기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon Redshift 기계 학습을 이용하여 고급 분석 수행
Po Hong과 Chyanna Antonio, Amazon Web Services
요약
Amazon Web Services(AWS) 클라우드에서는 Amazon Redshift 기계 학습(Amazon Redshift ML)을 사용하여 Amazon Redshift 클러스터 또는 Amazon Simple Storage Service(S3)에서 저장된 데이터에 대한 기계 학습 분석을 수행할 수 있습니다. Amazon Redshift 기계 학습은 일반적으로 고급 분석에 사용되는 지도 학습을 지원합니다. Amazon Redshift ML 사용 사례에는 수익 예측, 신용 카드 사기 탐지, 고객 평생 가치(CLV) 또는 고객 이탈 예측 등이 포함됩니다.
Amazon Redshift 기계 학습을 사용하면 데이터베이스 사용자가 표준 SQL 명령으로 기계 학습 모델을 쉽게 생성, 훈련 및 배포할 수 있습니다. Amazon Redshift ML은 Amazon SageMaker Autopilot을 사용하여 제어력과 가시성을 유지하면서 데이터를 기반으로 분류 또는 회귀에 가장 적합한 기계 학습 모델을 자동으로 훈련 및 조정합니다.
Amazon Redshift, Amazon S3 및 Amazon SageMaker 간의 모든 상호 작용은 추상화되어 자동화됩니다. ML 모델은 훈련 및 배포가 완료되면 Amazon Redshift에서 사용자 정의 함수(UDF)로 사용할 수 있게 되며, SQL 쿼리에 사용할 수 있습니다.
이 패턴은 AWS 블로그의 Amazon Redshift ML과 SQL을 사용하여 Amazon Redshift에서 ML 모델을 생성, 훈련 및 배포
사전 조건 및 제한 사항
사전 조건
활성 상태의 AWS 계정
Amazon Redshift 테이블의 기존 데이터
기술
기계 학습, 훈련 및 예측을 포함한 Amazon Redshift ML에서 사용하는 용어 및 개념을 숙지해야 합니다. 이에 관한 자세한 내용은 Amazon Machine Learning(Amazon ML) 설명서의 ML 모델 훈련을 참조하세요.
Amazon Redshift 사용자 설정, 액세스 관리 및 표준 SQL 구문에 대한 경험이 있어야 합니다. 이에 관한 자세한 내용은 Amazon Redshift 설명서의 Amazon Redshift 시작하기를 참조하세요.
Amazon S3 및 AWS Identity and Access Management(IAM)에 관한 지식과 경험이 있어야 합니다.
AWS Command Line Interface(AWS CLI)에서 명령을 실행한 경험이 있으면 유용하지만 필수 사항은 아닙니다.
제한 사항
Amazon Redshift 클러스터와 S3 버킷이 동일한 AWS 리전에 있어야 합니다.
이 패턴의 접근 방식은 회귀, 바이너리 분류 및 멀티클래스 분류와 같은 지도 학습 모델만 지원합니다.
아키텍처
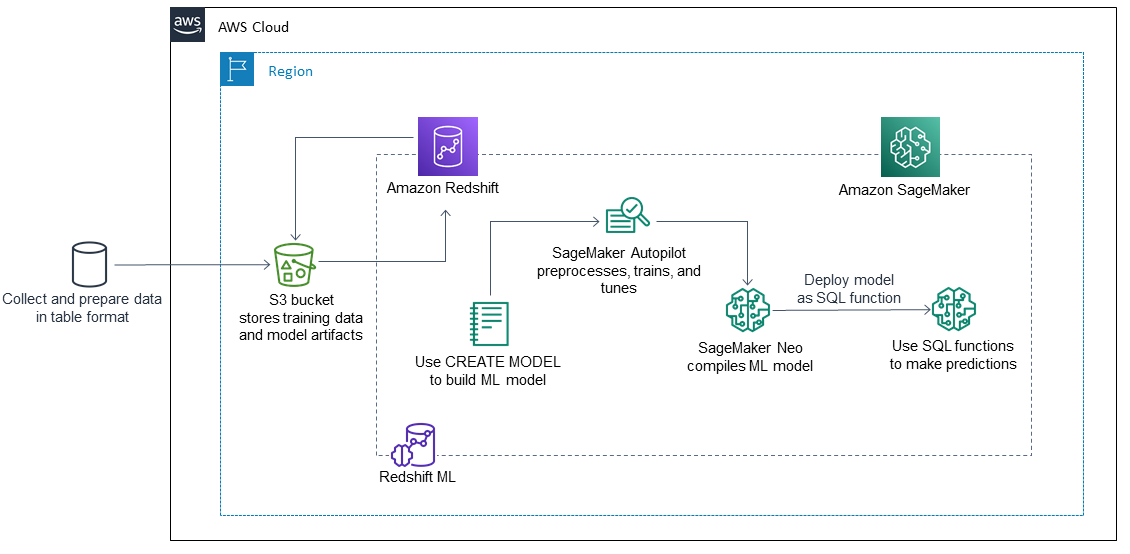
다음 단계에서는 Amazon Redshift ML이 SageMaker와 연동하여 ML 모델을 구축, 훈련 및 배포하는 방법을 설명합니다.
Amazon Redshift는 훈련 데이터를 S3 버킷으로 내보냅니다.
SageMaker Autopilot은 훈련 데이터를 자동으로 사전 처리합니다.
