Amazon Redshift에 대한 개념 증명(POC) 수행
Amazon Redshift는 널리 사용되는 클라우드 데이터 웨어하우스로, 조직의 Amazon Simple Storage Service 데이터 레이크, 실시간 스트림, 기계 학습(ML) 워크플로, 트랜잭션 워크플로 등과 통합되는 완전관리형 클라우드 기반 서비스를 제공합니다. 이어지는 섹션에서는 Amazon Redshift에 대한 개념 증명(POC)을 수행하는 과정을 안내합니다. 이 정보는 POC의 목표를 설정하고 POC에 대한 서비스 프로비저닝 및 구성을 자동화할 수 있는 도구를 활용하는 데 도움이 됩니다.
참고
이 정보를 PDF로 복사하려면 Amazon Redshift 리소스
Amazon Redshift의 POC를 수행할 때는 동급 최고의 보안 기능, 탄력적 규모 조정, 간편한 통합 및 수집, 유연한 분산형 데이터 아키텍처 옵션에 이르는 다양한 기능을 테스트하고 검증하고 채택합니다.

POC를 성공적으로 수행하려면 다음 단계를 따르세요.
1단계: POC의 범위

POC를 수행할 때 자체 데이터를 사용하거나 벤치마킹 데이터세트를 사용할 수 있습니다. 자체 데이터를 선택하면 해당 데이터에 대해 자체 쿼리를 실행합니다. 벤치마킹 데이터를 선택하면 벤치마크와 함께 샘플 쿼리가 제공됩니다. 아직 자체 데이터로 POC를 수행할 준비가 되지 않은 경우 자세한 내용은 샘플 데이터세트 사용을 참조하세요.
일반적으로 Amazon Redshift POC를 위해 2주 분량의 데이터를 사용하는 것이 좋습니다.
다음을 수행하여 시작하세요.
비즈니스 및 기능 요구 사항을 파악한 다음 거슬러 올라갑니다. 일반적인 예로는 성능 속도 향상, 비용 절감, 새로운 워크로드 또는 기능 테스트, Amazon Redshift와 다른 데이터 웨어하우스 간의 비교 등이 있습니다.
POC의 성공 기준이 되는 구체적인 목표를 설정합니다. 예를 들어, 성능 속도 향상을 먼저 결정한 후 가속화하려는 상위 5개 프로세스의 목록을 작성하고 현재 실행 시간과 필요한 실행 시간을 포함하세요. 보고서, 쿼리, ETL 프로세스, 데이터 모으기 등 현재 겪고 있는 문제점이라면 무엇이든 가능합니다.
테스트를 실행하는 데 필요한 구체적인 범위와 아티팩트를 식별합니다. Amazon Redshift로 마이그레이션하거나 지속적으로 수집해야 하는 데이터세트는 무엇이며 성공 기준을 바탕으로 측정하기 위한 테스트를 실행하려면 어떤 쿼리와 프로세스가 필요한가요? 이렇게 하는 방법은 두 가지입니다.
자체 데이터 사용
자체 데이터를 테스트하려면 성공 기준을 바탕으로 테스트하는 데 필요한 최소 실행 가능한 데이터 아티팩트 목록을 작성하세요. 예를 들어 현재 데이터 웨어하우스에 200개의 테이블이 있지만 테스트하려는 보고서에는 20개만 필요한 경우 더 적은 수인 20개만 사용하여 POC를 더 빠르게 실행할 수 있습니다.
샘플 데이터세트 사용
자체 데이터세트가 준비되지 않은 경우에도 TPC-DS
또는 TPC-H 와 같은 업계 표준 벤치마크 데이터세트를 사용하고 샘플 벤치마킹 쿼리를 실행하면 Amazon Redshift에 대한 POC를 시작하여 Amazon Redshift의 성능을 활용할 수 있습니다. 이러한 데이터세트는 Amazon Redshift 데이터 웨어하우스가 생성된 후 해당 데이터 웨어하우스 내에서 액세스할 수 있습니다. 이러한 데이터세트와 샘플 쿼리에 액세스하는 방법에 대한 지침은 2단계: Amazon Redshift 시작 섹션을 참조하세요.
2단계: Amazon Redshift 시작

Amazon Redshift는 규모에 따른 빠르고 쉽고 안전한 클라우드 데이터 웨어하우징을 통해 인사이트를 얻는 시간을 단축합니다. Redshift Serverless 콘솔
Amazon Redshift Serverless 설정
Redshift Serverless를 처음 사용할 때 콘솔은 웨어하우스를 시작하는 데 필요한 단계를 안내합니다. 또한 계정의 Redshift 서버리스 사용량에 대한 크레딧을 받을 자격이 있을 수도 있습니다. 무료 평가판 선택에 대한 자세한 내용은 Amazon Redshift 무료 평가판
이전에 계정에서 Redshift Serverless를 시작한 경우 Amazon Redshift 관리 안내서의 네임스페이스가 있는 작업 그룹 생성의 단계를 따르세요. 웨어하우스를 사용할 수 있게 되면 Amazon Redshift에서 사용할 수 있는 샘플 데이터를 로드하도록 선택할 수 있습니다. Amazon Redshift 쿼리 에디터 v2를 사용한 데이터 로드에 대한 자세한 내용은 Amazon Redshift 관리 안내서의 샘플 데이터 로드를 참조하세요.
