기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
데이터 압축 구성
페이지 또는 행 압축을 사용하여 EnterpriseOne 비즈니스 데이터 및 제어 테이블의 테이블과 인덱스를 압축할 수 있습니다. 의 대부분의 EnterpriseOne 워크로드는 페이지 압축을 통해 최상의 성능을 AWS 나타내지만, 매우 큰 워크로드(비압축 테라바이트의 배수)는 행 압축을 통해 더 나은 성능을 발휘할 수 있습니다. 이 가이드에서는 페이지 압축과 행 압축을 비교하여 자세히 설명하지 않습니다. 이 섹션에서는 주로 페이지 압축에 초점을 맞춥니다.
일반 EnterpriseOne 워크로드에 대해 압축을 활성화하면 CPU 사용량 증가는 미미하지만 전체 시스템 성능에는 다음 영역에서 측정 가능한 상당한 이점이 있습니다.
-
데이터가 압축된 형식으로 디스크에 저장되므로 데이터베이스 크기와 스토리지 요구 사항이 더 작습니다.
-
압축 시 버퍼 캐시가 훨씬 더 많은 데이터를 저장할 수 있으므로 버퍼 캐시 적중률이 더 높습니다.
-
각 I/O 작업이 훨씬 더 많은 데이터를 반환하므로 필요한 Amazon EBS IOPS와 처리량이 적어지고, 버퍼 캐시가 더 효과적이기 때문에 더 적은 작업이 필요합니다.
-
백업 프로세스 전체에서 데이터가 압축된 상태로 유지되므로 백업 속도가 빨라집니다.
테이블별로 또는 인덱스만으로 압축을 개별적으로 활성화할 수 있습니다. 테이블과 인덱스별로 압축 유형(페이지 또는 행)을 선택할 수도 있습니다. F0002(Next Number) 및 F0902(Account Balances) 테이블과 같이 정기적으로 업데이트되는 테이블은 압축하지 않는 것이 유리할 수 있습니다. 대부분의 경우 모든 테이블과 인덱스에서 압축을 활성화하면 객체별 분석 없이도 대부분의 이점을 얻을 수 있으므로 이 방법이 가장 쉬운 솔루션입니다. 이 가이드의 단계에서는 페이지 압축으로 모든 테이블과 인덱스를 압축합니다.
경우에 따라, 특히 타사 시스템이 JD Edwards 데이터베이스에 직접 액세스하여 테이블 및 인덱스 스캔 작업을 수행하는 경우 압축으로 인해 성능이 저하될 수 있습니다. 이러한 성능 저하는 대개 쿼리가 제대로 수행되지 않아 발생합니다. 이 경우에는 느린 쿼리를 검토하고 일반적인 최적화 기법을 사용하여 성능을 개선합니다. 예를 들어, 기존 인덱스를 사용하거나 새 인덱스를 빌드하도록 쿼리를 다시 작성하는 것을 고려해 보세요.
압축 활성화는 다단계 프로세스입니다. 대부분의 단계에서 데이터베이스 객체에 대한 단독 액세스가 필요하므로 EnterpriseOne과 기타 시스템을 오프라인으로 전환해야 합니다. 다음은 DTA 및 CTL 스키마의 모든 테이블과 인덱스에서 페이지 압축을 활성화하는 대략적 단계입니다.
압축 전 디스크 공간 사용률 확인
데이터베이스의 현재 디스크 공간 사용률을 확인하려면 다음 스크립트를 실행합니다.
USE JDE_PRIST920 SELECT DB_NAME() AS DbName, type_desc, CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT)/128.0 AS SpaceUsedMB FROM sys.database_files WHERE type IN (0,1) AND type_desc = 'ROWS'; SELECT SUM(CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT)/128.0) AS TotalSpaceUsedMB FROM sys.database_files WHERE type IN (0,1) AND type_desc = 'ROWS'
다음과 유사하게 출력됩니다.
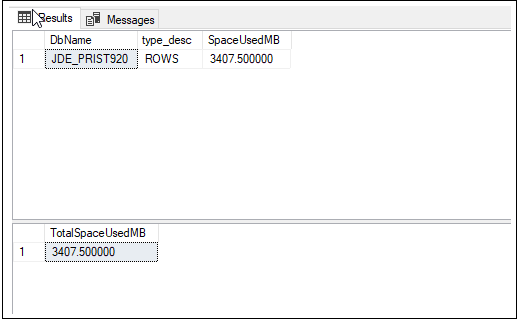
이 예제에서 테이블 행은 3,407MB의 디스크 공간을 차지합니다.
