기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon OpenSearch Service에서 멀티 테넌트 서버리스 아키텍처 구축
Tabby Ward 및 Nisha Gambhir, Amazon Web Services
요약
Amazon OpenSearch Service는 인기 있는 오픈 소스 검색 및 분석 엔진인 Elasticsearch를 쉽게 배포, 운영, 확장할 수 있는 관리형 서비스입니다. OpenSearch Service는 로그 및 지표와 같은 스트리밍 데이터를 위한 실시간에 가까운 수집 및 대시보드뿐만 아니라 자유 텍스트 검색을 제공합니다.
서비스형 소프트웨어(SaaS) 공급자는 OpenSearch Service를 자주 사용하여 확장 가능하고 안전한 방식으로 고객 인사이트를 얻는 동시에 복잡성과 가동 중지 시간을 줄이는 등 다양한 사용 사례를 해결합니다.
다중 테넌트 환경에서 OpenSearch Service를 사용하면 SaaS 솔루션의 파티셔닝, 격리, 배포 및 관리에 영향을 미치는 일련의 고려 사항이 도입됩니다. SaaS 공급자는 지속적으로 변화하는 워크로드에 맞춰 Elasticsearch 클러스터를 효과적으로 확장하는 방법을 고려해야 합니다. 또한 계층화 및 소음이 많은 이웃 조건이 파티셔닝 모델에 어떤 영향을 미칠 수 있는지도 고려해야 합니다.
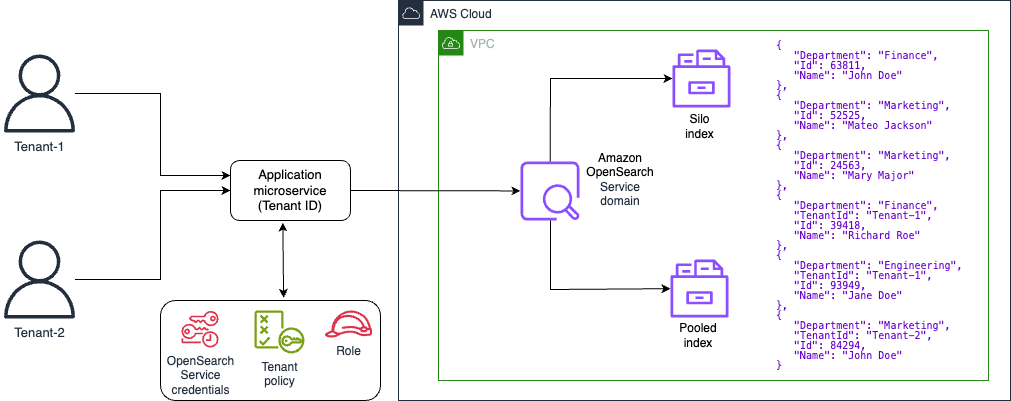
이 패턴은 Elasticsearch 구조로 테넌트 데이터를 표현하고 분리하는 데 사용되는 모델을 검토합니다. 또한이 패턴은 간단한 서버리스 참조 아키텍처를 예로 들어 다중 테넌트 환경에서 OpenSearch Service를 사용하여 인덱싱 및 검색을 시연하는 데 중점을 둡니다. 테넌트의 데이터 격리를 유지하면서 모든 테넌트 간에 동일한 인덱스를 공유하는 풀 데이터 파티셔닝 모델을 구현합니다. 이 패턴은 Amazon API Gateway, AWS Lambda Amazon Simple Storage Service(Amazon S3) 및 OpenSearch Service AWS 서비스를 사용합니다.
풀 모델 및 기타 데이터 파티셔닝 모델에 대한 자세한 내용은 추가 정보 섹션을 참조하십시오.
사전 조건 및 제한 사항
사전 조건
활성 AWS 계정
macOS, Linux 또는 Windows에 설치 및 구성된 AWS Command Line Interface (AWS CLI) 버전 2.x
Python 버전 3.9
pip3 — Python 소스 코드는 Lambda 함수에 배포할 수 있는.zip 파일로 제공됩니다. 코드를 로컬에서 사용하거나 사용자 지정하려면 다음 단계에 따라 소스 코드를 개발하고 다시 컴파일하십시오.
Python 스크립트와 동일한 디렉터리에서 pip3 freeze > requirements.txt 명령을 실행하여 requirements.txt 파일을 생성합니다.
종속성을 설치합니다: pip3 install -r requirements.txt
제한 사항
이 코드는 Python에서 실행되며 현재 다른 프로그래밍 언어를 지원하지 않습니다.
샘플 애플리케이션에는 AWS 교차 리전 또는 재해 복구(DR) 지원이 포함되지 않습니다.
이 패턴은 데모용으로만 제공됩니다. 프로덕션 환경에서 사용하기 위한 것이 아닙니다.
아키텍처
다음 다이어그램은 이 패턴의 높은 수준의 아키텍처를 보여줍니다. 이 아키텍처에는 다음 이벤트가 포함됩니다.
콘텐츠를 인덱싱하고 쿼리하는 Lambda
검색을 수행하는 OpenSearch Service
사용자와 API 상호 작용을 제공하는 API Gateway
원시 (인덱싱되지 않은) 데이터를 저장하는 Amazon S3
로그를 모니터링하는 Amazon CloudWatch
AWS Identity and Access Management 테넌트 역할 및 정책을 생성하기 위한 (IAM)
자동화 및 규모 조정
간소화를 위해 패턴은 AWS CLI 를 사용하여 인프라를 프로비저닝하고 샘플 코드를 배포합니다. AWS CloudFormation 템플릿 또는 AWS 클라우드 개발 키트 (AWS CDK) 스크립트를 생성하여 패턴을 자동화할 수 있습니다.