샘플 데이터세트를 로드하는 대신 자체 데이터를 사용하는 경우 3단계: 데이터 로드 섹션을 참조하세요.
3단계: 데이터 로드

Redshift Serverless를 시작한 후 다음 단계는 POC에 사용할 데이터를 로드하는 것입니다. 간단한 CSV 파일을 업로드하든, S3에서 반정형 데이터를 수집하든, 데이터를 직접 스트리밍하든, Amazon Redshift는 데이터를 소스에서 Amazon Redshift 테이블로 빠르고 쉽게 이동할 수 있는 유연성을 제공합니다.
다음 방법 중 하나를 선택하여 데이터를 로드합니다.
로컬 파일 업로드
빠른 수집 및 분석을 위해 Amazon Redshift 쿼리 에디터 v2를 사용하여 로컬 데스크톱에서 데이터 파일을 쉽게 로드할 수 있습니다. CSV, JSON, AVRO, PARQUET, ORC 등과 같은 다양한 형식의 파일을 처리할 수 있는 기능이 있습니다. 관리자가 사용자에게 쿼리 에디터 v2를 사용하여 로컬 데스크톱에서 데이터를 로드하는 권한을 부여하려면 공통 Amazon S3 버킷을 지정하고 사용자 계정을 적절한 권한으로 구성해야 합니다. 단계별 안내는 Data load made easy and secure in Amazon Redshift using Query Editor V2
Amazon S3 파일 로드
Amazon S3 버킷에서 Amazon Redshift로 데이터를 로드하려면 먼저 소스 Amazon S3 위치와 대상 Amazon Redshift 테이블을 지정하여 COPY 명령을 사용하세요. Amazon Redshift가 지정된 Amazon S3 버킷에 액세스할 수 있도록 IAM 역할 및 권한이 적절하게 구성되어 있는지 확인하세요. 단계별 지침은 튜토리얼: Amazon S3에서 데이터 로드를 참조하세요. 쿼리 에디터 v2에서 데이터 로드 옵션을 선택하여 S3 버킷에서 직접 데이터를 로드할 수도 있습니다.
지속적인 데이터 모으기
자동 복사(미리 보기)는 COPY 명령의 익스텐션으로, Amazon S3 버킷에서의 지속적인 데이터 로드를 자동화합니다. 복사 작업을 생성하면 Amazon Redshift는 지정된 경로에 새 Amazon S3 파일이 생성될 때 감지하여 사용자 개입 없이 자동으로 로드합니다. Amazon Redshift는 로드된 파일을 추적하여 한 번만 로드되었는지 확인합니다. 복사 작업을 생성하는 방법에 대한 설명은 COPY JOB 섹션을 참조하세요.
참고
자동 복사는 현재 미리 보기 단계이며 특정 AWS 리전에서 프로비저닝된 클러스터에만 지원됩니다. 자동 복사를 위한 미리 보기 클러스터를 생성하려면 Amazon S3에서 지속적인 파일 수집(프리뷰) 섹션을 참조하세요.
스트리밍 데이터 로드
스트리밍 수집을 사용하면 지연 시간이 짧고 빠른 속도로 Amazon Kinesis Data Streams
4단계: 데이터 분석

Redshift Serverless 작업 그룹과 네임스페이스를 만들고 데이터를 로드한 후에는 Redshift Serverless 콘솔
Amazon Redshift 쿼리 에디터 v2를 사용하여 쿼리
Amazon Redshift 콘솔에서 쿼리 에디터 v2에 액세스할 수 있습니다. 쿼리 에디터 v2를 사용하여 쿼리를 구성, 연결 및 실행하는 방법에 대한 전체 가이드는 Simplify your data analysis with Amazon Redshift query editor v2
또는 POC의 일환으로 로드 테스트를 실행하려는 경우 다음 단계에 따라 Apache JMeter를 설치하고 실행하면 됩니다.