열거 스크립트 실행
EnterpriseOne 데이터베이스의 테이블과 인덱스 용량이 크기 때문에 스크립트를 사용하여 압축할 객체를 열거할 수 있습니다. 열거 스크립트의 출력은 다음 섹션에서 사용되는 압축 스크립트입니다. 다음 스크립트를 실행하기 전에 압축하려는 테이블 및 인덱스의 소유자를 반영하도록 스키마 소유자 이름을 업데이트합니다.
declare @tblname as varchar(100) declare @idxname as varchar(100) declare @schemaname as varchar(100) declare @sqlstatement as varchar(512) declare tblcurs CURSOR for select t.name as tblname, s.name as schemaname from sys.tables t inner join sys.schemas s on t.schema_id = s.schema_id inner join sys.indexes i on i.object_id = t.object_id inner join sys.partitions p on i.object_id = p.object_id AND i.index_id = p.index_id where s.name in ('PS920DTA', 'PS920CTL') and i.type_desc='CLUSTERED' and p.data_compression_desc <> 'PAGE' open tblcurs FETCH next from tblcurs into @tblname, @schemaname while @@FETCH_STATUS = 0 begin FETCH next from tblcurs into @tblname, @schemaname set @sqlstatement = 'alter table ' + @schemaname + '.' + @tblname + ' rebuild with (DATA_COMPRESSION = PAGE)' print @sqlstatement end close tblcurs deallocate tblcurs declare idxcurs CURSOR for select i.name as idxname, t.name as tblname, s.name as schemaname from sys.tables t inner join sys.schemas s on t.schema_id = s.schema_id inner join sys.indexes i on i.object_id = t.object_id inner jOIN sys.partitions p ON i.object_id = p.object_id AND i.index_id = p.index_id where s.name in ('PS920DTA', 'PS920CTL') and p.data_compression_desc <> 'PAGE' and i.type_desc='NONCLUSTERED' and i.name is not null open idxcurs FETCH next from idxcurs into @idxname, @tblname, @schemaname while @@FETCH_STATUS = 0 begin FETCH next from idxcurs into @idxname, @tblname, @schemaname set @sqlstatement = 'alter index ' + @idxname + ' on ' + @schemaname + '.' + @tblname + ' rebuild with (DATA_COMPRESSION = PAGE)' print @sqlstatement end close idxcurs deallocate idxcurs
압축 스크립트 실행
마지막 섹션에서 실행한 열거 스크립트의 출력을 검토합니다. 이 압축 스크립트를 작은 스크립트로 나눠서 개별적으로 또는 병렬로 실행할 수 있습니다.
중요
EnterpriseOne 데이터베이스에 대해 이 스크립트를 실행할 때 EnterpriseOne 시스템이 오프라인 상태인지 확인합니다.
다음은 압축 스크립트의 예입니다.
alter table PS920DTA.F07620 rebuild with (DATA_COMPRESSION = PAGE) alter table PS920DTA.F760404A rebuild with (DATA_COMPRESSION = PAGE) alter table PS920DTA.F31B93Z1 rebuild with (DATA_COMPRESSION = PAGE) alter table PS920DTA.F31B65 rebuild with (DATA_COMPRESSION = PAGE) alter table PS920DTA.F47156 rebuild with (DATA_COMPRESSION = PAGE) alter table PS920DTA.F74F210 rebuild with (DATA_COMPRESSION = PAGE) ... alter index F4611_16 on PS920DTA.F4611 rebuild with (DATA_COMPRESSION = PAGE) alter index F4611_17 on PS920DTA.F4611 rebuild with (DATA_COMPRESSION = PAGE) alter index F7000110_PK on PS920DTA.F7000110 rebuild with (DATA_COMPRESSION = PAGE) alter index F7000110_3 on PS920DTA.F7000110 rebuild with (DATA_COMPRESSION = PAGE) alter index F7000110_4 on PS920DTA.F7000110 rebuild with (DATA_COMPRESSION = PAGE) alter index F76A801T_PK on PS920DTA.F76A801T rebuild with (DATA_COMPRESSION = PAGE) ...
압축 후 디스크 공간 사용률 확인
압축 후 데이터베이스의 현재 디스크 공간 사용률을 확인하려면 다음 스크립트를 실행합니다.
USE JDE_PRIST920 SELECT DB_NAME() AS DbName, type_desc, CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT)/128.0 AS SpaceUsedMB FROM sys.database_files WHERE type IN (0,1) AND type_desc = 'ROWS'; SELECT SUM(CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT)/128.0) AS TotalSpaceUsedMB FROM sys.database_files WHERE type IN (0,1) AND type_desc = 'ROWS'
다음과 같이 출력됩니다
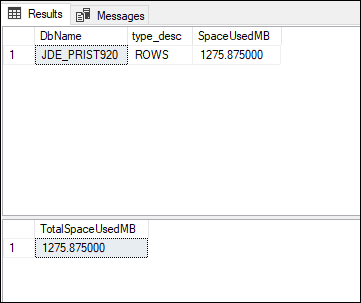
이 예제에서 사용된 공간이 3,407MB에서 1,275MB로 줄어들어 압축을 통해 62% 절약되었음을 확인할 수 있습니다. 데이터베이스의 절감 효과는 데이터베이스의 테이블에 데이터가 배포되는 방식에 따라 달라집니다.