AWS 서비스
AWS CLI는 명령줄 셸에서 명령을 사용하여 AWS 서비스 및 리소스를 관리하기 위한 통합 도구입니다.
Lambda는 서버를 프로비저닝하거나 관리하지 않고도 코드를 실행할 수 있는 컴퓨팅 서비스입니다. Lambda는 필요 시에만 코드를 실행하며, 일일 몇 개의 요청에서 초당 수천 개의 요청까지 자동으로 확장이 가능합니다.
API Gateway는 모든 규모의 REST, HTTP 및 WebSocket API를 생성, 게시, 유지 관리, 모니터링 및 보호하기 AWS 서비스 위한 입니다. APIs
Amazon S3는 웹상의 어디서나 언제든지 원하는 양의 정보를 저장하고 검색할 수 있는 객체 스토리지 서비스입니다.
OpenSearch Service는 Elasticsearch를 비용 효율적으로 대규모로 쉽게 배포, 보안 및 실행할 수 있는 완전 관리형 서비스입니다.
코드
첨부 파일은 이 패턴에 대한 샘플 파일을 제공합니다. 다음이 포함됩니다.
index_lambda_package.zip - 풀 모델을 사용하여 OpenSearch Service에서 데이터를 인덱싱하기 위한 Lambda 함수입니다.
search_lambda_package.zip - OpenSearch Service에서 데이터를 검색하기 위한 Lambda 함수입니다.
Tenant-1-data— 테넌트-1의 원시 (인덱싱되지 않은) 데이터 샘플.
Tenant-2-data— 테넌트-2의 원시 (인덱싱되지 않은) 데이터 샘플.
이 패턴의 스토리에는 Unix, Linux 및 macOS용 형식의 AWS CLI 명령 예제가 포함되어 있습니다. Windows의 경우 각 줄의 끝에 있는 백슬래시(\) Unix 연속 문자를 캐럿(^)으로 바꿉니다.
AWS CLI 명령에서 각도 대괄호(<>) 내의 모든 값을 올바른 값으로 바꿉니다.
에픽
| 작업 | 설명 | 필요한 기술 |
|---|
S3 버킷을 생성합니다. | 에서 S3 버킷을 생성합니다 AWS 리전. 이 버킷에는 샘플 애플리케이션의 인덱싱되지 않은 테넌트 데이터가 보관됩니다. 네임스페이스는 모든 사용자가 공유하므로 S3 버킷의 이름이 전역적으로 고유한지 확인합니다 AWS 계정. 다음과 같이 AWS CLI create-bucket 명령을 사용하여 S3 버킷을 생성할 수 있습니다. aws s3api create-bucket \
--bucket <tenantrawdata> \
--region <your-AWS-Region>
tenantrawdata은 S3 버킷 이름입니다. (버킷 이름 지정 지침을 따르는 모든 고유한 이름을 사용할 수 있습니다.)
| 클라우드 아키텍트, 클라우드 관리자 |
| 작업 | 설명 | 필요한 기술 |
|---|
OpenSearch Service 도메인 생성 | AWS CLI create-elasticsearch-domain 명령을 실행하여 OpenSearch Service 도메인을 생성합니다. aws es create-elasticsearch-domain \
--domain-name vpc-cli-example \
--elasticsearch-version 7.10 \
--elasticsearch-cluster-config InstanceType=t3.medium.elasticsearch,InstanceCount=1 \
--ebs-options EBSEnabled=true,VolumeType=gp2,VolumeSize=10 \
--domain-endpoint-options "{\"EnforceHTTPS\": true}" \
--encryption-at-rest-options "{\"Enabled\": true}" \
--node-to-node-encryption-options "{\"Enabled\": true}" \
--advanced-security-options "{\"Enabled\": true, \"InternalUserDatabaseEnabled\": true, \
\"MasterUserOptions\": {\"MasterUserName\": \"KibanaUser\", \
\"MasterUserPassword\": \"NewKibanaPassword@123\"}}" \
--vpc-options "{\"SubnetIds\": [\"<subnet-id>\"], \"SecurityGroupIds\": [\"<sg-id>\"]}" \
--access-policies "{\"Version\": \"2012-10-17\", \"Statement\": [ { \"Effect\": \"Allow\", \
\"Principal\": {\"AWS\": \"*\" }, \"Action\":\"es:*\", \
\"Resource\": \"arn:aws:es:<region>:<account-id>:domain\/vpc-cli-example\/*\" } ] }"