Apache JMeter를 사용하여 로드 테스트 실행
Amazon Redshift에 쿼리를 동시에 제출하는 'N'명의 사용자를 시뮬레이션하는 로드 테스트를 수행하려면 오픈 소스 Java 기반 도구인 Apache JMeter
Redshift Serverless 작업 그룹에 대해 실행되도록 Apache JMeter를 설치하고 구성하려면 Automate Amazon Redshift load testing with the AWS Analytics Automation Toolkit
SQL 문을 사용자 지정하고 테스트 계획을 완료한 후에는 테스트 계획을 저장하고 Redshift Serverless 작업 그룹에 대해 실행하세요. 테스트 진행 상황을 모니터링하려면 Redshift Serverless 콘솔
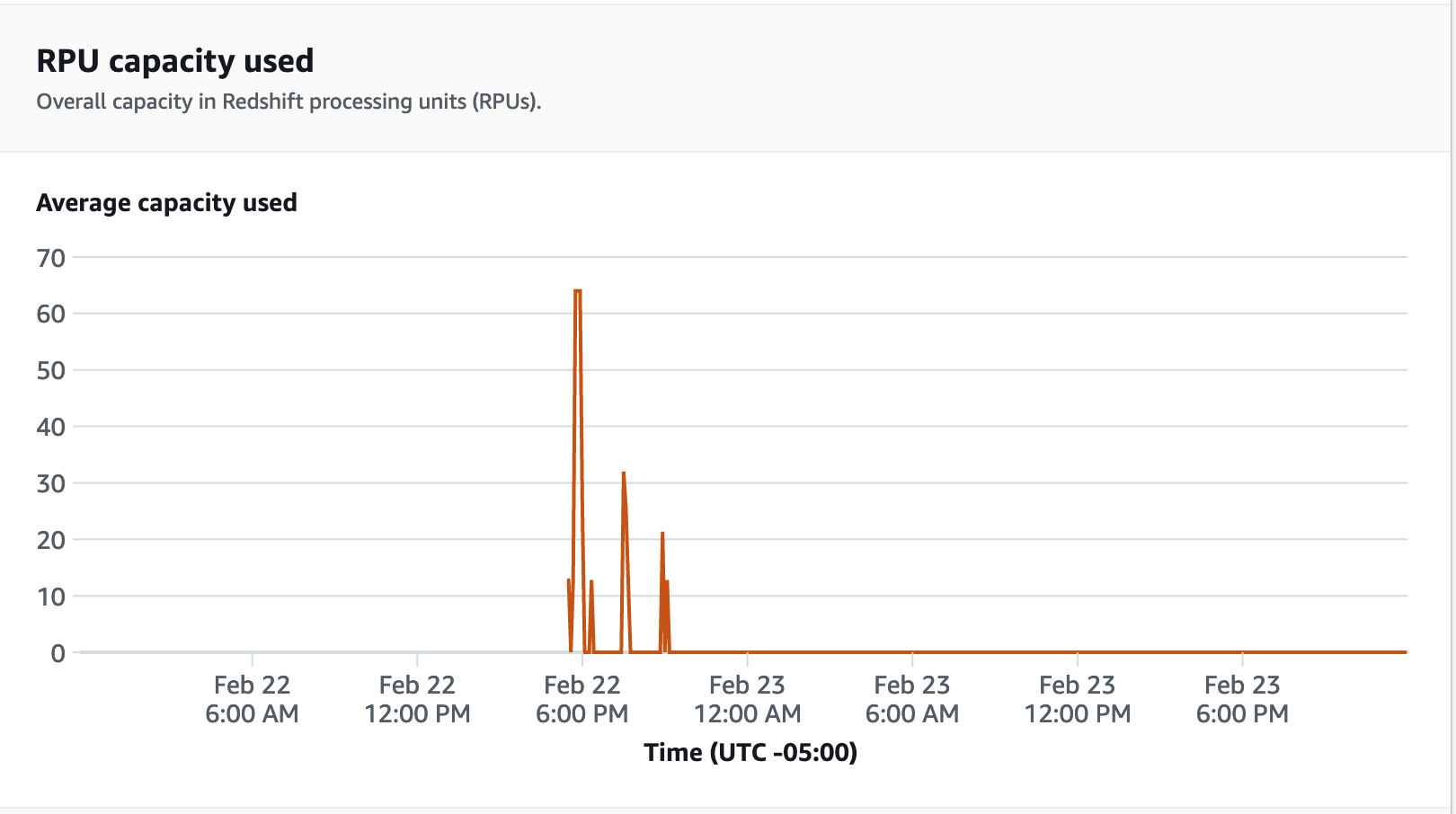
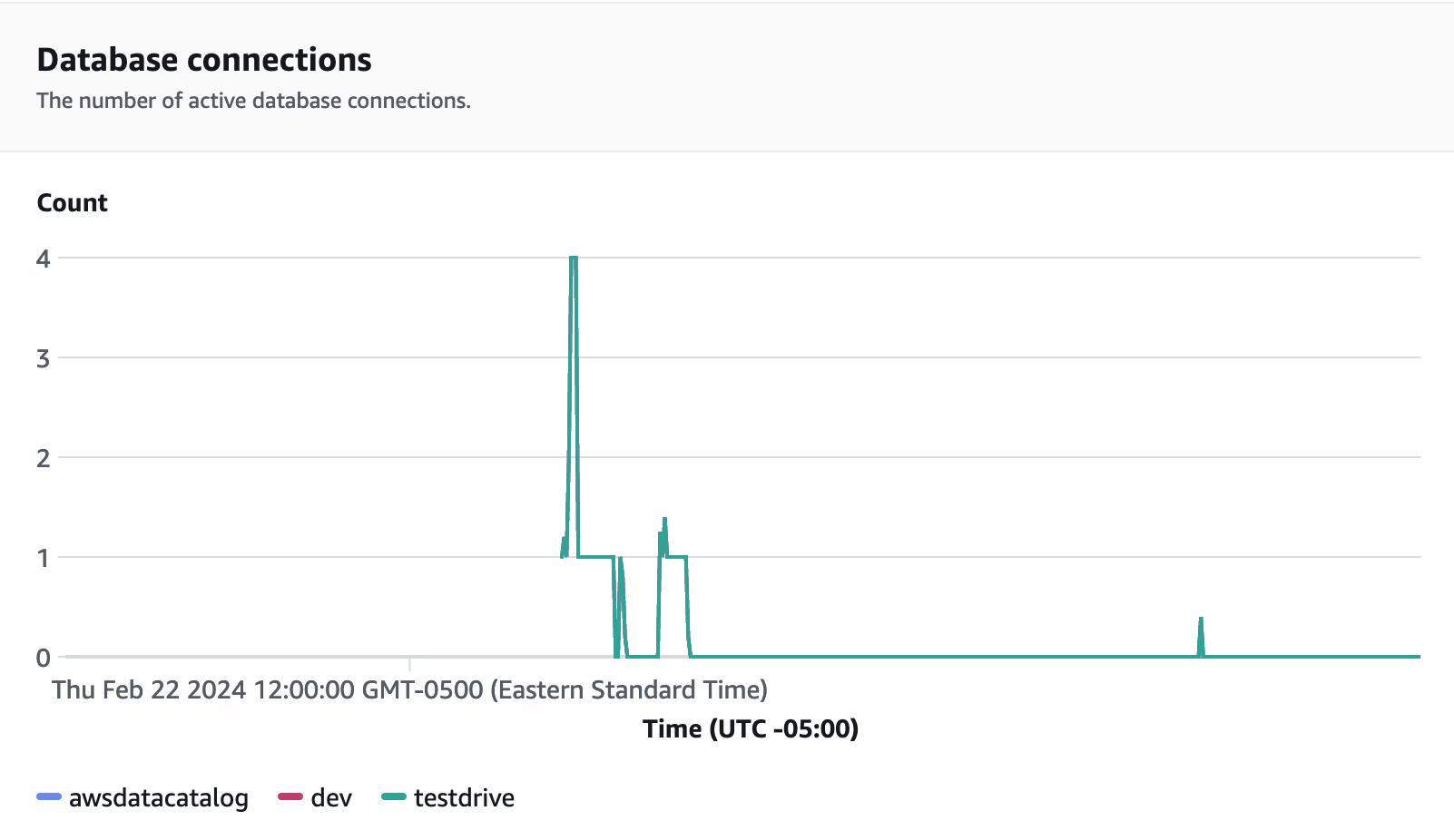
