기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
아키텍처
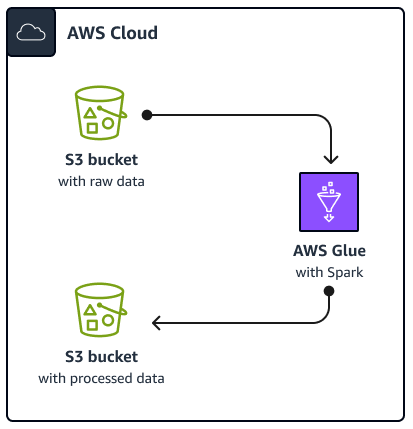
다음 다이어그램은이 가이드에 설명된 솔루션의 아키텍처를 보여줍니다. AWS Glue 작업은 데이터를 저장, 보호 및 검색하는 데 도움이 되는 클라우드 기반 객체 스토리지 서비스인 Amazon Simple Storage Service(Amazon S3) 버킷에서 데이터를 읽습니다. AWS Management Console, AWS Command Line Interface (AWS CLI) 또는 AWS Glue API를 통해 작업을 시작할 AWS Glue Spark SQL 수 있습니다. 작업은 AWS Glue Spark SQL Amazon S3 버킷에서 원시 데이터를 처리한 다음 처리된 데이터를 다른 버킷에 저장합니다.
예를 들어이 가이드에서는 Python 및 Spark SQL ()로 작성된 기본 AWS GlueSpark SQL 작업을 설명합니다PySpark. 이 AWS Glue 작업은 Spark SQL 튜닝 모범 사례를 보여주는 데 사용됩니다. 이 가이드는에 중점을 두지만이 가이드 AWS Glue의 모범 사례는 Amazon EMR Spark SQL 작업에도 적용됩니다.
다음 다이어그램은 Spark SQL 쿼리의 수명 주기를 보여줍니다. Spark SQL Catalyst Optimizer는 쿼리 계획을 생성합니다. 쿼리 계획은 SQL 관계형 데이터베이스 시스템의 데이터에 액세스하는 데 사용되는 지침과 같은 일련의 단계입니다. 성능 최적화 Spark SQL 쿼리 계획을 개발하려면 첫 번째 단계는 EXPLAIN 계획을 보고, 계획을 해석한 다음 계획을 조정하는 것입니다. Spark SQL 사용자 인터페이스(UI) 또는 Spark SQL 기록 서버를 사용하여 계획을 시각화할 수 있습니다.

Spark Catalyst Optimizer는 다음과 같이 초기 쿼리 계획을 최적화된 쿼리 계획으로 변환합니다.
-
분석 및 선언적 APIs - 분석 단계는 첫 번째 단계입니다. SQL 쿼리에서 참조되는 객체가 알려지지 않았거나 입력 테이블과 일치하지 않는 해결되지 않은 논리적 계획은 무한 속성 및 데이터 유형으로 생성됩니다. 그런 다음 Spark SQL Catalyst Optimizer는 일련의 규칙을 적용하여 논리적 계획을 수립합니다. SQL 구문 분석기는 SQL 추상 구문 트리(AST)를 생성하고 이를 논리적 계획의 입력으로 제공할 수 있습니다. 입력은 API를 사용하여 구성된 데이터 프레임 또는 데이터 세트 객체일 수도 있습니다. 다음 표에는 SQL, 데이터 프레임 또는 데이터 세트를 사용해야 하는 시기가 나와 있습니다.
SQL 데이터 프레임 데이터세트 구문 오류 런타임 컴파일 시간 컴파일 시간 분석 오류 런타임 런타임 컴파일 시간 입력 유형에 대한 자세한 내용은 다음을 검토하세요.
-
데이터 세트 API는 형식의 버전을 제공합니다. 이렇게 하면 사용자 정의 Lambda 함수에 대한 의존도가 높아져 성능이 저하됩니다. RDD 또는 데이터 세트는 정적으로 입력됩니다. 예를 들어 RDD를 정의할 때 스키마 정의를 명시적으로 제공해야 합니다.
-
데이터 프레임 API는 입력되지 않은 관계형 작업을 제공합니다. 데이터 프레임은 동적으로 입력됩니다. RDD와 마찬가지로 데이터 프레임을 정의할 때 스키마는 동일하게 유지됩니다. 데이터는 여전히 구조화되어 있습니다. 그러나이 정보는 런타임에서만 사용할 수 있습니다. 이렇게 하면 컴파일러가 SQL과 유사한 문을 작성하고 즉시 새 열을 정의할 수 있습니다. 예를 들어 모든 작업에 대해 새 클래스를 정의할 필요 없이 기존 데이터 프레임에 열을 추가할 수 있습니다.
-
Spark SQL 쿼리는 런타임 중에 구문 및 분석 오류에 대해 평가되므로 런타임이 더 빨라집니다.
-
-
카탈로그 - Spark SQL Apache Hive Metastore (HMS)를 사용하여 데이터베이스, 테이블, 열 및 파티션과 같은 영구 관계형 엔터티의 메타데이터를 관리합니다.
-
최적화 - 최적화 프로그램은 휴리스틱 및 비용을 사용하여 쿼리 계획을 다시 작성합니다. 최적화된 논리적 계획을 생성하기 위해 다음을 수행합니다.
-
열 정리
-
조건자를 푸시다운합니다.
-
조인 재정렬
-
-
물리적 계획 및 플래너 - Spark SQL Catalyst Optimizer는 논리적 계획을 물리적 계획 세트로 변환합니다. 즉, 무엇을 어떻게 변환하는지를 변환합니다.
-
선택한 물리적 계획 "" - Spark SQL Catalyst Optimizer는 가장 비용 효율적인 물리적 계획을 선택합니다.
-
최적화된 쿼리 계획 - 성능 최적화 및 비용 최적화 쿼리 계획을 Spark SQL 실행합니다. Spark SQL Memory Management는 메모리 사용량을 추적하고 작업과 연산자 간에 메모리를 분산합니다. Spark SQL Tungsten 엔진은 Spark SQL 애플리케이션의 메모리 및 CPU 효율성을 크게 개선할 수 있습니다. 또한 바이너리 데이터 모델 처리를 구현하고 바이너리 데이터에서 직접 작동합니다. 이렇게 하면 역직렬화의 필요성을 우회하고 데이터 변환 및 역직렬화와 관련된 오버헤드를 크게 줄일 수 있습니다.