도메인은 테스트용이므로 인스턴스 수는 1로 설정되어 있습니다. 도메인을 생성한 후에는 세부 정보를 변경할 수 없으므로 advanced-security-options 파라미터를 사용하여 세밀한 액세스 제어를 활성화해야 합니다. 이 명령은 Kibana 콘솔에 로그인하는 데 사용할 수 있는 마스터 사용자 이름(KibanaUser)과 암호를 생성합니다. 도메인은 가상 사설 클라우드 (VPC) 의 일부이므로 사용할 액세스 정책을 지정하여 Elasticsearch 인스턴스에 연결할 수 있는지 확인해야 합니다. 자세한 내용은 AWS 설명서의 VPC 내에서 Amazon OpenSearch Service 도메인 시작을 참조하세요. | 클라우드 아키텍트, 클라우드 관리자 |
Bastion Host 설정합니다. | Amazon Elastic Compute Cloud (Amazon EC2) Windows 인스턴스를 Kibana 콘솔에 액세스할 수 있는 접속 bastion host 로 설정합니다. Elasticsearch 보안 그룹은 Amazon EC2 보안 그룹으로부터의 트래픽을 허용해야 합니다. 지침은 Bastion Server를 사용하여 EC2 인스턴스에 대한 네트워크 액세스 제어 블로그 게시물을 참조하십시오. 접속 호스트가 설정되고 인스턴스와 연결된 보안 그룹을 사용할 수 있는 경우 AWS CLI authorize-security-group-ingress 명령을 사용하여 Amazon EC2(배스천 호스트) 보안 그룹의 포트 443을 허용하는 권한을 Elasticsearch 보안 그룹에 추가합니다. aws ec2 authorize-security-group-ingress \
--group-id <SecurityGroupIdfElasticSearch> \
--protocol tcp \
--port 443 \
--source-group <SecurityGroupIdfBashionHostEC2>
| 클라우드 아키텍트, 클라우드 관리자 |
| 작업 | 설명 | 필요한 기술 |
|---|
Lambda 실행 역할을 만듭니다. | AWS CLI create-role 명령을 실행하여 Lambda 인덱스 함수에 AWS 서비스 및 리소스에 대한 액세스 권한을 부여합니다. aws iam create-role \
--role-name index-lambda-role \
--assume-role-policy-document file://lambda_assume_role.json
여기서 lambda_assume_role.json는 다음과 같이 Lambda 함수에 AssumeRole 권한을 부여하는 JSON 문서입니다. {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
| 클라우드 아키텍트, 클라우드 관리자 |
Lambda 역할에 관리되는 정책을 첨부합니다. | AWS CLI attach-role-policy 명령을 실행하여 이전 단계에서 생성한 역할에 관리형 정책을 연결합니다. 이 두 정책은 역할에 엘라스틱 네트워크 인터페이스를 생성하고 CloudWatch Logs에 로그를 쓸 수 있는 권한을 부여합니다. aws iam attach-role-policy \
--role-name index-lambda-role \
--policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
aws iam attach-role-policy \
--role-name index-lambda-role \
--policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaVPCAccessExecutionRole
| 클라우드 아키텍트, 클라우드 관리자 |
Lambda 인덱스 함수에 S3 객체를 읽을 수 있는 권한을 부여하는 정책을 생성합니다. | 로 AWS CLI create-policy 명령을 실행하여 Lambda 인덱스 함수에 S3 버킷의 객체를 읽을 수 있는 s3:GetObject 권한을 부여합니다. aws iam create-policy \
--policy-name s3-permission-policy \
--policy-document file://s3-policy.json
파일은 아래에 표시된 JSON 문서s3-policy.json로, S3 객체에 대한 읽기 액세스를 허용하는 s3:GetObject 권한을 부여합니다. S3 버킷을 생성할 때 다른 이름을 사용한 경우 Resource 섹션에 올바른 버킷 이름을 입력합니다. {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::<tenantrawdata>/*"
}
]
}
| 클라우드 아키텍트, 클라우드 관리자 |
Amazon S3 권한 정책을 Lambda 실행 역할에 연결합니다. | AWS CLI attach-role-policy 명령을 실행하여 이전 단계에서 생성한 Amazon S3 권한 정책을 Lambda 실행 역할에 연결합니다. aws iam attach-role-policy \
--role-name index-lambda-role \
--policy-arn <PolicyARN>
PolicyARN은(는) Amazon S3 권한 정책의 Amazon 리소스 이름(ARN)입니다. 이 값은 이전 명령의 출력에서 가져올 수 있습니다.
