정확하게 추출해야 할 수 있습니다.
Amazon Web Services 클라우드에서 Amazon Textract는 PDF 파일에서 정보(예: 인쇄된 텍스트, 양식 및 표)를 자동으로 추출하고 소스 PDF 파일의 정보가 포함된 JSON 형식의 파일을 생성합니다. 관리 콘솔에서 또는 API 직접 호출을 구현하여 Amazon Textract를 사용할 수 있습니다. 프로그래밍 방식의 API 직접 호출
Amazon Textract는 파일을 처리할 때 페이지, 텍스트 줄 및 단어, 양식(키-값 쌍), 테이블 및 셀, 선택 요소 등의 Block 객체 목록을 생성합니다. 경계 상자, 신뢰 구간, ID 및 관계와 같은 다른 객체 정보도 포함됩니다. Amazon Textract는 콘텐츠 정보를 문자열로 추출합니다. 다운스트림 애플리케이션에서 더 쉽게 사용할 수 있으므로 데이터 값을 정확하게 식별하고 변환해야 합니다.
이 패턴은 Amazon Textract를 사용하여 PDF 파일에서 콘텐츠를 자동으로 추출하고 클린 출력으로 처리하는 단계별 워크플로를 설명합니다. 이 패턴은 템플릿 매칭 기법을 사용하여 필수 필드, 키 이름 및 테이블을 정확하게 식별한 후 각 데이터 유형에 사후 처리 수정 사항을 적용합니다. 이 패턴을 사용하여 다양한 유형의 PDF 파일을 처리한 다음 이 워크플로를 확장 및 자동화하여 형식이 동일한 PDF 파일을 처리할 수 있습니다.
사전 조건 및 제한 사항
사전 조건
활성 상태의 계정.
Amazon Textract에서 처리할 수 있도록 PDF 파일을 JPEG 형식으로 변환한 후 해당 파일을 저장할 기존 Amazon Simple Storage Service(S3) 버킷입니다. S3 버킷에 대한 자세한 내용은 Amazon S3 설명서의 버킷 개요를 참조하십시오.
Textract_PostProcessing.ipynbJupyter Notebook (첨부됨), 설치 및 구성됨. Jupyter Notebook에 대한 자세한 내용은 Amazon SageMaker 설명서에서 Jupyter Notebook 생성을 참조하십시오.형식이 동일한 기존 PDF 파일.
Python에 대한 이해.
제한 사항
PDF 파일은 품질이 좋고 읽기 쉬워야 합니다. 기본 PDF 파일을 사용하는 것이 좋지만, 개별 단어가 모두 명확하다면 PDF 형식으로 변환된 스캔 문서를 사용할 수 있습니다. 이에 대한 자세한 내용은 Machine Learning 블로그에서 Amazon Textract를 사용한 PDF 문서 사전 처리: 시각적 탐지 및 제거
를 참고하십시오. 여러 페이지 파일의 경우 비동기 작업을 사용하거나 PDF 파일을 단일 페이지로 분할하고 동기 작업을 사용할 수 있습니다. 이 두 옵션에 대한 자세한 내용은 Amazon Textract 설명서의 여러 페이지 문서에서 텍스트 감지 및 분석 및 단일 페이지 문서의 텍스트 감지 및 분석을 참고하십시오.
아키텍처
이 패턴의 워크플로는 먼저 샘플 PDF 파일에서 Amazon Textract를 실행한(처음 실행) 후에 첫 번째 PDF와 형식이 동일한 PDF 파일에서 실행(반복 실행) 합니다. 다음 다이어그램은 형식이 동일한 PDF 파일에서 콘텐츠를 자동으로 반복적으로 추출하는 최초 실행 및 반복 실행 워크플로를 함께 보여줍니다.
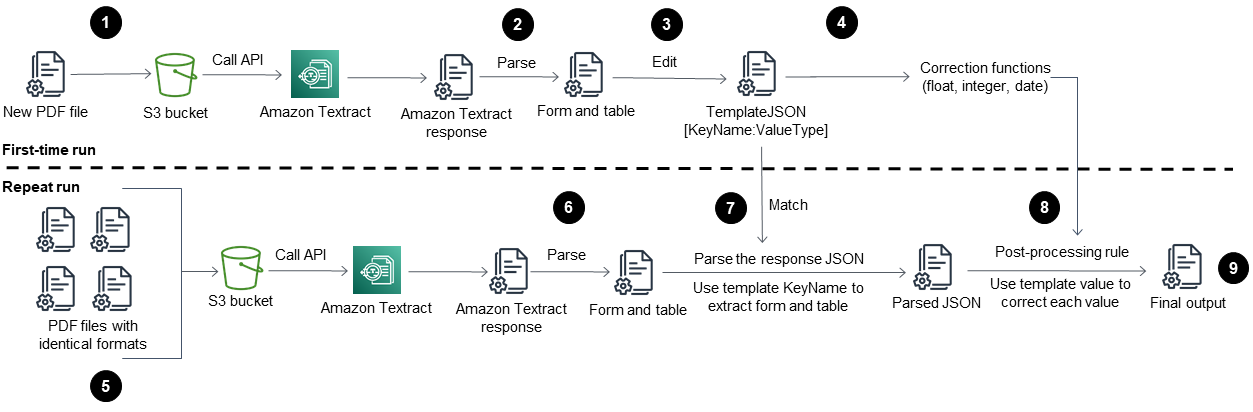
이 다이어그램은 이 패턴에 대해 다음 워크플로를 보여 줍니다.