성능 지표의 경우 Redshift Serverless 콘솔에서 데이터베이스 성능 탭을 선택하여 데이터베이스 연결 및 CPU 사용률과 같은 지표를 모니터링할 수 있습니다. 여기에서 그래프를 통해 작업 그룹에서 로드 테스트가 실행되는 동안 사용된 RPU 용량을 모니터링하고 Redshift Serverless가 동시 워크로드 수요를 충족하기 위해 어떻게 자동으로 규모를 조정하는지 볼 수 있습니다.
데이터베이스 연결은 작업 그룹이 증가하는 워크로드 수요를 충족하기 위해 주어진 시간에 수많은 동시 연결을 처리하는 방식을 확인하기 위해 로드 테스트를 실행하는 동안 모니터링할 수 있는 또 다른 유용한 지표입니다.
5단계: 최적화

Amazon Redshift는 개별 사용 사례를 지원하는 다양한 구성과 기능을 제공하여 수만 명의 사용자가 매일 엑사바이트 규모의 데이터를 처리하고 분석 워크로드를 강화할 수 있도록 지원합니다. 이러한 옵션 중에서 선택할 때 고객은 Amazon Redshift 워크로드 지원에 가장 적합한 데이터 웨어하우스 구성을 결정하는 데 도움이 되는 도구를 찾고 있습니다.
테스트 드라이브
테스트 드라이브