| 클라우드 아키텍트, 클라우드 관리자 |
Lambda 인덱스 함수를 생성합니다. | AWS CLI create-function 명령을 실행하여 OpenSearch Service에 액세스할 Lambda 인덱스 함수를 생성합니다. aws lambda create-function \
--function-name index-lambda-function \
--zip-file fileb://index_lambda_package.zip \
--handler lambda_index.lambda_handler \
--runtime python3.9 \
--role "arn:aws:iam::account-id:role/index-lambda-role" \
--timeout 30 \
--vpc-config "{\"SubnetIds\": [\"<subnet-id1\>", \"<subnet-id2>\"], \
\"SecurityGroupIds\": [\"<sg-1>\"]}"
| 클라우드 아키텍트, 클라우드 관리자 |
Amazon S3가 Lambda 인덱스 함수를 호출하도록 허용합니다. | AWS CLI add-permission 명령을 실행하여 Amazon S3에 Lambda 인덱스 함수를 호출할 수 있는 권한을 부여합니다. aws lambda add-permission \
--function-name index-lambda-function \
--statement-id s3-permissions \
--action lambda:InvokeFunction \
--principal s3.amazonaws.com \
--source-arn "arn:aws:s3:::<tenantrawdata>" \
--source-account "<account-id>"
| 클라우드 아키텍트, 클라우드 관리자 |
Amazon S3 이벤트에 Lambda 트리거를 추가합니다. | Amazon S3 ObjectCreated 이벤트가 감지되면 the AWS CLI put-bucket-notification-configuration 명령을 실행하여 Lambda 인덱스 함수에 알림을 보냅니다. 인덱스 함수는 객체가 S3 버킷에 업로드될 때마다 실행됩니다. aws s3api put-bucket-notification-configuration \
--bucket <tenantrawdata> \
--notification-configuration file://s3-trigger.json
파일 s3-trigger.json은(는) Amazon S3 ObjectCreated 이벤트가 발생할 때 Lambda 함수에 리소스 정책을 추가하는 현재 폴더의 JSON 문서입니다. | 클라우드 아키텍트, 클라우드 관리자 |
| 작업 | 설명 | 필요한 기술 |
|---|
Lambda 실행 역할을 만듭니다. | AWS CLI create-role 명령을 실행하여 Lambda 검색 함수에 AWS 서비스 및 리소스에 대한 액세스 권한을 부여합니다. aws iam create-role \
--role-name search-lambda-role \
--assume-role-policy-document file://lambda_assume_role.json
lambda_assume_role.json은(는) 다음과 같이 Lambda 함수에 AssumeRole 권한을 부여하는 현재 폴더의 JSON 문서입니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
| 클라우드 아키텍트, 클라우드 관리자 |
Lambda 역할에 관리되는 정책을 첨부합니다. | AWS CLI attach-role-policy 명령을 실행하여 이전 단계에서 생성한 역할에 관리형 정책을 연결합니다. 이 두 정책은 역할에 엘라스틱 네트워크 인터페이스를 생성하고 CloudWatch Logs에 로그를 쓸 수 있는 권한을 부여합니다. aws iam attach-role-policy \
--role-name search-lambda-role \
--policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
aws iam attach-role-policy \
--role-name search-lambda-role \
--policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaVPCAccessExecutionRole
| 클라우드 아키텍트, 클라우드 관리자 |
Lambda 함수를 생성합니다. | AWS CLI create-function 명령을 실행하여 OpenSearch Service에 액세스할 Lambda 검색 함수를 생성합니다. aws lambda create-function \
--function-name search-lambda-function \
--zip-file fileb://search_lambda_package.zip \
--handler lambda_search.lambda_handler \
--runtime python3.9 \
--role "arn:aws:iam::account-id:role/search-lambda-role" \
--timeout 30 \
--vpc-config "{\"SubnetIds\": [\"<subnet-id1\>", \"<subnet-id2>\"], \
\"SecurityGroupIds\": [\"<sg-1>\"]}"
| 클라우드 아키텍트, 클라우드 관리자 |
| 작업 | 설명 | 필요한 기술 |
|---|
테넌트 IAM 역할을 생성합니다. | AWS CLI create-role 명령을 실행하여 검색 기능을 테스트하는 데 사용할 두 개의 테넌트 역할을 생성합니다. aws iam create-role \
--role-name Tenant-1-role \
--assume-role-policy-document file://assume-role-policy.json
aws iam create-role \
--role-name Tenant-2-role \
--assume-role-policy-document file://assume-role-policy.json
파일 assume-role-policy.json은(는) Lambda 실행 역할에 AssumeRole 권한을 부여하는 현재 폴더의 JSON 문서입니다. {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "<Lambda execution role for index function>",
"AWS": "<Lambda execution role for search function>"
},
"Action": "sts:AssumeRole"
}
]
}
| 클라우드 아키텍트, 클라우드 관리자 |
테넌트 IAM 정책을 생성합니다. | AWS CLI create-policy 명령을 실행하여 Elasticsearch 작업에 대한 액세스 권한을 부여하는 테넌트 정책을 생성합니다. aws iam create-policy \
--policy-name tenant-policy \
--policy-document file://policy.json
파일 policy.json은(는) Elasticsearch에서 권한을 부여하는 현재 폴더의 JSON 문서입니다. {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"es:ESHttpDelete",
"es:ESHttpGet",
"es:ESHttpHead",
"es:ESHttpPost",
"es:ESHttpPut",
"es:ESHttpPatch"
],
"Resource": [
"<ARN of Elasticsearch domain created earlier>"
]
}
]
}
| 클라우드 아키텍트, 클라우드 관리자 |
테넌트 IAM 정책을 테넌트 역할에 연결합니다. | AWS CLI attach-role-policy 명령을 실행하여 이전 단계에서 생성한 두 테넌트 역할에 테넌트 IAM 정책을 연결합니다. aws iam attach-role-policy \
--policy-arn arn:aws:iam::account-id:policy/tenant-policy \
--role-name Tenant-1-role
aws iam attach-role-policy \
--policy-arn arn:aws:iam::account-id:policy/tenant-policy \
--role-name Tenant-2-role
정책 ARN은 이전 단계의 출력에서 가져온 것입니다. | 클라우드 아키텍트, 클라우드 관리자 |
Lambda에 역할을 수임할 권한을 부여하는 IAM 정책을 생성합니다. | AWS CLI create-policy 명령을 실행하여 Lambda가 테넌트 역할을 수임하도록 정책을 생성합니다. aws iam create-policy \
--policy-name assume-tenant-role-policy \
--policy-document file://lambda_policy.json
파일 lambda_policy.json은(는) AssumeRole에 권한을 부여하는 현재 폴더의 JSON 문서입니다. {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "<ARN of tenant role created earlier>"
}
]
}
Resource의 경우, 와일드카드 문자를 사용하여 각 테넌트에 대해 새 정책을 만들지 않아도 됩니다.