CREATE MODEL명령문이 호출된 후 Amazon Redshift ML은 SageMaker를 훈련에 사용합니다.SageMaker Autopilot은 평가 지표를 최적화하는 ML 알고리즘과 최적의 하이퍼파라미터를 검색하고 추천합니다.
Amazon Redshift ML은 출력 ML 모델을 Amazon Redshift 클러스터에 SQL 함수로 등록합니다.
기계 학습 모델의 함수는 SQL 문에서 사용할 수 있습니다.
기술 스택
Amazon Redshift
SageMaker
Amazon S3
도구
Amazon Redshift – Amazon Redshift는 페타바이트 규모의 엔터프라이즈 레벨 완전 관리형 데이터 웨어하우징 서비스입니다.
Amazon Redshift ML – Amazon Redshift 기계 학습(Amazon Redshift ML)은 모든 기술 수준의 분석가와 데이터 사이언티스트가 ML 기술을 쉽게 사용할 수 있도록 하는 강력한 클라우드 기반 서비스입니다.
Amazon S3 – Amazon Simple Storage Service(S3)는 인터넷에 대한 스토리지입니다.
Amazon SageMaker - Amazon SageMaker는 완전 관리형 ML 서비스입니다.
Amazon SageMaker Autopilot - SageMaker Autopilot은 자동 기계 학습(AutoML) 프로세스의 주요 작업을 자동화하는 기능 집합입니다.
코드
다음 코드를 사용하여 Amazon Redshift에서 지도 ML 모델을 생성할 수 있습니다.
"CREATE MODEL customer_churn_auto_model FROM (SELECT state, account_length, area_code, total_charge/account_length AS average_daily_spend, cust_serv_calls/account_length AS average_daily_cases, churn FROM customer_activity WHERE record_date < '2020-01-01' ) TARGET churn FUNCTION ml_fn_customer_churn_auto IAM_ROLE 'arn:aws:iam::XXXXXXXXXXXX:role/Redshift-ML' SETTINGS ( S3_BUCKET 'your-bucket' );")
참고
SELECT 상태는 Amazon Redshift 일반 테이블, Amazon Redshift Spectrum 외부 테이블 또는 둘 다를 참조할 수 있습니다.
에픽
| 작업 | 설명 | 필요한 기술 |
|---|---|---|
훈련 및 테스트 데이터 세트를 준비합니다. | AWS Management Console에 로그인한 다음 Amazon SageMaker 콘솔을 엽니다. 기계 학습 모델 구축, 훈련 및 배포 참고원시 데이터 세트를 모델 훈련을 위한 훈련 세트(70%)와 모델의 성능 평가를 위한 테스트 세트(30%)로 셔플링하고 분할하는 것이 좋습니다. | 데이터 사이언티스트 |
| 작업 | 설명 | 필요한 기술 |
|---|---|---|
Amazon Redshift 클러스터를 생성하고 구성합니다. | Amazon Redshift 콘솔에서 사용자의 요건에 따라 클러스터를 생성합니다. 이에 대한 자세한 내용은 Amazon Redshift 설명서의 클러스터 생성을 참조하세요. 중요Amazon Redshift 클러스터는 | DBA, 클라우드 아키텍트 |
S3 버킷을 생성하여 훈련 데이터와 모델 아티팩트를 저장합니다. | Amazon S3 콘솔에서 훈련 및 테스트 데이터를 위한 S3 버킷을 생성합니다. S3 버킷 생성에 대한 자세한 내용은 AWS Quick Starts의 S3 버킷 생성을 참조하세요. 중요Amazon Redshift 클러스터와 S3 버킷이 동일한 리전에 있는지 확인합니다. | DBA, 클라우드 아키텍트 |
IAM 정책을 생성하여 Amazon Redshift 클러스터에 연결합니다. | Amazon Redshift 클러스터가 SageMaker 및 Amazon S3에 액세스할 수 있도록 허용하는 IAM 정책을 생성합니다. 지침 및 단계는 Amazon Redshift 설명서에서 Amazon Redshift ML을 사용하기 위한 클러스터 설정을 참조하세요. | DBA, 클라우드 아키텍트 |
Amazon Redshift 사용자 및 그룹이 스키마와 테이블에 액세스할 수 있도록 허용합니다. | Amazon Redshift의 사용자 및 그룹이 내부 및 외부 스키마와 테이블에 액세스할 수 있도록 권한을 부여합니다. 단계 및 지침은 Amazon Redshift 설명서의 권한 및 소유권 관리를 참조하세요. | DBA |
| 작업 | 설명 | 필요한 기술 |
|---|---|---|
Amazon Redshift에서 ML 모델을 생성하고 훈련합니다. | Amazon Redshift ML에서 ML 모델을 생성하고 훈련합니다. 자세한 내용은 Amazon Redshift 설명서의 | 개발자, 데이터 사이언티스트 |
| 작업 | 설명 | 필요한 기술 |
|---|---|---|
생성된 ML 모델 함수를 사용하여 추론을 수행합니다. | 생성된 ML 모델 함수를 사용하여 추론을 수행하는 방법에 대한 자세한 내용은 Amazon Redshift 설명서의 예측을 참조하세요. | 데이터 사이언티스트, 비즈니스 인텔리전스 사용자 |
관련 리소스
훈련 및 테스트 데이터 세트 준비
기술 스택 준비 및 구성
Amazon Redshift에서 ML 모델 생성 및 훈련
Amazon Redshift에서 배치 추론 및 예측 수행
기타 리소스