PDF 파일을 JPEG 형식으로 변환하고 S3 버킷에 저장합니다.
Amazon Textract API를 호출하여 Amazon Textract 응답 JSON 파일을 파싱합니다.
각 필수 필드에 올바른
KeyName:DataType페어를 추가하여 JSON 파일을 편집하십시오. 반복 실행 단계를 위한TemplateJSON파일을 생성합니다.각 데이터 유형(예: 부동 소수점, 정수, 날짜)에 대한 사후 처리 수정 함수를 정의합니다.
첫 번째 PDF 파일과 형식이 동일한 PDF 파일을 준비합니다.
Amazon Textract API를 호출하고 Amazon Textract 응답 JSON을 파싱합니다.
파싱된 JSON 파일을
TemplateJSON파일과 일치시킵니다.사후 처리 수정을 구현합니다.
최종 JSON 출력 파일에는 각 필수 필드에 대한 올바른 KeyName 및 Value이 있습니다.
대상 기술 스택
Amazon SageMaker
Amazon S3
Amazon Textract
자동화 및 규모 조정
Amazon S3에 새 PDF 파일이 추가될 때 Amazon Textract를 시작하는 Lambda 함수를 사용하여 반복 실행 워크플로를 자동화할 수 있습니다. 그러면 Amazon Textract가 처리 스크립트를 실행하고 최종 출력을 스토리지 위치에 저장할 수 있습니다. 이에 대한 자세한 내용은 Lambda 설명서에서 Amazon S3 트리거를 사용하여 Lambda 함수 호출을 참고하십시오.
도구
Amazon SageMaker는 ML 모델을 빠르고 쉽게 구축하고 훈련시킨 다음 해당 모델을 프로덕션 지원 호스팅 환경에 직접 배포할 수 있는 완전 관리형 ML 서비스입니다.
Amazon Simple Storage Service(S3)는 원하는 양의 데이터를 저장, 보호 및 검색하는 데 도움이 되는 클라우드 기반 객체 스토리지 서비스입니다.
Amazon Textract를 사용하면 애플리케이션에 문서 텍스트 감지 및 분석을 쉽게 추가할 수 있습니다.
에픽
| 작업 | 설명 | 필요한 기술 |
|---|---|---|
PDF 파일을 변환합니다. | PDF 파일을 단일 페이지로 분할하고 Amazon Textract 동기 작업( 참고다중 페이지 PDF 파일에 Amazon Textract 비동기 작업( | 데이터 사이언티스트, 개발자 |
Amazon Textract의 응답 JSON을 파싱합니다. |
다음 코드를 사용하여 응답 JSON을 양식 및 테이블로 구문 분석합니다.
| 데이터 사이언티스트, 개발자 |
TemplateJSON 파일을 편집합니다. | 각 이 템플릿은 각 개별 PDF 파일 유형에 사용되므로 형식이 동일한 PDF 파일에 템플릿을 재사용할 수 있습니다. | 데이터 사이언티스트, 개발자 |
사후 처리 수정 함수를 정의합니다. |
다음 코드를 사용하여
| 데이터 사이언티스트, 개발자 |
| 작업 | 설명 | 필요한 기술 |
|---|---|---|
PDF 파일을 준비합니다. | PDF 파일을 단일 페이지로 분할하고 Amazon Textract 동기 작업( 참고다중 페이지 PDF 파일에 Amazon Textract 비동기 작업( | 데이터 사이언티스트, 개발자 |
Amazon Textract API를 호출합니다. | 다음 코드를 사용하여 Amazon Textract API를 호출합니다.
| 데이터 사이언티스트, 개발자 |
Amazon Textract의 응답 JSON을 파싱합니다. | 다음 코드를 사용하여 응답 JSON을 양식 및 테이블로 구문 분석합니다.
| 데이터 사이언티스트, 개발자 |
TemplateJSON 파일을 로드하고 파싱된 JSON과 일치시킵니다. | 다음 명령을 사용하여
| 데이터 사이언티스트, 개발자 |
사후 처리 수정. |
| 데이터 사이언티스트, 개발자 |
관련 리소스
첨부
이 문서와 관련된 추가 콘텐츠에 액세스하려면 attachment.zip 파일의 압축을 풉니다.