| 클라우드 아키텍트, 클라우드 관리자 |
Amazon S3에 액세스할 수 있는 권한을 Lambda 인덱스 역할에 부여하는 IAM 정책을 생성합니다. | AWS CLI create-policy 명령을 실행하여 Lambda 인덱스 역할에 S3 버킷의 객체에 액세스할 수 있는 권한을 부여합니다. aws iam create-policy \
--policy-name s3-permission-policy \
--policy-document file://s3_lambda_policy.json
파일 s3_lambda_policy.json은(는) 현재 폴더의 다음 JSON 정책 문서입니다. {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::tenantrawdata/*"
}
]
}
| 클라우드 아키텍트, 클라우드 관리자 |
정책을 Lambda 실행 역할에 첨부합니다. | AWS CLI attach-role-policy 명령을 실행하여 이전 단계에서 생성한 정책을 이전에 생성한 Lambda 인덱스 및 검색 실행 역할에 연결합니다. aws iam attach-role-policy \
--policy-arn arn:aws:iam::account-id:policy/assume-tenant-role-policy \
--role-name index-lambda-role
aws iam attach-role-policy \
--policy-arn arn:aws:iam::account-id:policy/assume-tenant-role-policy \
--role-name search-lambda-role
aws iam attach-role-policy \
--policy-arn arn:aws:iam::account-id:policy/s3-permission-policy \
--role-name index-lambda-role
정책 ARN은 이전 단계의 출력에서 가져온 것입니다. | 클라우드 아키텍트, 클라우드 관리자 |
| 작업 | 설명 | 필요한 기술 |
|---|
API 게이트웨이에서 REST API를 만듭니다. | AWS CLI create-rest-api 명령을 실행하여 REST API 리소스를 생성합니다. aws apigateway create-rest-api \
--name Test-Api \
--endpoint-configuration "{ \"types\": [\"REGIONAL\"] }"
엔드포인트 구성 유형의 경우 EDGE 특정 대신 엣지 로케이션REGIONAL을 사용하도록 대신를 지정할 수 있습니다 AWS 리전. 명령 출력에서 id 필드 값을 적어 둡니다. 이는 후속 명령에서 사용할 API ID입니다. | 클라우드 아키텍트, 클라우드 관리자 |
검색 API용 리소스를 만드세요. | 검색 API 리소스는 리소스 이름 search을(를) 사용하여 Lambda 검색 함수를 시작합니다. (객체가 S3 버킷에 업로드될 때 자동으로 실행되므로 Lambda 인덱스 함수용 API를 생성할 필요가 없습니다.) the AWS CLI get-resources 명령을 실행하여 루트 경로의 상위 ID를 가져옵니다. aws apigateway get-resources \
--rest-api-id <API-ID>
ID 필드의 값을 기록합니다. 다음 명령에서 이 부모 ID를 사용합니다. {
"items": [
{
"id": "zpsri964ck",
"path": "/"
}
]
}
AWS CLI create-resource 명령을 실행하여 검색 API에 대한 리소스를 생성합니다. parent-id의 경우, 이전 명령에서 확인한 ID를 지정합니다. aws apigateway create-resource \
--rest-api-id <API-ID> \
--parent-id <Parent-ID> \
--path-part search
| 클라우드 아키텍트, 클라우드 관리자 |
검색 API용 GET 메서드를 만드세요. | the AWS CLI put-method 명령을 실행하여 검색 API에 대한 GET 메서드를 생성합니다. aws apigateway put-method \
--rest-api-id <API-ID> \
--resource-id <ID from the previous command output> \
--http-method GET \
--authorization-type "NONE" \
--no-api-key-required
resource-id의 경우, create-resource 명령 출력에서 ID를 지정합니다.
| 클라우드 아키텍트, 클라우드 관리자 |
검색 API에 대한 메서드 응답을 생성합니다. | the AWS CLI put-method-response 명령을 실행하여 검색 API에 대한 메서드 응답을 추가합니다. aws apigateway put-method-response \
--rest-api-id <API-ID> \
--resource-id <ID from the create-resource command output> \
--http-method GET \
--status-code 200 \
--response-models "{\"application/json\": \"Empty\"}"
에서 이전 create-resource 명령의 출력에서 ID를 resource-id지정합니다. | 클라우드 아키텍트, 클라우드 관리자 |
검색 API에 대한 프록시 Lambda 통합을 설정합니다. | AWS CLI put-integration 명령을 실행하여 Lambda 검색 함수와의 통합을 설정합니다. aws apigateway put-integration \
--rest-api-id <API-ID> \
--resource-id <ID from the create-resource command output> \
--http-method GET \
--type AWS_PROXY \
--integration-http-method GET \
--uri arn:aws:apigateway:region:lambda:path/2015-03-31/functions/arn:aws:lambda:<region>:<account-id>:function:<function-name>/invocations
resource-id의 경우, 이전 명령의 출력에서 ID를 지정합니다. create-resource
| 클라우드 아키텍트, 클라우드 관리자 |
Lambda 검색 기능을 호출할 수 있는 API 게이트웨이 권한을 부여합니다. | AWS CLI add-permission 명령을 실행하여 API Gateway에 검색 함수를 사용할 수 있는 권한을 부여합니다. aws lambda add-permission \
--function-name <function-name> \
--statement-id apigateway-get \
--action lambda:InvokeFunction \
--principal apigateway.amazonaws.com \
--source-arn "arn:aws:execute-api:<region>:<account-id>:api-id/*/GET/search
대신 다른 API 리소스 이름을 사용한 경우 source-arn 경로를 변경하십시오. search | 클라우드 아키텍트, 클라우드 관리자 |
검색 API를 배포하세요. | AWS CLI create-deployment 명령을 실행하여 라는 스테이지 리소스를 생성합니다dev. aws apigateway create-deployment \
--rest-api-id <API-ID> \
--stage-name dev
API를 업데이트하는 경우 동일한 AWS CLI 명령을 사용하여 동일한 단계에 다시 배포할 수 있습니다. | 클라우드 아키텍트, 클라우드 관리자 |
| 작업 | 설명 | 필요한 기술 |
|---|
Kibana 콘솔에 로그인합니다. | OpenSearch Service 콘솔의 도메인 대시보드에서 Kibana에 대한 링크를 찾습니다. URL 형식은 다음과 같습니다<domain-endpoint>/_plugin/kibana/. 첫 번째 에픽에서 구성한 bastion host 를 사용하여 Kibana 콘솔에 액세스하세요. OpenSearch Service 도메인을 생성할 때 이전 단계의 마스터 사용자 이름과 암호를 사용하여 Kibana 콘솔에 로그인합니다. 테넌트를 선택하라는 메시지가 표시되면 [Private] 를 선택합니다.
| 클라우드 아키텍트, 클라우드 관리자 |
Kibana 역할을 만들고 구성하세요. | 데이터 격리를 제공하고 한 테넌트가 다른 테넌트의 데이터를 검색할 수 없도록 하려면 테넌트가 테넌트 ID가 포함된 문서에만 액세스할 수 있도록 하는 문서 보안을 사용해야 합니다. Kibana 콘솔의 탐색 창에서 보안, 역할을 선택합니다. 새 테넌트 역할을 생성합니다. 클러스터 권한을 로 설정indices_all하여 OpenSearch Service 인덱스에 대한 생성, 읽기, 업데이트 및 삭제(CRUD) 권한을 부여합니다. 인덱스 권한을 인덱스로 제한하십시오. tenant-data (인덱스 이름은 Lambda 검색 및 인덱스 함수의 이름과 일치해야 합니다.) 인덱스 권한을 로 설정하여 indices_all 사용자가 모든 인덱스 관련 작업을 수행할 수 있도록 하십시오. (요구 사항에 따라 보다 세분화된 액세스를 위해 작업을 제한할 수 있습니다.) 문서 수준 보안을 위해 다음 정책을 사용하여 테넌트 ID별로 문서를 필터링하여 공유 인덱스의 테넌트에 데이터를 격리하십시오. {
"bool": {
"must": {
"match": {
"TenantId": "Tenant-1"
}
}
}
}
색인 이름, 속성 및 값은 대/소문자를 구분합니다.
| 클라우드 아키텍트, 클라우드 관리자 |
사용자를 역할에 매핑합니다. | 역할에 대해 [매핑된 사용자] 탭을 선택한 다음 [사용자 매핑] 을 선택합니다. 백엔드 역할 섹션에서 이전에 생성한 IAM 테넌트 역할의 ARN을 지정한 다음 Map을 선택합니다. 이렇게 하면 IAM 테넌트 역할이 Kibana 역할에 매핑되므로 테넌트별 검색에서 해당 테넌트에 대한 데이터만 반환됩니다. 예를 들어 테넌트-1의 IAM 역할 이름이 Tenant-1-Role인 경우, 테넌트-1 Kibana 역할의 백엔드 역할 상자에서 Tenant-1-Role(테넌트 역할 생성 및 구성 에픽에서)의 ARN을 지정합니다. 테넌트-2에 대해 1단계와 2단계를 반복합니다.
테넌트 온보딩 시 테넌트 및 Kibana 역할 생성을 자동화하는 것이 좋습니다. | 클라우드 아키텍트, 클라우드 관리자 |
테넌트 데이터 인덱스를 생성합니다. | 탐색 창의 관리에서 Dev Tools를 선택하고 다음 명령을 실행합니다. 이 명령은 TenantId 속성에 대한 매핑을 정의하는 tenant-data 색인을 만듭니다. PUT /tenant-data
{
"mappings": {
"properties": {
"TenantId": { "type": "keyword"}
}
}
}
| 클라우드 아키텍트, 클라우드 관리자 |
| 작업 | 설명 | 필요한 기술 |
|---|
Amazon S3용 VPC 엔드포인트를 만듭니다. | AWS CLI create-vpc-endpoint 명령을 실행하여 Amazon S3에 대한 VPC 엔드포인트를 생성합니다. 엔드포인트를 사용하면 VPC의 Lambda 인덱스 함수가 Amazon S3에 액세스할 수 있습니다. aws ec2 create-vpc-endpoint \
--vpc-id <VPC-ID> \
--service-name com.amazonaws.us-east-1.s3 \
--route-table-ids <route-table-ID>
의 경우vpc-id, Lambda 인덱스 함수에 사용할 VPC를 지정하십시오. 의 service-name 경우 Amazon S3 엔드포인트에 올바른 URL을 사용하십시오. 의 경우route-table-ids, VPC 엔드포인트와 연결된 라우팅 테이블을 지정합니다. | 클라우드 아키텍트, 클라우드 관리자 |
에 대한 VPC 엔드포인트를 생성합니다 AWS STS. | AWS CLI create-vpc-endpoint 명령을 실행하여 AWS Security Token Service ()에 대한 VPC 엔드포인트를 생성합니다AWS STS. 엔드포인트를 사용하면 VPC의 Lambda 인덱스 및 검색 함수에 액세스할 수 있습니다 AWS STS. 함수는 IAM 역할을 수임할 AWS STS 때를 사용합니다. aws ec2 create-vpc-endpoint \
--vpc-id <VPC-ID> \
--vpc-endpoint-type Interface \
--service-name com.amazonaws.us-east-1.sts \
--subnet-id <subnet-ID> \
--security-group-id <security-group-ID>
의 경우vpc-id, Lambda 인덱스 및 검색 함수에 사용할 VPC를 지정하십시오. 의 경우subnet-id, 이 엔드포인트를 생성해야 하는 서브넷을 제공하십시오. 의 경우security-group-id, 이 엔드포인트를 연결할 보안 그룹을 지정하십시오. (Lambda가 사용하는 보안 그룹과 같을 수 있습니다.) | 클라우드 아키텍트, 클라우드 관리자 |
| 작업 | 설명 | 필요한 기술 |
|---|
색인 및 검색 함수에 대한 Python 파일을 업데이트하십시오. | index_lambda_package.zip 파일에서 파일을 편집 lamba_index.py하여 AWS 계정 ID AWS 리전및 Elasticsearch 엔드포인트 정보를 업데이트합니다.
search_lambda_package.zip 파일에서 lambda_search.py 파일을 편집하여 AWS 계정 ID AWS 리전및 Elasticsearch 엔드포인트 정보를 업데이트합니다.
OpenSearch Service 콘솔의 개요 탭에서 Elasticsearch 엔드포인트를 가져올 수 있습니다. OpenSearch 이 리전은 <AWS-Region>.es.amazonaws.com의 형태로 되어 있습니다. | 클라우드 아키텍트, 앱 개발자 |
Lambda 코드를 업데이트합니다. | the AWS CLI update-function-code 명령을 사용하여 Python 파일에 대한 변경 사항으로 Lambda 코드를 업데이트합니다. aws lambda update-function-code \
--function-name index-lambda-function \
--zip-file fileb://index_lambda_package.zip
aws lambda update-function-code \
--function-name search-lambda-function \
--zip-file fileb://search_lambda_package.zip
| 클라우드 아키텍트, 앱 개발자 |
S3 버킷에 원시 데이터를 업로드합니다. | AWS CLI cp 명령을 사용하여 Tenant-1 및 Tenant-2 객체에 대한 데이터를 tenantrawdata 버킷에 업로드합니다(이를 위해 생성한 S3 버킷의 이름 지정). aws s3 cp tenant-1-data s3://tenantrawdata
aws s3 cp tenant-2-data s3://tenantrawdata
S3 버킷은 데이터가 업로드될 때마다 Lambda 인덱스 함수를 실행하도록 설정되어 있어 문서가 Elasticsearch에서 인덱싱됩니다. | 클라우드 아키텍트, 클라우드 관리자 |
Kibana 콘솔에서 데이터를 검색하세요. | Kibana 콘솔에서 다음 쿼리를 실행합니다. GET tenant-data/_search
이 쿼리는 Elasticsearch에서 인덱싱된 모든 문서를 표시합니다. 이 경우 Tenant-1Tenant-2개가 표시되어야 합니다. | 클라우드 아키텍트, 클라우드 관리자 |
API Gateway에서 검색 API를 테스트합니다. | API Gateway 콘솔에서 검색 API를 열고 검색 리소스 내에서 GET 메서드를 선택한 다음 Test를 선택합니다. 테스트 창에서 테넌트 ID에 대한 다음 쿼리 문자열 (대소문자 구분) 을 제공한 다음 [Test] 를 선택합니다. TenantId=Tenant-1
Lambda 함수는 문서 수준 보안을 기반으로 테넌트 문서를 필터링하는 쿼리를 OpenSearch Service로 보냅니다. 메서드는 테넌트-1에 속하는 문서를 반환합니다. 쿼리 문자열을 다음과 같이 변경합니다. TenantId=Tenant-2
이 쿼리는 Tenant-2에 속하는 문서를 반환합니다.
화면 그림은 추가 정보 섹션을 참조하십시오. | 클라우드 아키텍트, 앱 개발자 |
리소스를 정리합니다. | 계정에 추가 요금이 부과되지 않도록 생성한 모든 리소스를 정리합니다. | AWS DevOps, 클라우드 아키텍트, 클라우드 관리자 |
관련 리소스
추가 정보
데이터 파티셔닝 모델
멀티테넌트 시스템에서 사용되는 일반적인 데이터 파티셔닝 모델은 사일로, 풀, 하이브리드의 세 가지입니다. 선택하는 모델은 환경의 규정 준수, 잡음이 많은 이웃, 운영 및 격리 요구 사항에 따라 달라집니다.
사일로 모델
사일로 모델에서 각 테넌트의 데이터는 테넌트 데이터가 섞이지 않는 별개의 스토리지 영역에 저장됩니다. 두 가지 접근 방식을 사용하여 OpenSearch Service로 사일로 모델을 구현할 수 있습니다. 하나는 테넌트당 도메인이고 다른 하나는 테넌트당 인덱스입니다.
사일로 모델에서의 격리 - 사일로 모델에서는 IAM 정책을 사용하여 각 테넌트의 데이터를 보관하는 도메인이나 인덱스를 분리합니다. 이러한 정책은 한 테넌트가 다른 테넌트의 데이터에 액세스하는 것을 방지합니다. 사일로 격리 모델을 구현하기 위해 테넌트 리소스에 대한 액세스를 제어하는 리소스 기반 정책을 만들 수 있습니다. 이는 주로 주체가 Elasticsearch 인덱스 및 API를 비롯한 도메인의 하위 리소스에서 수행할 수 있는 작업을 지정하는 도메인 액세스 정책입니다. IAM 자격 증명 기반 정책을 사용하면 OpenSearch Service 내에서 도메인, 인덱스 또는 APIs에 대해 허용되거나 거부된 작업을 지정할 수 있습니다. IAM 정책의 Action 요소는 정책에 따라 허용되거나 거부되는 특정 작업에 대해 설명하며 Principal 요소는 영향을 받는 계정, 사용자 또는 역할을 지정합니다.
다음 샘플 정책은 Tenant-1에 도메인의 하위 리소스에만 전체 액세스 권한 (에서 지정한 대로es:*) 을 부여합니다. tenant-1 Resource 요소의 뒤에 오는 /*는 이 정책이 도메인 자체에 적용되는 것이 아니라 도메인의 하위 리소스에 적용됨을 나타냅니다. 이 정책이 시행되면 테넌트는 새 도메인을 만들거나 기존 도메인의 설정을 수정할 수 없습니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<aws-account-id>:user/Tenant-1"
},
"Action": "es:*",
"Resource": "arn:aws:es:<Region>:<account-id>:domain/tenant-1/*"
}
]
}
인덱스 사일로 모델당 테넌트를 구현하려면 인덱스 이름을 지정하여 Tenant-1을 지정된 인덱스로 추가로 제한하도록이 샘플 정책을 수정해야 합니다. 다음 샘플 정책은 Tenant-1을 인덱스로 제한합니다. tenant-index-1
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:user/Tenant-1"
},
"Action": "es:*",
"Resource": "arn:aws:es:<Region>:<account-id>:domain/test-domain/tenant-index-1/*"
}
]
}
풀 모델
풀 모델에서는 모든 테넌트 데이터가 동일한 도메인 내의 인덱스에 저장됩니다. 테넌트 식별자는 데이터 (문서) 에 포함되어 파티션 키로 사용되므로 어떤 데이터가 어떤 테넌트에 속하는지 확인할 수 있습니다. 이 모델은 관리 오버헤드를 줄여줍니다. 풀링된 인덱스를 운영하고 관리하는 것이 여러 인덱스를 관리하는 것보다 쉽고 효율적입니다. 그러나 테넌트 데이터가 동일한 인덱스 내에서 혼합되므로 사일로 모델이 제공하는 자연스러운 테넌트 격리가 손실됩니다. 이 접근 방식은 노이즈 인접 효과 때문에 성능을 저하시킬 수도 있습니다.
풀 모델에서의 테넌트 격리 - 일반적으로 테넌트 격리는 풀 모델에서 구현하기가 어렵습니다. 사일로 모델에 사용되는 IAM 메커니즘으로는 문서에 저장된 테넌트 ID를 기반으로 격리를 설명할 수 없습니다.
또 다른 접근 방식은 Elasticsearch용 오픈 배포판에서 제공하는 세분화된 액세스 제어 (FGAC) 지원을 사용하는 것입니다. FGAC를 사용하면 색인, 문서 또는 필드 수준에서 권한을 제어할 수 있습니다. FGAC는 요청이 있을 때마다 사용자 자격 증명을 평가하여 사용자를 인증하거나 액세스를 거부합니다. FGAC가 사용자를 인증하면 해당 사용자에게 매핑된 모든 역할을 가져오고 전체 권한 집합을 사용하여 요청을 처리할 방법을 결정합니다.
풀링 모델에서 필요한 격리를 달성하려면 문서 수준 보안을 사용할 수 있습니다. 문서 수준 보안을 사용하면 역할을 인덱스에 있는 문서의 하위 집합으로 제한할 수 있습니다. 다음 샘플 역할은 쿼리를 Tenant-1로 제한합니다. 이 역할을 테넌트-1에 적용하면 필요한 격리를 달성할 수 있습니다.
{
"bool": {
"must": {
"match": {
"tenantId": "Tenant-1"
}
}
}
}
하이브리드 모델
하이브리드 모델은 동일한 환경에서 사일로 및 풀 모델을 조합하여 각 테넌트 계층 (예: 무료, 표준 및 프리미엄 계층) 에 고유한 경험을 제공합니다. 각 계층은 풀 모델에서 사용된 것과 동일한 보안 프로필을 따릅니다.
하이브리드 모델의 테넌트 격리 - 하이브리드 모델에서는 풀 모델과 동일한 보안 프로필을 따르며, 문서 수준에서 FGAC 보안 모델을 사용하면 테넌트 격리가 제공됩니다. 이 전략은 클러스터 관리를 단순화하고 민첩성을 제공하지만 아키텍처의 다른 측면을 복잡하게 만듭니다. 예를 들어, 각 테넌트와 관련된 모델을 결정하려면 코드가 더 복잡해야 합니다. 또한 단일 테넌트 쿼리가 전체 도메인을 포화시켜 다른 테넌트의 경험을 저하시키지 않도록 해야 합니다.
API Gateway에서의 테스트
테넌트-1 쿼리의 테스트 창
테넌트-2 쿼리의 테스트 창
첨부
이 문서와 관련된 추가 콘텐츠에 액세스하려면 attachment.zip 파일의 압축을 풉니다.